- HOME
- [종료]주주클럽 스터디
- 2017년 관계형데이터모델링 스터디
- 8.8 복잡한 주 식별자
잘못알려진 상식
- 흔히 주 식별자를 구성히는 속성은 다섯개 이내가 좋으며, 많더라도 일곱 개를 넘어서는 안된다는 등의 가이드(Guideline)가 존재한다
하지만 이는 전혀 논리적이지 않고 좋은 개념이 아니다.
복잡한 주실별자
- 업무 식별자가 주 식별자가 되는 것은 바람직하며 가장 기본적인 원칙
- 주변에 관계를 가지는 엔터티도 고려해야 한다
- (다른 엔터티에서 빈번하게 참조되면 주 식별자가 여러 속성으로 구성되는 것이 문제가 될 수 있지만 그렇지 않다면 문제 될 것이 없다.
- 오히려 성능을 고려해 깊은단계의 복잡한 조인(join)을 피하려고 주 식별자를 식별자로 상속시키는 전략 탓에 주 식별자가 복잡 해질 수 있다.)
- ->이때는 주 식별자를 구성하는 속성의 개수에 대한 가이드가 필요할 수 있다.
- 많은엔티티 에서 참조되지 않으면 주식별자가 복잡한것은 보통 문제가 되지 않는다.
- (오히려 업무 식별자를 그대로 사용하는 것이 비람직해서 인조 식별자를 채택할 이유가 없다.)
- -> 인조 식별자를 채택하면 인덱스를 히나 더 생성해야 하며 업무 식별자에 유니크 인텍스를 생성해야 하므로 업무식별자에 대한 별도의 관리가 필요해진다
주식별자가 복잡해질때
- 기준데이터를관리할 때
- 집계 데이터를 관리할 때
- 인스턴스를 생성하는 기준이 복잡할 때
- 교차 앤터티일 때
- 슈퍼 식별자가 사용될 때
- PK 인덱스(커버링 인덱스)를 사용하려 할 때
- 주 식별자상속이 지속적으로 이루어질 때
기준데이터를관리할 때

- 기준정보는 보통 하위 엔터티가 존재하지 않는다.
- 식별자가 복집해지는것은 문제가 되지 않는다
(인조 식별자를 사용하면 결과를 저장하는 속성(종속자)과 관리 기준이 되는 속성(결정자)사이에 혼란이 생긴다)
집계 데이터를 관리할 때

- 집계정보는 보통 하위 엔터티가 존재하지 않는다.
- 집계 엔터티의 주 식별지는 디벤젼(Dimension:관점,차원) 이 되므로 많은 싱위(부모) 엔티티가 존재할 수 있다.
인스턴스를 생성하는 기준이 복잡할 때
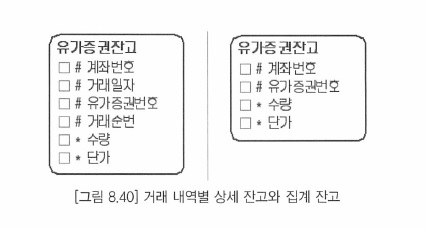
- 데이타를 관리하려는 상세 수준에 따라서 주 식별자가 복잡해질 수 있다
- 왼쪽 엔터티와 같이 매입할 때마다 인스턴스를 생성하면 잔고를 상세하게 관리한다
- ( 어떻게 관리할지 따라 주식별자가 복잡해진다 )
교차 엔터티일 때
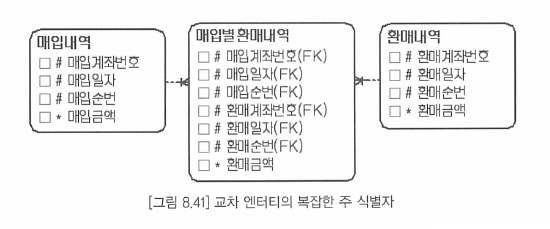
- 그림8-40을 다대다로 이력테이블로 관리
- 다대다(M:M) 관계를 데이티로 관리하려면 교차 엔터티가 필요 ( 매핑테이블이 필요하다 )
- 양쪽 엔터티의 주 식별자를 상속받으므로 교차 엔터티의 주 식별자는 더 복잡해진다.
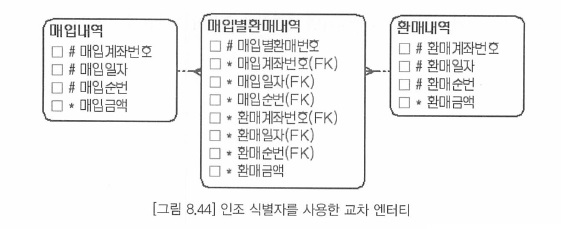
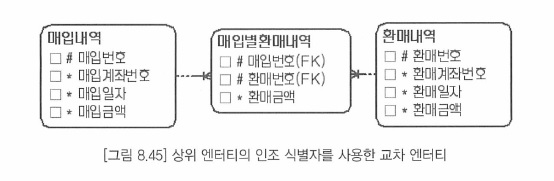
- 복잡해진 주식별자로 인해 인조 식별자로 단순화 방법과 부모의 엔터티를 단순화하는 방법이 있다.
슈퍼 식별자가 사용될 때 / PK 인덱스(커버링 인덱스)를 사용하려 할 때
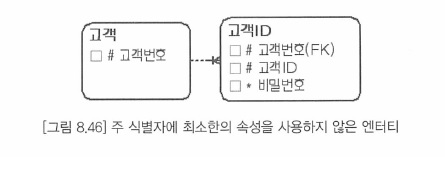
- 고객ID 엔터티의 주식별자는 고객ID 속성이고 고객변호 속성은 일반속성으로 관리돼야한다.
- 커버링 인텍스(Covering Index)를 시용하려는 의도나 인덱스를 여러 개 만들지 않으려는 의도에서 슈퍼 식별자(고객번호,고객ID)를 사용
- -> 이는 주식별자를 잘못 결정한 것이다
주 식별자상속이 지속적으로 이루어질 때
- 식별자 상속과 단절이 적절이 이루어지지 않으면 주식별자가 복잡해질 수 있다.
- 조인 없이 조회하기 편리해 무조건 상속하면 주 식별자는 복잡해진다
- 존재 종속 원칙에 근거해 식별자로 상속했다면 주 식별지가 복집해 지는 것이 잘못된 것은 아니다.
- 효율성을 고려해 단절 정책을 세워야 한다.
- HOME
- [종료]주주클럽 스터디
- 2017년 관계형데이터모델링 스터디
- 8.8 복잡한 주 식별자