- HOME
- [종료]주주클럽 스터디
- 2017년 관계형데이터모델링 스터디
- 4.1 정규화
4.1. 정규화(Normalization)란?
정의
- 속성 간의 부정확한 종속성을 없애는 것
- 함수 종속 개념을 기반으로 유사한 속성을 모으고 종속성이 없는 독립적인 속성들은 분리하는 것
- 관계형 데이터 모델이 되려면 속성의 종속성과 의존성을 분석해 더는 분해될 수 없는 엔터티로 만드는 정규화 과정을 거쳐야 함
효과
- 아노말리 현상을 최소화함
- 중복이 최소화된 효율적인 구조의 모델이 생성됨
- 실제 업무를 가장 잘 반영할 수 있음
- 직관적이고 이해하기 쉬움
중복 데이터가 사용된 모델의 예
 | .JPG) |
| Richard Barker 표기법 | IE 표기법 |
- 상품 엔터티와 조인을 피하려고 상품명을 중복 속성으로 채택한 모델이다.
- 상품코드가 '101011'인 상품의 이름이 바뀌면, 상품 엔터티에 존재하는 상품명 속성값만 수정해선 안 됨
- '101011' 상품이 장바구니, 관심상품, 주문상품 엔터티에 존재하면 상품명 속성 값을 같이 수정하여야 함 -> 다량의 업데이트 발생으로 성능저하
- 만약 업데이트를 하지 않으면 데이터 정합성이 깨짐
ER 다이어그램 표기법
- $ : 식별자 비상속
- # : 실질 식별자(PK)
- (#) : 보조 식별자
- \* : 반드시 값이 존재해야 하는 속성
- 0 : 반드시 값이 존재하지 않아도 되는 속성
Richard Barker 표기법
- 관계에서
- | 표시 있는 것은 식별자로 상속
- | 표시 없는 것은 일반속성으로 상속
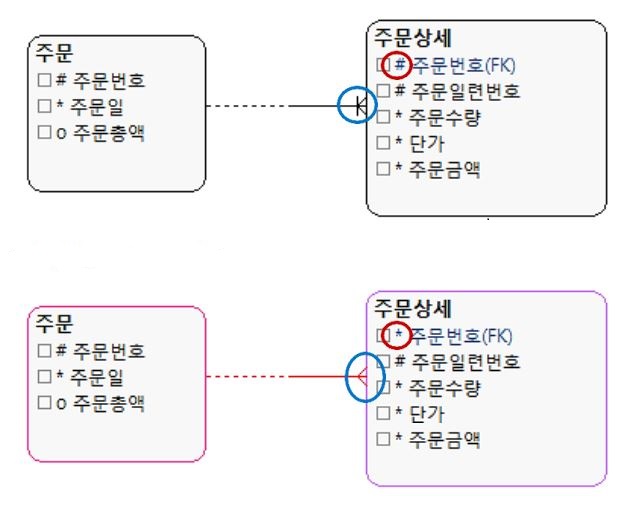
- 시작하는 쪽이 점선으로 시작하면 반대쪽 데이터가 존재하지 않을 수 있음
IE 표기법
- O가 붙어 있는 쪽은 데이터가 존재하지 않을 수 있음
- HOME
- [종료]주주클럽 스터디
- 2017년 관계형데이터모델링 스터디
- 4.1 정규화