08. 레플리케이션 (61p) (by nav012) [2017.06.24]
1. 글로벌 트렌젝션 ID
- Replication 이란 고가용성 및 부하 분산을 위한 기능
- 마스터 노드 에서 수행 된 Transaction 을 슬레이브 노드에 로그를 이용해 읽기 전용으로 복제
GTID 사용 이전 버전에서는
- 마스터 노드의 바이너리 로그 파일 이름과 위치를 전달하는 방법 사용
- 파일 위치와 정보 등은 서버 내에서만 의미 있는 정보이므로 여러 슬레이브 노드 간 호환되지 않음
1) GTID 란

- 파일의 물리적 위치정보가 아니라 전체 node 간 호환 가능한 가상의 트렌젝션 ID
- 각 노드들의 바이너리 로그파일 및 Offset 정보가 다를지라도 글로벌 ID 값은 동일
- 트렌젝션을 지원하는 스토리지 엔진에서는 거의 트렌젝션 단위로 GTID 채번, 미 지원 엔진에서는 SQL 단위로 채번
MySQL 의 GTID 는
- GTID 시퀀스에서 누락 값을 허용하지 않음
- 멀티 스레드 복제 시 바이너리 로그의 순서와 무관하게 수행 가능
MariaDB 의 GTID 는
- GTID 시퀀스에서 누락 값을 허용
- 멀티 스레드 복제 시 바이너리 로그의 순서대로 수행
2) GTID 의 필요성


하나의 마스터에 두 개 이상의 슬레이브가 연결 된 복제 DB 에서 마스터 서버에 장애 발생 시
- 슬레이브 중 하나의 노드를 마스터로 승격시키고
- 다른 하나의 슬레이브를 새로 생긴 마스터 노드를 바라보게 전환
- 이 때 장애 발생 전 슬레이브 노드 간 전송 지연등에 의해 시점 차이가 있었을 경우 장애 이후 자동 동기화 불가


글로벌 ID 를 사용한다면
- 모든 노드 간 동일한 ID 값을 사용하므로
- 마스터 노드가 바뀌더라도 무관
- 전송 지연이 된 슬레이브라도 새로 승격 된 마스터에서 동일한 GTID 값을 이용해 따라잡을 수 있다
1) Maria DB 의 GTID
- "도메인 ID - 서버 ID - 트렌젝션 ID" 의 형식
- 도메인 ID 는 멀티 소스 레플리케이션 시 사용할 수 있는 마스터 노드의 정보
GTID 를 스용한 복제 구축 절차
1. 바이너리 로그 파일과 위치 기반 복제를 GTID 로 변경
2. 기존 DB 서버의 데이터 백업
3. 새 슬레이브에 데이터 복구
4. 백업 시점의 바이너리 로그 파일명과 위치 확인
5. 바이너리 로그와 위치로 GTID 확인
6. 슬레이브의 GTID 값을 마스터의 GTID 로 변경
7. 슬레이브에서 CHANGE MASTER 명령 수행하여 마스터와 연결
GTID 를 이용하여 슬레이브에서 복제 건너뛰기
- 사용자의 실수나 장애로 인해 특정 이벤트의 중복 키 에러가 자주 발생한는 편이다
- 복제가 에러로 멈췄을 때 마지막 TGID 값을 확인하여 그 다음 GTID 값으로 재 설정
1) MySQL 의 GTID
- "서버 UUID : 트렌젝션 번호" 의 체계를 갖춤
- GTID 컨시스턴스 모드를 활성화 해야 한다는 제약이 있음
- --> 이 때 CTAS와 같은 명령을 사용할 수 없다 - DML 과 DDL 이 결합 된 형태이므로 에러 발생 시 롤백이 불가능하다고 함
GTID 를 스용한 복제 구축 절차
- Maria DB 와 동일
GTID 를 이용하여 슬레이브에서 복제 건너뛰기
- Marai DB 와 다르게 트렌젝션 번호의 누락을 허용하지 않는다.
- 건너 뛸 GTID 로 슬레이브 DB 의 파라메터 값을 맞춰주고 더미 트렌젝션(BEGIN; COMMIT;) 을 수행
2. 멀티 소스 복제

- Maria 10.0 부터(MySQL 은 5.7 부터 예상) 부터 구현 가능함
- 일반적인 복제에서는 CUD 작업은 마스터 노드에서만 가능하기 때문에 쓰기 성능을 확장 하고자 만들어 진 개념
1) 멀티소스 복제 구축
- 기존 복제와 큰 차이가 있는것은 아님
- 마스터의 데이터를 슬레이브에 백업-복구 시 시스템 테이블스페이스 등 공통 데이터 충돌에 대한 고려 필요
백업-복구 방식
- mysqldump 와 같은 논리적 백업-복구
- 물리적 백업/복구가 아니라 실 데이터만 이동하므로 병합 시 문제가 생기지 않는다
- 데이터가 크다면 구축에 오랜 시간이 소요
- XtraBackup 과 같은 물리적 백업-복구
- DB 모든 데이터 파일을 복사하므로 시스템 테이블스페이스에 대한 충돌을 막을 수 없다
충돌을 고려한 백업 복구 방안
- 1. 마스터 두 노드의 데이터가 모두 크지 않을 경우
- mysqldump 와 같은 논리적 백업으로 양 DB 데이터 모두 이관
- 2. 마스터 두 노드의 한쪽이 큰 경우
- 대용량 DB 쪽을 XtraBackup 으로 물리적 이행, 작은쪽을 mysqldump 로 논리적 이행
- 3. 마스터 두 노드 모두 대용량일 경우
- 둘 다 XtraBackup 으로 물리 백업 수행
- 테!11.JPG!이블 갯수가 많은쪽을 먼저 슬레이브로 이행
- 남은 백업에서 테이블의 ibd 파일을 하나씩 추출하여 슬레이브에 임포트
1) 멀티소스 복제와 글로벌 트렌젝션
- 일반 복제 구성과 다르지 않게 구성 가능하다
- GTID 의 첫 부분이 도메인 값으로 구성 되어 있으므로 슬레이브에서 GTID 끼리 충돌은 발생하지 않는다
3. 멀티 스레드 복제
1) MySQL 의 멀티 스레드 복제

멀티 쓰레드는 데이터베이스 단위로 병렬 처리를 지원함
- 데이터베이스가 하나 일 경우 아무 장점이 없다
- 사용하는 데이터베이스의 개수만큼 슬레이브의 쓰레드 개수 설정
멀티 쓰레드 코디네이터의 기능과 역할

- 릴레이 로그 파일의 바이너리 로그 이벤트를 읽어 데이터베이스 단위로 분리하고 슬레이브의 각 스레드에 분배
- 이벤트 간 충돌에 대한 제어 - 테이블이나 row 단위의 lock 을 제어하는게 아닌 데이터베이스 단위로 수행
마스터에서 이벤트 발생 순서대로 슬레이브에서 처리되지 않는다
- DB 단위로 분배되므로 빠른 순서가 먼저 수행 됨
- 하나의 GTID 에 복제 된 시점의 바이너리 로그 위치를 표현할 수 없음
- 이로 인해 GTID Set 의 개념 사용 - "서버UUID:시작 Transaction 번호 - 마지막 Transaction 번호" 의 연속으로 구성
- 누락된 Transaction 번호가 있을 경우 "UUID:Start#-End#" 의 나열이 너무 많아질 수 있어서 누락을 아예 허용하지 않는다고 함
1) Maria DB 의 멀티 스레드 복제
- 순차/비순차의 두 가지 방식 지원
비 순차 복제
- 도메인 ID 를 기준으로 동작하며 데이터베이스 단위의 멀티 스레드는 지원하지 않음
- 하나의 마스터만 있는 경우에는 도메인 ID 는 세션 단위로 설정 가능한 변수이므로 배치 프로그램 등에서 임의로 도메인 ID 를 지정하여 수행 하면 슬레이브에서 멀티 스레드로 동작 가능
순차 복제
- 바이너리 로그의 그룹 커밋이란? 쓰기 성능 향상을 위해 여러 이벤트를 한번에 모아 커밋 처리
- 순차 복제 시 동일 그룹의 트렌젝션을 대상으로 처리
- 코디네이터 스레드가 각 SQL 스레드에 커밋 그룹 단위로 작업 분배
- 커밋 그룹 간의 충돌이 없다는게 이미 마스터에서 검증 되었으므로 가능
- 하나의 그룹 내에 트렌젝션이 많을 수록 - 빠르고 가벼운 쿼리들이 빈번하게 사용되는 환경에서 유용 함
4. 크래시 세이프 슬레이브
- 복제 구성에서는 IO 스레드와 SQL 스레드가 필요
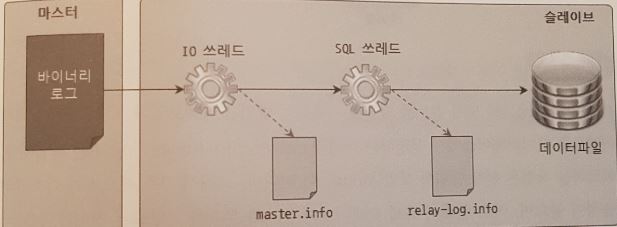
IO 스레드
- 마스터로부터 바이너리 로그 이벤트를 네트워크를 통해 가져온 후 슬레이브의 로컬 디스크에 파일로 저장
- master.info 파일에 저장
SQL 스레드
- IO 스레드가 기록한 이벤트를 슬레이브에서 재 수행
- relay-log.info 파일에 저장
- 바이너리 로그 이벤트가 복제 될 때마다 디스크에 IO 를 발생하므로 부하가 크다
- 일반적으로 부하를 줄이기 위해 비 동기 방식으로 처리한다
- 이 경우 서버 비 정상 종료 후 재 시작 시 이미 수행 된 정보가 다시 수행되어 중복 키 에러가 발생 가능하다
크래시 세이프 복제

- 이러한 문제점을 막기 위해 디스크가 아닌 테이블에 저장하도록 개선
- 복제 위치 정보 테이블에 대한 기록과 실제 테이블 변경을 하나의 트렌젝션으로 묶어 처리 하므로 원자성(Atomicity) 보장 가능
- 트렌젝션 처리가 지원 되는 innoDB 나 XtraDB 스토리지 엔진 필요
1) Maria DB 의 크래시 세이프 복제
- 글로벌 트렌젝션 ID 사용 시 gtid_slave_pos 에 수행한 복제 위치 정보가 자동 저장
- GTID 를 사용하지 않을 경우 크래시 세이프 복제는 구현 불가능
1) MySQL DB 의 크래시 세이프 복제
- 글로벌 트렌젝션과 무관하게 시스템 변수로 구현 가능
STATEMENT 타입을 사용한 용량 최적화
- 전통적인 방법 - SQL 문장을 저장하는 방법인 듯
- UUID 함수와 같이 비 결정적(NOT DETERMINISTIC) 함수나 기능들에 대해서는 복제 불가능
ROW 타입
- 최종적으로 테이블에 저장 된 값을 저장하므로 제약이 없음
- STATEMEMTN 타입보다 많은 저장공간 필요
MIXED TYPE
- STATEMENT 타입과 ROW 타입의 장점을 결합
2) 시스템 변수를 사용한 용량 최적화
MySQL 5.6 에서의 시스템 변수 binog_row_image
- FULL
- ROW 포맷과 같이 변경 레코드의 모든 컬럼을 기록
- INSERT 의 경우 변경 후 모든 컬럼
- UPDATE 의 경우 전/후 컬럼
- DELETE 의 경우 변경 전 모든 컬럼 기록
- MINIMAL
- 변경 될 내용을 슬레이브에 적용 시 꼭 필요한 컬럼만 기록
- PKE(Primary Key Equivalent) - PK 처럼 취급할 수 있는 값
- 테이블에 PK 가 있을 경우는 PK 를 PKE 로 사용
- 테이블에 PK 가 없을 경우는 Not Null UK 사용, UK 도 없을 경우는 모든 컬럼 조합을 PKE 로 사용
- INSERT 의 경우 변경 후 모든 컬럼(AutoIncrement 사용 시 값 포함)
- UPDATE 의 경우 변경 전은 PKE, 변경 후는 값이 명시 된 모든 컬럼
- DELETE 의 경우 변경 전 PKE
- NOBLOB
- 기록하지 않음
2) ROW 포맷 바이너리 로그의 정보성 로그 이벤트
- 많은 사용자들이 STATEMEMT 방식을 사용하는 이유는 사용자가 수행 한 SQL 이 어떤건지 그대로 확인 가능하기 때문
- ROW 포맷에서는 값 자체를 기록하므로 SQL 은 확인 불가
- MariaDB 5.3 의 주석 이벤트, MySQL 5.6 의 정보성 로그 이벤트 도입으로 보완
MariaDB 주석 이벤트
- 사용자가 수행 한 문장을 "Annotate_rows" 이벤트로 기록

MySQL 정보성 로그 이벤트
- 사용자가 수행 한 문장을 "Rows_query" 이벤트로 기록
