6.4 전문 검색 엔진
MySQL 5.6 부터 InnoDB 에서도 전문 검색 엔진 기능 추가.
MySQL 5.5 에서는 MyISAM 의 한계로 전문 검색 엔진 효용 가치 낮음.
6.4.1 전문 검색 인덱스 추가
create table employee_name_innodb (
emp_no int(11) not null,
first_name varchar(14) not null,
last_name varchar(16) not null,
primary key (emp_no)
) engine=innodb default charset=utf8;
insert into employee_name_innodb
select emp_no, first_name, last_name from employees;
alter table employee_name_innodb
add fulltext index fx_firstname_lastname (first_name, last_name);
show warnings;
- 전문 검색 엔진 인덱스 생성 시 내부 FTS_DOC_ID 컬럼 필요, 없을 경우 경고와 함께 추가(Table rebuilding) 됨
- 컬럼 추가는 온라인 처리 불가
6.4.2 전문 검색 인덱스를 위한 테이블 스페이스
| ibd 파일 | 역할 | 비고 |
|---|
| employee_name_innodb.ibd | 테이블 데이터 저장용 기본 테이블 스페이스 | |
| FTS_xxx_yyy_DOC_ID.ibd | 단위 검색어로 구성 된 인덱스 테이블 스페이스 | 컬럼의 값을 구분자로 자른 결과, 인덱스 별 존재 |
| FTS_xxx_CONFIG.ibd | 전문 검색 인덱스 설정 저장 | optimize_checkpoint_limit, synced_doc_id, deleted_doc_count, stopword_table_name, use_stopword 등 |
| FTS_xxx_STOPWORDS.ibd | 전문 검색 인덱스가 사용하는 구분자 저장 | 기본 내장, 사용자 지정 |
| FTS_xxx_{ADDED,DELETED}.ibd | 추가/삭제 레코드 FTS_DOC_ID 저장, 검색시 DELETED 레코드 제거 후 사용자에게 반환 | 레코드 추가 삭제 즉시 전문 검색 인덱스 반영 안됨 |
| FTS_xxx_BEING_{ADDED,DELETED}.ibd | 전문 검색 인덱스에 반영(임시→메인)시 작업중 FTS_DOC_ID 값 저장 | 이 파일은 대부분 비어 있음 |
| FTS_xxx_{ADDED,DELETED}_CACHE.ibd | 레코드 추가 삭제 내용을 즉시 반영하는 임시 전문 인덱스, 메인 전문 인덱스 반영은 테이블 리빌드에 의해 처리 | |
-- 전문 검색 인덱스 반영을 위한 테이블 리빌드
ALTER TABLE employee_name_innodb ENGINE = InnoDB;
OPTIMIZE TABLE employee_name_innodb;
- 메인 전문 검색 인덱스 생성 이후 변경 데이터는 임시 전문 인덱스로 관리.
- 테이블 리빌드 시 임시 전문 인덱스는 메인 전문 인덱스에 병합.
- 임시 전문 인덱스가 지나치게 커지지 않도록 주기적 테이블 리빌드 필요.
- 각 테이블 스페이스 파일은 필요시 생성 되고, 전문 인덱스 삭제 후 테이블 리빌드 하야 모든 테이블 스페이스 파일 삭제됨
| 테이블 | 단위 | 내용 |
|---|
| INNODB_FT_CONFIG | 전체 | 전문 검색 인덱스의 기본 설정 |
| INNODB_FT_DEFAULT_STOPWORD | 전체 | InnoDB의 기본 구분자 목록, 영어에 적합한 구분자 존재 |
| INNODB_FT_INDEX_TABLE | 테이블 | innodb_ft_aux_table 변수값 저장 |
| INNODB_FT_INDEX_CACHE | 테이블 | 임시 전문 인덱스 내용 저장 |
| INNODB_FT_{INSERTED,DELETED} | 테이블 | 추가/삭제된 레코드의 FTS_DOC_ID 저장 |
| INNODB_FT_BEING{INSERTED,DELETED} | 테이블 | 테이블 리빌드에 의해 메인 전문 인덱스에 반영 중인 레코드 정보 저장 |
- 테이블 단위 조회는 innodb_ft_aux_table 변수에 대상 테이블 명시 필요.
SET GLOBAL innodb_ft_aux_table = 'employees/employee_name_innodb';
6.4.4 전문 검색 인덱스 사용
- 전문 검색 전용 쿼리 문법 사용
- MATCH 절에 전문 검색 인덱스 구성 컬럼 모두 명시 필수
SELECT * FROM employee_name_innodb WHERE MATCH(first_name, last_name) AGAINST ('+Matt +Wallrath' IN BOOLEAN MODE);
EXPLAIN
SELECT * FROM employee_name_innodb WHERE MATCH(first_name) AGAINST ('+Matt +Wallrath' IN BOOLEAN MODE);
-- ALL
EXPLAIN
SELECT * FROM employee_name_innodb WHERE MATCH(first_name, last_name) AGAINST ('+Matt +Wallrath' IN BOOLEAN MODE);
-- FULLTEXT
6.4.5 주의 사항
- MyISAM, InnoDB 전문 검색 인덱스의 기본 구분자 리스트는 서로 다르므로 검색 결과가 다를 수 있음.
- 빌트인 구분자 리스트 : INFORMATION_SCHEMA.innodb_ft_default_stopword
- 커스텀 구분자 리스트 : 기본 구분자 리스트 와 같은 구조 테이블 생성 후 구분자 입력 하고, innodb_ft_server_stopword_table 시스템 변수에 설정 (db_name/table_name)
- 커스텀 구분자 리스트 설정 이후 테이블에 대해서만 적용 됨
CREATE TABLE stopword_for_employees (
value varchar(18) NOT NULL DEFAULT ''
) ENGINE = InnoDB;
INSERT INTO stopword_for_employees SELECT * FROM INFORMATION_SCHEMA.innodb_ft_default_stopword;
SELECT * FROM stopword_for_employees limit 10;
SET GLOBAL innodb_ft_server_stopword_table = 'employees/stopword_for_employees';
-- ERROR 1231 / Latin1 문자 셋만 사용 가능
ALTER TABLE stopword_for_employees CONVERT TO CHARACTER SET Latin1;
SET GLOBAL innodb_ft_server_stopword_table = 'employees/stopword_for_employees';
- 구분자 리스트 테이블 이용 순서
- 사용자 : innodb_ft_user_stopword_table
- 시스템 : innodb_ft_server_stopword_table
- 기본값 : INFORMATION_SCHEMA.innodb_ft_default_stopword
- 단위 검색어 길이 기본 값
| 구분 | 최소 | 최대 |
|---|
| MyISAM | ft_min_word_len(4) | ft_max_word_len(무제한) |
| InnoDB | innodb_ft_min_token_size(3) | innodb_ft_max_token_len(64) |
- InnoDB 전문 검색 추가 시스템 변수
- innodb_ft_result_cache_limit : 검색 쿼리 중간/최종 결과가 저장되는 메모리 공간 제한, 초과 시 쿼리 취소 (기본값:2GB)
- innodb_ft_total_cache_size : 모든 임시 전문 검색 인덱스 사용 공간 제한, 초과 시 강제 동기화
- 전문 검색 알고리즘
6.5 Memcached 플러그인
- PK 를 통한 검색 과 같은 단순한 쿼리의 반복 수행은 분석/최적화 부하가 상대적으로 큼
- MariaDB 5.5 의 HandlerSocket 인터페이스 제공
- MySQL 5.6 InnoDB 의 Memcached API 제공 (윈도우 미제공)
6.5.1 아키텍처
- 모든 테이블 접근은 모든 스토리지 엔진을 위한 "핸들러 API" 계층 경유 (최적X)
- Memcached 플러그인은 직접 InnoDB 스토리지 엔진 호출 (최적, MySQL 서버 프로세스 내 별도 스레드 형태)

- Memcached 플러그인 기능 과 특성
- MySQL 서버 프로세스 내 스레드로 작동 하므로 InnoDB 스토리지 엔진 접근 빠름
- InnoDB API 직접 사용으로 빠름 (쿼리 분석/최적화, 핸들러 API 우회)
- Memchached 텍스트/바이너리 프로토콜 지원, Memcapable 의 55개 호환성 테스트 통과
- InnoDB 테이블의 멀티 컬럼을 구분자 활용하여 Memcached 의 Value 로 매핑 가능
- Memcached 의 캐시 메모리와 InnoDB 버퍼 풀 메모리 조합 사용 가능
- Memcached 옵션 지정 가능 : daemon_memcached_option 시스템 변수
- Memcached 플러그 인으로 유입되는 요청의 격리 수준 설정 가능 (innodb_api_trx_level )
6.5.2 설치 및 테스트
- libevent 1.4.3 이상 필요
- 컴파일 시 "-DWITH_INNODB_MEMCACHED=ON" 옵션 필요
- my.cnf
| 구분 | 설정 |
|---|
| TCP/IP 포트 | daemon_memcached_option = '-m 64 -p 11211 -c 200 -t 6' |
| Unix 소켓 파일 | daemon_memcached_option = '-m 64 -c 200 -t 6 -s /tmp/memcached.sock' |
| 옵션 | 설명 | 비고 |
|---|
| -m | 로컬 캐시 메모리 크기(단위: MB) | MySQL 쿼리 캐시, InnoDB 버퍼 풀 무관 |
| -p | Listen Port | |
| -s | 유닉스 도메인 소켓 파일 | 클라이언트가 로컬에 있을 때, 설정 시 -p 옵션 무시 |
| -c | 최대 연결 수 | |
| -t | 사용자 요청 처리용 스레드 수 | 200개 커넥션의 요청을 6개 스레드가 처리 |
| -v, -vv, -vvv | 에러/에러+경고/에러+경고+진단 로그 출력 | MySQL 서버 에러 로그 사용 |
-- 메타 테이블 생성
mysql> SOURCE $[MYSQL_HOME]/share/innodb_memcached_config.sql
-- 플러그인 활성화
mysql> INSTALL PLUGIN daemon_memcached SONAME "libmemcached.so";
| 메타 테이블 | 설명 | 비고 |
|---|
| cache_policies | SET/GET/DELETE/FLUSH 에 대한 캐시 정책 설정 |
| config_options | 레코드가 Memcached 프로토콜로 전송될 수 있도록 설정 | separator : 각 컬럼의 구분자 지정, table_map_delimiter : 키 명시 |
| containers | Memcached 플러그인이 INSERT/SELECT 할 테이블의 정보 관리 |
| 프로토콜 | 설명 | 비고 |
|---|
| 텍스트 | 텍스트 기반, 단순함, 처음 부터 사용 | Endian 고려 불필요 |
| 바이너리 | CPU, 네트워크 대역폭 적게 사용 | |
-- TCP/IP Port 접속
$ telnet localhost 11211
-- 데이터 입력 : key, flag, expire_time, byte_count, value
set matt 0 3600 12
Real MariaDB
-- 데이터 조회 : key
get matt
-- 데이터 삭제 : key
delete matt
-- 종료
quit
-- 유닉스 도메인 소켓 파일 접속
$ nc -U /tmp/memcached.sock
| 인자 | 설명 | 비고 |
|---|
| key | 아이템의 키 | 최대 250 Byte |
| flag | 응용프로그램에서 활용 가능한 4바이트 정수 타입 필드 | |
| expire_time | 캐시 메모리에 유지할 시간 (초단위) | 259200 보다 작으면 상대 시간, 크면 unixtimestamp 로 인식 |
| byte_count | 아이템의 값(value)의 전체 바이트 | 최대 1MB |
| value | 아이템의 값 | |
6.5.3 캐시 정책
- Memcached 플러그인 자체 캐시 메모리 정책 (테이블 단위 설정 가능)
| 정책 | 설명 | 비고 |
|---|
| innodb_only | Memcached 플러그인 자체 캐시 무시 | SET 된 데이터는 즉시 InnoDB 에 영구 저장 |
| cache_only | Memcached 플러그인 캐시만 사용, InnoDB 의 데이터와 무관하게 동작 | MySQL 서버 재기동 시 데이터 초기화 |
| caching | InnoDB 엔진, Memcached 플러그인 협업 동작 | 먼저 Memcached 캐시 메모리 액세스 후 필요시 InnoDB 엔진 액세스 |
| disabled | Memcached 플러그인 안씀 |
6.5.4 사용자 테이블 등록
- 초기화 스크립트(innodb_memcached_config.sql)는 test 데이터베이스 내 test_demo 테이블 생성 후 Memcached 플러그인에 등록.
- Memcached 플러그인 적용 테이블, 키 컬럼 제약 사항
- 키 값에 공백/줄바꿈 포함 불가
- 키 타입은 정수, 문자열 만 가능
- 키 컬럼은 PRIMARY KEY, UNIQUE KEY 생성 필수
- 파티션 테이블 적용 불가
create database my_service;
use my_service;
create table mc_store (
c_key varchar(250) collate Latin1_bin not null,
c_value mediumblob,
c_flag int not null default '0'
c_cas bigint unsigned not null default '0',
c_expire int not null default '0',
PRIMARY KEY (c_key)
) ENGINE = InnoDB STATS_PERSISTENT = 0;
use innodb_memcache;
insert into containers (name, db_schema, db_table, key_columns, value_columns, flags, cas_column, expire_time_column, unique_idx_name_on_key)
values ('default', 'my_service', 'mc_store', 'c_key', 'c_value', 'c_flag', 'c_ca', 'c_expire', 'PRIMARY');
-- containers.name = 'default'
- Memcached 는 테이블 개념 없으나, MySQL 테이블과 매핑 수단 제공
- @@product.A01 : product 테이블의 키가 'A01' 인 아이템
- @@order.A01 : order 테이블의 키가 'A01' 인 아이템
- A01 : default(유일한) 테이블의 키가 'A01' 인 아이템
6.5.5 관련 시스템 변수
| 변수 | 설명 | 비고 |
|---|
| daemon_memcached_option | Memcached 플러그인 기동 옵션 | |
| innodb_api_trx_level | Memcached 플러그인 커넥션 격리 수준 설정 | 0:READ_UNCOMMITED, 1:READ_COMMITED, 2:REPEATABLE_READ, 3:SERIALIZABLE |
| daemon_memcached_{r,w}_batch_size | COMMIT 실행에 필요한 GET/SET 실행 수 | 기본값:1, 중요하지 않은 데이터라면 값을 늘려서 성능 개선 가능 |
| innodb_api_bk_commit_interval | Memcached 플러그인 관련 커넥션 일괄 커밋 Interval | 기본값:5초 |
| innodb_api_enable_binlog | Memcached 플러그인을 통한 변경 내용 바이너리 로그 기록 여부 |
6.6 카산드라 스토리지 엔진
- 원격의 카산드라 서버로 접속하여 SQL 문법으로 데이터 조회 기능 제공
6.6.1 카산드라
- 카산드라 : NoSQL 데이터베이스, P2P 방식으로 노드간 통신 하는 클러스터
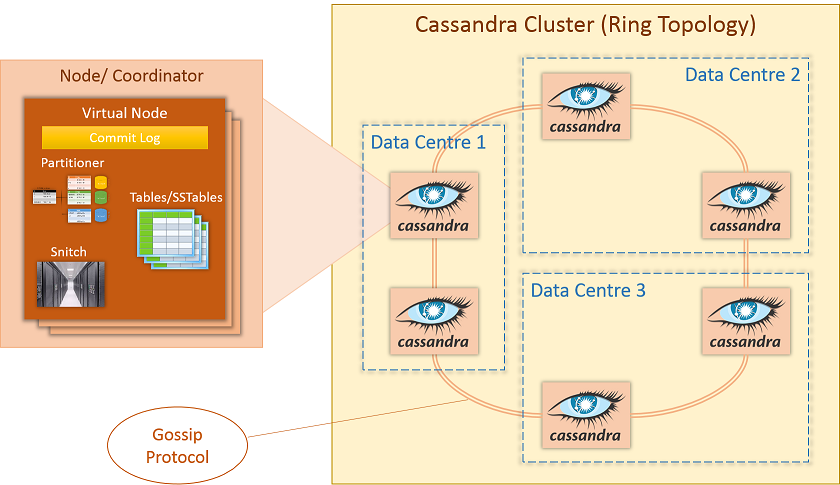
- 클러스상 자신의 위치가 정해져 있고 좌/우/임의 노드와 통신을 유지 하면서 전체 노드 상태 관리
- Gossip : 다른 노드들의 상태를 전파하는 프로토콜
- 클러스터 내 Ring 형태로 노드 존재, 데이터를 1/N 로 나누고 자신의 데이터에 대해서 서비스, 다른 노드 데이터에 대한 Proxy 서비스
- 다차원 Key/Value 로 정보 관리 - (Key(Key/Value))
- 테이블이나 레코드 개념 데이터 조립 가능.
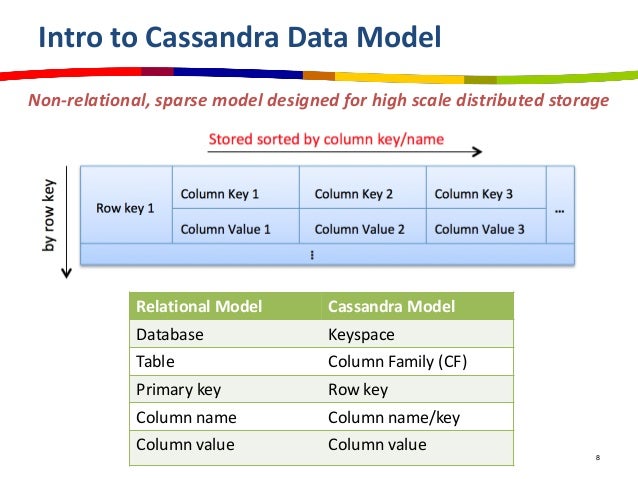
| 오브젝트 | 설명 | 비고 |
|---|
| 키 스페이스 | MariaDB 의 데이터베이스(Schema) | |
| 칼럼 패밀리(CF) | MariaDB 의 테이블, 데이터 집합 정의 | 함께 자주 사용하는 데이터를 모아서 정의 |
| 로우 키 | RDBMS의 Row 의 Primary Key | |
| 칼럼 | 이름-값 쌍으로 관리, 정의 후 사용하는 구조 아님 |
CQL(Cassandra Query Language)
- 조인, 서브쿼리 미지원
- 집합, 정렬은 로우키 + 컬럼이름 만 가능
- 로우키, 컬럼이름 만 WHERE 절 조건 가능
6.6.2 카산드라 스토리지 엔진
- 원격 서버에 있는 카산드라 클러스터 데이터에 대한 뷰 제공
INSTALL PLUGIN cassandra SONAME 'ha_cassandra.so';
-- my.cnf [mysqld]
plugin-load = ha_cassandra.so
$ cqlsh
create keyspace cassandra_se
... with strategy_class = 'org.apache.cassandra.locator.SimpleStrategy'
... and strategy_options:replication_factor='1';
use cassandra_se;
create columnfamily cf_friends (
... uid varchar primary key,
... friend_uid varchar) with compact storage;
insert into cf_friends (uid, friend_uid) values ('matt', 'pitt');
insert into cf_friends (uid, friend_uid) values ('matt', 'pott');
select * from cf_friends;
-- 카산드라 컬럼 패밀리와 컬럼 이름 및 데이터 타입 일치 필요
$ mysql
create table cass_friends (
uid varchar(64) primary key,
friend_uid varchar(64)
) ENGINE = cassandra THRIFT_HOST = '192.168.0.1' KEYSPACE='cassandra_se' COLUMN_FAMILY='CF_FRIENDS';
-- thrift_host : 테이블 별 접속 카산드라 클러스터 설정
-- cassandra_default_thrift_host : 전체 테이블 공통 카산드라 클러스터 설정||
insert into cass_friend (uid, friend_uid) values ('toto', 'pitt');
insert into cass_friend (uid, friend_uid) values ('toto', 'pott');
select * from cass_friends where uid = 'toto';
6.7 CONNECT 스토리지 엔진
6.7.1 CONNECT 스토리지 엔진 설치
INSTALL PLUGIN connect SONAME 'ha_connect.so';
SHOW ENGINES;
SHOW PLUGINS;
6.7.2 오라클 RDBMS 테이블 연결
-- DSN (ORCL) 등록
-- 테이블 생성
create table ora_emp engine = connect
table_type = odbc tabname = 'EMP' connection = 'DSN=ORCL;UID=SCOTT;PWD=TIGER'
srcdef='SELECT empno, ename, mgr, level from emp connect by prior empno = mgr;';
select * from ora_emp;
-- engine_condition_pushdown = 'ON' 설정 시 WHERE 절 내용이 원격 DBMS에 전달 됨 (기본값 : OFF)
SET optimizer_switch='engine_condition_pushdown = ON';
6.7.3 my.cnf 설정 파일 연결
create table mysql_config (
section varchar(64) flag = 1,
keyname varchar(64) flag = 2,
value varchar(256)
) engine = connect table_type = ini file_name = '/etc/my.cnf' option_list='Layout=Row;seclen=90000';
select * from mysql_config;
select * from mysql_config where section = 'mysqld' and keyname = 'port';
6.7.4 운영체제의 디렉터리 연결
create table temp_dir (
path varchar(@56) not null flag = 1,
fname varchar(256) not null,
ftype char(4) not null,
size double(12,0) not null flag = 5
) engine = connect table_type = dir file_name = '/data/*' option_list = 'subdir = 1';
-- subdir = 1 : 서브디렉터리 까지 조회
select * from temp_dir;
6.8 시퀀스 스토리지 엔진
- 순차적 번호를 주어진 조건에 맞게 메모리 테이블로 생성
INSTALL PLUGIN sequence SONAME 'ha_sequence.so';
6.8.1 시퀀스 스토리지 엔진 기본 사용법
- 테이블 이름 패턴
- seq_<시작값>_to_<종료값>
- seq_<시작값>_to_<종료값>_step_<건너뛸 값의 개수>
- 특성
- 음수 불가(UNSIGNED 타입), 반복 불가
select * from seq_1_to_5;
select * from seq_5_to_1;
select * from seq_1_to_5_step_2; -- 1,3,5
select * from seq_5_to_1_step_2; -- 5,3,1
select * from 'seq_-5_to_1' limit 4; -- 안됨
select -1 * convert(seq, signed integer) as seq from seq_5_to_1; -- -5 ~ -1
6.8.2 누락된 번호 찾기
create table seq_test (seq int) engine = InnoDB;
insert into seq_test values (1), (2), (3), (4), (5), (8), (9), (10);
select s.seq from seq_1_to_10 s left outer join seq_test t on t.seq = s.eq where t.seq is null;
6.8.3 순차적으로 조합된 번호 쌍 생성
select s1.seq, s2.seq from seq_1_to_2 s1, seq_1_to_3 s2 order by s1,seq, s2.seq;
6.8.4 배수 또는 공배수 찾기
-- 100 보다 작은 3의 배수
select seq from seq_3_to_100_step_3;
-- 100보다 작은 3과 의 공배수
select s1.seq from seq_5_to_100_step_5 s1, seq_3_to_100_step3 s2 on s1.seq = s2.seq;
6.8.5 순차적인 알파벳 생성
select char(seq) as seq_char from (
-- 소문자
(select seq from seq_97_to_122 l)
union all
-- 대문자
(select seq from seq_65_to_90 u)
union all
-- 숫자
(select seq from seq_48_to_57 d)
) seq_ch;
6.8.6 순차적인 날짜 생성
select date_add('2014-01-29', interval s.seq - 1 day) as seq_dat
from seq_1_to_30 s;
6.8.7 데이터 복제 가공 (copy_t)
select case when seq = 1 then e.emp_no else 'MIN_HIREDATE' end emp_no,
case when seq = 1 then e.first_name else '' end first_name,
case when seq = 1 then e.hire_date else min(e.hire_date) end hire_date
from employees e, seq_1_to_2 s
where e.emp_no between '10001 and 10020
group by case when seq = 1 then e.emp_no else seq end;
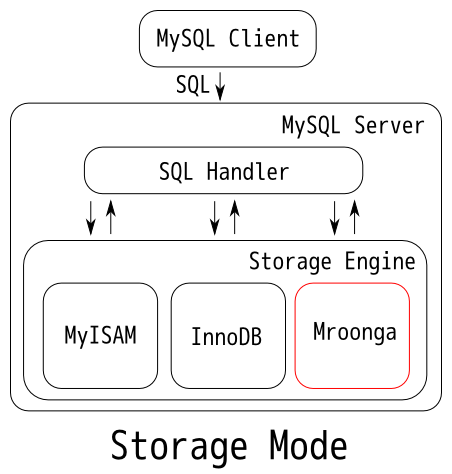
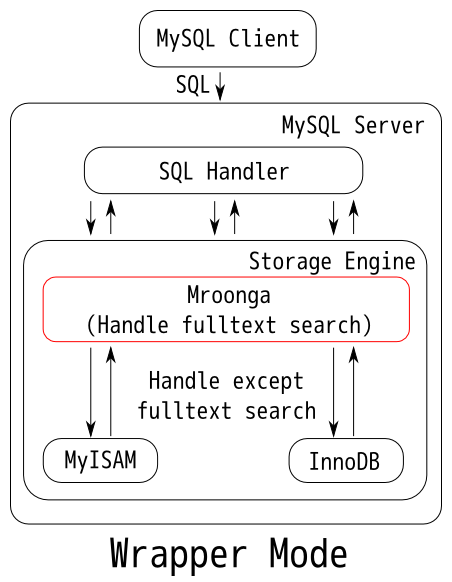
6.9 Mroonga 전문 검색 스토리지 엔진
- 일본 DeNA 에서 개발한 컬럼 기반 전문 검색 엔진
- 두가지 실행 모드 : 스토리지 엔진 / 래퍼(Wrapper) - 실제 데이터는 InnoDB 스토리지 엔진에 저장하고 검색용 전문 인덱스만 Mroonga 스토리지 엔진에 저장
| 스토리지 모드 | 래퍼 모드 |
|---|
 |  |
6.9.1 인덱스 알고리즘
6.9.1.1 구분자(Stopword) 방식
- 공백, 탭, 띄어쓰기, 마침표 같은 문장 기호, 한국어의 조사 등을 구분자 목록에 정의 하고, 구분자를 이용하여 키워드를 분석 후 인덱스 생성
- 매우 자주 씌이는 단어를 구분자에 넣기 도 함
- MySQL 내장 전문 검색 엔진 채택 방식
6.9.1.2 n-Gram 방식
- 전문을 무조건적으로 몇 글자씩 잘라서 인덱싱
- 인덱싱 알고리즘이 복잡하고, 인덱스가 상대적으로 큼
- 2-Gram(Bi-Gram) 많이 사용
6.9.1.3 구분자와 n-Gram의 차이
SELECT * FROM tb_test WHERE MATCH(doc_body) AGAINST ('아이폰' IN BOOLEAN MODE);
| doc_body | 구분자 | n-Gram |
|---|
| 중고 아이폰 3G 팝니다. | O | O |
| 아이폰 3Gs 구해 봅니다. | O | O |
| 애플아이폰 3Gs 싸게 팝니다. | X | O |
6.9.2 Mroonga 전문 검색 엔진 설치
INSTALL PLUGIN mroonga SONAME 'ha_mroonga.so';
CREATE FUNCTION last_insert_grn_id RETURNS INTEGER SONAME 'ha_mroonga.so';
CREATE FUNCTION mroonga_snippet RETURNS STRING SONAME 'ha_mroonga.so';
6.9.3 Mroonga 전문 검색 엔진 사용
create table tb_test (
id int primary key auto_increment,
content varchar(255),
fulltext index fx_content (content) comment 'parser "TokenBigramIgnoreBlankSplitSynbolAlphaDigit"'
) ENGINE = mroonga COMMENT = 'engine "innodb"' DEFAULT CHARSET utf8mb4;
INSERT INTO TB_TEST (CONTENT) VALUES ('오늘은 MariaDB 공부를 했습니다. 내일도 MariaDB 공부를 할 것입니다.");
INSERT INTO TB_TEST (CONTENT) VALUES ('오늘은 MariaDB 공부를 했지만, 내일은 MariaDB 공부를 할 것입니다.");
SELECT *, MATCH (content) AGAINST ('MariaDB' IN BOOLEAN MODE) AS SCORE
FROM tb_test
WHERE MATCH (content) AGAINST ('MariaDB' IN BOOLEAN MODE)
ORDER BY MATCH (content) AGAINST ('MariaDB' IN BOOLEAN MODE) DESC;
TokuDB
- Fractal Tree 기반의 스토리지 엔진
- 온라인 DDL 기능 제공
- Fractal Tree 및 압축 효율로 Disk I/O 를 효과적으로 줄여서 Insert 성능 좋음

HandlerSocket
- DeNA 에서 개발한 단순 읽기 최적 플러그인
- 파싱/옵티마이즈 단계를 없애고 Handler API 직접 호출 하는 방식
- Primary Key 로만 데이터 접근 하는 경우와 같이 단순한 쿼리라면 파서/옵티마이저 단계가 오버헤드일 수 있음
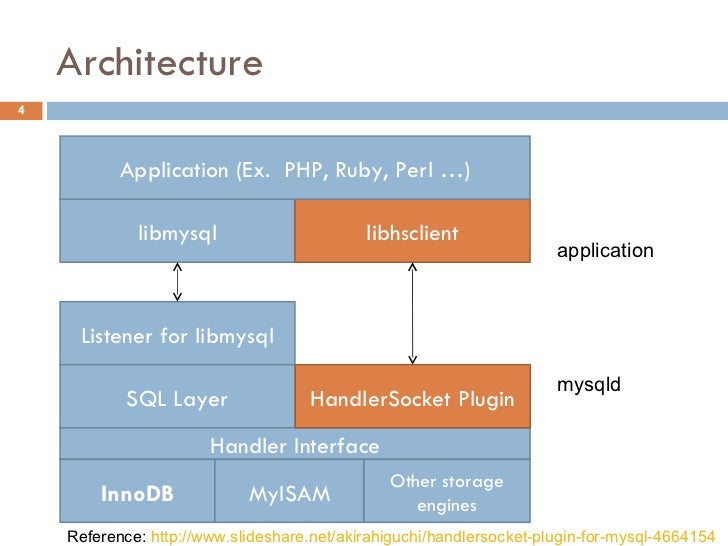
- 쓰기 성능

- 읽기 성능

FederatedX
- 원격 데이터베이스 내 테이블을 로컬에 있는 것 처럼 접근 가능
- 2-Phase Commit 일관성 제공
- 테이블 파티션 별 다른 서버 연결 가능
create server 'remote' foreign data wrapper 'mysql' options
(host 'remote',
database 'target_db',
user 'appuser',
password 'passwd123',
port 3306,
socket ''
owner 'appuser');
SELECT * FROM mysql.servers;
-- 원격/로컬 이름이 같음
create table tb_remote (
col01 bigint(20) not null,
col02 bigint(20) not null,
col03 varchar(20) not null default '',
primary key (col01)
) engine = federated connection = 'remote';
-- 원격/로컬 이름이 다름
create table tb_local (
col01 bigint(20) not null,
col02 bigint(20) not null,
col03 varchar(20) not null default '',
primary key (col01)
) engine = federated connection = 'mysql://appuser:passwd123@remote:3306/target_db/tb_remote';