5.1 풀 테이블 스캔
- 1. 테이블의 레코드 건수가 너무 작을 때
- 2. WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 3. 옵티마이저 판단하에 조건 일치 레코드 건수가 너무 많은 경우
- MariaDB 에는 풀 테이블 스캔을 실행할 때 한꺼번에 몇 개씩 페이지를 읽어올지 설정하는 변수는 없다.
- 리드 어헤드 : 어떤영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 미리 디스크에서 읽어 XtraDB의버퍼
풀에 가져다 둔다.
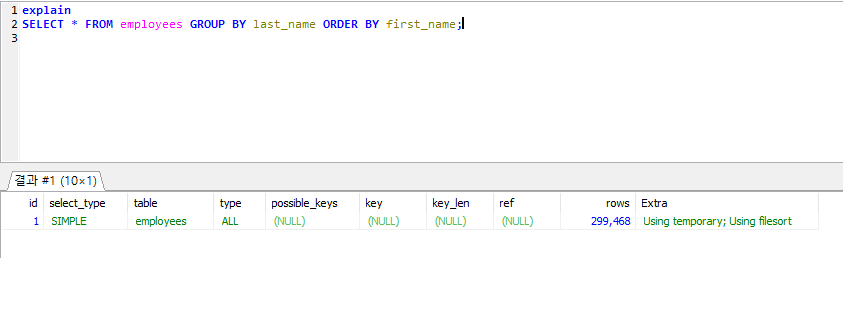
5.2.1 ORDER BY 처리 (Using filesort)
정렬 처리
INDEX 이용
- DML처리시 인텍스가 정렬돼 있으므로 빠르지만 부가적인 인덱스 추가 및 디스크 공간 필요.
Filesort
- 인덱스를 생성하지 않으므로 인덱스의 단점이 보완되지만 레코드가 많으면 느려진다.
인덱스를 이용하는 정렬이 힘든 경우.
- 1. 정렬기준 많음
- 2. Group BY, DISTINCT
- 3. 임시테이블 결과(UNION)
- 4. 랜덤한 레코드
5.2.1 소트 버퍼 (Sort buffer)
- 1. 정렬 처리시에 필요한 메모리 공간으로 정렬이 완료되면 시스템으로 반납됨.
- 2. sort_buffer_size, aria_sort_buffer_size 변수로 설정가능.
- 3. 멀티머지(Multi merge)횟수를 줄이기 위해 소트버퍼를 크게 해도 차이는 없음.(저자추천 256KB~512KB)
- 4. 소트버퍼는 세션메모리 영역으로 작업이 많거나 커넥션이 많으면 OOM-Killer에 의해 종료당 할 수 있음.
5.2.2 정렬 알고리즘
SQL 예시
SELECT emp_no, first_name, last_name
FROM employees
ORDER BY first_name;
1. 싱글패스(single pass)
- MySQL 5.0이후 최신 버전에 도입됨.
- emp_no, first_name, last_name 모두 읽어 정렬.
- 건수가 작을 때 유리.
2. 투패스(two pass)
- 정렬에 필요한 first_name 칼럼과 키인 emp_no만 읽어서 정렬을 수행하고 다시 last_name 읽음.
- 건수가 클 때 유리.
- 팁 : 따라서 컬럼을 항상 지정하는 습관이 좋다. *는 자제하도록 하자.
5.2.3 정렬의 처리 방식
5.2.3.1 인덱스를 사용한 정렬
SELECT * FROM employees e, salaries s
WHERE 1=1
AND s.emp_no=e.emp_no
AND e.emp_no BETWEEN 100002 AND 100020
ORDER BY e.emp_no;
계획 코멘트 없음
- 1. 반드시 ORDER BY에 명시된 칼럼이 제일 먼저 읽는 테이블(조인이 사용된 경우 드라이빙 테이블)에 속하고,ORDER BY의 순서대로 생성된 인덱스가 있어야 한다.
- 2. 완벽한 조건을 요구하는 만큼 처리는 빠르며 유일한 스트리밍 방식이다.
- 팁 : 인덱스 사용한다고 어차피 정렬된다는 생각에 ORDER BY를 제외하면 안된다.
경험상(본인) 기계는 매우 멍청하다. 정확한 지정이 필요하다.
5.2.3.2 드라이빙 테이블만 정렬
SELECT *
FROM employees e, salaries s
WHERE 1=1
AND s.emp_no=e.emp_no
AND e.emp_no BETWEEN 100002 AND 100010
ORDER BY e.last_name;
Using filesort
- 1. emp_no BETWEEN 100002 AND 100010 키 활용으로 범위 검색
- 2. last_name로 정렬.(드라이빙 테이블)
- 3. 차례대로 조인하며 결과 도출.
- 4. 버퍼링 방식.
5.2.3.3 임시 테이블을 이용한 정렬
SELECT *
FROM employees e, salaries s
WHERE 1=1
AND s.emp_no=e.emp_no
AND e.emp_no BETWEEN 100002 AND 100010
ORDER BY s.salary;
Using filesort, Using temporary
- 1. ORDER BY s.salary가 드리븐 테이블 컬럼이므로 일단 조인 후 임시 테이블에서 정렬.
- 2. 버퍼링 방식.
5.2.3.4 정렬 방식의 성능 비교
- 1. 인덱스 활용하도록 유도. 최소한 드라이빙 테이블만 정렬해도 되는 수준으로 유도.
- 2. 업무설계시 애초에 테이블을 잘 만드는 것이 더 좋을 것으로 보임.
5.2.4 ORDER BY .. LIMIT n 최적화
SELECT emp_no, first_name, last_name
FROM employees
WHERE 1=1
AND emp_no BETWEEN 10001 AND 10900
ORDER BY last_name
LIMIT 10;
- 1. 우선순위 큐(Priority Queue) 한다는 말이다.
- 2. 900개 정렬하는 것이 아니라 큐에 들어오는 10개만 정렬한다.
5.2.5 정렬 관련 상태 변수
- 1. Sort_merge_passes는 멀티 머지 처리 횟수
- 2. Sort_range는 인덱스 레인지 스캔을 통해 검색된 결과에 대한 정렬 작업 ?수.
- 3. Sort_scan은 풀 테이블 스캔을 통해 검색된 결과에 대한 정렬 작업 횟수.
- 4. Sort_scan과 Sort_range는 둘 다 정렬작업 횟수를 누적하고 있는 상태 값.
- 5. Sort_rows는 지금까지 정렬한 전체 레코드 건수를 의미.
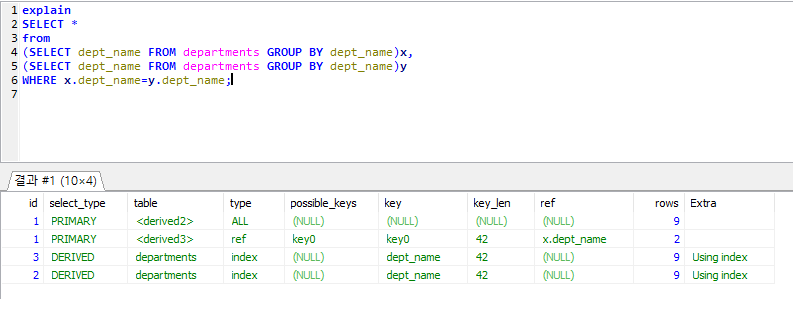
5.3 GROUP BY 처리
5.3.1 인덱스 스캔을 이용하는 GROUP BY(타이트 인덱스 스캔)
- 조인의 드라이빙 테이블에 속한 칼럼만 이용해 그룹핑할 때
5.3.2 루스(loose) 인덱스 스캔을 이용하는 GROUP BY
- 1. 단일 테이블의 GROUP BY에서만 가능.
- 2. 인덱스의 유니크한 값이 적을수록 향상.
- 3. 임시 테이블 불필요.
- 4. 집합함수시 불가.(MIN, MAX는 가능)
- 5. GROUP BY 의 칼럼이 인덱스 구성 칼럼의 왼쪽부터 일치해야 함.
- 6. SELECT 절의 칼럼이 GROUP BY 와 일치해야 함.
5.3.3 임시 테이블을 사용하는 GROUP BY
5.4 DISTINCT 처리
5.4.1 SELECT DISTINCT
- 1. 정렬이 보장되지 않음.
- 2. 레코드(튜플)를 유니크 하게 함.
5.4.2 집합 함수와 함께 사용된 DISTINCT
SELECT DISTINCT first_name, last_name
FROM employees A
WHERE 1=1
AND A.emp_no BETWEEN 10001 AND 10200
;
-- 목록나옴
SELECT COUNT(DISTINCT first_name), COUNT(DISTINCT last_name)
FROM employees A
WHERE 1=1
AND A.emp_no BETWEEN 10001 AND 10200
;
--188 184
SELECT COUNT(DISTINCT A.first_name, A.last_name)
FROM employees A
WHERE 1=1
AND A.emp_no BETWEEN 10001 AND 10200
;
--200
5.5 임시 테이블(Using temporary)
- 1. 임시 테이블이 메모리를 사용시 : MEMORY 스토리지 엔진
- 2. 임시 테이블이 디스크 저장시 : Aria 스토리지 엔진
5.5.1 임시 테이블이 필요한 쿼리
- 1. ORDER BY와 GRCXJP BY에 명시된 칼럼이 다른 쿼리
- 2. ORDER BY나 GROJP BY에 명시된 칼럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- 3. DISTINCT와 ORDER BY가 동시에 쿼리에 존재하는 경우 또는 DISTINCT가 인덱스로 처리되지 못하는 쿼리
- 4. UNION이나 UNION 이STINCT가사용된쿼리(select_type 칼럼이 UNION RESULT인 경우)
- 5. UNION ALL이 사용된 쿼리(select_type 칼럼이 UNION RESULT인 경우)
- 6. 쿼리의 실행 계획에서 select_type이 DERIVED인 쿼리
5.5.2 임시 테이블이 디스크에 생성되는 경우(Aria 스토리지 엔진을 사용)
- 1. 임시 테이블에 저장해야 하는 내용 중 BLOB(Binary Large Object)나 TEXT와 같은 대용량 칼럼이 있는 경우
- 2. 임시 테이블에 저장해야 하는 레코드의 전체 크기나 UNION이나 UNION ALL에서 SELECT되는 칼럼 중에서 길이가 512바이트 이상인 크기의 칼럼이 있는 경우
- 3. GROUP BY나 DISTINCT 칼럼에서 512바이트 이상인 크기의 칼럼이 있는 경우
- 4. 임시 테이블에 저장할 데이터의 전체 크기(데이터의 바이트 크기)가 tmp_table_size 또는 max_heap_table_size 시스템 설정 값보다 큰 경우
- 자세히 되어 있지만 결국 데이터가 크면 디스크에 생성된다는 것이다. 단, 4번처럼 초기 데이터가 크지 않으면 처음엔 메모리에 생성된다.
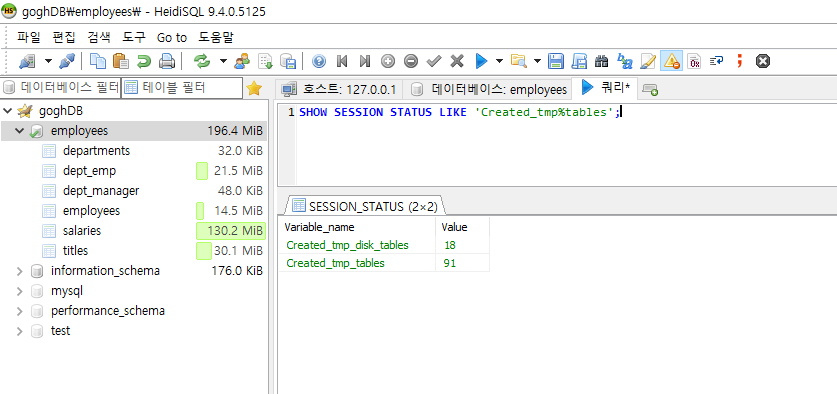
5.5.3 임시 테이블 관련 상태 변수
- 1. Created_tmp_tables 메모리, 디스크 임시 테이블 모두 누적한 값.
- 2. Created_tmp_disk_tables 디스크 임시 테이블 누적 값.
5.5.4 인덱스를 가지는 내부 임시 테이블
5.5.5 내부 임시 테이블(Internal Temporary Table)의 주의사항
- 1. 인덱스를 활용하려 노력하고 대상 레코드를 적게 만들자.
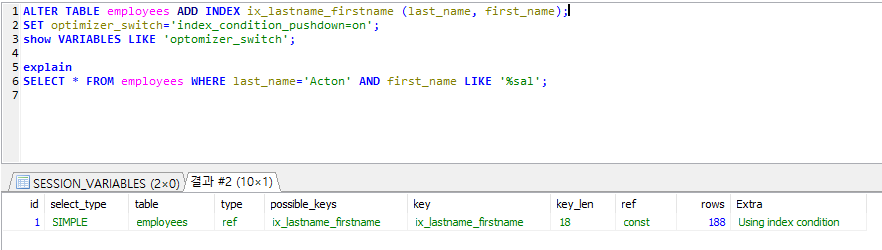
5.6 인덱스 컨디션 푸시다운(Index Condition Pushdown, ICP)
- 1. 인덱스에 포함된 first_name 칼럼을 이용할지 또는 테이블의 first_name 칼럼을 이용할 지가 결정
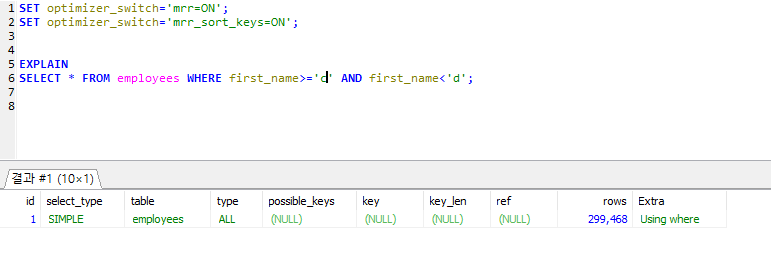
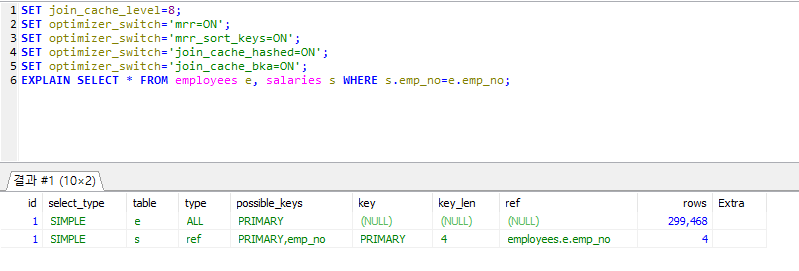
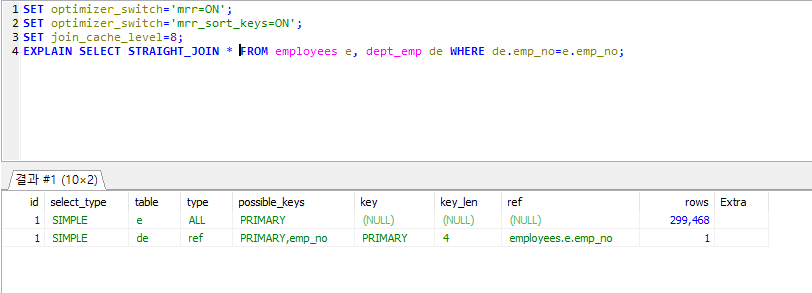
5.7 멀티 레인지 리드(Multi Range Read)
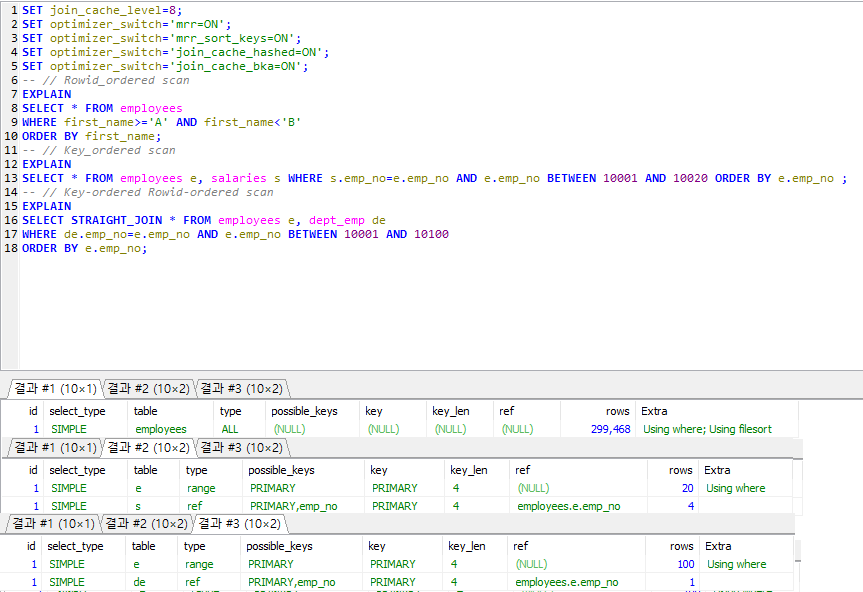
- 1. 인덱스 튜플을 적정한 양만큼 읽은 후 그 튜플들을 Rowld 순서대로 정렬해서 데이터 파일의 레코드를 읽는 것.
5.7.1 Rowid 기준 정렬
5.7.2 Key 기준 정렬
5.7.3 Rowid와 Key 기준 정렬
5.7.4 MRR 최적화와 정렬
5.7.5 MRR 최적화 주의 사항
- 1. mrr_buffer_size : 너무 작으면 MRR 여러번 실행되고 너무 크면 메모리 낭비
- 2. join_cache_space_limit : 조인버퍼 설정으로 메모리 낭비 주의
- 3. Handler_mrr_init : 얼마나 MRR 최적화가 사용되었는가
- 4. Handler_mrr_key_refills : Key-ordered scan이 사용될 때 몇 번이나 MRR 버퍼가 다시 채워졌는가
- 5. Hand ler_m rr_rowid_refills : Rowid-ordered scan이 사용될 때 몇 번이나 MRR 버퍼가 다시 채워졌는가