데이터베이스 튜닝 전문가라면 당연히 DBMS 내부 아키텍처에 대한 지식은 필수다.
성능 튜닝 원리를 이해하는 데 도움이 되는 수준까지 중요 요소에 대한 원리를 설명 한다.
핵심 내용 : 6절(문장수준 읽기 일관성), 7절(Consistent vs. Current 모드 읽기)
- 01. 기본 아키텍처
- 02. DB 버퍼 캐시
- 03. 버퍼 Lock
- 04. Redo
- 05. Undo
- 06. 문장수준 읽기 일관성 (Statement-Level Read Consistency)
- 07. Consistent vs. Current 모드 읽기
- 08. 블록 클린아웃
- 09. Snapshot too old
- 10. 대기 이벤트
- 11. Shared Pool
01. 기본 아키텍처
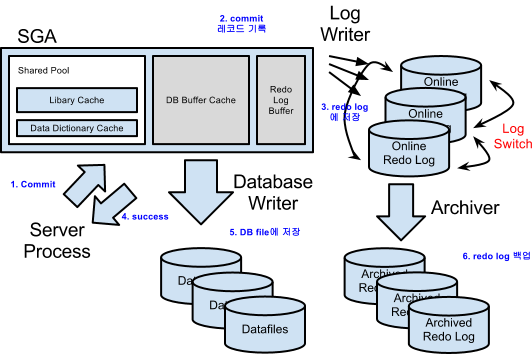
- 오라클은 데이터베이스와 이를 액세스하는 프로세스 사이에 메모리 캐시 영역(SGA)이 있다.
- 디스크 I/O 에 비해 메모리 캐시 I/O 는 매우 빠르다.
- 많은 프로세스가 동시에 데이터를 액세스 하기 때문에 사용자 데이터를 보호하는 Lock 과 공유 메모리 영역인 SGA 에 위치한 데이터 구조 액세스를 직렬화 하기 위한 Latch도 필요.
- 오라클은 블록 단위로 I/O 하며, DBWR/CKPT 가 주기적으로 캐시-데이터파일 동기화 수행.
- Database : 디스크에 저장된 데이터 집합(Datafile, Redo Log File, Control File...)
- Instance : SGA + Process
- Server Process : 사용자 명령 처리
- Dedicated Server Process : 클라이언트를 위한 전용 프로세스, 사용자에게 필요한 서비스 제공 (SQL 파싱, 최적화, 실행, 블록 읽기, 읽은 데이터 정렬, 네트워크 전송)
- 스스로 처리하지 못하는 일을 만나면 OS, I/O 서브시스템, Background Process 등에 신호를 보내 대신 일을 처리하도록 요청
- Background Process : 뒤에서 역할 수행
- 오라클 접속할 시 내부 처리 과정
- 리스너에 연결 요청 시 프로세스를 띄우고(Fork) 메모리(PGA)를 할당 한다.
- 비용이 큰 작업 이므로 성능을 위해 Connection Pool 을 통해 **재사용** 필수
- Connection Pool
- 하나의 데이터베이스를 엑세스 하는 다중 인스턴스로 구성
- 과거 공유 디스크 방식, 현재 공유 캐시 방식
- 글로벌 캐시 개념 : 로컬 캐시에 없는 데이터 블록을 원격 노드에서 전송 받음
- 다른 인스턴스의 Dirty 버퍼도 Interconnect 를 통해 주고 받으며 갱신 수행, OPS 는 디스크로 쓰기 작업 선행 필요 (Ping)
- SQL Trace - 정확한 이해 필요(query, current)
| 항목 | 설명 |
|---|
| count | 수행 횟수 |
| cpu | CPU 시간(초) |
| elapsed | 수행 시간(초) |
| disk | Physical(Disk) Read Block Count / physical reads |
| query | Consistent Read Block Count / consistent gets |
| current | Current(Dirty) Read Block Count / db block gets |
| rows | Record Count |
02. DB 버퍼 캐시
- 메모리 캐시 영역(SGA) 중 사용자 데이터가 거쳐 가는 부분
(1) 블록 단위 I/O
오라클에서 I/O는 블록(Block) 단위로 이뤄짐
- single block read / multi block read (Full Scan, DBWR)
- 하나 레코드의 하나 컬럼만 읽어도 속한 블록 전체를 읽음
- 블록 개수
- SQL 성능을 좌우하는 가장 중요한 성능 지표
- 옵티마이저의 판단에 가장 큰 영향을 미침(INDEX SCAN / FULL TABLE SCAN)
(2) 버퍼 캐시 구조
- 바둑판처럼 생긴 버퍼 캐시에서 읽고자 하는 블록을 어떻게 찾는가? (해시 테이블)
- 해시 테이블(해시 맵)은 SGA 내에서 가장 많이 사용되는 자료구조.
- 주소록과 유사 - 성씨가 같은 고객은 같은 페이지(해시 버킷)에 정렬 없이 관리
- 해시 버킷 내에서 스캔 방식 사용 (성능을 위해 각 버킷 내 엔트리 개수 일정 수준 유지 필요)
- 버퍼 캐시도 해시 테이블 구조로 관리 됨 - 해시 키 값 : DBA(Data Block Address)
- 해시 함수에 DBA 입력해 리턴 받은 해시 값이 같은 블록들을 같은 해시 버킷에 연결 리스트(해시 체인)로 구조화
- 필요한 블록 주소를 해시 버킷에서 스캔 후 있으면 읽고, 없으면 디스크에서 읽어 해시 체인에 연결 후 읽음
- 버퍼 헤더만 해시 체인에 연결 됨, 데이터 값은 포인터를 이용해 버퍼 블록을 찾아 얻게 됨
(3) 캐시 버퍼 체인
- 각 해시 체인은 Latch 에 의해 보호 됨
- DB 버퍼 캐시는 공유 메모리 영역에 존재 하므로 동시 액세스 가능 하며, 액세스 직렬화(Serialization) 메커니즘 필요 - Latch
- Latch 를 획득한 프로세스만 그 Latch 에 의해 보호되는 자료구조 진입 허용
- cache buffers chains - 해시 체인에 버퍼 블록을 스캔/연결/해제 작업 보호, 하나의 Latch 가 여러 해시 체인을 동시 보호
| DB버전 | Latch 갯수 |
|---|
| 9i | 241 개 |
| 10g | 394 개 |
| 11g | 496 개 |
| 구분 | 파라미터 | 책 | 실제(11g) |
|---|
| 해시 버킷 개수 | _db_block_hash_buckets | 2,097,152 | 8,388,608 |
| 래치 개수 | _db_block_hash_latches | 65,536 | 262,144 |
| 래치 당 해시 버킷 수 | - | 32 | 32 |
| 블록 버퍼 개수 | _db_block_buffers | 836,684 | 3,084,990 |
| 해시 버킷 개수 / 블록 버퍼 개수 | - | 2.5 | 2.7 |
- 하나의 해시 체인에 하나의 버퍼만 달리는 것이 목표 임 - 해시 체인 스캔 비용 최소화
- 블록 버퍼 대비 해시 버킷 개수가 충분히 많아야 함 - 2.5배 ?
- 9i 부터 읽기 전용 작업 시 cache buffers chains Latch 를 Share 모드 획득 가능
- SELECT (X) , 필요한 블록을 찾기 위한 해시 체인 스캔 (O)
- 버퍼 헤더에 Pin 설정 시 cache buffers chains Latch 사용
- Share 모드 획득 후, 체인 구조 변경 혹은 버퍼 헤더에 Pin 설정 시 Exclusive 모드로 변경
(4) 캐시 버퍼 LRU 체인
- LRU(Least Recently Used) 알고리즘
- 사용 빈도 높은 블록들 위주로 버퍼 캐시가 구성 되도록 함
- 모든 버퍼 블록 헤더를 LRU 체인에 연결
- 사용 빈도 순으로 위치 이동
- Free 버퍼 필요시 액세스 빈도가 낮은 블록을 우선 밀어냄 (자주 액세스 되는 블록이 캐시에 더 오래 남게 됨)
- cache buffers lru chain Latch 로 보호
- 모든 버퍼 블록은 둘중 하나의 LRU 리스트에 속함
- Dirty 리스트 : 캐시 내 변경 됨, 아직 디스크에 반영 안된 블록 관리 (LRUW 리스트)
- LRU 리스트 : Dirty 리스트 외 나머지 블록 관리
- 모든 버퍼 블록은 셋중 하나의 상태임
- Free 버퍼 : 빈 상태 혹은 데이터 파일과 동기화 된 상태, 언제든 덮어 쓸 수 있음, 변경 시 Dirty 버퍼 됨
- Dirty 버퍼 : 변경 되어 데이터 파일과 동기화 필요 상태, 동기화 되면 Free 버퍼 됨
- Pinned 버퍼 : 읽기/쓰기 작업 중인 버퍼 블록
03. 버퍼 Lock
(1) 버퍼 Lock 이란?
- 하나의 cache buffers chains Latch 에 여러(32) 해시 체인이 보호 되고 있음 (Latch 경합)
- 동시에 버퍼 블록 접근 할 경우 정합성 문제 발생 가능 (직렬화 필요)
- 버퍼 블록을 찾으면 버퍼 Lock 설정 후 Latch 해제 (읽기: Share 모드, 변경: Exclusive 모드)
- SELECT 문 도 블록 클린아웃 필요 시 Exclusive 모드 설정
- 이미 Exclusive 모드로 점유 된 상태라면 버퍼 헤더의 Lock 대기자 목록(Waiter List) 등록 후 Latch 해제 - buffer busy waits, 선행 버퍼 Lock 해제시 버퍼 Lock 획득
- 버퍼 블록 Lock 해제 시 Latch 다시 획득 (한개 블록 읽기가 이렇게 고비용)
한번 래치 획득 읽기
블록 읽을 때 대부분 두번 래치 획득 (찾고 Pin 설정, 다쓰고 Pin 해제), 하지만 몇몇 오퍼레이션은 한번만 래치 획득 - consistent gets - examination
(2) 버퍼 핸들
- 버퍼 Lock 은 버퍼 사용중을 표시 (버퍼 헤더에 Pin 설정 / Pinned 버퍼)
- 변경 시 하나의 프로세스만 Pin 가능, 읽기는 동시에 Pin 가능
- 버퍼 핸들(Buffer Handle)을 버퍼 헤더에 있는 소유자 목록(Holder List)에 연결 시켜 Pin 설정
- cache buffer handles 래치
- 각 프로세스 마다 _db_handles_cached(5) 개수 만큼 버퍼 핸들 미리 할당
- 미리 할당된 갯수 이상의 버퍼 핸들 얻을 때 필요
- 시스템 전체 버퍼 핸들 개수 : _db_handles = processes * _db_handles_cached
(3) 버퍼 Lock의 필요성
- 한개 레코드 갱신도 블록 단위로 I/O를 수행
- 정합성 유지를 위해 블록 자체로의 진입을 직렬화 해야 함
- 블록 내 10개 레코드를 읽는 순간 다른 프로세스에 의해 변경이 발생 하면 잘못된 결과를 얻게 됨
- 로우 단위 Lock 설정 도 레코드 속성 변경 이므로 동시 수행은 문제가 됨
- 블록 헤더 변경(블록 SCN, ITL 슬롯 등)도 동시 수행은 문제가 됨 (Lost Update 발생)
Consistent 모드 읽기
쿼리 SCN 과 블록 SCN 을 비교해 읽어도 되는 블록인지 확인 하면서 읽기 (블록 읽는 도중 블록 내용 변경 대응 불가)
Pin 된 버퍼 블록
alter system flush buffer_cache; 에도 밀려 나지 않는다.
alter system set events 'immediate trace name flush_cache'; (9i)
(4) 버퍼 Pinning
- 버퍼를 읽고 나서 버퍼 Pin을 즉각 해제하지 않고 데이터베이스 Call이 진행되는 동안 유지하는 기능
- 래치 획득 없이 버퍼를 읽으므로 논리 읽기 횟수가 감소 됨
- 버퍼 Pinning 발생 지점
- 인덱스를 스캔하면서 테이블을 액세스할 때의 인덱스 리프 블록 (전통적)
- 인덱스로부터 액세스되는 하나의 테이블 블록 (8i)
- NL 조인 시 Inner 테이블을 Lookup 하기 위해 사용되는 인덱스 루트 블록 (9i)
- Index Skip Scan 시 브랜치 블록 (9i)
- NL 조인 시 Inner 테이블의 루트 외 다른 인덱스 블록 (11g)
- DML 수행 시 Undo 블록
| 블록 액세스 방법 | 증가 수치 |
|---|
| 래치 획득 후 | session logical reads |
| 버퍼 Pinning 후 | buffer is pinned count |
- 버퍼 Pinning 은 하나의 데이터베이스 Call (Parse, Execute, Fetch) 내에서만 유효
- 버퍼 Pinning 을 통한 블록 I/O 감소효과는 SQL 튜닝의 중요 부분
- Reorg 를 통한 인덱스 클러스터링 팩터 (버퍼 Pinning) 개선 가능
04. Redo
- 데이터/컨트롤 파일의 모든 변경 사항을 하나의 Redo 로그 엔트리로서 Redo 로그에 기록
| Redo 구분 | 속성 |
|---|
| Online | Redo 로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일, 최소 두 개 구성, 라운드 로빈 로그 스위칭 발생 |
| Archived | Online Redo 로그 파일이 재사용 되기 전 다른 위치로의 백업본 |
Redo 목적
1. Database Recovery
2. Cache Recovery (Instance Recovery)
3. Fast Commit
- Media Fail 발생 시 데이터베이스 복구 위해 Archived Redo 로그 사용
- 인스턴스 비정상 종료 시 휘발성의 버퍼 캐시 데이터 복구 위해 Redo 로그 사용
- 인스턴스 재기동 시 Online Redo 로그의 마지막 Checkpoint 이후 트랜잭션의 Roll Forward (버퍼 캐시에만 존재했던 변경 사항이 Commit 여부와 관계 없이 복구 됨)
- Undo 데이터를 이용해 Commit 안된 트랜잭션을 Rollback (Transaction Recovery)
- 데이터 파일에는 Commit 된 변경 사항만 존재
- Fast Commit 을 위해 Redo 로그 사용
- 메모리의 버퍼 블록이 아직 디스크에 기록되지 않았지만 Redo 로그를 믿고 빠르게 커밋 완료
- 변경 사항은 Redo 로그에는 바로 기록하고, 버퍼 블록의 메모리-디스크 동기화는 나중에 일괄 수행
- 버퍼 블록의 디스크에 기록은 Random 액세스(느림), Redo 로그 기록은 Append 액세스 (빠름)
Delayed 블록 클린아웃
- 로우 Lock 이 버퍼 블록 내 레코드 속성으로 구현 되어 있어, Commit 시 바로 로우 Lock 해제 불가능
- Commit 시점에는 Undo 세그먼트 헤더의 트랜잭션 테이블에만 Commit 정보 기록, 블록 클린아웃(Commit 정보 기록, 로우 Lock 해제)은 나중에 수행
- Redo 레코드는 Redo 로그 버퍼 → Redo 로그 파일 기록 됨
- 3초마다 DBWR 로부터 신호 받을 때 (DBWR 은 Dirty 버퍼를 데이터 파일에 기록하기 전 LGWR 에 신호 보냄) - Write Ahead Logging (DBWR 가 Dirty 블록을 디스크에 기록하기 전, LGWR 는 해당 Redo 엔트리를 모두 Redo 로그 파일에 기록 해야 한다.)
- 로그 버퍼의 1/3이 차거나, Redo 레코드량이 1MB 넘을 때
- 사용자 Commit/Rollback - Log Force at Commit (최소 Commit 시점에는 Redo 정보가 디스크에 저장 되어야 한다.)
- 사용자 Commit
- LGWR 가 Commit 레코드 Redo 로그 버퍼 기록
- 트랜잭션 로그 엔트리와 함께 Redo 로그 파일 기록 (이후 복구 가능)
- 사용자 프로세스에 Success Code 리턴
log file sync
LGWR 프로세스가 로그 버퍼 내용을 Redo 로그 파일에 기록 하는 동안 서버 프로세스가 대기하는 현상
05. Undo
- Undo 세그먼트는 일반 세그먼트와 다르지 않다. (Extend 단위 확장, 버퍼 캐시 캐싱, 변경사항 Redo 로깅)
- 트랜잭션 별로 Undo 세그먼트가 할당 되고 변경 사항이 Undo 레코드 단위로 기록 됨 (복수 트랜잭션이 한 Undo 세그먼트 공유 가능)
| 구분 | 설명 |
|---|
| Rollback | 8i 까지, Rollback 세그먼트 수동 관리 |
| Undo | 9i 부터, AUM(Automatic Undo Management) 도입 |
AUM
- 1 Undo 세그먼트, 1 트랜잭션 목표로 자동 관리
- Undo 세그먼트 부족 시 가장 적게 사용되는 Undo 세그먼트 할당
- Undo 세그먼트 확장 불가 시 다른 Undo 세그먼트로 부터 Free Undo Space 회수 (Dynamic Extent Transfer)
- Undo Tablespace 내 Free Undo Space 가 소진 되면 에러 발생
Undo 목적
- Transaction Rollback
- 트랜잭션 Rollback 시 Undo 데이터 사용
- Transaction Recovery
- Instance Recovery 시 Roll Forward 후 Commit 안된 트랜잭션 Rollback 시 Undo 데이터 사용
- Read Consistency
- 읽기 일관성을 위해 Undo 데이터 사용 (다른 DB는 Lock 을 통해 읽기 일관성 구현)
(1) Undo 세그먼트 트랜잭션 테이블 슬롯
- Undo 세그먼트 중 첫 익스텐트, 첫 블록의 Undo 세그먼트 헤더에 트랜잭션 테이블 슬롯이 위치
- 트랜잭션 테이블 슬롯 기록 사항
- 트랜잭션 ID - USN(Undo Segment Number)# + Slot# + Wrap#
- 트랜잭션 상태 정보 (Transaction Status)
- 커밋 SCN (트랜잭션이 커밋 된 경우)
- Last UBA (Undo Block Address)
- 기타
- 트랜잭션 테이블 슬롯(Slot) 할당 및 Active 표시 후 트랜잭션 시작 가능 (대기 이벤트 : undo segment tx slot)
- 트랜잭션의 변경사항은 Undo 블록에 Undo 레코드로서 순차적으로 하나씩 기록 됨 (Last UBA[Undo Block Address] 정보로 마지막 Undo 레코드 확인)
- Undo 레코드는 체인 형태로 연결 되며, Rollback 시 체인을 거슬러 올라가며 작업 수행
- v$transaction.{used_ublk, used_urec}
- 트랜잭션이 사용중인 Undo Block 수, Undo 레코드 수 확인 가능
| 구분 | Undo 레코드 내용 | v$transaction.used_urec 증가(TBL) | v$transaction.used_urec 증가(TBL+IDX) | 비고 |
|---|
| INSERT | 추가된 레코드 ROWID | 1 | 2 | |
| UPDATE | 변경 컬럼 Before Image | 1 | 3 | 인덱스는 DELETE/INSERT 처리 |
| DELETE | 전체 컬럼 Before Image | 1 | 2 | |
- 커밋 된 순서대로 트랜잭션 슬롯 순차적 재사용
- 커밋 안된 Active 상태의 Undo 블록 및 트랜잭션 슬롯은 재사용 안됨
- 커밋에 의해 트랜잭션 상태 정보 (committed), 그 시점의 커밋 SCN이 저장된 트랜잭션 슬롯이 재사용 됨
- Undo Retention (undo_retention)
- 완료된 트랜잭션의 Undo 데이터를 지정된 시간만큼 "가급적" 유지
- 값을 기준으로 unexpired / expired 구분 되며 Undo Extent 필요시 expired 상태의 Extent 먼저 활용, 필요시 unexpired 상태의 Extent 도 활용
- guarantee 옵션 : unexpired 상태의 Extent 활용 불가
- alter tablespace undotbs1 retention guarantee;
- Automatic Undo Retention Tuning
- 시스템 상황에 따라 tuned_undo_retention 값 자동 계산 및 Undo Extent 관리 (undo_retention 최소값이 되며 "가급적" 지켜 짐)
(2) 블록 헤더 ITL 슬롯
- 테이블/인덱스 블록 헤더에는 ITL(Interested Transaction List) 슬롯 존재
- ITL 슬롯 번호
- 트랜잭션 ID
- UBA (Undo Block Address)
- 커밋 Flag
- Locking 정보
- 커밋 SCN (트랜잭션이 커밋 된 경우)
- 레코드 갱신 시 블록 헤더의 ITL 슬롯 확보 후 트랜잭션 ID 및 트랜잭션 Active 상태 기록 선행 필요
- ITL 슬롯 확보 될 때 까지 트랜잭션은 Blocking 됨 (enq: TX - allocate ITL entry)
- ITL 슬롯 수 관련 파라미터 : initrans(1/2), maxtrans(255), pctfree
(3) Lock Byte
- 레코드가 저장되는 로우 헤더에 관련 트랜잭션 ITL 슬롯 번호 기록 하는 Lock Byte 할당
- 로우 Lock 구현 = 로우 단위 Lock + 트랜잭션 Lock 조합 (TX Lock)
- 레코드 갱신 예제
- 대상 레코드의 Lock Byte 확인 : 활성화 상태
- ITL 슬롯 의 트랜잭션ID 확인
- 트랜잭션 테이블 슬롯 에서 트랜잭션 상태 확인 : 활성화 상태
- 대기
- Lock 매니저
- 다른 DBMS 는 Lock 매니저로 갱신 중 레코드 정보 관리, 오라클은 별도 리소스 없음 (레코드 속성)
- Lock 매니저는 유한한 리소스 문제로 로우 → 블럭 → 테이블 레벨로 Lock 에스컬레이션 발생 가능 (급격한 동시성 저하)
ITL 슬롯의 UBA(Undo Block Address) 정보
- 트랜잭션에 의한 변경 이전 데이터(Before Image)가 저장된 Undo 블록 주소를 가리키는 포인터 정보 (CR Copy 생성 시 사용)
06. 문장수준 읽기 일관성 (Statement-Level Read Consistency)
- 단일 SQL문(트랜잭션)이 수행 되는 도중, 다른 트랜잭션에 의해 데이터가 변경
된다면 일관성 없는 결과가 나타날 수 있음.
(1) 문장수준 읽기 일관성이란?
- 단일 SQL문이 수행되는 도중 다른 트랜잭션에 의해 데이터가 변경 되어도 일관성 있는 결과 집합을 리턴 하는 것
- 다른 DBMS 는 로우 Lock을 사용해 Dirty Read 방지 (읽을 때 Shared Lock 사용, Exclusive Lock 걸린 로우 읽지 못함)
- 로우 Lock 으로 문장수준 읽기 일관성 보장 안됨
- 오라클은 Undo 세그먼트 내 Undo 데이터 활용 하므로 완벽한 문장수준 읽기 일관성 보장.
※ 사례들
| 계좌번호 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| 잔고 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 |
- 트랜잭션(TX1)에서 모든 계좌 잔고 총합을 구하는 쿼리 수행
SELECT SUM(잔고) FROM 계좌;
- <사례1>
- TX1의 SUM(잔고) 이 진행 되는 동안 다른 트랜잭션(TX2)에서 아래 INSERT 처리
INSERT INTO 계좌 (계좌번호, 잔고) VALUES (11, 1000);
COMMIT;
- 새 레코드가 뒤쪽에 추가 되면, SUM(잔고)에 포함, 그렇지 않으면 누락 (레코드 위치에 따라 결정, 일관성 없음)
- 트랜잭션 고립화 수준을 높이거나, 테이블 Lock 적용 필요
- <사례2>
- TX1의 SUM(잔고) 이 진행 되는 동안 다른 트랜잭션(TX2)에서 이미 읽고 지나간 레코드에서 잔고를 차감해 읽을 레코드에 잔고를 더하는 경우 SUM(잔고) 이 다르게 구해질 수 있으므로 일관성 없음
테이블 레벨 Lock을 통한 읽기 일관성 확보
- 트랜잭션 고립화 수준을 상향 조정으로 사례와 같은 비일관성 문제 해결 가능 하나 Lock 이 넓고 오래 유지 되므로 동시성 저하 및 교착상태(Deadlock) 발생 가능성 높아 짐.
- 트랜잭션 고립화 수준 Level 1 (Read Committed) : 레코드 읽는 순간만 Shared Lock 걸고 다음 레코드 이동시 Shared Lock 해제 (기본)
- 트랜잭션 고립화 수준 Level 2 (Repeatable Read) : 쿼리가 읽은 레코드는 트랜잭션이 종료 될 때 까지 Shared Lock 이 유지 됨
(2) Consistent 모드 블록 읽기
- 오라클은 쿼리가 시작된 시점 기준으로 커밋된 데이터만 읽음
- 쿼리 시작 이후 변경된 블록은 Current 블록 에서 CR 블록 생성해서 읽음
- 다중 버전 읽기 일관성 모델 (Multi-Version Read Consistency Model)
| 블록 구분 | 특성 |
|---|
| Current | 최종 상태의 원본 블록, 한개 존재 |
| CR | Current 블록의 복사본, 여러 버전 존재 |
| 구분 | Current 블록 수 |
|---|
| 싱글 | 한개 |
| RAC(로컬) | 한개 |
| RAC(글로벌/Share 모드) | 노드당 한개 |
| RAC(글로벌/Exclusive 모드) | 노드중 한개 |
- 특정 노드 Current 블록이 Exclusive 모드로 업그레이드 되면, 나머지 노드 Current 블록은 Null 모드로 다운그레이드 됨
- Null 모드로 다운그레이드 된 블록은 다른 노드 혹은 디스크에서 블록을 다시 읽어야 함
- 따라서 Current 블록 SCN이 쿼리 SCN 보다 작다면 그냥 읽어도 됨
| 모드 | 설명 |
|---|
| Current | 데이터를 찾아간 바로 그 시점의 최종 값 읽기 |
| Consistent | 쿼리가 시작된 시점을 기준으로 값 읽기 |
- SCN(System Commit Number)을 이용해 데이터베이스의 일관성 있는 상태 식별
- 사용자 커밋 마다 1씩, 백그라운드 프로세스에 의해 조금씩 증가
- SCN_TO_TIMESTAMP(V$DATABASE.CURRENT_SCN)
- 목적 : 일관성/동시성 제어, Redo 로그 정보 순서 식별, 데이터 복구시 사용
- 블록 SCN : 블록 헤더에 저장된 SCN(System Change Number)
- 블록 ITL 엔트리의 트랜잭션별 커밋 SCN 과 별개임
(3) Consistent 모드 블록 읽기의 세부원리
- 오라클에서 모든 쿼리는 SCN 값 확인 후 작업 시작
- 확보된 쿼리 SCN 과 읽을 블록의 SCN 비교 판단
- Current 블록 SCN <= 쿼리 SCN 이고, committed 상태
- Current 블록 SCN > 쿼리 SCN 이고, committed 상태
- Current 블록이 Active 상태, 즉 갱신이 진행 중인 상태
A. Current 블록 SCN <= 쿼리 SCN 이고, committed 상태
- Consistent 모드 읽기는 블록 SCN(System Change Number)이 쿼리 SCN(System Comit Number) 보다 작거나 같은 블록만 읽을 수 있음
- 쿼리가 시작된 이후 블록에 변경이 가해지지 않음, Current 블록 바로 읽음
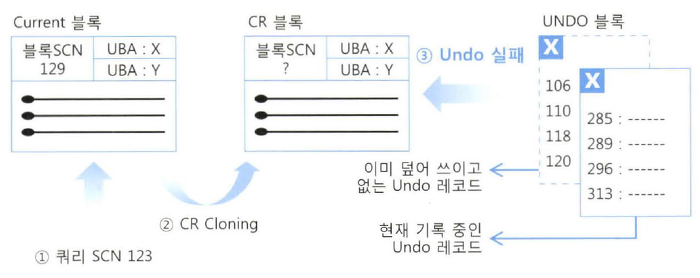
B. Current 블록 SCN > 쿼리 SCN 이고, committed 상태
- 쿼리가 시작된 이후 블록이 변경된 후 커밋됨, CR 블록 생성 후 읽음
- 원본(Current 블록)의 복사본(CR 블록) 생성 - CR Cloning
- CR 블록을 읽을 수 있는 과거 버전으로 되돌림 (쿼리 SCN 보다 낮은 마지막 Committed 시점)
- ITL 슬롯에서 UBA(Undo Block Address)가 가리키는 Undo 블록 사용
- 읽을 수 있을 때 까지 반복적으로 ITL 슬롯의 UBA가 가리키는 Undo 블록 사용하여 되돌림
- 블록 SCN이 쿼리 SCN 보다 같거나 작으면서 커밋되지 않은 내용이 포함되지 않으면 CR 블록을 읽을 수 있음
- 되돌림 과 Snapshot too old
- 되돌릴 때 필요한 Undo 정보가 다른 트랜잭션으로 덮어 씌워짐
- Delayed 블록 클린아웃 과정에서 관련 트랜잭션 테이블 슬롯이 재사용 되어 블록의 정확한 커밋 시점 확인 불가
ITL 내 UBA
ITL 변경 내역도 Undo 레코드에 기록 되므로, CR 블록이 되돌려질 때 ITL 내 UBA 도 같이 되돌려 지고, 반복적 되돌림에 UBA 계속 사용 가능
- CR 블록의 반복적 되돌림 데모
- TX1 의 UPDATE 를 반복 수행 함에 따라, TX2 의 consistent gets 가 하나씩 계속 증가
- CR 블록 생성을 위한 UNDO 블록 반복 방문
TX1) update emp set sal = sal + 1 where empno = 7900;
TX2) select * from emp where empno = 7900;
IMU(In-Memory Undo)
- Undo 데이터를 Undo 세그먼트 대신 Shared Pool 내 미리 할당된 IMU Pool(KTI-Undo)에 저장* 각 Pool 은 하나의 트랜잭션 전용 할당, in memory undo latch 로 보호
- IMU Pool 가득 차면 Undo 데이터를 Undo 세그먼트로 일괄 기록(IMU Flush) 후 이후 Undo 데이터는 예전처럼 Undo 세그먼트에 저장
- 작은 트랜잭션을 위한 기능, Undo 세그먼트 헤더/일반 블록에 대한 경합 감소
- 10g NF, 파라미터 : _in_memory_undo, _imu_pools
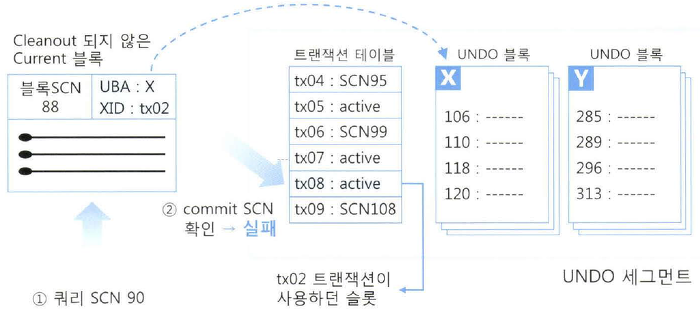
C. Current 블록이 Active 상태, 즉 갱신이 진행 중인 상태
- Delayed 블록 클린아웃 때문에 Active 상태 확인을 위해 Undo 세그먼트 헤더의 트랜잭션 테이블 접근 필요
- 레코드 Lock Byte + ITL 내 커밋 정보 없음 : Active 상태 추정
- 트랜잭션 테이블로부터 커밋정보를 가져와 블록 클린아웃 시도
- 쿼리 SCN 이전 커밋된 블록 : 그냥 읽음
- 쿼리 SCN 이후 커밋 혹은 커밋전 블록 : CR 블록 생성 후 읽음
<상황 1>
- SCN 105 쿼리문이 위 블록을 만나면 Current 블록 SCN 이 105 보다 작고 Committed 상태 이므로 그냥 읽는다. (CUR / SCN 100 / Committed)
<상황 2>
- SCN 125 쿼리문이 위 블록을 만나면 Current 블록 SCN 이 125 보다 크고 Active 상태 이므로, CR 블록 생성 후 두번 Rollback 하여 SCN 120 / committed 만든 후 읽는다. (CR / SCN 120 / Committed)
<상황 3>
- SCN 145 쿼리문이 위 블록을 만나면 Current 블록 SCN 이 135 이지만 Active 상태 이므로 CR 블록 생성 후 SCN 145 보다 낮은 마지막 Committed 상태로 만든 후 읽는다. (CR / SCN 130 / Committed)
<상황 4>
- SCN 150 쿼리문이 위 블록을 만나면 Current 블록 SCN 이 140 이고 Committed 상태 이므로 그냥 읽는다. (CUR / SCN 140 / Committed)
<상황 5>
- SCN 135 쿼리문이 위 블록을 만나면 Current 블록 SCN 이 140 이므로 CR 블록 생성 후 SCN 135 보다 낮은 마지막 Committed 상태로 만든 후 읽는다. (CR / SCN 130 / Committed)
DBA당 CR 개수 제한
- 데이터 블록 한개 당 여섯개 까지 CR Copy 허용 (_db_block_max_cr_dba)
- CR Copy 는 LRU 리스트에서 LRU End 쪽에 위치
07. Consistent vs. Current 모드 읽기
(1) Consistent 모드 읽기와 Current 모드 읽기의 차이점
| 구분 | Consistent 모드 읽기(gets in consistent mode) | Current 모드 읽기(gets in current mode) |
|---|
| SCN | SCN 확인 과정 있음 | SCN 확인 안함 |
| 시점 | 쿼리가 시작된 시점의 일관성 있는 블록 액세스 | 데이터를 찾아간 시점의 블록 액세스(Commit 된 값) |
| SQL Trace 항목 | query | current |
| AutoTrace 항목 | consistent gets | db block gets |
| 기타 | Current 블럭을 읽어도 query 항목에 집계, CR 블록 생성을 위한 Undo 세그먼트 액세스 블록 수 포함 | |
- Current 모드 읽기 발생 상황
- DML
- select for update
- Table Full Scan Query (8i 이전, Extent Map 조회)
- 디스크 소트를 동반한 대량 데이터 정렬
(2) Consistent 모드로 갱신할 때 생기는 현상
<상황1>
| <TX1> | | <TX2> |
|---|
| select sal from emp where empno = 7788; | t0 | |
| update emp set sal = sal + 100 where empno = 7788; | t1 | |
| t2 | update emp set sal = sal + 200 where empno = 7788; |
| commit; | t3 | |
| t4 | commit; |
- Consistent 모드로 갱신 한다면 답은?
- t1, t2 시점에 SAL 은 1,000 이며, 각각 100, 200 을 더하면 최종 SAL 은 1,200. (Lost Update 발생)
- Lost Update 회피를 위해 갱신 작업은 Current 모드 사용 필요
- TX2 는 Exclusive Lock 대기 하다가, t3 단계에서 TX1 commit; 후, Current 모드로 SAL 을 읽어 업데이트 한다.
(3) Current 모드로 갱신할 때 생기는 현상
<상황2>
| <TX1> | | <TX2> |
|---|
| update emp set sal = 2000 where empno = 7788 and sal = 1000; | t1 | |
| t2 | update emp set sal = 3000 where empno = 7788 and sal = 2000; |
| commit; | t3 | |
| t4 | commit; |
- Current 모드로 갱신 한다면 답은?
- TX2 는 t3 단계(TX1 트랜잭션이 커밋)를 기다린 후 SAL = 2000 확인 하고 업데이트 한다.
<상황3>
| <TX1> | | <TX2> |
|---|
| update t set no = no + 1 where no > 50000; | t1 | |
| t2 | insert into t values (100001, 100001); |
| t3 | commit; |
| commit; | t4 | |
※ t 테이블의 no 컬럼에 1 ~ 100,000 unique 값 레코드 존재, no 컬럼에 인덱스 존재, <TX1>의 update 는 인덱스 경유
- <TX1> 에서 no > 50,000 조건의 50,000 개 레코드 업데이트 도중 <TX2> 에서 100,001 인 레코드 추가
- 오라클 환경 에서 업데이트 된 레코드 건수는?
- Current 모드로 업데이트 한다면 레코드 건수는?
- 인덱스 경유 하지 않는 다면 레코드 위치에 따라 레코드 건수 다름
- <TX2> 에서 insert 대신 update t set no = 0 where no = 100000; 한 경우 49,999 건 업데이트 됨
- "delete from t;" 수행 중 새로 입력된 레코드도 지워질 수 도 있음
- DML 도중 적용 대상이 그때그때 변할 수 있음
(4) Consistent 모드로 읽고, Current 모드로 갱신할 때 생기는 현상
- UPDATE 수행 시 대상 레코드 읽을 때는 Consistent 모드로 읽고(query) 값을 변경할 때는 Current 모드로 읽는다.(current)
<상황4>
| <TX1> | | <TX2> |
|---|
| update emp set sal = 100 where empno = 7788 and sal = 1000; | t1 | |
| t2 | update emp set sal = sal + 200 where empno = 7788 and sal = 1000; |
| commit; | t3 | |
| t4 | commit; |
- <TX2> 는 <TX1> commit 후 진행 되므로 <TX2> 는 실패 함. (1,100)
- 아래 처럼 업데이트 대상 레코드를 Consistent 모드로 탐색(sal = 1000) 하는데 왜 실패 하는가?
-- <TX2> UPDATE
-- Current 모드 시작
update
(
-- Consistent 모드 시작
select sal from emp
where empno = 7788
and sal = 1000
-- Consistent 모드 종료
)
set sal = sal + 200;
-- Current 모드 종료
(5) Consistent 모드로 갱신대상을 식별하고, Current 모드로 갱신
- 오라클 동작 방식 : Consistent 모드로 수행한 조건 체크를, Current 모드로 액세스 하는 시점에 한번더 수행
-- <TX2> UPDATE
for c in
(
-- 단계1) Consistent : WHERE 절 조건에 따라 대상 레코드 ROWID 찾기
select rowid rid, empno, sal from emp
where empno = 7788 and sal = 1000
)
loop
-- 단계2) Current : ROWID 기준 로우 Lock 설정 후 값이 변경되는 시점 기준 DML 수행
update emp set sal = sal + 200
where empno = c.empno
and sal = c.sal <<< 조건 체크 한번 더 수행
and rowid = c.rid;
end loop;
- 단계1 은 갱신이 진행 되는 동안 변경으로 새로 들어오는 레코드를 제외 하기 위함
- 단계2 는 변경이 이뤄지는 시점 기준으로 값을 읽고 갱신 (블록 SCN - 쿼리 SCN 비교 안함, Commit 된 값이면 읽음)
동작 방식 정리
1. SELECT 는 Consistent 모드로 읽음
2. DML 은 Current 모드로 읽고 쓴다, 다만 대상 레코드 식별은 Consistent 모드로 함
Write Consistency
- <상황4> 에서 EMP.SAL 값의 변경으로 <TX2>의 UPDATE가 실패 했을 때 오라클은 내부적으로 Restart 메커니즘 사용
- 그 때까지 갱신을 롤백하고 UPDATE를 처음부터 다시 실행, Restart 메커니즘이 작동해도 대개 처리 결과가 달라지지 않음. (<상황4> 포함)
- 동시 트랜잭션 유형, 데이터 저장 위치, 갱신 시점의 미묘한 차이 때문에 일관성 없게 값이 갱신 되는 현상 방지 목적 구현
Write Consistency 데모#1
id col1 col2
---- ---- -----
1 4 A
2 5 B
3 6 C
TX1> update t set col2 = 'X' where col1 <= 5;
-- 위의 update 가 1번 레코드 갱신 후 2번 레코드 갱신 하기 전 아래 update & commit 수행 완료
TX2> update 5 set col1 = (case when col1 = 5 then 6 else 5 end) where id in (2, 3);
TX2> commit;
-- 최종 상태
id col1 col2
---- ---- -----
1 4 X
2 6 B
3 5 X
- Restart 메커니즘 없다면 2번, 3번 레코드는 갱신 안됨, 하지만 두 레코드가 동시에 col1 <= 5 조건 만족하지 못한 시점 없음
- <TX1> 시작 시점 기준 : 2번 레코드 조건 만족
- <TX1> 완료 시점 혹은 <TX2> 완료 시점 기준 : 3번 레코드 조건 만족
- 이 문제를 해결 하기 위해 Restart 메커니즘 존재, Restart 시점이 일관성 기준 시점이 됨
- 처음 UPDATE 시작 시점과 Restart 시점 사이의 제3 트랜잭션 변경 사항도 UPDATE에 반영 됨
- 많은 갱신 작업이 이뤄진 후 이기능이 작동하면 성능상 불이익 발생
- Restart 반복을 막기 위해 대상 레코드를 모두 SELECT FOR UPDATE 모드로 Lock 설정 후 UPDATE 재시작
- 오라클은 일단 UPDATE 해보고 (낙관적 동시성 제어) - 부하 감소 및 동시성 유지를 위함
- 일관성을 해칠만한 상황(조건절 컬럼 값이 변경 됨)이 생기면 처리를 롤백
- SELECT FOR UPDATE 모드로 Lock 설정 하고 다시 UPDATE 수행
Write Consistency 데모#2
- emp 레코드 갱신시 로그 테이블에 기록하는 before update each row 트리거 존재 가정
- <상황4> 에서 t3 시점에 <TX2>에 대한 블로킹 해제되며 로그 테이블에 insert 발생, 하지만 emp 업데이트 실패
- 일관성 없는 상태이나 Restart 메커니즘 작동 시 해결 됨
(6) 오라클에서 일관성 없게 값을 갱신하는 사례
- 오라클에서도 일관성 없게 값을 갱신할 가능성 존재
- 오라클만의 독특한 읽기 모드를 정확히 이해하고 주의 깊은 SQL 작성 필요
- 주로 사용자 정의 함수/프로시저, 트리거 등을 사용할 때 발생
- 스칼라 서브쿼리는 특별한 이유가 없는 한 항상 Consistent 모드 읽기 수행
-- 계좌2.잔고 는 Current 모드로 읽음
-- 계좌1.잔고 는 Consistent 모드로 읽음 (update 가 시작되는 시점)
update 계좌2
set 총잔고 = 계좌2.잔고 + (select 잔고 from 계좌1 where 계좌번호 = 계좌2.계좌번호)
where 계좌번호 = 7788;
- 계좌2.잔고, 계좌1.잔고 모두 Current 모드로 읽음
update 계좌2
set 총잔고 = (select 계좌2.잔고 + 잔고 from 계좌1 where 계좌번호 = 계좌2.계좌번호)
where 계좌번호 = 7788;
08. 블록 클린아웃
블록 클린아웃(Block Cleanout)
트랜잭션에 의해 설정된 로우 Lock을 해제하고 블록 헤더에 커밋 정보를 기록하는 오퍼레이션
로우 단위 Lock
- 로우 단위 Lock 은 레코드 속성(Lock Byte)으로 관리
- Lock Byte는 로우 헤더에서 블록 헤더에 있는 ITL 엔트리를 가리키는 포인터
- 트랜잭션 커밋 시 블록 클린아웃까지 완료 해야 하나, 대량 갱신 작업의 경우 빠른 커밋을 위해 커밋 정보를 트랜잭션 테이블에만 기록하고 커밋 처리 하는 경우가 있음
(1) Delayed 블록 클린아웃
- 갱신한 블록 개수가 총 버퍼 캐시 블록 개수의 1/10 초과시 적용
- 커밋 이후 해당 블록을 액세스하는 첫 번째 쿼리에 의해 클린아웃 처리 됨
- ITL 슬롯에 커밋 정보 저장
- 레코드에 기록된 Lock Byte 해제
- Online Redo 에 Logging
- 블록을 읽는 과정에서 Active 상태(커밋 정보가 ITL에 없는 상태) 블록은 읽기 전에 먼저 블록 클린아웃을 시도 한다.
- ITL 슬롯에 기록된 트랜잭션 ID를 이용해 Undo 세그먼트 헤더의 트랜잭션 테이블 슬롯을 찾아가 트랜잭션 상태 확인
- 커밋된 트랜잭션이라면 ITL 슬롯 및 로우 Lock 상태 갱신 하여 블록 클린아웃 처리
- 블록 클린아웃을 위한 갱신내용도 Redo 에 로깅 하고 블록 SCN 변경
(2) 커밋 클린아웃(= Fast 블록 클린아웃), (= Delayed 로깅 블록 클린아웃)
- 블록을 읽을 때 마다 블록 클린아웃이 필요 하다면 성능에 부정적임
- 블록 클린아웃은 Current 블록에 작업 수행 (RAC/OPS 환경에서 Exclusive 모드 Current 블록 요청)
- 갱신한 블록 개수가 총 버퍼 캐시 블록 개수의 1/10 이하시 커밋 시점에 바로 블록 클린아웃 수행
- 이 경우에도 '불완전한 형태의 클린아웃' 수행, 해당 블록을 갱신하는 다음 트랜잭션에 의해 완전한 클린아웃 처리
- 커밋 시점에는 ITL 슬롯에 커밋 정보만 저장하고, 로우 헤더에 기록된 Lock Byte는 해제 안함 (로깅을 하지 않고 뒤로 미룸)
- 이후 블록 액세스시 커밋 여부와 커밋 SCN 확인을 위해 트랜잭션 테이블 조회 불필요
- 이후 Current 모드로 읽는 시점에(ITL 슬롯이 필요) 비로소 Lock Byte를 해제하고 완전한 클린아웃 수행, 그리고 Redo 로깅
(3) ITL과 블록 클린아웃
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0004.00c.0000350c3 0x008005a2.042f.lc --U- 1 fsc 0x0003.03536d7f
0x02 0xffff.000.000000000 0x00000000.0000.00 C--- 0 scn 0x0000.0353689e
0x03 0x0005.00d.0000003c4 0x00801a0b.01d1.Id C-U_ C-U- scn 0x0000.006770c0
- 1번 슬롯(0x01)은 Fast 클린아웃 상태
- 로우 헤더에 Lock Byte가 미해제(Lck=1), 커밋 SCN 존재, Fast 클린아웃 상태 표시(fsc), Flag=U
- Lock Byte 해제 로 2번 슬롯 상태로 만든 후, ITL 슬롯 재사용 가능
- 2번 슬롯(0x02)은 Delayed 블록 클린아웃 상태
- 언제든 ITL 슬롯 재사용 가능, Lock Byte 해제 상태 (Lck=0), 정확한 커밋 SCN 존재, Flag=C
- 3번 슬롯(0x03)은 Delayed 블록 클린아웃 상태
- Lock Byte 해제 상태 (Lck=0), 언제든 ITL 슬롯 재사용 가능, 추정된 커밋 SCN 존재, Flag=CU
09. Snapshot too old
- 발생원인
- 데이터 읽는 중 쿼리 SCN 이후 변경된 블록의 CR 블록 생성 시도 했으나, 필요한 Undo 정보를 얻을 수 없는 경우 (Undo 세그먼트 크기가 작아서)
- 커밋된 트랜잭션 테이블 슬롯이 재사용돼 커밋 정보 확인할 수 없는 경우 (Undo 세그먼트 수가 적어서)
(1) Undo 실패
-- 고객별 미납금 조회 쿼리 : 1시간 소요
SELECT /*+ ordered use_nl(b) */ A.고객ID
, NVL(SUM(과금액, 0) 과금액
, NVL(SUM(수납액, 0) 수납액
, NVL(SUM(과금액, 0) - NVL(SUM(수납액, 0) 미납액
FROM 과금 A, 수납B
WHERE A.과급년월 = :과금년월
AND A.과금유형 = :과금유형
AND A.고객ID = B.고객ID(+)
AND A.과금년월 = B.수납년월(+)
GROUP BY A.고객ID
- SCN 123 시점 쿼리 시작
- 수납 일괄 처리 배치 수행 - 홍길동 수납액 변경 (10,000 > 20,000), 블록 SCN 129
- 홍길동 수납액 변경 관련 Undo 블록이 재사용 됨
- 고객별 미납금 조회 쿼리가 홍길동 고객 블록 도달 후 SCN 비교 후 CR 블록 생성을 위해 ITL 엔트리의 UBA 를 참조하여 Undo 세그먼트 블록 탐색
- Undo 블록은 재사용 되었으므로, ORA-01555 에러 발생
fetch across commit 쿼리
-- ANSI 표준 : 열린 커서는 Commit 시점에 무효화, 오라클은 fetch across commit
허용for C in (select /*+ ordered use_nl(b) */ A.고객ID, A.입금액, B.수납액
from 은행입금 A, 수납 B
where A.입금일자 = trunc(sysdate)
and B.수납년월(+) = to_char(sysdate, 'yyyymm')
and B.고객ID(+) = A.고객ID)
loop
if C.수납액 IS NULL then
insert into 수납 (고객ID, 수납년월, 수납액)
values (C.고객ID, to_char(sysdate, 'yyyymm'), C.입금액);
else
update 수납 set 수납액 = 수납액 + C.입금액
where 고객ID = C.고객ID
and 수납년월 = to_char(sysdate, 'yyyymm');
end if;
commit;
end loop;
- SCN 100 시점, 커서 C 오픈
- 홍길동 수납액 변경에 따라 500번 블록 SCN 이 120 으로 변경
- 홍길동 수납액 변경 관련 Undo 블록이 재사용 됨 (아마도 다른 고객 처리 트랜잭션에 의해...)
- 커서 C 에서 500번 블록 내 김철수 수납 정보 도달 후 SCN 비교 후 CR 블록 생성 시도
- 관련 Undo 블록은 재사용 됨에 따라, ORA-01555 에러 발생
(2) 블록 클린아웃 실패
- Delayed 블록 클린아웃 상황에서 Free 상태가 된 트랜잭션 테이블 슬롯이 재사용 될 수 있음
- 이후 블록 접근시 관련 트랜잭션 테이블 슬롯이 없다면 정상적인 블록 클린아웃과 일관성 모드(Consistent Mode) 읽기가 불가능할 수 있음.
- 하지만 Undo 세그먼트 헤더 블록 갱신도 Undo 레코드로 기록 되므로 필요한 시점의 CR 블록 생성 후 블록 클린아웃 수행 가능.
- 만약 Undo 세그먼트 헤더 블록의 Undo 레코드 조차 없다면 Snapshot too old 가 발생 하는가?
- 트랜잭션 슬롯이 필요하면 커밋 SCN이 가장 낮은 슬롯 부터 재사용
- 그리고 재사용 슬롯의 커밋 SCN을 Undo 세그먼트 헤더에 '최저 커밋 SCN(Low commit SCN)' 으로 기록
- 따라서 필요한 트랜잭션 테이블 슬롯이 없을 때는 정확한 커밋 SCN 대신 Undo 세그먼트 헤더에 있는 '최저 커밋 SCN' 을 블록 클린아웃에 사용한다.
- ITL 의 커밋 SCN 에 '최저 커밋 SCN' 기록, Flag 는 'C\-\-\-' 대신 'C-U-' (추정된 커밋 SCN) 설정, 블록 SCN 도 변경
- 이후 해당 블록은 일관성 모드(Consistent Mode) 읽기가 불가능 함 (CR 블록 생성 불가)
- (결론) Delayed 블록 클린아웃에 의해 Snapshot too old 발생 원인
- '최저 커밋 SCN' 이 쿼리 SCN 보다 높아질 정도로 갑자기 트랜잭션이 몰릴 때
(3) Snapshot too old 회피 방법
- 재현이 어려워 문제 원인 찾기 쉽지 않음
- 조치 방법도 확률을 낮출 뿐이며 가능성 0% 는 아님
- Lock 에 의한 동시성 저하를 해결 하는 댓가(Side Effect)
- AUM(Automatic Undo Management)에 의해 Snapshot too old 발생 감소 됨
- DBA 는 충분한 크기의 Undo Space 준비 하면 됨
- 어플리케이션 구현 측면 노력은 여전히 필요
- 불필요한 잦은 커밋 제거
- fetch across commit 형태를 다른 방식으로 구현 (ANSI 표준 : 커밋 이전에 열려 있던 커서는 더 Fetch 하면 안됨)
- 트랜잭션이 몰리는 시간대에 오래 걸리는 쿼리 동시 수행 금지
- 큰 테이블을 나눠 처리하도록 코딩 (Snapshot too old 감소, 중간 재시작 가능)
- 오래 걸리는 NL 조인, 인덱스 경유 테이블 액세스 회피 (HASH 조인, FTS...)
- ORDER BY 삽입 으로 소트 연산 발생 시켜 데이터가 Temp 세그먼트에 저장 되도록 함 (소트 부하 감수)
- Delayed 블록 클린아웃이 의심되면 대량 업데이트 후 FTS, IFFS 수행
10. 대기 이벤트
(1) 대기 이벤트란?
- 오라클은 역할 분담된 많은 프로세스(쓰레드)간 커뮤니케이션 과 상호작용이 이뤄지고, 다른 프로세스 처리를 기다리는 상황이 자주 발생 함.
- 프로세스는 일 할수 있는 조건이 충족 될 때까지 수면(Sleep) 상태에 빠짐 → 대기 이벤트(Wait Event)
- 대기 이벤트는 원래 오라클 개발자들이 디버깅 용도로 개발한 것
- 공유 자원에 대한 경합이나 기타 원인에 의한 대기가 발생할 때마다 로그를 생성 하도록 커널 코드에 추가 한것
- 현재 OWI(Oracle Wait Interface) 이름으로 성능 관리 분야에 일대 변혁을 가져옴
- 대기 이벤트 수 : 7.0 100 여 개, 9i 400 여개, 10g 890 여개, 11g 1,100 여개
| Oracle | SQL Server |
|---|
| 대기 이벤트(Wait Event) | 대기 유형(Wait Type) |
- 시스템 커널 레벨 관점의 대기 이벤트
- 프로세스가 할 일을 모두 마쳤거나 다른 프로세스를 기다려야 하는 상황에서 CPU 를 낭비하지 않고 수면(Sleep) 상태로 빠지는 것
- 프로세스가 Wait Queue 로 옮겨짐 (OS 는 Wait Queue 내 프로세스에 CPU 할당 제외)
- 선행 프로세스가 일을 마치면 OS에게 알림 (Interrupted)
- OS는 기다리던 Wait Queue 내 프로세스를 Runnable Queue 에 옮김
- r 컬럼 : 수행 중 혹은 runnable queue 에서 CPU 리소스를 기다리는 프로세스 수
- 값이 CPU 개수를 초과하고 CPU 사용률이 100%에 근접 할 경우 CPU 병목 임
- w 컬럼 : wait queue 에 놓인 프로세스 수
- Sleep 상태의 프로세스 개수, 이 값이 큰 것도 병목일 수 있음 (오라클 에서는 대기 이벤트가 많이 발생 하는 상태, 대기 이벤트 종류 분석 필요)
(2) 대기 이벤트는 언제 발생할까?
- 대기 이벤트가 지속적으로 많이 발생 하면 데이터베이스에 병목의 신호
- 병목과 관련 없는 예외 대기 이벤트도 있음
- 서버 프로세스가 사용자의 명령(신호) 대기
- SQL*Net message from client
- SQL*Net more data from client
- 서버 프로세스의 idle 대기 이벤트
- pmon timer
- smon timer
- px idle
- 대기 이벤트 발생 상황
- 자신이 필요로 하는 특정 리소스가 다른 프로세스에 의해 사용중
- 읽으려는 버퍼가 다른 프로세스에서 쓰기 중
- buffer busy waits, latch free, enqueue 관련 대기 이벤트
- 다른 프로세스에 의해 선행작업이 완료되기를 기다림
- DBWR 가 Dirty 버퍼를 디스크에 기록할 때 LGWR 에서 로그 버퍼 내 Redo Entry 의 Redo Log 파일 기록이 선행 되어야 함 - Write Ahead Logging
- 따라서 DBWR 는 LGWR 를 깨워 로그 버퍼를 비우라는 신호(Signal, Post)를 보내고 LGWR 가 일을 마칠 때까지 수면 상태로 빠짐
- LGWR 가 일을 마치면 DBWR 를 깨우고 자신은 수면 상태로 빠짐
- 관련 이벤트 : write complete waits, checkpoint completed, log file sync, log file switch
- 할 일이 없을 때(Idle 대기 이벤트)
- 쿼리 결과를 클라이언트에 전송시 Array 단위로 처리, Array 크기 만큼 전송하면 다음 Fetch Call 받을 때까지 대기 (SQL*Net message from client)
- 병렬 쿼리 수행시 일이 먼저 끝난 Slave 프로세스는 다른 Slave 들이 일 마칠 때까지 대기 (PX Deq: Execution Msg)
(3) 대기 이벤트는 언제 사라질까?
- 선행 프로세스가 자신을 깨워주지 않아도, 타이머에 설정된 시간이 도래(Timeout) 할 때마다 깨어나 자신이 기다리던 리소스 가용 여부 확인.
- Timeout 값은 대기 이벤트 마다 다름
- DBWR, LGWR 상호 작용의 Timeout 은 둘다 3초
- LGWR 를 깨워 Redo 버퍼를 비우도록 할 때 발생하는 log file sync 의 Timeout 은 1초
- buffer busy wait 의 Timeout 은 1초
- enqueue 관련 Lock 대기 이벤트 의 Timeout 은 3초
- Timeout 에 의해 깨어 났으나 아직 리소스가 사용중 이면 다시 수면 상태로 빠짐
- 잦은 대기 이벤트 발생도 문제, 잦은 타임아웃은 더 문제 (Latency 증가)
- 대기 프로세스가 활동을 재기하는 시점
- 기다리던 리소스 가용화
- 선행 작업 완료
- 할 일이 생김
(4) 래치와 대기 이벤트 개념 명확화
- 래치를 얻는 과정은 경합이 아님 (v$latch.gets 증가는 문제 아님)
- 접근 요청 횟수 보다, 접근 과정 중 다른 프로세스와 경합 발생 여부가 중요
- v$latch (willing-to-wait 모드)
| 컬럼 | 의미 |
|---|
| gets | 래치 요청 횟수 |
| misses | 래치를 요청 했으나, 자원이 사용중이라 첫 시도에서 래치를 얻지 못한 횟수 |
| simple_gets | 첫 시도에서 곧바로 래치 획득에 성공한 횟수 (=gets - misses) |
| spin_gets | 첫 시도에서 래치를 얻지 못했으나, 이후 spin 중 래치 획득 한 횟수 (=misses - sleeps) |
| sleeps | 래치를 얻지 못했고, 정해진 횟수(_spin_count=2000)만큼 spin 했는데도 얻지 못해 대기 상태로 빠진 횟수(latch free) |
- 래치는 큐잉 메커니즘이 없음, 획득 성공 까지 반복 액세스 시도, 획득 우선권/순서 없음
- 9i 까지는 래치 대기 이벤트가 latch free 하나 였으나, 10g 부터는 세분화 됨(latch: cache buffers chains, latch: library cache lock 등)
- spin : CPU 점유 상태로 래치 획득 시도 반복 하는 것
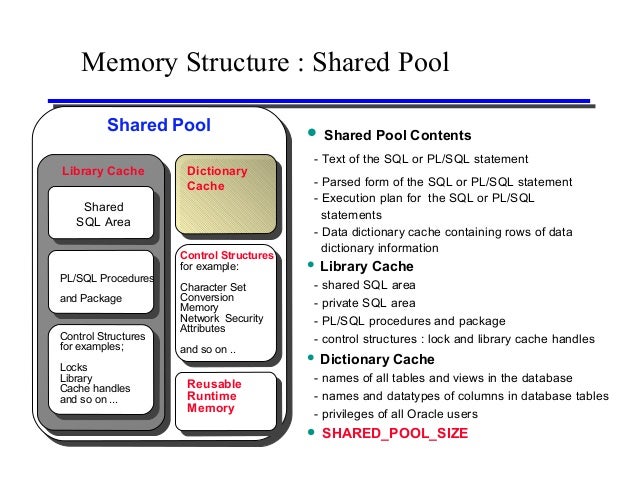
11. Shared Pool
(1) 딕셔너리 캐시
- 오라클 딕셔너리 정보를 저장 하는 캐시 영역
- Row 단위로 읽고 쓰기 때문에 로우 캐시(Row Cache) 라고도 불림
- 테이블, 인덱스, Tablespace, Datafile, Segment, Extent, Constraint, User, Sequence, Database Link 관련 정보 캐싱
SEQUENCE CACHE 옵션
- CACHE 옵션으로 로우 캐시 경합 감소 가능
- CACHE 20 는 NOCACHE 대비 로우 캐시 UPDATE 횟수가 5% 임 (NEXTVAL 이 많을 경우 CACHE 값 상향 조정)
-- HIT_RATIO 가 낮으면 SHARED_POOL 증가 필요
SELECT ROUND((SUM(GETS - GETMISSES)) / SUM(GETS) * 100, 2) HIT_RATIO
FROM V$ROWCACHE;
-- V$ROWCACHE.TYPE = 'PARENT' 와 V$LATCH_CHILDREN.NAME = 'row cache objects' 건수 같음
-- 로우 캐시 엔트리 당 래치 할당 추정
SELECT *
FROM (SELECT COUNT(*) FROM V$ROWCACHE WHERE TYPE = 'PARENT'),
(SELECT COUNT(*) FROM V$LATCH_CHILDREN WHERE NAME = 'row cache objects');
(2) 라이브러리 캐시
- 사용자 SQL 과 실행 계획 저장 하는 캐시 영역
- 무거운 하드 파싱을 최소화 하기 위해, 만들어진 실행 계획을 라이브러리 캐시에 저장 하여 재사용
문서에 대하여
- 최초작성자 : ~openlsw
- 최초작성일 : 2016년 03월 19일
- 이 문서는 오라클클럽 오라클 데이터베이스 스터디 모임에서 작성하였습니다.
- {*}이 문서의 내용은 (주)비투엔컬설팅에서 출간한 '오라클 성능 고도화 원리와 해법 I'를 참고하였습니다.*