2.8 FPD (Filter Push Down) 조건절을 인라인뷰 내부로 이동시켜라 (by dolphhong) [2013.05.29]
2.A Heuristic Query Transformation 이란?
- Heuristic : 문제 해결에 있어 노력을 최소화 하기 위해 사용되는 고찰이나 과정
- 자원/시간 낭비하는 Coasting 과정을 생략하여 특정 Rule을 적용하여 최적화를 진행하겠다는 의미
- "특정 작업의 부하를 줄일 수 있는 가장 좋은 방법은 그 작업을 수행하지 않는 것이다."
- SQL 자체 성능 최적화 + Hard parsing 시 Coasting 과정에서 부하 제거 하여 parsing 의 성능을 빠르게함
{info}
- SQL 자체 성능 최적화 + Hard parsing 시 Coasting 과정에서 부하 제거 하여 parsing 의 성능을 빠르게함
- count( * ) 를 하는데 Order by 는 필요없음 ! 불필요한 부하 제거를 위해 ORDER BY 를 제거하는것.
-> Heuristic Rule
SELECT COUNT(*)
FROM tab1
ORDER BY col1;
- "꼭 필요한 일만 해라"
- 고객번호, 고객명을 select 하는데 공통코드 테이블과 조인은 필요없다. ( A.고객구분코드 가 NULL 인 데이터가 없을 경우 )
공통코드 테이블에 Unique 인덱스만 있으면 위 SQL에서 공통코드쪽을 삭제한다.
- 고객번호, 고객명을 select 하는데 공통코드 테이블과 조인은 필요없다. ( A.고객구분코드 가 NULL 인 데이터가 없을 경우 )
SELECT a.고객번호, a.고객명
FROM 고객 a, 공통코드 b
WHERE a.고객구분코드=b.고객구분코드(+);
2.1. CSE (Common Subexpression Elimination) : Where절에서 or 사용시 중첩된 조건절은 제거하라
- CSE : 중첩되는 Where조건을 찾아서 제거하는 것
SELECT department_id, salary
FROM employee
WHERE (department_id = 60 AND salary = 4200)
OR (department_id = 60) ;
- 같은 조건이 존재. where절에 department_id = 60 만 있으면 된다.
- Logical Optimizer는 이러한 경우에 (department_id = 60 AND salary = 4200) 조건을 삭제해 버린다. ( 넓은 범위 조건을 남긴다. )
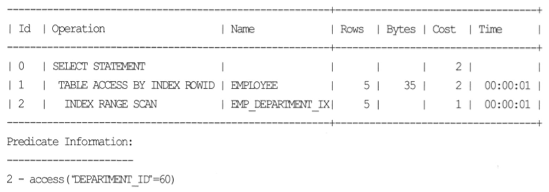
- predicate information 을 보면 DEPARTMENT_ID=60 만이 남아있고 나머지 조건은 삭제됨.
- 10053 Trace


- Or 부분이 (salary = 4200 OR 0=0) 로 재작성 되었다. 0=0 조건은 항상 True이므로 괄호 안에 모든 조건은 삭제되어도 무방하다.
- CSE기능이 없다면 ?
- Full table Scan 발생.
- predicate information 을 보면 where 절이 그대로 수행됨.
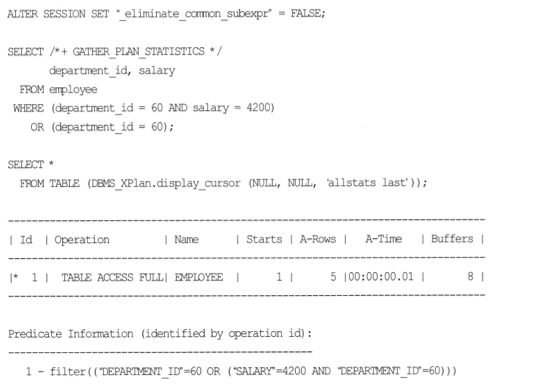
- CSE기능이 있으나, SQL작성 시 중복 조건을 쓰지 않도록 해야한다.
2.2 JE (Join Elimination): 직접 사용하지 않는 테이블은 SQL에서 삭제하라
- FK를 사용하면 느려진다 ? - JE기능이 나오기 전까지는 그러했다.
- 이제는 상황에 따라 FK로 인해 성능이 향상되는 경우가 많이 있다.
- SELECT 절에 자식 쪽 컬럼만 나열하는 경우, 부모와 자식간에 FK를 만들어 두면 부모테이블을 액세스 하지 않는다.
- FK가 자식 테이블에 존재하는 값이 100% 부모테이블에도 존재한다는 것을 보장함.
- 부모쪽 테이블 조인을 제거하여 I/O와 조인 부하를 감소시킬 수 있다.
- JE기능 : FROM절의 부모테이블 제거, WHERE절 부모 자식간 조인절 제거 ( 10gR2 )
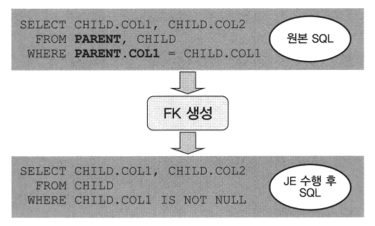
- JE가 발생하는 경우
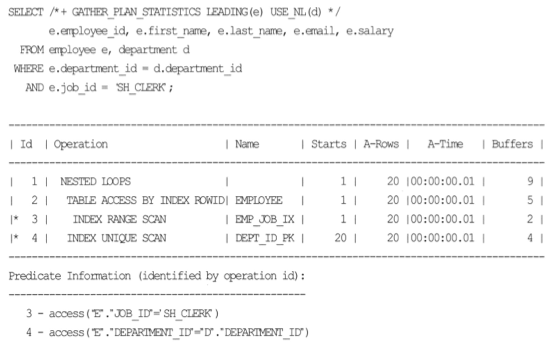
- 위 경우에 JE가 발생하지 않음. FK를 생성하고 다시 수행.
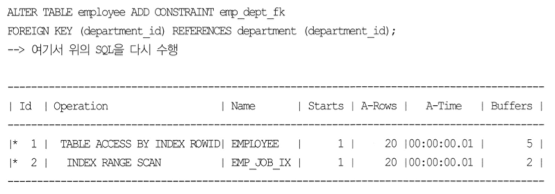
- JE기능이 수행되어 DEPARTMENT 테이블 액세스 OPERATION이 사라짐.
- oracle이 JE 기능을 사용하기 위해 ELIMINATE_JOIN 힌트를 사용한다.
- Outline Data
Outline Data: /*+
BEGIN Outline DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE('11.1.0.6')
DB_VERSION('11.1.0.6')
ALL_ROWS
Outline_LEAF(@"SEL$F7859CDE")
*ELIMINATE_JOIN(@"SEL$1" "D"@"SEL$1")*
Outline(@"SEL$1")
INDEX_RS_ASC(@"SEL$F7859CDE" "E"@"SEL$1" ("EMPLOYEE"."JOB_ID")
END_Outline_DATA
*/
- FK가 존재하더라도 NO_ELIMINATE_JOIN 힌트 사용 / _optimizer_join_elimination_enabled 파라미터 false 로 적용 할 경우 JE 기능을 사용할 수 있다.
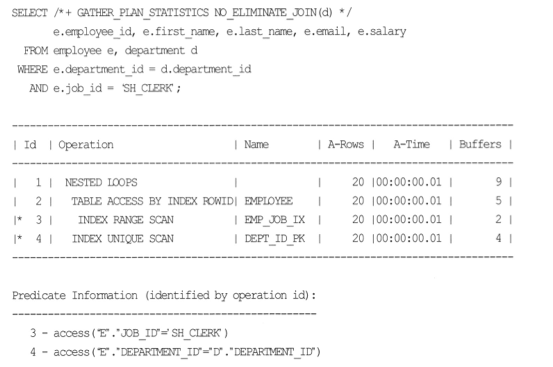
- JE기능 제약사항
- join 되는 FK 가 Multi Column일 경우 기능이 수행되지 않는다. ( sequence 를 이용하여 인공key를 pk로 사용해야 한다.)
- Equal(=) 조인 이외에 Range join (Between , > , < , Like) 등을 조인절에 사용하면 기능이 수행되지 않는다.
- Department 테이블의 PK를 제외한 컬럼을 select 절에 사용하면 JE 기능을 사용할 수 없다.
- Oracle 10g 에서는 JE가 발생할 수 있는 상황에 ANSI SQL (ANSI Style join)을 사용하면 안된다.
- ANSI SQL에서 JE 기능은 11g 부터 사용 가능하다.
2.3. OE (Outer Join Table Elimination): 불필요한 Outer쪽 테이블은 삭제하라
- 11g 에서 OE 기능이 추가됨.
- OE : OUTER조인 시 불필요한 테이블 제거하는 기능
- JE와 달리 PK/FK가 필요 없다.
ALTER TABLE employee DROP CONSTRAINT emp_dept_fk ;
ALTER TABLE department DROP PRIMARY KEY CASCADE KEEP INDEX ;
- PK/FK를 제거, Unique 인덱스만 있으면 DEPARTMENT쪽을 액세스 하지 않음.
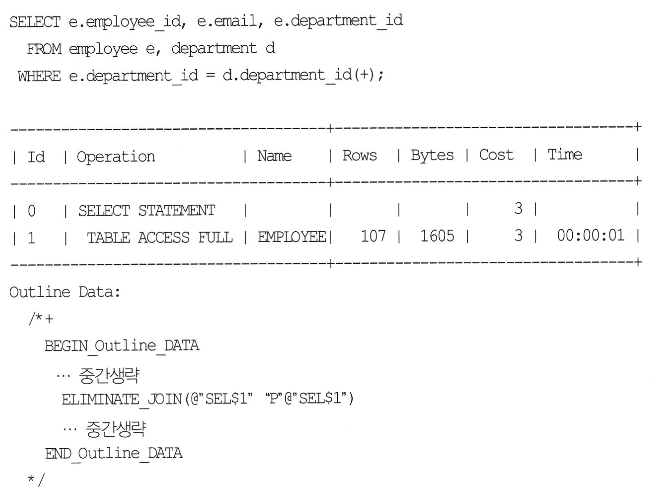
- OE기능을 Control 하는 파라미터는 _optimizer_join_elimination_enabled 파라미터로 JE와 같다.
- Outline Data - ELIMINATE_JOIN 힌트를 사용 ( OE기능은 JE기능을 확장한 것 )
- 10053 Trace

- SQL 에서 Outer조인임을 확인하고 JE기능을 수행함.
- SEL$1 에서 조인이 제거되거 새로운 쿼리블럭인 SEL$F78959CDE가 생성됨.
- QUERY BLOCK SIGNATURE - 쿼리블럭의 FROM 절에는 E(employee) 만 존재하며 D(department)는 삭제됨.
- Outer Join Table Elimination기능의 제약사항은 JE 제약사항과 일치한다.
- SELECT 절에 INNER 쪽 컬럼만 사용하는 경우 Where절에 Outer 테이블 쪽의 조건이 추가되어도 결과는 동일하다.
- d.manager_id( + ) = 10 조건이 결과에 영향이 없으나, Outer Join Table Elimination이 수행되지 않음.

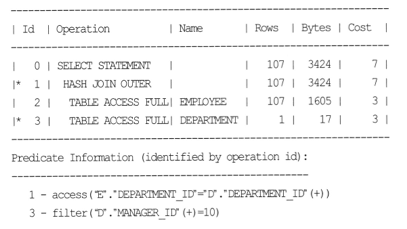
2.4 OJE (Outer-Join Elimination) : 의미 없는 Outer 조인을 Inner 조인으로 바꾸어라
- Oracle은 Outer 조인 조건절 분석하여, 가능한 경우 Outer 조인을 Inner 조인으로 변경한다.
- OE, OJE 차이점
- OE : SQL 의 From 절에서 Outer쪽의 테이블을 삭제하는 기능
- OJE : Outer join 을 Inner Join 으로 바꾸는 기능 ( oracle v7 )

- 위 plan 에서 1번ID Operation 이 Hash Join Outer 가 아니라 Hash Join 으로 수행.
- 오라클이 outer 조인을 제거한 것.
- outer join 과 상관 없이 LOCATION_ID = 1700 데이터가 추출되므로 Outer join 조건 삭제되어도 무방한 것.
- Outline 정보에서 OUTER_JOIN_TO_INNER 힌트를 사용하여 Outer 조인 조건을 제거를 확인할 수 있다.
/*+
BEGIN_Outline_DATA
...중간생략
OUTER_JOIN_TO_INNER(@"SEL$1")
...중간생략
END_Outline_DATA
*/
- 10053 Trace

- D.LOCATION_ID=1700 조건으로 OJE 발생, 그 결과 새로운 쿼리블록 SEL$6E71C6F6 생성됨. (From 절에 D,E 가 존재한다.)
- 실제로 위 SQL은 잘못되었으며 Outer 조인을 제대로 사용하기 위해 where 조건을 변경해야함.

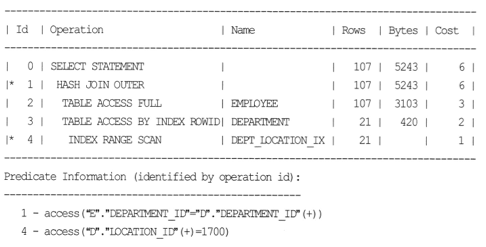
- LOCATION_ID 에 ( + ) 추가하니 HASH JOIN OUTER 가 나왔다.
- IS NULL 조건을 사용할 경우 OJE 가 작동하지 않으므로 주의해야 한다.
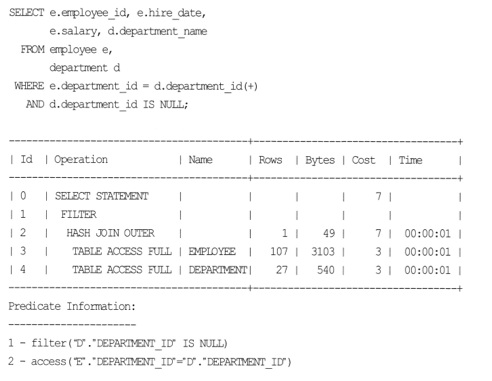

- D.DEPARTMENT_ID IS NULL 조건은 Outer 조인 수행 후 판단 가능하므로 OJE 사용 안되는 것은 당연한 것.
- 10053 Trace 로 IS NULL 조건으로 인해 OJE 사용 되지 않음을 확인할 수 있다.
- Outer 쪽 조건에 IS NULL이 붙는다면, Anti Join 을 활용하는 것이 성능상 유리하다.
- Anti Join - 2.23 OJTAJ (Outer Join To Anti Join)
2.5 OBYE (Order By Elimination): 불필요한 Order By를 삭제하라
- Order by 가 필요없는 경우에 OBYE 가 발생된다.
- JOB_ID = 'ST_CLERK' 조건을 만족하는 데이터를 DEPARTMENT_ID 로 Group By 하여 count 하는 쿼리

- 인라인 뷰 d 에 쓸모 없는 order by 절이 있다. -> SORT 부하에 의한 수행속도 저하와 불필요한 PGA 소모 발생 가능성.


- 실행계획으로 보면 Sort Order By 가 존재하지 않음
- 오라클이 Order by 절을 삭제하기 위한 힌트를 사용하였다

- 10053 Trace

- order by removed 로 OBYE 가 수행됨을 확인
- OBYE 가 수행된 결과로 새로운 쿼리블럭인 SEL$73523A42 가 생성되었다.
- 새로운 쿼리블럭 SEL$73523A42 의 From 절에 DEPARTMENT "D" 가 있음을 확인.
- OBYE 파라미터 _optimizer_order_by_eliment_enabled 이며 default = true
- ELIMINATE_OBY/NO_ELIMINATE_OBY 힌트를 사용하여 해당 기능을 Control 할 수 있다.
2.6. DE (Distinct Eliminate): 불필요한 Distinct 를 제거하라
- DE는 select 절에 Unique 한 컬럼이 포함된 경우, 불필요한 Distinct 를 제거하는 기능.
- 이로 인해 Sort , 중복제거 부하가 많은 작업을 수행하지 않을 수 있다. (11g 추가)

- 실행계획에서 Distinct Operation 인 Sort Unique , Hash Unique 가 없음.
- Transformer가 위 SQL을 분석, Distinct 가 없어도 Unique 함을 확인함.
- d.department_id , l.location_id 는 두 테이블의 PK. PK 컬럼이 SELECT 절에 포함되면 Unique 하므로 Distinct operation 이 삭제된다.
- 10053 Trace


- SEL$1 에서 Distinct 가 삭제되었음.
- DE 가 OBYE 자리에서 수행됨을 확인할 수 있다. - 실행순서 상 OBYE 먼저 발생, 이후에 DE 수행됨.
(DE가 OBYE에 포함되는 개념은 아니다) - Unique 하다고 항상 DE 가 발생하지는 않는다! (제약사항)
SELECT distinct d.department_id, d.location_id
FROM department d, location l
WHERE d.location_id = l.location_id ;

- 컬럼 하나만 변경 ( l.location_id ) 되었는데 Hash Unique 가 수행되었다.
- 이유 : 논리적으로 select 절에 d.location_id 을 사용하거나, l.location_id 사용하는 것은 같으나, DE에 해당 기능은 제공되지 않는다.
- 조인된 컬럼을 사용할 것인지, 참조되는 컬럼을 사용할 것인지 신중하게 결정해야 한다.
- department 쪽 PK Constraint 를 Drop 하고 Unique index 만 존재한다면 DE가 발생하지 않는다. ( Null 데이터가 중복될 수 있기 때문 )
- not null 제약조건을 추가하면 DE가 발생한다. ( 1:N 관계에서 N쪽은 Not Null 조건이 필요하다 )
DE의 또 다른 유형 DEUI (Distinct Elimination using Unique Index)
- Unique 인덱스를 사용하여 INDEX UNIQUE SCAN Operation 이 나오는 경우 Distinct 를 제거한다.

- Location 쪽 unique 컬럼이 select 절에 없음에도 Sort Unique, Hash Unique 가 실행되지 않는다.
- department, location 두 테이블에 모두 index unique scan 을 사용하기 때문에 결과가 1건 혹은 0을 보장한다.
- 이는 DE기능이 아니다. DE 파라미터로 Control 할 수 없고 수행 로직이 다르기 때문.
- DE : Index unique scan 과 상관없이 select 절에 각 테이블 unique 컬럼만 있으면 수행
- DEUI : plan 상 operation 이 index unique scan 이면 언제든 수행 가능함. 그러나 Unique 인덱스 사용하지 않으면 DEUI는 수행되지 않음.
- SQL에서 FULL 힌트를 추가할 경우

- department 테이블을 FULL SCAN 하니 Plan 상에 HASH UNIQUE 가 발생.
- DE 수행 유무 - SELECT 절에 Unique 컬럼의 존재 유무에 따라 결정됨
- DEUI 수행 유무 - Access Path 가 INDEX UNIQUE SCAN 인지 아닌지에 따라 결정됨
- "원인 없는 결과는 없다"
- 서브쿼리 Unnesting 되어 Driving 집합이되면, 메인쿼리 집합 보존을 위해 default 로 distinct 가 추가되는데,
이 때 DE나 DEUI 기능이 수행되면 distinct 가 제거된다. - (서브쿼리 Unnesting 은 서브쿼리를 인라인뷰로 바꿔 정상적으로 조인으로 만드는 기능.)
- 서브쿼리 Unnesting 되어 Driving 집합이되면, 메인쿼리 집합 보존을 위해 default 로 distinct 가 추가되는데,
- DE는 10.2.0.4 에서도 수행되나, _optimizer_distinct_elimination 파라미터가 없는 것이 11g와 다른 점이다.
2.7 CNT (Count(column) To Count( * )) : Count(컬럼) 사용시 해당 컬럼이 Not Null인 경우 Count( * )로 대체하라
- CNT 기능 : Not Null 컬럼임에도 Count(컬럼) 을 사용하는 경우가 있는데, Logical OPtimizer는 Count( * ) 를 SQL로 바꾼다.

- 인덱스 : JOB_ID + DEPARTMENT_ID
- Count 함수에서 LAST_NAME 컬럼을 사용하여 테이블 액세스가 있어야 하나, CNT 기능으로 count( * ) 로 바뀌어 인덱스만 Scan 하였다.
- 10053 Trace


- CNT 기능은 항상 동작하는 것인가 ?

- FIRST_NAME 컬럼이 Null허용 컬럼이기 때문에 CNT 가 작동하지 않음
- 물리모델링 시 Not Null 컬럼이라면 Constraint 를 명시적으로 지정해야 한다.
- 가능한한 Count( * ) 를 사용하라. Not null constraint 가 있는 컬럼을 count 에 사용하지 않아야 한다.
2.8 FPD (Filter Push Down) : 조건절을 뷰 내부로 이동시켜라
- FPD는 뷰, 인라인뷰 밖에서 뷰 내부 컬럼을 이용하여 조건절을 사용할 때, 조건절이 뷰 내부로 침투되는 현상.

- 인라인뷰에 NO_MERGE 힌트 사용 이유 : SVM (Simple View Merging) 을 피하기 위해.
- SVM 발생 시 뷰가 해체되므로, 인라인 뷰로 파고드는 Filter 를 관찰할 수 없기 때문이다.
- a.job_id = 'MK_REP' 조건이 뷰 내부로 파고들었다. 그 결과 employee 테이블의 job_id 인덱스를 사용하였다.
- 10053 Trace

- 쿼리블럭 SEL$2 (인라인뷰) 에 FPD를 고려, 인라인뷰 내부에 조건절을 생성하였다.
- predicate Move-Around Title 에서 FPD 발생 확인할 수 있다. ( 특정한 Title 이 없기 때문에 PM 이 끝나고 FPD 가 실행됨 )
- Transformer 가 SQL을 아래처럼 변경함


- 위 SQL에서 인라인뷰 내에서 Group By 나 Distinct 를 사용하지 않음 ( 이러한 인라인 뷰를 Simple View 라고 함 )
- Simple view 에 적용된 FPD = Simple FPD
- 10053 Trace 에서 "simple filter push" 항목으로 확인할 수 있다.
- Group by, 집계함수 사용 시 이러한 Transformation 발생 = Cost Based Predicate Push Down 이라 한다. ( 3.1장 )
- Simple view 라 하더라도, 인라인뷰 내부에서 rownum 사용 / rank 분석함수 사용하면 FPD기능 사용할 수 없다.


- 인라인 뷰 내부에서 분석함수 (rank) 사용 시 FPD 기능 수행되지 않음을 확인할 수 있다.
- a.job_id = 'MK_REP' 조건이 view 외부로 밀려남