LGWR (by dolphhong) [2013.04.25]
chapter6. 기록과 복구
- Oracle의 ACID 중 내구성 (durability)을 어떤 방식으로 만족할까 ?
- dbwr (database writer) , lgwr ( log writer )
목표
- 오라클은 (buffered) 데이터 블록과 리두 로그 (버퍼) 내용을 디스크로 기록하는 전략을 고려해야 한다.
- 리두로그 버퍼의 내용이 더 중요. 최소한의 디스크 I/O 로 내구성을 제공해야 하기 때문
- 커밋된 트랜잭션에 대해서는, 인스턴스 장애시에도 유실이 없다는 것을 보장해야 한다.
- 복구의 핵심
- 리두로그 를 적절한 시점에 디스크로 기록하는 것.
- 복구시간 최소화를 위해 데이터베이스 블록 을 지속적으로 디스크로 기록해아 한다.
- 작업들을 정확한 순서(오래된 것 먼저) 모아서 한번에 처리. (데이터베이스 블록에 대한 기록 작업 횟수 최소화)
{info:title=write-ahead logging 전략}
- lgwr 이 블록의 변경 내역에 대한 리두로그를 디스크로 기록하기 전까지
dbwr은 변경된 블록을 디스크에 기록하지 않는다. - 리두로그 파일 + 아카이브 = 데이터베이스 최신 변경 사항
- 데이터파일 = 최근의 스냅샷.
- nologging 시 무효화
{info}
LGWR
- 로그 버퍼의 내용을 메모리로부터 디스크로 복사.
- 오라클 초기 버전은 로그 버퍼를 위해 하나의 연속된 메모리 영역을 할당함.
- public, private 버퍼 개념
- 로그 파일은 디스크 섹터 크기 (512 bytes)에 맞춰 자동으로 블록 포맷
- 로그 버퍼는 current 로그파일 ( 각 블록마다 16 byte헤더 존재 ) rolling window 방식으로 매핑된다.

- 블록의 숫자로, 11번째 재사용된 후 12번째 재사용 중임을 확인.
10g 이상에서는 log_buffer 파라미터 설정 필요 없다.
DB기동 시 인스턴스에 의해 자동적으로 설정되며, public 로그 버퍼 사이즈는 수 MB가 된다.
log buffer space 대기 이벤트에 영향을 받을 경우에는 로그버퍼 사이즈 확장을 위해 설정도 가능하다.
- 로그 버퍼는 래치에 의해 보호되어야 한다.
- 로그 버퍼의 사용에 영향을 미치는 세 개의 메모리 위치를 래치로 보호.
- 버퍼의 프리영역의 시작위치
- 프리영역의 끝 위치
- lgwr이 기록 중인지의 여부를 알려주는 플래그 ( write flag )
- 다수의 public 로그 버퍼인 경우, 버퍼 당 두개의 포인터가 존재. 플래그는 모든 버퍼에 대해 단 하나만 존재한다. (LGWR 은 하나이기 때문)

- LGWR이 기록 완료 -> 포인터 2는 LGWR에 의해 현재 기록되고 있는 영역의 끝 위치로 이동 -> LGWR은 더 많은 버퍼의 내용을 디스크로 기록하라는 요청을 받게됨
- 다른 세션들은 생성된 리두를 로그버퍼에 기록하기 위해, 포인터 1 (프리영역의 시작) 의 위치를 이동, 사용할 공간을 할당받는다.
- 포인터 1은 로그 버퍼의 우측 끝까지 이동한 후 , 다시 순환하여 로그 버퍼의 좌측 끝에서 부터 시작한다.
{note:title=LGWR의 기록작업}
- 매 3초 마다 알람 콜이 발생할 때
- (public) 로그 버퍼가 1/3 채워졌을 때
- (public)로그 버퍼가 1MB 이상의 변경 레코드를 가질 때
- 세션이 commit; 또는 rollback; 을 수행했을 때
{note}
- 트랜잭션의 내구성(durability)를 보장하는 commit/rollback 매커니즘
- 세션이 commit 을 수행하면
- 리두 (언두 세그먼트 헤더 블록 내의 트랜잭션 테이블 슬롯에 대한 변경과 관련된 리두) 를 생성,
- 해당 리두를 로그버퍼에 기록
- 언두세그먼트 헤더 블록을 변경
- lgwr 호출하여 로그 버퍼의 내용을 디스크로 기록하라고 요청
- lgwr이 기록을 완료할 때 까지 log file sync 대기이벤트 대기
- 롤백의 마지막 단계도, 롤백을 위해 언두 체인지 벡터 적용 후 최종 트랜잭션 테이블 슬롯 변경 후 lgwr호출
- 매 3초마다 lgwr이 rdbms ipc message 대기 이벤트 대기 ( 프로세스간 통신을 위한 대기 )
- 1MB , 1/3 이 채워진 경우를 확인하고자 한다면 단일 세션에서 array update 작업의 크기를 조정하면서 3개의 통게지표 확인
- 사용자 세션의 message sent
- redo size
- lgwr 의 message received
- 로그 버퍼를 3MB 보다 작게 설정한다면, 사용자 세션의 redo size 지표의 수치가 로그 버퍼의 1/3 이 되는 시점에 사용자 세션은 lgwr 에게 메시지를 전송한다. ( message sent 지표로 확인 )
- 로그버퍼가 3MB보다 크다면 redo size 지표 수치가 1MB 되는 시점에 메시지 전송
- lgwr은 한번에 3초간 sleep.
-> 사용된 로그 버퍼의 양을 확인하는 방법 ? 각 세션은 로그 버퍼에 공간을 할당받을 때마다 사용된 전체 크기를 체크한다. ( 프리영역 끝 - 프리영역 시작 위치간 차이 이용 )
사용된 전체 크기가 한계를 초과하면 세션은 리두를 로그 버퍼에 복사한 이후 lgwr에게 즉시 메시지 전송.
- 매우 빠르게 작은 량의 리두 발생하면 ?
-> 한계 초과 시점에 다수의 중복된 메시지 ( 기록 요청하는 ) 가 lgwr 에게 전송되지 않을지 ?
-> write flag 가 있어 이런 일은 발생하지 않을 것.
- LGWR은 기록을 시작할 때 write flag 설정하고, 기록 완료되면 write flag 해제.
- lgwr에게 메시지를 전송하려는 세션은 플래그를 확인한 후, lgwr이 현재 기록중이면 메시지를 전송하지 않는다.
- lgwr은 write flag 변경하기 위해 redo writing 래치 획득.
- 각 세션은 플래그를 읽기 위해 래치 획득.
- 두 래치 획득 모두 wiling-to-wait 모드 래치 획득한다.
message
- 3장에서 redo synch write 통계 : 세션이 commit 시에 lgwr에게 메시지를 전송한 횟수 -> 근사치 이다.
- 세션이 commit 을 수행한 시점에 이미 lgwr이 기록 중이면, 세션은 lgwr에게 메시지를 전송하지 않으며, redo synch write 통계만 증가 시킨다.
- 세션이 lgwr 에게 메시지를 전송하는 경우
- lgwr이 기록중이 아니라면 lgwr 은 런큐에서 빠져나와있는 상태. rdbms ipc messages 대기이벤트 대기
- 세션은 lgwr 을 다시 런큐에 등록하도록 OS에 요청
- 런큐에 등록된 lgwr은 기록을 시작한다.
- Lgwr은 자신을 깨운 세션 정보, 디스크로 기록할 로그 버퍼의 양을 확인할 필요가 없음
- 디스크로 기록할 만큼 기록한 후, 현재 런큐에서 빠져나와있는 세션 중에 log file sync 대기이벤트의 buffer# ( 대기 이벤트의 파라미터 1 )가 lgwr에 의해 기록된 마지막 buffer# 보다 작은 세션을 검색.
- 세션이 log file sync 대기 후 깨어났을 때, 작업 완료 확인. ( 11.1 : 1초 / 11.2.0.1 부터 설정 가능함. default 0.1초 )
- lgwr 의 기록을 완료한 위치, 프리영역의 끝 위치를 이용하여 요청 기록작업 ( buffer# ) 이 완료되었는지 확인
- LGWR 기록작업 완료
- active 세션 목록에서 log file sync 대기 세션 검색
- 마지막으로 기록한 buffer# 와 log file sync 대기 세션의 buffer# 를 비교한다.
- 세션의 buffer# 가 lgwr 이 마지막으로 기록한 buffer# 보다 작으면 lgwr 은 해당 세션들이 작업 재개하도록 포스팅함.
- lgwr 이 마짐가 기록 완료한 시점에 로그 버퍼 내 디스크로 기록해야 할 커밋 레코드가 존재 시, lgwr은 즉시 기록 시작.
PL/SQL 최적화
- 커밋 레코드를 로그 버퍼에 저장한 세션은 lgwr 에 의해 포스팅 되기 전 까지 log file sync 대기 이벤트를 대기함.
- PL/SQL 최적화의 경우 기록이 완료될 때 까지 항상 대기하지는 않는다.
- 500 Row 테이블의 매 20번째 row를 변경한다. ( 25번의 update, 25번의 commit 수행 )
begin
for r in (
select id from t1
where mod(id,20) = 0
) loop
update t1
set small_no = small_no + .1
where id = r.id;
commit ;
end loop;
end;
/
- 독립적으로 수행한다면 아래 성능통계/대기이벤트 예상
user commits (session statistic) 25
messages sent (session statistic) 25
redo synch writes (session statistic) 25
log file sync (session statistic) 25
messages received (lgwr statistic) 25
redo writes (lgwr statistic) 25
log file parallel write (lgwr statistic) 25
=> 같은 작업이 25번 반복적으로 수행되었다고 해석
- 사용자 세션이 커밋 수행
- 사용자 세션이 lgwr 포스팅 후 redo sync writes 성능통계 증가
- 사용자 세션이 lgwr 에게 포스팅될 때까지 log file sync 대기이벤트를 대기
- Lgwr 깨어남
- Lgwr은 로그버퍼의 내용을 디스크로 기록, 기록 시 마다 잠시 대기
- 실제 결과는 예상과 다르게 다음과 같이 나타남
user commits (session statistic) 25
messages sent (session statistic) 6 // 사용자 세션이 lgwr 에게 작업 요청한 count
redo synch writes (session statistic) 1
log file sync (session statistic) 1
messages received (lgwr statistic) 6
redo writes (lgwr statistic) 6
log file parallel write (lgwr statistic) 6
- 사용자 세션은 lgwr에게 6번 기록작업 요청
- redo sync write 는 한번 증가함.
- 내구성 요구사항 위반. 해당 루프 수행 중 인스턴스 장애 발생 시 커밋 트랜잭션 복구 불가함.
- 해당 동작의 이유 ?
- 사용자 세션은 전체 PL/SQL 블록 실행이 완료될 때까지, 얼마나 많은 트랜잭션 커밋이 되었는지 알지 모한다.
- 세션은 PL/SQL 블록이 종료되거나 제어를 반환하는 시점에 redo synch writes 성능통계를 증가, log file sync 대기 이벤트를 대기한다.
- 블록 마지막 문장에 dbms_lock.sleep을 추가하여 세션을 몇초 동안 정지 시킬 경우, lgwr은 로그버퍼를 비우게 된다.
- sleep 이후에 깨어난 세션은 lgwr의 상태를 확인하며 자신의 리두로그가 기록되었는지 확인한다.
- 이때 redo synch writes 성능통계 증가 / message sent, log file sync 대기이벤트는 발생하지 않는다.
{info}
- single database call 내부에서 커밋 수행
- 매 커밋마다 lgwr 을 호출하지 않는다.
- single database call이 종료되는 시점에 log file sync 대기이벤트를 대기 + redo synch writes 성능통계 증가
- 콜을 끝내려고 하는 동안 log file sync (redo synch writes 증가) 를 한번만 대기한다.
- PL/SQL 루프 내부에서 커밋 수행 시, 해당 트랜잭션은 인스턴스 장애 이후 복구 보장이 되지 않는다.
- 데이터베이스 링크 를 이용할 시 동일한 PL/SQL 루프 블록에서 매 커밋 시 마다 log file sync 대기이벤트를 대기한다.
{info}
- 은행 애플리케이션에서 PL/SQL 블록 이용하는 경우
- 계좌테이블의 각 로우마다 돈을 송금하는 외부 프로시저를 호출
- 호출 완료 시 각 로우를 UPDATE한 후 커밋 수행
- 이 시점에 장애 발생 시, 송금은 완료되고 (외부 프로시저) / 계좌테이블에 돈이 남아있는 경우(UPDATE) 가 존재할 수 있다.
- 2-phase commit 을 사용하지 않는 분산 트랜잭션은 항상 데이터 불일치를 유발할 수 있다.
- 루프 내에서 DB Link를 사용할 경우 내부적으로 2-phase commit 사용한다.
ACID 이상현상
- 다음과 같은 처리 순서에서 발생할 수 있는 문제점을 살펴본다.
- 트랜잭션 테이블을 변경하기 위한 체인지 벡터 생성
- 로그 버퍼로 체인제 벡터를 복사
- 언두 세그먼트 헤더에 체인지 벡터를 적용
- 로그 버퍼의 내용을 디스크로 기록하기 위해 lgwr 포스트
- 커밋 레코드가 기록되지 않은 시점에 (3 - 4 사이), 다른 세션들이 트랜잭션 변경 내역을 확인 할 수 있다.
- 3 - 4 단계 사이에 인스턴스 장애 발생 시, 커밋된 트랜잭션이 복구되지 않으며, 다른 세션의 데이터 불일치 현상 발생.
- 현상 재현
- 세션1 : oradebug를 사용하여 lgwr 정지
- 세션2 : 일부 데이터를 변경하고 커밋 수행. 세션은 hang상태가 됨
- 세션1 : 데이터 조회 시, 세션2 가 변경한 내용 확인 가능
- 세션1 : 인스턴스 장애 유발 (shutdown abort)
- 인스턴스 재시작 시 2단계 변경내용 확인 불가하다.
커밋 개선사항
- 10g 부터 커밋 최적화 파라미터 제공
- 10.2 : commit_write 커밋 동작 제어 옵션
- 11g : commit_logging , commit_wait 파라미터로 분리됨
- PL/SQL 루프 내구성 문제는 commit 모드를 commit write batch wait 으로 변경하여 해결함.
{note:title=COMMIT 명령} - commit write [batch|immediate] [wait|nowait]
- (11g) batch/immediate 여부 - commit_logging 파라미터로 설정 가능
wait/nowait - commit_wait 파라미터로 설정
NAME TYPE VALUE
----------------- -------- -----------
commit_logging string
commit_wait string
- (10g) commit_write 하나의 파라미터로 모든 설정 가능
{note} - PL/SQL 루프 실행하여 중요 지표 차이 ( Oracle 11.2.0.2 )
- 표6-1. commit_logging 과 commit_wait 의 효과분석

- wait 옵션 지정 시, 세션은 매 커밋마다 redo synch writes 성능통계 증가 + log file sync 대기이벤트 대기
- 적은 량의 많은 기록을 유발함. ( redo wastage, redo size, redo blocks written 성능통계 증가 )
- redo entries 수치가 25 , 50 - 25의 경우는 10g 리두 최적화 효과. ( 작은 트랜잭션에 대한 리두 체인지 벡터를 하나의 리두 레코드에 저장 하기 때문 (2장))
- Batch옵션 / Immediate옵션
- immediate 옵션 : commit change vector 가 별도 리두레코드로 분리되어, redo size 성능통계 증가함
- batch + nowait : 사용자 세션은 lgwr에게 어떠한 메시지도 전송하지 않는다.
( 커밋된 내용이 모두 복구를 보장해야 한다면, wait 옵션을 사용해야 한다. ) - batch + wait : 트랜잭션이 매우 작을 경우 성능면에서 유리
동작원리
- 로그 버퍼의 동작 원리
- 몇몇 개의 세션은 커밋 수행, 몇몇 세션은 리두 생성중, lgwr은 기록중인 시점을 나타낸다.

- c1 커밋 레코드를 생성한 세션은 lgwr을 포스팅
- lgwr 기록작업 시작 전, c2, c3 커밋레코드를 생성한 두개의 세션도 lgwr 포스팅
- c1,c2,c3 세션이 log file sync 대기이벤트 대기
( 즉, 세션이 lgwr을 포스팅 하는 시점과, 실제로 lgwr이 기록을 수행하는 시점 사이에 lgwr로의 중복 포스팅이 가능함. ) - lgwr은 redo writing 래치 획득, write flag 설정하고 해당 래치를 릴리즈
- 로그 버퍼내의 프리 영역의 시작 위치를 확인. (redo allocation 래치 획득)
- 해당 위치를 블록의 끝으로 이동 후, 해당 래치를 릴리즈하고 로그 버퍼의 내용을 디스크로 기록
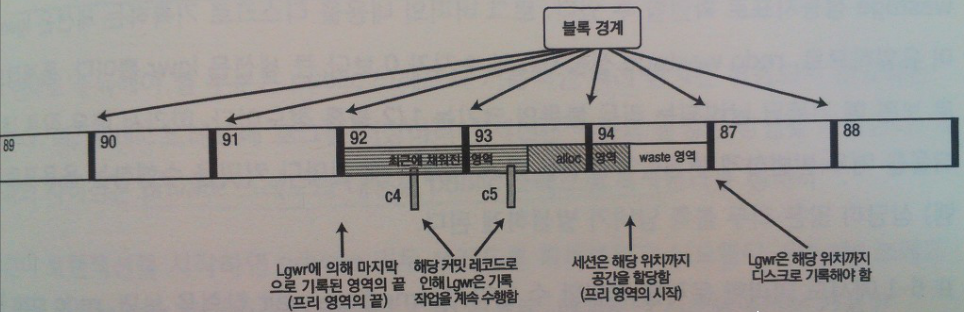
( lgwr 포스팅은 c1 커밋레코드지만, lgwr은 c2,c3 커밋레코드를 한번에 처리함. c2,c3 를 group 또는 piggyback 커밋이라고 함 ) - lgwr이 기록중일 때 추가적인 리두와 커밋 레코드 (c4,c5) 가 로그 버퍼내에 저장되었다.
- c4,c5를 저장한 세션은 redo writing 래치 획득 후 lgwr이 이미 기록중임을 확인하여 lgwr포스팅 하지 않고
redo synch write 성능통계 증가, logfile sync 대기이벤트를 대기한다. - 세션에 의해 할당되었지만, 리두 레코드를 복사하지 않은 "alloc" 영역
- lgwr 은 기록 완료 후, write flag 해제 ( redo writing 래치 획득 후 릴리즈 )
- "프리영역의 끝 위치"를 "lgwr에 의해 기록중인 영역의 끝 위치"로 이동 ( redo allocation 래치 획득 후 릴리즈 )
- log file sync 대기이벤트 대기세션 중 커밋 레코드가 디스크로 기록된 세션들을 런큐에 등록시키기 위해 OS로 신호 전송.
{info:title=우선순위 역전 (priority inversion)}
- 다수의 프로세스가 lgwr을 대기중, 동시에 깨어날 경우 해당 프로세스들에 의해 lgwr이 런큐에서 밀려나가는 문제 "우선순위 역전(priority inversion)
- CPU리소스를 lgwr이 프로세스들보다 많이 사용한 상태로, 프로세스들이 우선순위를 갖게되면서 lgwr이 작업 수행을 못하여 성능저하 발생
- lgwr우선순위를 높이거나 / cpu 리소스를 사용함에 따라 우선순위 감소시키는 룰을 lgwr에게 적용하지 말아야 한다.
{info}
- lgwr은 커밋레코드가 디스크에 기록되지 않아서 log file sync 대기이벤트 대기 세션이 존재하는지 찾는다.
- 존재한다면, 위 순서로 작업 반복한다.
- 세션에 의해 할당되었지만, 리두 copy 완료하지 않은 alloc 영역의 발생 원인?
(로그 버퍼에 리두를 저장하기 위해 세션이 수행하는 단계)- redo copy 래치 획득
( 래치 개수 = 2 * cpu_count ) immediate 모드로 순차적으로 시도 후, 마지막 redo copy 래치는 willing-to-wait 모드로 시도 - redo allocation 래치 획득
- 프리 영역의 시작 포인터를 이동
- redo allocation 래치 릴리즈
- 리두를 로그버퍼에 복사
- redo copy 래치 릴리즈
- 사용공간이 로그버퍼의 1/3 초과, 1MB 초과, 커밋레코드 존재 시 lgwr에 기록요청 ( 기록여부 확인 시 redo writing 래치 획득 )
- 리두레코드가 커밋레코드일 경우 redo synch writes 성능통계 증가, log file sync 대기이벤트 대기, 런큐에서 빠져나온다.
- redo copy 래치 획득
*세션이 로그버퍼 내 공간 할당받기 위해 redo allocation 래치 획득 시 버퍼 내 공간없을 경우 ?*
redo writing 래치 획득하여 lgwr이 기록중인지 확인
-> lgwr 이 기록중이 아닐 경우, lgwr포스팅하고 redo writing 래치 릴리즈
-> log buffer space 대기이벤트 대기
-> lgwr 기록 완료 후 log buffer space대기이벤트 대기 세션이 작업 재개 하도록 포스팅
-> lgwr이 기록중일 경우, 프리영역이 곧 만들어질 것으로 redo allocation 래치 획득 후 공간할당받음.
- 세션은 redo copy 래치 획득 후 로그버퍼 내 공간 할당받고 리두 복사한다.
- lgwr이 기록을 시작하기 전 "alloc" 영역의 존재 확인하는 방법은
- v$latchholder 참조하여 redo copy 래치 획득한 세션이 존재하는지 확인한다.
- redo copy 래치 획득 세션이 하나라도 존재한다면, lgwr은 LGWR wait for redo copy 대기이벤트 대기한다.
- 어떤 세션이 LGWR wait for redo copy 대기이벤트 중인 lgwr을 포스팅 ?
- LGWR wait for redo copy 대기이벤트의 parameter1 값이 이용된다.
- 해당 값은 copy latch# 를 나타낸다. 따라서 redo copy 래치를 릴리즈 하기 전, lgwr이 해당 래치를 대기하는지 확인 후, 대기할 경우 lgwr포스팅.
{panel:title=LOG FILE SYNC|borderStyle=dashed|bgColor=#FFFFFF|titleBGColor=#F0F0F0}
- log file sync 대기 이벤트 발생 시, 로그파일에 대한 기록 속도가 느릴 것이라 생각하는 것이 일반적이나, 반드시 그렇지는 않다.
- log file sync대기이벤트 대기 시점과 실제 작업 재개한 시점 사이에 많은 일이 수반된다.
- lgwr이 현재 기록중일 경우
- 현재 기록 완료 후 CPU리소스 할당받기 위해 대기.
- redo allocation 및 redo copy 래치 와 관련된 작업 수행.
- log file sync 대기이벤트 대기 세션을 포스트.
- lgwr이 현재 기록중이 아닐 경우
- 기록 완료한 lgwr이 디스크로 기록되지 않은 커밋 레코드가 있는지 확인.
- 해당 커밋 레코드 존재 시, lgwr은 기록 작업 시작 전 래치 관련작업 수행.
- 세션이 리두를 로그 버퍼로 저장하는 동안 대기.
- 완료 후 log file sync 대기이벤트 대기 세션을 포스트.
{panel}
리두낭비
- lgwr이 기록 요청을 받으면, redo allocation 래치 획득, "프리영역의 시작" 위치를 현재 블록의 끝으로 이동함.
- 8개의 블록으로 구성된 로그 버퍼
- 디스크로 기록해야 할 c4,c5 커밋레코드 존재
- 프리영역의 시작 위치를 블록의 끝으로 이동시킴으로써 블록의 일부 공간을 왜 낭비하는 것일까 ?
- 디스크 기록 작업 시, 디스크 섹터 단위로 수행되어야 함. ( 512byte : 리두블록크기 )
- "프리영역의 시작 위치" 를 블록의 끝으로 이동시키지 않으면, 섹터의 일부분만 디스크로 기록해야 한다.
- 이를 위해서 사전 읽기 작업을 통해 적절한 위치 찾기 작업이 필요하다.
- 다른 세션이 마지막 플록의 나머지 영역을 사용한다면, lgwr은 로그 버퍼 내의 동일한 블록을 또 다시 기록하거나
디스크로부터 이전에 사용한 섹터를 찾는 작업을 수행해야 한다. -> 성능문제 유발 - 따라서 오라클은 "프리영역의 시작" 위치를 블록 끝으로 이동하여, 블록을 기록하고, 기록된 블록은 다시 읽지 않는다.
- 이로 발생하는 공간 낭비는 redo wastage 성능지표로 확인 가능.
- 매우 작은 데이터들을 매우 빈번하게 변경 할 경우, 많은 리두 블록 낭비가 발생함.
- 표6-1 immediate wait 컬럼 : redo size 12.5KB , redo wastage 12KB
- 각 트랜잭션은 1블록 보다 조금 더 큰 크기를 (블록헤더 16bytes + 12,752/25 = 516bytes) 필요로 하여, 두번째 블록 나머지 공간을 낭비함.
- 4KB 섹터 크기의 디스크 사용 시 redo wastage 는 88KB로 증가. 트랜잭션 각각의 redo size 510bytes , 낭비공간 매 블록마다 3.5KB.
프라이빗 리두 (private redo)
- 10g 이후 향상된 기능인 private 로그 버퍼 - private 리두 쓰레드 / multi public 로그 버퍼 동작 원리를 설명한다.
- 사용되는 쓰레드의 개수
- private 및 public 쓰레드를 모두 동적으로 생성.
- 쓰레드 수 최소로 유지하려고 노력한다.
- redo allocation 래치 대기로 인해 sleep이 발생하는 경우에 한해 쓰레드의 수가 증가한다.
- 4개의 public 쓰레드, 20개의 private쓰레드 존재하는 시스템에서 6개의 세션이 30분간 작업 -> 1개의 public쓰레드, 6개의 private쓰레드 사용됨.
- Public 쓰레드의 기본 처리방식
- public쓰레드에 로그 저장하려는 세션은 기존과 동일한 방식을 사용.
- 차이점은 private 쓰레드의 내용을 public쓰레드로 복사한다는 점.
- 세션이 트랜잭션 시작 시 private 쓰레드 획득 시도하고, 존재하지 않으면 public 쓰레드를 사용한다.
- 각각 private 쓰레드는 자신의 redo allocation 래치를 소유, 해당 쓰레드를 사용하는 세션도 관련 래치를 획득해야 한다.
- private 쓰레드는 여러개 이지만, 래치 획득을 위해 willing-to-wait 모드를 사용
- 기록작업
- lgwr은 기록작업 요청 받으면, 모든 (active) public 리두 쓰레드를 차례로 기록해야 한다.
- 기록 요청이 한번이라도 리두관련 래치 획득/리두 대기를 수차례 반복해야 한다.