ch1.시작하기 (by kkabong) [2013.04.04]
1. 시작하기
오라클 메커니즘을 충분히 설명함으로써 데이터베이스 시스템에 발생한 문제를 스스로 해결 할 수 있도록 하는 것이다.
접근방법 :
프로세스 위주의 설명은 중요하지 않은 나열이 될 수 있고,
트렌젝션을 중심으로 설명하기 위해서는 Internal적인 지식이 필요하게 된다.
그래서 필자는 "오라클 메커니즘을 설명하는 가장 좋은 방법은 각 주제들을 반복적으로 점차 상세하게 설명하는 것이다"라고 주장한다.
A. 오라클 주요 프로세스들
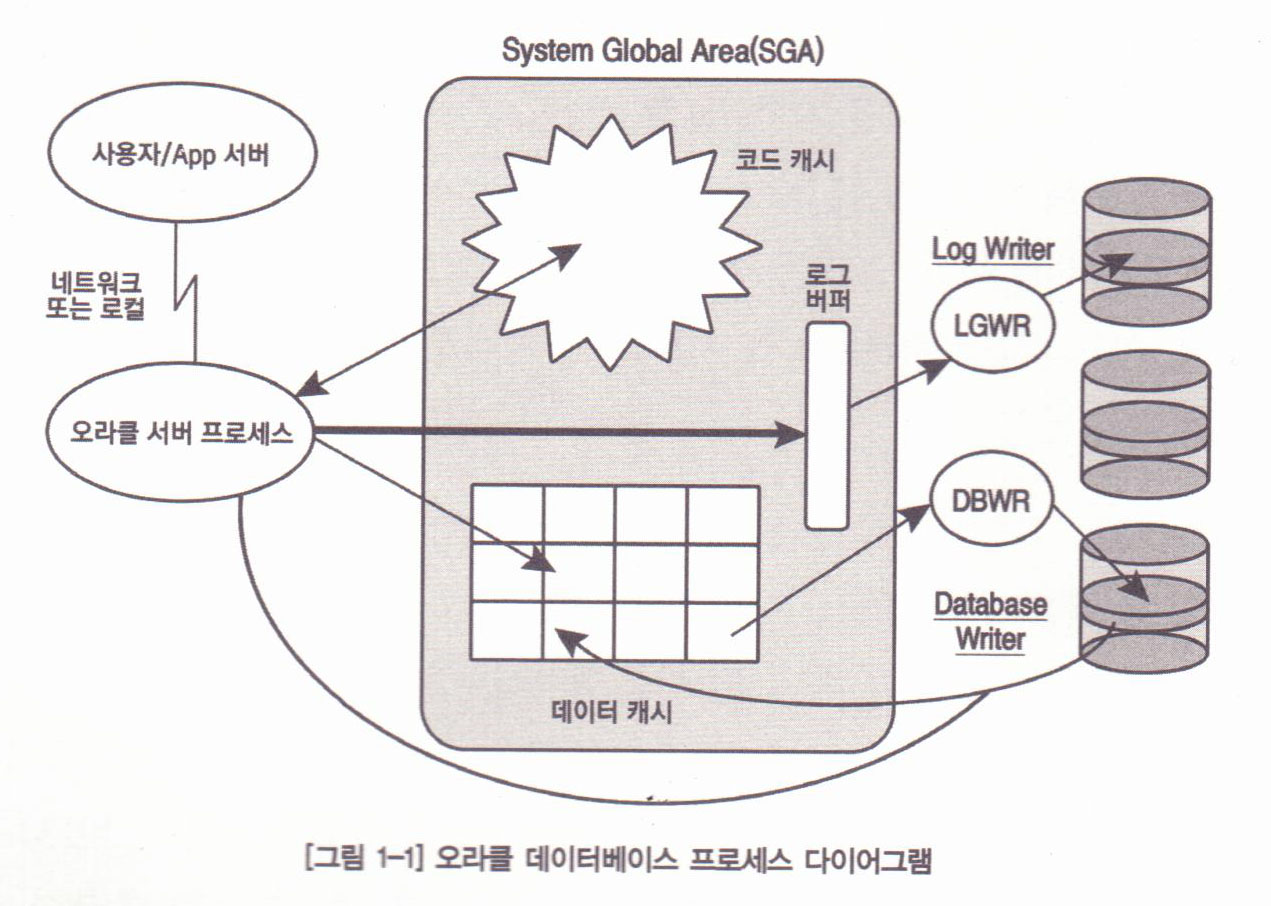
- 데이터파일은 "실제" 데이터를 보관하며, 리두로그파일은 데이터파일에 발생한 모든 변경사항의 목록을 연속적인 스트림 형태로 저장한다.
-랜덤액세스를 효율적으로 수행하기 위하여 동일한 I/O크기, 블록 크기를 가진다.
-다수의 데이터파일은 테이블스페이스라는 논리적인 오브젝트로 그룹핑할 수 있다. 테이블스페이스의 필수적인 세가지 유형은 UNDO테이블스페이스, TEMPORARY테이블스페이스, 및 "SYSTEM, SYSAUX"테이블스페이스 유형이다.
-기술적으로 데이터파일, 리두로그파일, 컨트롤파일 등 데이터 파일들을 데이터베이스라고 하며, 수행되는 프로세스와 SGA의 조함을 인스턴스라고 한다.
-RAC(Real Application Clusters)는 다수의 인스턴스로 구성할 수 있으며, 각 인스턴스는 독립된 장비에 설치될 수 있다. 하지만 모든 인스턴스는 동일한 데이터베이스를 공유한다.
-SGA내에는 인스턴스 활동성을 조정하기 위해 사용되는 "Clock"이 존재하며, 일반적으로 SCN(system change number)로 불린다.
-SGA를 액세스하는 모든 프로세스는 SCN을 읽고 수정할 수 있다
-오라클 메커니즘과 관련하여 가장 중요한 프로세스는 log writer, database writer, server process이다.
-Lgwr는 로그버퍼로부터 로그파일로 정보를 복사하는 프로세스이며, 인스턴스당 하나의 프로세스만 존재한다.
-Dbwr는 데이터 캐시로부터 데이터파일로 정보를 복사하는 프로세스이다.
-Server 프로세스는 SGA를 조작하고 데이터파일을 읽는다.
B. 동시성 관점에서의 오라클
오라클의 동작원리 :
서버 프로세스는 읽기 일관성을 가지고, 정확한 데이터를 획득해야하고 정확하게 데이터를 수정해야한다. 그리고 인스턴스는 정애로부터 데이터베이스를 보호해야 한다.
이슈 & 포커스 :
어떻게 데이터를 효과적으로 액세스할 수 있을까?
어떻게 데이터를 효과적으로 변경할 수 있을까?
어떻게 데이터베이스를 보호할 수 있을까?
어떻게 다른 사용자의 간섭을 최소화할 수 있을까?
데이터베이스에 문제가 발생할 경우 어떻게 이전 시점으로 원복 할 수 있을까?
C. 요약
효율성과 동시성이란 이슈를 해결하기 위한 오라클의 노력(메커니즘)에 대해서 설명할 것이다.