1. 옵티마이저 (by wooa1201) [2017.04.21]
01.옵티마이저
(1) 옵티마이저란?
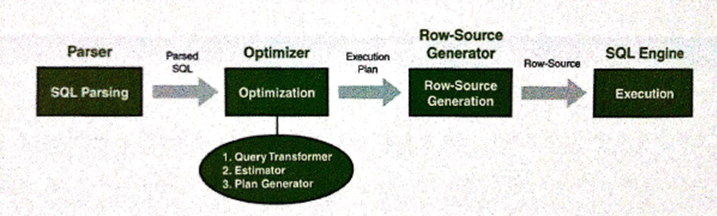
- 옵티마이저 (Optimizer)는 사용자가 요청한 SQL을 가장 효율적이고 빠르게 수행할 수 있는 최적(최저비용)의 처리경로를 선택해 주는 DBMS 의 핵심엔진
- 구조화된 질의언어(SOL)로 사용자가 원하는 결과집합을 정의하면 이를 얻는 데 필요한 처리절차(프로시저)는 내장된 옵티마이저가 자동으로 생성
옵티마이저 종류
- 규칙기반 옵티마이저(Rule-Based Optimizer, RBO)
- 비용기반 옵티마이저(Cost-Based Optimizer, CBO)
- 오라클 10g부터 RBO 에 대한 지원을 중단한다고 공식적으로 선언
(2) 규칙기반 옵티마이저
| 순위 | 액세스경로 |
|---|---|
| 1 | Single Row by Rowid |
| 2 | Single Row by Cluster Join |
| 3 | Single Row by Hash Cluster Key with Unique or Primary Key |
| 4 | Single Row by Unique or Primary Key |
| 5 | Clustered Join |
| 6 | Hash Cluster Key |
| 7 | Indexed Cluster Key |
| 8 | Composite Index |
| 9 | Single-Column Indexes |
| 10 | Bounded Range Search on Indexed Columns |
| 11 | Unbounded Range Search on Indexed Columns |
| 12 | Sort Merge Join |
| 13 | MAX or MIN of Indexed Column |
| 14 | ORDER BY on Indexed Column |
| 15 | Full Table Scan |
- 미리 정해 놓은 우선순위 에 따라 액세스 경로(Access Path)를 평가하고 실행계획을 선택
- OLTP 환경의 중소형 시스템이라면 RBO 규칙이 어느 정도 보편 타당성하지만,
데이터량, 값의수(number of distinct value), 컬럼 값 분포, 인텍스 높이, 클러스터링 팩터 같은 데이터 특성을 고려하지 않기 때문에 RBO는 대용량 데이터 를 처리하는 데 있어 합리적이지못할 때가 많음
(ex)조건절 컬럼 에 인덱스가 있으면 무조건 사용, 항상 인덱스를 신뢰하며, Full Table Scan과의 손익을 따지지 않음
- CBO에 대한 연구를 통해 특성을 파악하고, 데이터와 시스템특성에 맞는 통계정보 수집 정책을 수립함으로써 옵티마이저가 스스로 최적의 결정을 할 수 있도록 돕는 쪽에 역량을 집중하는 것이 바람직
(3) 비용기반 옵티마이저
- 비용을 기반으로 최적화를 수행하고, '비용(Cost)'란 쿼리를 수행하는데 소요되는 일량 또는 시간
- 전통적인 I/O 비용 모델에서는 I/O 요청(Call)횟수만으로 비용을 평가했지만 CPU 비용 모델에서는 CPU 연산 비용까지 감안
- 수행 일량을 상대적인 시간 개념으로 환산해 비용을 평가
- CBO가 실행 계획을 수립할 때 판단 기준이 되는 비용은 어디까지나 예상치, 미리 구해놓은 테이블과 인덱스에 대한 여러 통계정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고,이를 합산한 총비용이 가장 낮은 실행계획 하나를 선택
- 오브젝트 통계뿐만 아니라 최근에는 하드웨어적 특성을 반영한 시스템 통계정보(CPU 속도,디스크 I/O 속도 등)까지 이용
옵티마이저의 최적화 수행단계
1. 사용자가 던진 쿼리수행을 위해 후보군이 될만한 실행계획을 찾는다.
2. 데이터 딕셔너리(Data Dictionary)에 미리 수집해 놓은 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
3. 각 실행계획의 비용을 비교해서 최저비용을 갖는 하나를 선택한다.
동적 샘플링(Dynamic Sampling)
쿼리를 최적화할 때, 테이블과 인덱스에 대한 통계정보가 없거나 너무 오래돼 신뢰할 수 없을 때 옵티마이저가 동적으로 생플링을 수행
optimizer_dynamic_sampling 파라미터로 동적 샘플링 레벨을 조정하며. 9i에서 기본 레벨이 1이 던 것이 10g에서 2로 상향 조정
lOg에서는 쿼리 최적화 시 통계정보 없는 태이블을 발견하면 무조건 통적 샘플링을 수행
레벨을 0으로 설정해 동적 샘플링이 일어나지 않게 할 수 있으며. 9i 기본 값인 1로 설정할 때는 아래 조건을 모두 만족할 때만 동적 샘플령이 일어난다.
(1) 통계정보가 수집되지 않은 테이블이 적어도 하나 이상 있고
(2) 그 테이블이 다른 테이블과 조인되거나 서브쿼리 또는 Non-mergeable View에 포함되고,
(3) 그 태이블에 인덱스가 하나도 없고,
(4) 그 테이블에 할당된 블록 수가 32개(동적 샘플링을 위한 표본 블록 수의 기본 값) 보다 많을 때
레벨설정은 10 까지 가능(레벨이 높을수록 옵티마이저는 더 적극적인 동적 생플링을 수행하며 생플령에 시용되는 표본 블록 개수도 증가 )
동적 샘플링으로 얻은 통계정보는 데이터 닥셔너리에 영구 저장되지 않으며, 통계정보가 올바르지 않은 테이블을 참조하는 쿼리는 "하드 파싱할 때마다" 동적 샘플링을 위한 Recursive SQL이 추가로 수행(성능 저하, 통계정보를 관리 )

스스로 학습하는 옵티마이저(Self-Learning Optimizer)
v$sql, v$sql_plan_statistics, v$sql_plan_statistics_all, v$sql_workarea 등에 SQL별로 저장된 수많은 런타임 수행 통계를 보면 앞으로 옵티마이저의 발전 방향을 예상
옵EI마이저는 지금까지 오브젝트 통계와 시스댐 통계로부터 산정한 '예상'비용만으로 실행계획을 수립했지만 앞으로는 예상치가 빗나갔을 때 이들 런타임 수행 통계를 보고 실행계획을 조정
'스스로 학습하는 옵EI마이저' 를 9i와 lOg에서 선보이는 듯하더니 11g부터 이를 본격화
(ex)적응적 커서 공유(Adaptive Cursor Sharing) , 9i 동적 실시간 최적화(Dynamic Runtime Optimizations) 개념
(4) 옵티마이저 모드
alter system set optimizer_mode = all_rows ; --시스템 레벨 변경
alter session set optimizer_mode = all_rows -- 세션 레벨 변경
select /*+ all_rows */ * from t where ... -- 쿼리 레벨 변경
RULE
- RBO 모드를 선택하고자 할 때 사용
ALL_ROWS
- 쿼리 최종 결과집합을 끝까지 Fetch하는 것을 전제로 시스템 리소스(I/O, CPU,메모리 등)를 가장 적게 사용하는 실행계획을 선택
- DML 문장은 일부 데이터만 가공하고 멈출 수 없으므로 옹티마이저 모드에 상관없이 항상 all_rows 모드로 작동
- select 문장도 union, minus 같은 집합(set) 연산자나 for update 절을 사용하면 all_rows 모드로 작동
- PL/SQL 내에서 수행되는 SQL도 힌트를 사용하거나 기본 모드가 rule인 경우를 제외하면 항상 all_rows 모드로 작동
FIRST_ROWS
- 전체 결과집합 중 일부 로우만 Fetch하다가 멈추는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행계획을 선택
- 사용자가 만약 끝까지 Fetch한다면 오히려 더 많은 리소스를 사용하고 전체 수행 속도도 느려질 수 있음
- first_rows는 비용과 규칙 (=휴리스틱)을 혼합한 형태의 옵티마이저 모드로, 얼마만큼을 Fetch할지 지정하지 않았으므로 정확한 비용을 예측할 수 없고 따라서 옵티마이저는 내부적으로 정해진 규칙을 사용
(ex) order by 컬럼에 인덱스가 있으면 Table Full Scan 비용과 비교해 보지도 않고 무조건 그 인덱스를 이용해 sort order by 연산을 대체(RBO 규칙, 규칙을 사용하긴 하지만 통계정보를 이용하므로 비용기반 옵티마이저임 )
FIRST_ROWS_N
- 사용자가 처음 n개 로우만 Fetch하는 것을 전제로 가장 빠른 응답 속도를 낼 수 있는 실행계획 선택
- n으로 지정할 수 있는 값은 1, 10, 100, 1000 네 가지며, 사용자가 지정한 n개 로우 이상을 Fetch한다면 오히려 더 많은 리소스를 사용하고 전체 수행 속도도 느려질 수 있음.
- 힌트를 사용할 때는 괄호 안에 O보다 큰 어떤 정수 값이라도 입력 가능하므로 파라미터를 이용할 때보다 더 정밀하게 제어
- first_rows와 달리 first_rows_n은 완전한 CBO 모드로 작동
(ex)first_rows_100 이면 100개 로우를 가장 빨리 리턴할 수 있는 최저비용의 실행계획을 선택,Table Full Scan 비용이 오히려 낮다면 그것을 선택
CHOOSE
- 액세스되는 테이블 중 적어도 하나에 통계정보가 있다면 CBO, 그중에서도 all_rows 모드를 선택, 통계정보가 없으면 RBO를 선택
- 9i 까지는 choose 기본 설정이었으나 lOg부터는 all_rows가 기본 옵티마이저 모드로 설정
- 1Og부터 RBO를 공식적으로 지원하지 않게 된 탓이며, 동적 샘플링 기본 레벨이 2로 바뀐 것과도 무관하지 않음(통계정보 없는 테이블을 발견하면 무조건 동적 샘플링이 일어나기 때문에 RBO로 작동할 일이 없음)
옵티마이저 모드 선택
- 일반적으로 first_rows는 OLTP 환경에서,all_rows는 DW 나 배치 프로그램 등에서 사용
- 요즘과 같은 웹애플리케이션 환경에서는 OLTP 이더라도 대개 all_rows가 올바른 선택이 ( 애플리케이션에서 수행되는 쿼리 자체가 전체 범위 처리를 요구하기 때문)
- all_rows 모드는 SQL 결과 집합을 모두 Fetch 하기에 가장 효율적인 실행계획을 옵티마이저에게 요구하는 것이고, first_rows는 그 중 일부만 Fetch하고 멈추는 것을 전제로 가장 효율적인 실행계획을 요구하는 옵티마이저 모드
- DW 시스템 또는 배치 프로그램이라면 all_rows 모드를, OLTP일 때는 애플리케이션 아키텍처에 따라
(Ex) 2-Tier 환경의 클라이언트/서버 : first_rows 모드 ( 전체 결과집합이 아무리 많아도 사용자가 스크롤을 통해 일부만 Fetch하다가 멈춘 , 결과집합을 끝까지 Fetch하거나 다른 쿼리를 수행하기 전까지 SQL 커서는 오픈된 상태를 유지 )
3-Tier 구조 : 클라이언트와 서버 간 연결을 지속하지 않는 환경이므로 오픈 커서를 계속 유지할 수 없어 페이지 처리 기법을 주로 사용, rownum으로 결과집합을 10건 내지 20건으로 제힌하는 쿼리를 주로 사용
대량의 데이터에서 일부만 Fetch하다 멈추는 것이 아니라 집합 자체를 소량으로 정의
- 바인드 변수와 연관해 테스트해 보면 좀 더 복잡한 이슈들을 발견하게 되지만 그런 불합리한 요소들은 옵티마이저 버전이 올라가면서 개선될 것으로 판단
- 어차피 모든 SQL을 만족하게 하는 옵티마이저 모드는 현존하지 않음
- 애플리케이션 특성상 확실히 first_rows가 적합하다는 판단이 서지 않는다면 all_rows를 기본 모드로 선택하고, 필요한 쿼리 또는 세션 레벨에서 first_rows 모드로 전환할 것을 권고