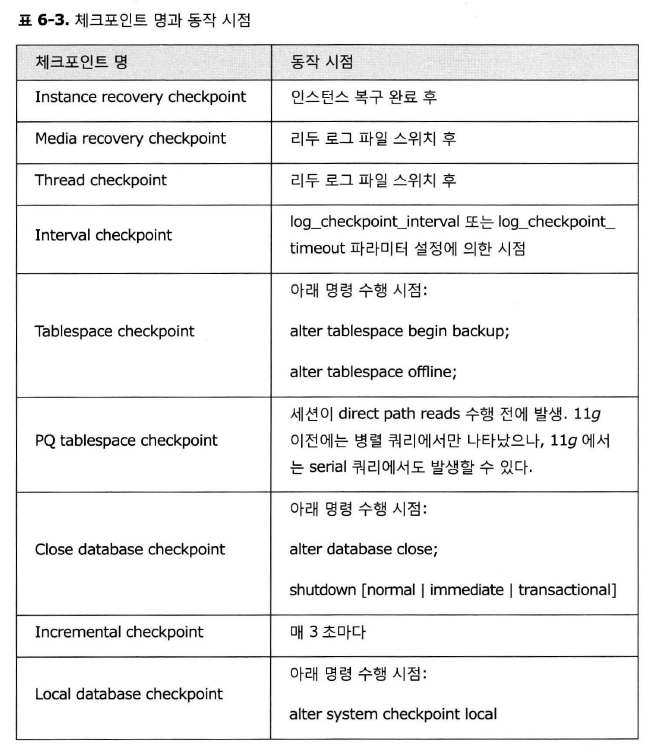
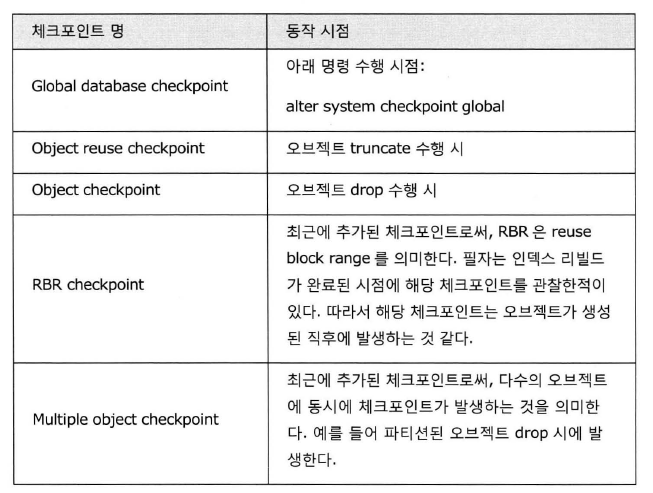
1.목표
- ACID (atomic:원자성, consistency:일관성, isolation:격리성, durability:내구성) 중 오라클이 어떤 방식으로 내구성을 만족하는지 확인
- 내구성의 요구조건 : 커밋된 트랜잭션에 대해서 인스턴스 장애시에도 유실이 없다는 것을 보장함
- 이에 대한 내용으로 메모리로부터 디스크로 정보를 기록하는 프로세서들인 dbwr(database writer), lgwr(log writer)을 살펴볼 예정임
2. LGWR
- 로그 버퍼의 내용을 디스크로 복사하는 프로세스
- 하나의 연속된 메모리 영역을 할당(이후 public, private 버퍼의 개념이 등장)
- 1개의 블록은 디스크 섹터 크기(보통 512바이트)에 맞춰 자동으로 포멧됨
- lgwr은 하나이며, 다수의 프로세스에 의해 변경되는 로그 버퍼는 래치에 의해 보호될 필요가 있음
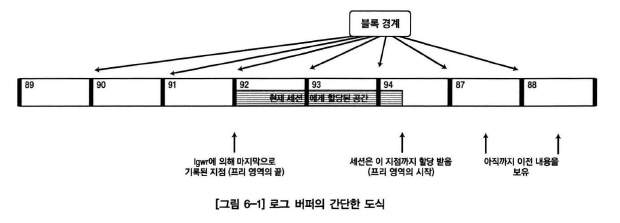
- 로그 버퍼는 2개의 메모리 위치 포인터, 1개의 플래그를 래치로 관리함
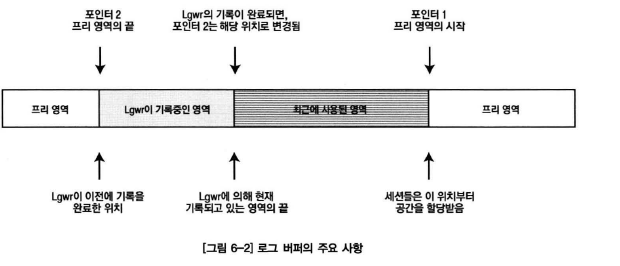
- 버퍼의 프리영역 시작지점, 버퍼의 프리영역 끝 지점을 나타내는 포인터
- lgwr이 기록중인지 여부를 나타내는 플래그
2.1 LGWR 기록작업
1. 매 3초마다
2. 로그 버퍼가 1/3 채워졌을 때
3. 로그 버퍼가 1M이상 변경 레코드를 가질 때
4. 세션이 commit 또는 rollback을 수행할 때
- 세션은 로그 버퍼에 공간을 할당 받을 때마다 사용중인 로그버퍼의 전체크기를 체크함 -> 1MB보다 크면 lgwr를 호출하여 기록하게 함
- lgwr은 기록을 시작할 때 write flag를 설정하고, 기록이 완료되면 해제하는 방식으로 짧은 시간내 많은 세션들로부터 기록 요청이 오는 것을 방지함.
- 동작 순서 : 세션이 lgwr 호출(런-큐에 등록)
-> lgwr이 로그버퍼를 디스크에 기록
-> lgwr이 log file sync 대기중인 세션 검색
-> lgwr이 기록한 버퍼번호와 대기중인 세션의 버퍼번호를 비교하여
lgwr이 기록한 버퍼보다 작은 세션들은 작업을 시작하도록 포스팅,
반대인 경우에는 다시 로그버퍼를 디스크에 기록
2.2 PL/SQL의 최적화
begin
for r in
select id from t1
where mod(id, 25) = 0
) loop
update t1
set small no small no + .1
where id r.id;
commit;
end loop;
end;
/
- 위 프로시저를 수행시키면 아래와 같은 통계데이터가 나올 것이라고 판단됨
user commits (session statistic) 25 <-- 세션의 커밋횟수
messages sent (session stati stic) 25 <-- 세션이 lgwr에게 전달한 메시지 수
redo synch writes (session statistic) 25
log file sync (session events) 25 <-- 세션이 로그 기록을 위해 대기한 수
messages received (lgwr statistic) 25 <-- lgwr이 세션으로부터 전달받은 메시지 수
redo writes (lgwr statistic) 25 <-- lgwr이 로그파일에 내려쓴 횟수
log file parallel write (lgwr events) 25
- 실제로는 아래와 같은 통계데이터가 나옴(PL/SQL 최적화)
user commits (session statistic) 25
messages sent (session statist ic) 6
redo synch writes(session statistic) 1
log file sync (session events) 1
messages received (lgwr statistic) 6
redo writes (lgwr statistic) 6
log file parallel write (lgwr events) 6
- 위와 같은 동작을 하는 이유
- 사용자 세션은 PL/SQL 블록을 실행이 완료될 때까지 얼마나 많은 트랜잭션이 커밋됐는지 알 수 없음
- 위 이유로 PL/SQL 블록이 종료될 때까지 복구를 위한 노력(로그파일에 기록됐음을 보장하지 않음)을 하지 않음
- PL/SQL 블록이 끝날 때, 한 번만 log file sync 를 대기함 --> PL/SQL 최적화
- 만약 PL/SQL 블록을 수행중에 인스턴스 장애가 발생하면 복구할 수 없음(rollback 처리됨)
- 단, PL/SQL 블록내에 DB LINK가 존재하면 매 커밋마다 log file sync를 대기함
- 은행의 송금업무 같은 원격지 데이터베이스 간에 트랜잭션이 발생할 경우 2-phase commit을 사용하여 데이터의 불일치를 막는다(원자성)
2.3 ACID 이상현상
1. 트랜잭션 테이블을 변경하기 위한 체인지 벡터를 생성
2. 로그 버퍼로 체인지 벡터를 복사
3. 언두 세그먼트 헤더에 체인지 벡터를 적용
4. 로그 버퍼의 내용을 디스크로 기록하기 위해 lgwr 포스트
- 위 리두로그 기록과정 중 3~4단계 사이에 인스턴스 장애가 발생하면 커밋된 트랜잭션은 복구되지 않으며, 해당 변경 내역을 이용한 다른 세션들은 데이터 불일치 현상이 발생할 수 있다.
- 아래과정을 통해 재현할 수 있음
1 세션 1: oradebug 를 사용하여 lgwr 을 정지시킨다
2. 세션 2: 일부 데이터를 변경하고 커밋을 수행하면 세션은 행(정지) 상태가 된다.
3. 세션 1: 데이터를 조회 하면 세션 2가 변경한 내용을 확인할 수 있다.
4. 세션 1: 인스턴스 장애를 유발한다 (shutdown abort).
- 하지만 lgwr의 장애는 많지않아, 위와 같은 장애 가능성은 희박함
2.4 커밋 개선사항
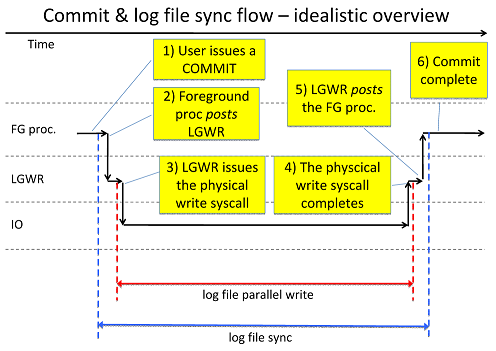
- 오라클 10g 부터 커밋 최적화를 위한 공개 파라미터 제공
- wait : 동기화 방식, 매 커밋마다 redo synch writes 성능통계를 증가, log file sync 대기이벤트를 대기(리두가 디스크에 기록되면 다음작업 실시), 내구성 보장
- nowait : 비동기화 방식, lgwr이 리두로그를 기록 여부 미확인, 데이터 손실 가능성 존재
- immediate : lgwr에게 리두로그를 디스크로 기록하라고 메시지를 바로 전달, commit change vecotr 별도의 리두 레코드로 분리, redo size 성능통계 다소 증가
- batch : 리두로그를 모아서 전달
2.5 동작원리
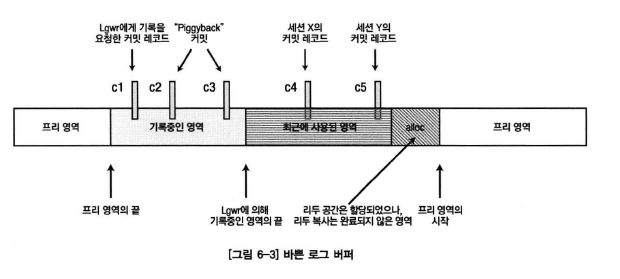
1. c1 세션 : lgwr 포스팅
2. c2, c3 세션 : lgwr 포스팅
3. lgwr : redo writing 래치 획득
-> write flag 설정
-> redo writing 래치 릴리즈
-> relod allocation 래치 획득
-> 프리 영역시작의 포인터 블록의 끝으로 이동
-> relod allocation 래치 릴리즈
-> 로그 버퍼내용을 디스크로 기록
4. c4, c5 세션 : 3번 작업중일 때 로그 버퍼에 커밋레코드 발생
-> redo writing 래치 획득
-> lgwr이 기록중임을 확인함
-> reo synch writes 성능 통계 증가
-> log file sync 대기이벤트 대기
5. lgwr : 로그버퍼 기록완료
-> write flag 해제(redo writing 래치 획득 후 릴리즈)
-> 프리 영역의 끝 위치를 lgwr에 의해 기록중인 영역의 끝 위치로 이동
(reo allocation 래치 획득 후 릴리즈)
-> log file sync 대기 이벤트를 대기중인 세션들 중 커밋 레코드가 기록된 세션들에게 포스트
-> 커밋 레코드가 기록되지 않은 세션이 존재하면 3번 작업 부터 반복
1. redo copy 래치 획득
2. redo allocation 래치 획득
3. 프리 영역의 시작포인터 이동
4. redo allocation 래치 릴리즈
5. 리두를 로그버퍼에 복사
6. redo copy 래치 릴리즈
7. 사용된 공간이 로그 버퍼의 1/3 또는 1MB초과한 커밋 레코드가 존재하면 lgwr에 기록 요청
8. 리두 레코드가 커밋 레코드인 경우에는 redo synch writes 성능통계를 증가시키고,
logfile sync 대기 이벤트를 대기한 후 런-큐에서 빠져 나옴
2.6 리두낭비
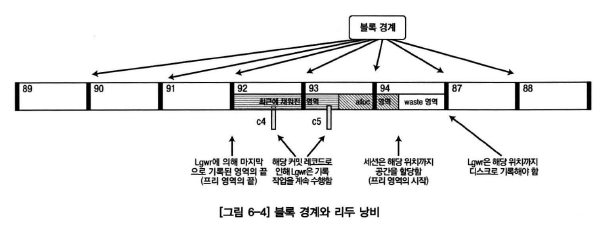
- "프리 영역의 시작 위치"를 지정할 때 블록의 끝을 지정함
- 일반적으로 그버퍼에 리두로그가 블록을 꽉 채우지 못하므로 마지막 블록은 낭비가 발생함
- 위와 같이 블록의 낭비를 감수하고 블록 단위로 포인터를 지정하는 이유
- 디스크로의 기록작업은 디스크 섹터 단위로 수행되며(보통 512바이트, 리두버퍼의 크기와 동일)
- 블록단위로 포인터를 지정하지 않으면 로그버퍼 1개의 블록이 2개 이상의 세션에서 기록될 수 있으며,
- 매번 디스크의 마지막 기록부분을 섹터단위로 검색해야 함
- 이러한 작업들은 심각한 성능저하를 유발함
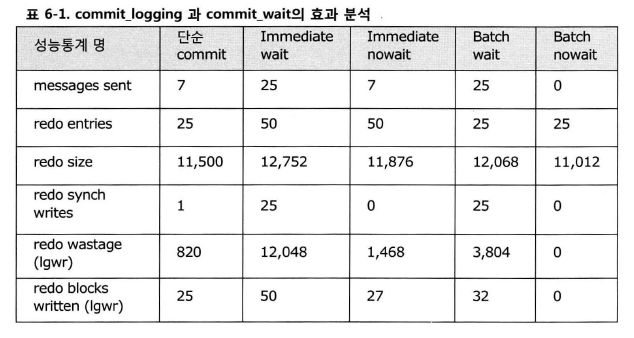
- redo wastage : 블록단위로 포인터를 지정함으로써 발생하는 공간의 낭비를 확인할 수 있음
- 매우 작은 데이터를 무척 빈번하게 변경한다면 많은 리두 블록 낭비가 발생할 것임(표 6-1 Immediate wait에서 확인가능)
2.7 프라이빗 리두(Private Redo)
- private 로그 버퍼(private 리두 쓰레드라고도 함) : Oracle 10g 부터 지원하는 기능
- 세션이 트랜잭션을 시작하면 private 리두 쓰레드를 획득하려고 시도함
- 대부분의 시스템에서 private 리두 쓰레드는 쉽게 획득하여 사용가능함(양이 많다)
- 각각의 private 쓰레드는 자신의 redo allocation 래치를 소유하며, private 쓰레드를 사용하려는 세션은 관련 래치를 획득해야 함
- 각 private 쓰레드의 내용을 public 쓰레드로 복사하며, public 쓰레드 처리 방식은 기존 리두로그 처리방식과 동일함
3. DBWR
- 오라클은 리두로그와 lgwr을 이용해 내구성을 유지함
- 디스크의 데이터블록에 리두로그를 모두 적용하면 현재 메모리상의 버퍼와 일치하게 됨
- 하지만 결국 데이터베이스 버퍼를 디스크에 기록해야함
- 위와 같은 방법을 적용하면 엄청나게 많은 시간이 소요되므로, 최소비용 전략을 사용해야 함
- 그 방법이 "가장 오래된 버퍼 먼저" 디스크에 기록하는 것임
3.1 체크포인트 큐
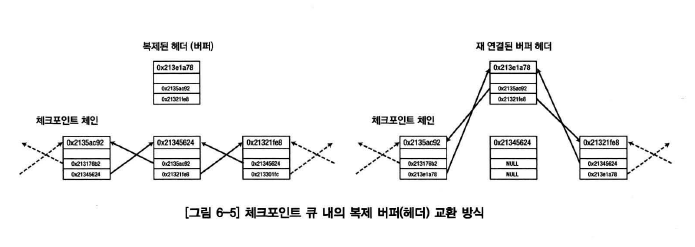
- 세션이 더티버퍼를 만들게 되면 checkpoint queue latch 래치를 획득하고 체크포인트 큐의 "최근" 끝 위치에 연결
- 블록 복제가 발생하는 경우에는 기존 버퍼를 큐에서 분리하고 해당 위치에 연결한다.
3.2 Incremental 체크포인트
- dbwr이 깨어나면 각각의 체크포인트 큐에 버퍼가 존재하는지 확인하고(checkpoint queue latch 래치 획득 후), 버퍼를 디스크로 기록한 후 큐로부터 분리
- 큐에 버퍼가 존재하지 않는다면 dbwr은 슬립하며, 이런 방식을 "incremental 체크포인트"라고 한다.
4. DBWR의 상호작용
4.1 DBWR과 LGWR의 상호작용
- lgwr은 dbwr이 데이터 블록을 디스크로 기록하기 이전에 리두로그를 남기는데 이는 dbwr이 데이터 블록에 변경사항을 적용하지 못해도 복구가 가능하다는 것을 의미한다.
- 만약 dbwr이 더티버퍼를 기록하기 직전에 또다시 버퍼에 변경이 발생하는 경우 lgwr을 포스트하고 건너띄어 다른 더티 버퍼를 기록한다.
- 작업이 완료되면 건너띈 버퍼의 로그가 기록됐는지 여부를 확인한다.
- dbwr은 더티버퍼를 디스크로 기록한 후 기록이 완료되었다는 리두 레코드를 생성하는데 이를 block written record(BWR)이라고 한다.
4.2 DBWR과 LRU
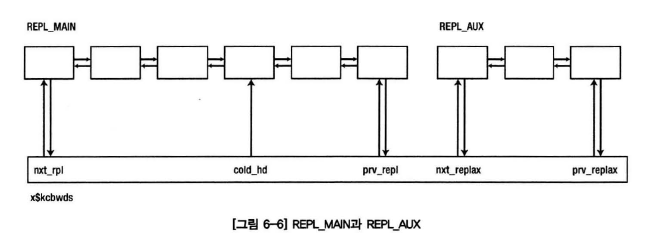
- REPL_AUX : 즉시 재사용이 가능한 버퍼들이 연결된다. 전체 버퍼의 25%를 유지하려고 하며, CR복제본이나 방문 횟수가 1이거나, 디스크로 기록될 필요가 없는 버퍼가 연결된다.
- REPL_MAIN : 현재 사용중이거나 사용했던 버퍼들이 연결된다. 왼쪽이 가장 최근에 사용된 버퍼, COLD로 갈 수록 사용빈도가 떨어진다.
- 랜덤 I/O가 매우 극심하게 발생하는 경우 : 대량의 블록을 메모리에 읽어들이면서 REPL_AUX는 소진되고, REPL_MAIN 리스트에 버퍼가 연결되어 점차 REPL_MAIN 리스트의 끝으로 이동할 것이다. 이 때 다른 세션이 비어있는 버퍼를 찾기위해서는 먼저 REPL_AUX리스트를 검색 후에 REPL_MAIN 리스트의 끝부터 검색을 시작한다. 일정 버퍼개수 이상을 검색하여도 여유버퍼를 찾지못하면, dbwr을 포스트하여 dbwr이 더티버퍼를 기록할 때까지 free buffer waits를 대기한다.
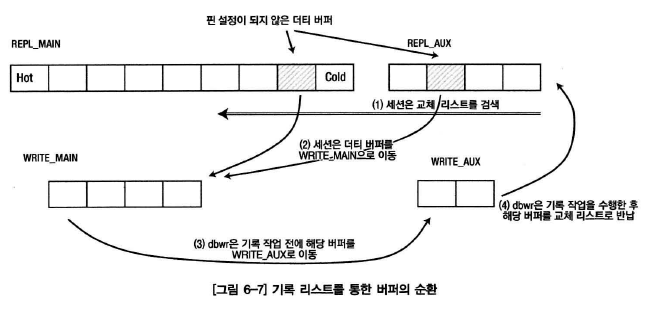
- 세션이 프리버퍼를 찾기위해 REPL_MAIN 리스트를 검색
-> 도중 더티 버퍼 발견
-> REPL_MAIN 리스트에서 분리한 후, WRITE_MAIN 리스트에 연결
-> 세션은 dbwr을 포스트하고 free buffer waits를 대기
-> dbwr은 WRITE_MAIN리스트에 연결된 버퍼를 WRITE_AUX에 연결
(만일 관련 리두로그가 기록되지 않았다면 lgwr을 포스팅하고 해당 더티블록은 건너띔)
-> WRITE_AUX에 연결된 더티버퍼를 배타적인 모드로 핀 설정 후 디스크에 기록
-> 기록작업 완료 후 WRITE_AUX 리스트에 분리하여 REPL_AUX에 연결, 체크포인트 큐에서도 분리
-> free buffer waits 대기하는 세션을 포스팅
4.3 체크포인트와 큐
- 체크포인트는 동기화를 의미한다.
- 데이터 블록이 체크포인트 이전에 변경되었다면, 변경된 내용은 디스크에 존재한다"는 것을 의미한다.
- 체크포인트 전에 생성된 리두는 불필요하다는 의미이다.
5. 복구
- 오라클은 복구에 적용되는 리두 로그의 양을 최소화하기 위해 "로그파일 스위치 체크포인트", "incremental 체크포인트", "BWR(block written records)"를 사용한다.
5.1 미디어 복구
- 인스턴스 복구와 미디어 복구의 차이점은?
- 백업을 정기적으로 수행하고, 온라인 리두로그 파일을 모두 보관하고 있다면 차이점은 없다.
5.2 Flashback 데이터베이스
- 데이터베이스 플래시백 기능을 활성하시키면 플래시백 로그가 생성됨
- 플래시백 로그는 블록의 전체를 보유(모든 블록이 아니고, 블록 1개)
- 단, 변경되는 블록의 일부만을 기록한다.(따라서 아카이브 리두를 이요한 복구가 필요하다)
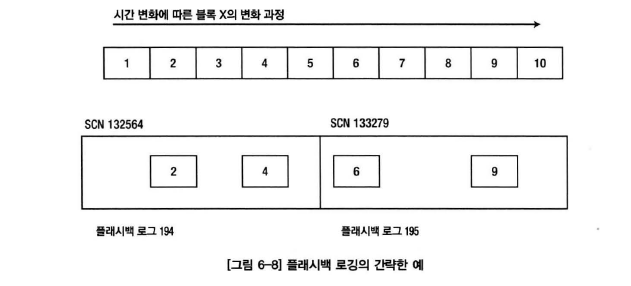
- 위 그림에서 SCN 132867시점으로 플래시백하며, 해당 SCN은 블록 3번에 해당된다고 가정하자
- 1단계 : 플래시백 하려는 시점과 가장 가까운 "이전" 시점의 블록을 선택 = 플래시백 로그 194
- 2단계 : 194번 로그 내에 저장된 블록들을 SCN 역순(최신버전부터) 읽어 목표 SCN보다 작은 SCN을 가진 첫번째 블록을 찾는다 = 블록 2번
- SCN 123564를 가진 아카이브 리두 로그파일로부터 복구를 시작하여 목표 SCN에 도달하면 복구를 중지한다.
- 커밋되지 않은 트랜잭션은 롤백을 수행한다.
5.3 부작용
- 플래시백 로깅을 활성화하면, 블록의 이전 버전을 디스크로 읽어 플래시백 로그에 기록하는 I/O 부하가 발생한다.
- 사용자의 실수로 인한 복구 시에는 아주 유용하다.
6. 요약
- 오라클은 write-ahead logging 전략을 사용한다.
- 이는 로그 버퍼의 변경 내용을 로그파일에 먼저 기록한 후에 데이터 블록을 디스크로 기록하는 것을 의미한다.
- 위와 같은 전략으로 트랜잭션 내구성을 보장한다.(커밋 옵션 중 nowait는 제외)
- 데이터베이스 블록은 변경 즉시 디스크로 기록되지 않으며, 2가지 전략을 통해 기록된다.
- 하나는 가장 오래전 변경된 블록을 기록하는 것이며, 다른 하나는 LRU/TCH 알고리즘에 의해 캐시로부터 밀려나갈 때가 된 더티 블록을 기록하는 것이다.
- 세션은 프리버퍼를 검색할 때, REPL_AUX 검색 -> 더티버퍼 WRITE_MAIN 리스트로 이동 -> DBWR이 WRITE_MAIN리스트에 연결된 버퍼를 WRITE_AUX로 이동 -> 디스크 기록 -> 기록완료된 버퍼 REPL_AUX 리스트로 이동한다.
- 체크포인트가 완료되면 로그파일내의 모든 변경사항이 데이터 블록에 적용되었다는 것을 의미한다.