개요
- 오라클은 경합에 의해 공유 자원이 손상되지 않도록 4개의 메커니즘 제공: 1) 락(lock), 2) 래치(latch), 3)핀(pin), 4)뮤텍스(mutax)
| 구분 | 락 | 래치 | 핀 | 뮤텍스 |
| 동작방식 | 순서대로 | 순서 무관 | 순서대로 | 순서 무관 |
| 보호대상 | 오브젝트 | 공유 메모리 | | |
| 지속시간 | 길다 | 짧다 | | |
자료구조
- 배열
- 동일한 형태와 크기를 갖는 오브젝트들의 목록
- 동일한 크기이므로 배열 내의 오브젝트를 쉽게 검색
- 예) x$ksuse(v$session 뷰의 기반 구조)
- segmented 배열
- 배열을 생성하는 시점에는 고정된 레코드 개수를 위한 메모리 청크를 할당한 후, 필요할 경우 동적으로 메모리 청크를 할당하는 구조
- 청크들의 리스트를 유지하며, 각 청크들은 리스트 내의 다음 청크에 대한 정보를 포함
- 예1) x$ktatl(v$resource_limit 뷰 내의 temporary_table_locks에 해당되는 항목) : 144bytes의 16개 레코드로 시작, 16개 레코드의 청크 단위로 확장(10g)
- 예2) x$ksqrs, x$ksqeq: 훨씬 큰 배열(?) 로 시작, 32개 레코드 청크 단위로 확장
- 포인터
- 메모리 공간주소를 가리키는 변수
- 예1) x$ksmfsv
- 링크드 리스트
- 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조
- 분류
- 단일 링크드 리스트, 이중 링크드 리스트
- FIFO 링크드 리스트, LIFO 링크드 리스트
- 오라클에서는 대부분 이중 링크드 리스트를 사용
- 리스트 내의 다음 항목뿐 아니라 이전 항목까지 포함
- 예1) 트랜젝션 테이블
- 해시 테이블
- 컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조
- 해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산한다.
- 배열과 링크드 리스트 문제점: 원하는 항목을 찾기 위해서는 배열 또는 리스트 전체를 검색해야 한다.
- 오라클은 동시에 매우 작은 대량의 메모리 구조를 처리하기 위해 해시 테이블 사용
- 다수의 항목들이 지속적으로 생성되고 제거되는 환경에서 원하는 항목을 항상 빨리 찾을 수 있다.
- 해시함수의 중요 원칙
- 다른 입력 값이 동일한 해시 값으로 해시 될 수 있다.
- 사용자들은 동일한 버킷에 많은 항목이 연될되는 것을 원치 않는다.
- 일부 해시 알고리즘은 다른 알고리즘에 비해서 보다 균등하게 데이터를 분산시킨다.
- 해시 알고리즘은 동일한 오브젝트에 대해서는 항상 동일한 버킷에 위치시켜야 한다.
- 사용자들은 적용하기에 유용한 해시 알고리즘을 원한다.
- 예) 라이브러리 캐시
 |
- 해시 버킷에 대한 접근
- 세션(a)는 첫 번재 해시 버킷 내의 오브젝트를 사용하려고 한다. <<< 해시 체인 리스트
- 세션(b)는 프리 메모리를 확보하기 위해 동일한 해시 버킷 내에서 특정 오브젝트를 제거하려고 한다. <<< 메모리 프리 리스트
- 만일 동시에 해시 버킷에 대한 접근을 허용한다면, 세션(b)가 오브젝트를 제거한 후 양쪽에 위치한 오브젝트들의 포인터를 변경하기 전에, 세션(a)가 해당 오브젝트들을 접근할 수 있다.
- 이 문제를 방지하기 위해서는, 세션(a)가 링크드 리스트를 접근할 때는 세션(b)가 링크드 리스트를 변경할 수 없도록 하고, 세션(b)가 링크드 리스트를 접근할 때는 세션(a)가 링크드 리스트를 변경할 수 없도록 해야 한다.
래치
- 개요
- SGA 내의 메모리 위치와 해당 위치의 값을 확인하고 변경하기 위해서 사용할 수 있는 atomic CPU 연산의 조합
※ atomic CPU 연산: 한번에 단 하나의 CPU만 메모리의 특정 위치를 액세스하도록 메모리 버스에 락킹을 설정하는 것 - 유형: exclusive 래치, shared read 래치, sharable 래치(exclusive 모드로 shared read 래치를 획득)
- 획득하는 방식: willing to wait방식, immediate 방식
- 래치의 숨겨진 로직(?)
- 기본 로직: 래치 메모리 위치를 특정 값(N)으로 설정할 수 있다면, 래치가 보호하는 구조를 사용(또는 변경) 할 수 있다. 그리고 완료된 후, 이전 값으로 변경한다.
- exclusive 래치 획득 의사코드
- 레지스터 변수 X는 래치 주소 A를 가리키도록 설정
- 만일 주소 A의 값이 0이면 0xff로 설정 <<< atomic
- 만일 주소 A의 값이 0xff로 설정되었다면, 래치를 "소유"
- 만일 그렇지 않다면 처음으로 되돌아가서 재 시도 (수천 번 동안)
- sharable 래치 획득 의사코드 (compare and swap 연산)
- 플래그 F를 0으로 설정
- 레지스터 변수 X는 래치 주소 L을 가리키도록 설정
- 레지스터 변수 Y는 L에 저장된 현재 값을 저장하도록 설정
- 레지스터 변수 Z는 새로운 값을 설정
- 만일 "Y의 값" = "L의 값" 이라면, L을 "Z의 값"으로 설정하고 플래그 F를 1로 설정 <<< atomic
- 만일 플래그 F가 1로 설정되었다면, 래치 값은 수정된 것이다.
- reader 래치 획득 의사코드
- 수천 번 loop(스핀) 수행
- 만일 write bit가 설정되었다면 loop의 처음으로 이동
- 래치 value를 value+1로 설정하기 위해 시도 (읽기 권한을 획득하기 위함) <<< 래치의 획득 및 해제를 스스로 카운트
- 만일 플래그가 설정되면 loop를 빠져 나옴
- writer 래치 획득 의사코드
- 수천 번 loop(스핀) 수행
- 만일 write bit가 설정되었다면 loop의 처음으로 이동
- 래치 value를 "write bit + current value"로 설정하기 위해 시도 (write bit을 획득하기 위함)
- 만일 플래그가 설정되면 loop를 빠져 나옴
- Reader Value가 0이 될 때까지 대기
- 오라클에서 발생하는 읽기/쓰기 충돌에 대한 해법은 위 설명한 것보다 좀 더 정교하다.
- 래치 실패
- 래치 획득 실패 시: 스핀(spin) 방식, 포스팅(posting) 방식
- 스핀 방식
- 세션은 짧은 간격 후에 스스로 깨우도록 알람을 설정하고, 스스로를 운영체제의 런-큐에서 제거한다. (슬립 상태)
- 운영체제의 스케줄러에 의해 다시 런-큐에 등록될 때는 큐의 상단에 위치하게 되고, 래치를 획득하기 위해 루프를 수행한다.
- 만일 또 다시 래치 획득을 실패하면, 다시 슬립 상태로 빠지게 된다. <<< 슬립 시간은 exponential backoff 알고리즘 사용
- 포스팅 방식
- 필요한 래치를 획득하지 못한 프로세스는 스스로를 latch wait list에 등록한 후 다른 프로세스에 의해 깨워질 때까지 슬립한다.
- 슬립하기 전에 해당 세션이 수행한 일은, 래치를 획득하려는 모드와 해당 시점의 래치의 상황에 따라 다양한 변형이 존재한다.
- 래치를 소유한 프로세스는 래치를 릴리즈할 때 리스트의 맨 앞에 위치한 프로세스를 포스트 한다.
- latch wait list에 등록된 프로세스가 존재하는 시점에 다수의 프로세스들이 해당 래치를 획득하려고 시도하는 경우, 새로운 프로세스가 래치를 획득할 가능성이 존재한다.
- 세션 1이 exclusive 래치를 획득한다.
- 세션 2가 exclusive 래취를 획득하려고 시도한 후 슬립 한다.
- 세션 1이 래치를 릴리즈하고 세션 2를 포스트 한다.
- 세션 2가 시작하기 전에 세션 3이 래치를 획득한다.
- 세션 2는 깨어나고, spin을 수행하고, 다시 슬립해야만 한다.
- 이와 같은 이유로 발생하는 sleep 수는 오라클이 제공하지 않지만, 하나의 latch miss는 하나의 spin_get 또는 sleep이 된다는 사실을 통해 sleep의 수를 추정할 수 있다. <<< sleeps + spin_gets - misses는 0을 초과
- 대량의 래치 활동성으로 큐의 길이가 길어지는 부작용 발생
- 설계자/개발/코더로써, 대량의 래치 활동성을 유발하지 마라. 예들 들어, 하나의 job을 매우 많은 수의 작은 단계로 분리하지 마라.
- DBA로써, 래치의 수를 증가시킬 필요가 있는지 확인하라. 데이터 내의 핫-스팟을 식별한 후 해당 데이터를 더 많은 블록을 분산시킬 방법을 찾아봐라. 그리고 최신 패치를 눈 여겨 보는 것도 좋은 생각이다.
- 오라클 사의 설계자/개발자로써, 래치 활동에 대한 의존을 줄일 수 있는 매커니즘을 생성하라(이를 위해 pin과 mutex가 개발되었다.)
- 래치 확장성
- 래치 경합과 관련해서 고려해야 할 사항
- 얼마나 많은 래치들이 라이브러리 캐시를 보호할 것인가? 많은 래치가 존재한다면 각각의 래치에 의해 보호되는 링크드 리스트에 대한 충돌은 감소하나, 유지 관리, 리포팅 또는 가비지 컬렉션 등의 일을 더 많은 일을 해야 한다.
- 얼마나 자주 래치를 획득하기 위한 절차를 수행할 것인가? 래치를 획득하고 리스트를 검색하는 횟수가 증가할수록 다른 프로세스와 충동할 가능성은 높아진다.
- 얼마나 길게 래치를 소유할 것인가? 래치를 소유하는 시간이 길수록 다른 프로세스들과 충돌이 발생할 가능성은 높아진다.
- 오라클 10g까지 라이브러리 캐시를 보호하는 래치의 개수는 CPU 수(대략 cpu_count 파라미터와 동일)에 따라 결정되며, 최대 67개이다.
- 예) 필자 시스템: 라이브러리 캐시 래치가 3개로 131,072 버킷을 보호
- 래치의 수가 적으므로, 오브젝트를 찾기 위해 라이브러리 캐시를 검색하는 횟수를 최소화하는 매커니즘이 필요 : KGL Lock과 KGL Pin <<< 오라클 11g에서는 뮤텍스로 대체 (7장 참조)
락(Lock)
lock과 enqueue 간의 차이점
"차이점 없다"
동일한 개념에 대한 두개의 단어이자만, 문서에서는 "lock"을 사용하는 경향이 있는 반면, 내부 구조와 인스턴스 활동 통계는 "enqueue"를 사용한다.
| type | id1 | id2 | 내용 |
| PS | 1 | 4 | 인스턴스 1번에서 수행되는 병령 수행 슬레이브 P0004를 의미 |
| TM | 80942 | 0 | object_id가 80,942인 테이블을 의미 |
| TX | 65543 | 11546 | 트랙잭션이 사용하는 언두 세그먼터의 1번(trunc(65543 / 16 4 )), 슬롯은 7번(mod(64443, 16 4 ))이며 해당 슬롯은 11,546번 재 사용된 것을 의미 |
- 리소스에 대한 소유 및 락킹을 관계를 표현하기 위해 사용되는 배열
- 주요 배열: x$ksqeq(generic enqueue), x$ktadm(table/DML locks),x$ktcxb(transactions)
- 그 외 배열: x$kdnssf, x$ktatrfil, x$ktatrfsl, x$ktatl, x$ktstusc, x$ktstuss
- v$lock과 메모리 배열(x$)
| x$ 컬럼 | v$lock | 비고 |
| KSQLKMOD | lmode | |
| KSQLKREQ | request | |
| KSQLKCTIM | ctime | |
| KSQLLKBLK | blcok | |
| KSQLKSES | sid | 락킹 세션 주소 |
| KSQLKRES | type, id1, id2 | 리소스의 주소 |
- 리소스 보호 매커니즘
- x$ksqrs 구조로부터 하나의 로우를 획득한 후 리소스를 식별하기 위한 표시를 한다.
- x$ksqeq 구조(또는 동등한)로부터 하나의 로우를 획득한 후 락 모드를 설정하고, x$ksqrs 구조의 로우와 연결한다.
- 세션37: 부모 테이블의 레코드 1과 관련된 자식 테이블의 레코드를 삭제한다.
- 세션36: 부모 테이블의 레코드 2와 관련된 자식 테이블의 레코드를 삭제한다.
- 세션39: exclusive 모드로 자식 테에블에 락을 시도한다.그리고 대기를 시작한다.
- 세션37: 부모 테이블의 레코드 1을 삭제하려고 한다 시도한다. 그리고 FK 인덱스의 부재로 인해 대기를 시작한다.
- 세션35: 부모 테이블의 레코드 3과 관련된 자식 테이블의 레코드를 삭제한다. 그리고 대기를 시작한다.
{info:title=Foreign key 락킹}
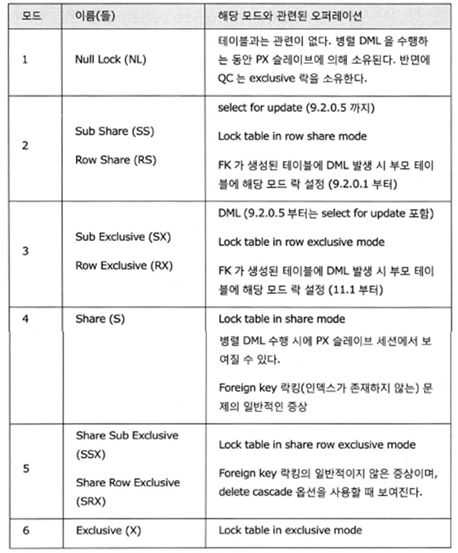
테이블에 foreign key 제약조건을 선언하고, 해당 제약조건을 위한 인덱스를 생성한지 않았다면, 부모 키를 삭제 또는 변경하려고 시도하는 세션은 자식 테이블에 share락(모드 4)을 설정하려고 한다.
하지만 만일 해당 세션이 부모 테이블을 변경하기 전에 자식 테이블에서 몇 개의 로우를 삭제했다면, 해당 세션은 이미 자식 테이블에 대한 subexclusive락(모드 3)을 획득한 상태이다. 이것은 락 모드를 up-convert해야 한다는 것을 의미한다. 이 경우 락 모드를 5로 변환해야 한다.
{info}
 |
- 커밋 시나리오
- SID 36이 커밋을 수행하면, owners 리스트를 빈 상태가 된다. 이로 인해 SID 37은 converts 리스트에서 owners 리스트로 이동하고, 모드 5로 락을 획득하고 ctime을 다시 0으로 설정한다. SID 39와 35는 여전히 waiters 리스트에 위치한다.
- 그 이후에 SID 37이 커밋을 수행하면, owners 리스트는 다시 빈 상태가 된다. 이로 인해 SID 39는 owners 리스트로 이동하고, 모드 6으로 락을 획득하고, ctime을 0으로 설정한다. SID 35는 waiters 리스트의 가장 앞에 위치하게 되지만 owners 리스트로는 이동할 수 없다. 이미 SID 39가 테이블에 대한 exclusive(모드 6) 락을 획득했기 때문이다.
- 그 이후에 SID 39가 커밋을 수행하면, owners 리스트는 다시 빈 상태가 된다. 이로 인해 SID 35는 owners 리스트로 이동하고, 모드 3으로 락을 획득하고 ctime을 0으로 설정한다.
- Enqueue 트레이스
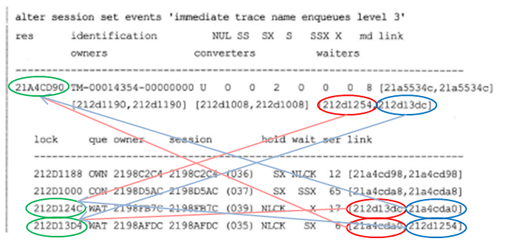 |
- 데드락
- 데드락 시나리오™
- 세션37: 부모 테이블의 레코드 1과 관련된 자식 테이블의 레코드를 삭제한다.
- 세션36: 부모 테이블의 레코드 2와 관련된 자식 테이블의 레코드를 삭제한다.
- 세션37: 부모 테이블의 레코드 1을 삭제하려고 시도한다. 그리고 FK 인덱스의 부재로 인해 대기를 시작한다.
- 세션36: 부모 테이블의 레코드 2을 삭제하려고 시도한다. 그리고 FK 인덱스의 부재로 인해 대기를 시작한다. <<< 데드락
- 세션37: 3초 내에 데드락을 감지하고 명령어 레벨의 롤백을 (자동적으로) 수행한다.
- 위와 동시에 데드락 트레이스 파일을 생성하고 "deadlock detected"를 의미하는 ORA-00060 에러를 발생시킨다.
{tip:title=TM enqueue 동작방식}
TM 락을 대기하는 세션은 매 3초마다 깨어나서 테이블에 설정된 모든 락 상태를 점검하고, (일반적으로) 다시 3초를 대기한다.
오라클은 이러한 타임아웃 방식을 이용하여 데드락을 감지한다.
{tip}
- TX 데드락
- 트랜잭션 테이블 슬롯은 단일 트랙잭션에 의해 수행된 모든 일들에 대한 시작점이고, 트랜잭션에 의해 변경된 데이터 및 인덱스 블록내의 ITL은 트랜잭션 테이블 슬롯을 가리킨다. (3장 복습)
- 트랜잭션을 실행중인 세션은 트랜잭션을 위한 enqueue 리소스(유형은 TX, id1은 언두 세그먼트 번호와 슬롯은 번호를 나타내며, id2는 슬롯 시퀀스 번호를 의미)를 생성함으로써 트랜잭션 테이블 슬롯에 락을 설정하고, 락 모드 6(exclusive)로 x$ktcxb 구조에 enqueue를 등록한다.
- 만일 첫 번째 세션에 의해 변경되었지만 아직 커밋 되지 않은 로우를 두 번째 세션이 변경하려고 한다면, 두 번째 세션은 첫 번째 세션의 TX 리소스를 위한 enqueue를 waiters 리스트에 등록한다.
- 만일 이 시점에, 두 번째 세션에 의해 변경되었지만 아직 커밋 되지 않은 로우를 첫 번째 세션이 변경하려고 한다면, 첫 번째 세션은 두 번째 세션의 TX 리소스 위한 enqueue를 waiters 리스트에 등록한다.
- 이로 인해 waiters 리스트 내의 첫 번째 세션은 두 번째 세션의 TX 리소스를 대기하고, 두 번째 세션은 첫 번째 세션의 TX 리소스를 대기하는 트랜잭션(또는 데이터) 데드락 발생한다.
- 세션 중의 하나는 3초 이내에 오라클 에러 ORA-00060가 방생하고 마지막 명령어를 롤백한다.
- 만일 PL/SQL 블록 내에서 데드락이 발생하고, 데드락에 대한 예외처리가 없다면, 블래 내에서 커밋되지 않은 모든 SQL문은 롤백된다.
- 데드락 트레이스 파일(Deadlock graph)
 |
- 데드락에 대한 중요한 개념
- 데드락은 다수의 세션간에도 발생할 가능성이 있다. 단지 두개의 세션에 제한된 문제는 아니다.
- TX 락을 모드 6으로 상호간에 획득하려는 것이 가장 일반적인 형태지만, 락을 대기하는 다른 상황에서도 발생할 수 있다.
- 데드락의 변형: 트랜잭션의 Share 모드(모드 4) 대기 (TX/4 대기)
- 인덱스(또는 IOT(index organized table) 테이블) 충돌 시
- 두 개의 세션이 동일한 primary key값을 입력한다.
- 한 세션은 자식 테이블에 한 로우를 입력하고 다른 세션은 부모 테이블에 삭제한다.
- 한 세션은 부모 테이블에 한 로우를 입력했으나 커밋 전 상태이고, 이 시점에 다른 세션이 해당 로우를 자식 테이블에 입력한다.
- 두 개의 세션이 동일한 비트맵 인덱스 청크에 의해 관리되는 로우를 삭제하려고 시도한다.
- 리프 블록 분할(split) 시
- 액티브 트랜잭션들로 인해 ITL을 모두 사용했고 ITL을 확장할 여유 공간이 없을 때, 또 다른 트랜잭션이 블록을 변경하고 하는 경우
- 위 상황이 자주 발생한다면, 문재가 발생하는 오브젝트를 추적한 후 속성(일반적으로 initrans 값)을 변경하는 것이 바람직하다.
- 10g부터는 ITL 대기를 별도의 TX 대기(enq:TX-allocate ITL entry)로 제공하고 Statspack 및 AWR 리포트를 통해 ITL 대기가 발생한 세그먼트에 대한 정보를 확인할 수 있다.
- 데이터베이스 링크 또는 XA TPM(9.2 이전 Transaction processing monitors)을 사용한 select문에서도 발생: two-phase commit(2PC)
- 프리리스트 고갈로 데이터 파일 확장 시 (autoextend)
- 테이블스페이스를 read-only 모드로 변경 시
 |
 |
- 락 획득 절차
- 해시 값을 설정하기 위해 리소스 식별자(type, id1, id2)를 사용한다. 해시 테이블의 크기는 2 * session + 35 정도이다. "소수" 또는 "2의 제곱"의 일반적인 형식을 사용하지 않는다.
- 해시 버킷은 enqueue hash chains 래치에 의해 보호된다. 래수의 수는 CPU의 수와 일치하며, 해시 버킷은 래치를 통해 "라운드-로빈" 방식으로 공유된다. 만일 락을 설정하려고 리소스에 해당하는 x$ksqrs구조의 한 로우가 이미 해시 체인에 링크되었는지를 확인할려면, 래치를 획득한 후 버킷을 검색(예를 들어, 체인을 따라가면서 검색)하면 된다.
- 만일 enqueue 리소스를 사용할 준비가 되었다면, 연관된 enqueue 구조(x$ksqeq 구조 등)로부터 하나의 로우를 획득한다. 하지만 동시에 동일한 enquene 로우를 다른 세션이 획득한느 것을 방지하기 위해 관련된 enqueue 래치를 획득해야만 한다. 획득할 필요가 있는 래치는 세션이 사용하려는 enqueue의 유형에 다라 다르다. 예를 들어, x$ksqeq구조로부터 로우를 획득하려면 enqueue 래치를 획득해야 하고, x$ktadm 구조로부터 로우를 획득하려면 dml allocation 래치를 획득해야 한다. 그리고 안전하게 enqueue 로우를 획득하자마자 래치를 릴리즈해야 한다.
- 만일 enqueue 리소스를 사용할 준비가 되지 않았다면 (enqueue hash chains 래치를 획득한 채로) x$ksqrs 구조로부터 하나의 로우를 획득하고, 세션이 사용하려는 리소스를 표현하도록 표시하고, 해시 체인에 연결한 후 해당 로우와 연결된 enqueue 로우를 획득한다.
- 이 모든 것이 완료되면 enqueue hash chains 래치를 릴리즈 한다.
{info:title=필자의 생각: x$ksqrs에서 프리 항목을 찾는 효율적인 방법}
오라클이 enqueue 리소스를 해시 체인으로부터 분리할 때, 스택 (LIFO)처럼 동작하도록 또 다른 "링크드 리스트"를 사용하는 것 같다.
이는 x$ksqrs 배열 내의 가용한 첫 번째를 가리키는 포인터를 가지고 있으므로 배열을 검색할 필요가 없다.
{info}
- KGL Lock과 KGL Pin
- 라이브러리 캐시를 위한 락 Set인 KGL Lock와 KGL Pin은 각각 owners와 waiters 두 개의 큐만을 사용한다.
- KGL lock은 parents 커서와 이와 관련된 child 커서에 대한 락을 모두 가진다.
- 이는 래치를 획득하고 해시 체인을 검색하는 대신, 해당 오브젝트의 주소로 직접 접근하는 것을 허용한다.
- KGL lock이 메모리 내의 오브젝트를 잡고 있긴 하지만 오브젝트의 일부분은 동적으로 재생성(SQL문의 실행계획) 될 수 있으며, 극심한 메모리가 요구가 발생한다면 KGL lock을 획득했다고 하더라도 메모리에서 밀려날 수 있다.
- 그러나 실제로 오브젝트를 사용(SQL문 수행)할 때, 재생성 가능한 부분이 메모리에 밀려나가지 않는다는 것을 보장하기 위해 오브젝트에 KGL pin을 사용한다.
- 문제점
- KGL lock은 대략 200bytes이고 KGL pin은 대략 40bytes로, 메모리에 대한 지속적인 할당과 해제는 shared pool 내의 프리 메모리의 단편화 현상을 유발
- 독점적으로 래치를 소유해야 하기 때문에 확장성을 심각하게 위협
※ 11g에서는 KGL lock/KGL pin 매커니즘은 뮤텍스 매커니즘으로 대체 되고 있다.
뮤텍스(Mutex)
- locking과 pinning 매커니즘을 제거하기 위한 목적으로 오라클 10.2의 라이브러리 캐시 처리를 위해 처음으로 사용
- 라이브러리 캐시 오브젝를 위한 "private mini-latch"이다.
- 모든 개별 라이브러리 캐시 해시 버킷마다 개별적인 뮤텍스를 할당하고, 모두 부모 및 자식 커서에 두 개의 뮤텍스를 사용함으로써, 빈번하게 사용되는 명령어의 확정성을 향샹시킨다.
- 뮤텍스에 대한 문제가 발생했을 때 분석을 위한 정보가 부족하다는 단점이 있다.
- 래치와 뮤텍스의 차이점
- 래치는 process에 의해 소유, 뮤텍스는 session에 의해 소유
- 하나의 프로세스는 다수의 세션(공유 서버 또는 커넥션 pooling)을 위해 동작할 수 있으며, 동일한 프로세스 내에서 동작하는 두 개의 세션간에 뮤텍스로 인한 데드락이 발생할 수 있다.
요약
- 오라클은 경합에 의해 공유 자원이 손상되지 않도록 4개의 메커니즘 제공: 1) 락(lock), 2) 래치(latch), 3)핀(pin), 4)뮤텍스(mutax)
- 래치 또는 뮤텍스 획득은 기본적으로 atomic "compare and swap" 연산에 의해 결정: "내가 word의 값을 X에서 Y로 변경할 수 있어야만, 그 이후에 내 작업을 수행할 수 있다."
- 래치 또는 뮤텍스의 보호가 필요한 작업 중의 일부는 동시에 수행될 수 있으며, 이 때 안정성을 보장하기 위해 오라클은 sharded read 매커니즘을 사용한다.
- 리소스를 비교적 오랜 시간 소유해야 한다는 요구사항을 만족하기 위해서, 오라클은 메모리 항목들의 링크드 리스트(큐)를 이용하는 일반적인 매커니즘을 가지고 있다.
- 이는 v$lock 뷰를 통해 enqueue 리소스에 등록된 enqueue를 확인 할 수 있으며, v$open_cursor 뷰를 통해 라이브러리 캐시 오브젝트에 등록된 KGL lock을 확인할 수 있다.
- 11g부터 KGL lock/KGL pin 매커니즘은 뮤텍스 매커니즘으로 대체 되고 있다.







