- HOME
- [종료]구루비 DB 스터디
- 2015년 상반기 - 오라클 데이터베이스 스터디
- 4.1 속성에 대한 사설
4.1 속성에 대한 사설
- 모델링의 3요소는 엔터티, 속성, 관계 이다.
- 속성은 엔터티의 성격을 기술하는 특성이다.
- 속성은 데이터를 저장하는 가장 작은, 독립된 저장 단위
- 속성의 분류법
- 식별자(Key) 속성 & 비식별자(Non-Key)
- 기초(Basic) 속성 & 관계(Relationship) 속성 & 추출(Derived) 속성 & 시스템(System) 속성
- 원본(Raw) 속성 & 추출(Derived) 속성
- 단일 값(Single-Valued) 속성 & 다가(Multivalued) 속성
- 단순(Simple) 속성 & 복합(Composite) 속성
- 필수(Mandatory) 속성 & 선택(Optional) 속성
- 코드(Code) 속성 & 비코드(Non-Code) 속성
4.2 식별자(Key) 속성 & 비식별자(Non-Key) 속성
- 식별자 속성이란 엔터티에 존재하는 인스턴스의 유일성을 보장해 주는 속성이나 속성 집합이다.
- 하나의 속성이 식별자의 역할을 하지 못할 때는 여러 속성이 모여 식별자가 되며, 이를 복합 식별자(Composite Key Attribute 또는 Composite Identifier)라고 한다.
- 비식별자 속성은 일반 속성으로서, 인스턴스마다 같은 값을 가질 수 있다.
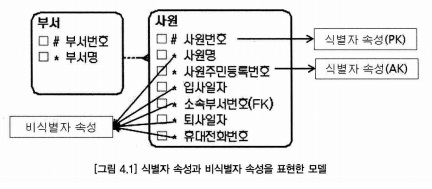
- 식별자(결정자)속성이 엔터티의 본질이나 태생과 관련이 있다면, 비식별자(종속자)속성은 엔터티 특성을 묘사(Descriptors)하는 역할을 한다.
4.3 식별자 종류 - 후보 식별자(Candidate Identifier)
- 후보 식별자(Candiate Identifier)는 주 식별자가 될 가능성이 있는 식별자를 의미한다.
- 후보 식별자는 하나의 엔터티에 여러개 있을 수 있다. (예:사원주민등록번호, 휴대폰번호, 이메일 주소, 고객번호)가 후보 식별자가 될 수 있다.
- 사원주민등록번호, 휴대폰번호, 이메일주소, 고객번호 속성 값은 릴레이션에서 유일하게 하나만 존재 하므로, 이 값을 알면 나머지 속성 값도 알 수 있기 때문에 결정자(Determinant)면서 후보 식별자다.
- 고객번호가 '321098'이라는 것을 알면 휴대폰번호 '010-345-6789'이고, 사원명은 '김길동'이라는 것을 알 수 있다. 함수 종속으로 표현하면 아래와 같다.
- 사원주민등록번호, 휴대폰번호, 이메일주소 속성의 함수 종속 표현
- FD1 : 사원주민등록번호 -> 사원명
- FD2 : 휴대폰번호 -> 사원명
- FD3 : 이메일주소 -> 사원명
- 함수 종속에서 왼쪽의 결정자(Determinant) 속성이 모두 후보 식별자다.여러 개의 후보 식별자중에서 주 식별자가 결정된다.
- 널(Null)을 허용할 수 있다는 것을 제외하면 후보 식별자는 주 식별자와 성격이 동일하다.
- 물리적으로 인스턴스의 유일성을 보장해주기 위해 유니크 인덱스를 생성해야 한다.
4.4 식별자 종류 - 주 식별자(Primary Identifier)
- 주 식별자(Primary identifier)는 엔터티에 하나만 존재하는 대표 식별자다.
- 주 식별자와 주 키(Primary Key)라는 용어는 동일하게 사용
- PK(Primary Key)는 테이블에 지정된 물리적인 제약(Constraints)을 의미하며, 주 식별자는 논리적으로 인스턴스를 식별하는 기준을 의미
- 논리적인 주 식별자에 다른 속성을 추가해서 물리적인 PK를 생성할 수도 있다.
- 주 식별자는 여러 개의 후보 식별자 중에서 대표를 지정하는 방법이 있으며, 적당한 후보 식별자가 없다면 인조 식별자를 만들어 주 식별자로 사용하는 방법
- 엔터티에는 논리적인 주 식별자가 반드시 존재해야 하지만, 물리적인 주 키(Primary Key)는 존재하지 않을 수 있다.
- 주 식별자는 하나만 존재 한다.
4.5 주 식별자가 바뀌는 현상
- 엔터티 정의가 불명확할 때
- 데이터 분석이 미흡할 대
- 이력 데이터를 고려하지 않았을 대
- 업무가 변경될 때
4.6 어떤 속성을 주 식별자로 선택해야 하는가?
- 주 식별자 속성의 값이 변경되지 않도록 선정
- 일반 속성에 종속되지 않도록 선정
- 인조 식별자에 의미를 부여하지 않도록 선정
- 인조 식별자 값에 부여된 의미는 속성에도 존재하는데, 속성 값이 변경되어 주 식별자가 변경 될 수 있다.
- 아무 의미 없이 식별 기능만을 하는 순번으로 주로 사용
- 일반 속성으로도 관리되고 주 식별자 속성으로도 관리되면 중복 데이터 이다.
- 한 번 부여되면 변하지 않을 속성이 상품 코드에 체계화돼 있다면 단점은 없으나, 뚜렷한 장점도 없다.
- 실익이 없으므로 무의미하게 차례대로 증가하는 순번을 인조 식별자의 값으로 사용하는 것이 최선다.
- 불가피 하게 인조 식별자에 의미가 포함 될 수 있다.
- 여러 종류의 상품을 하나의 엔터티로 통합하려고 할 때 주 식별자인 상품번호 값이 중복 될 수 있다.
- 상품번호와 상품종류 코드를 복합 주 식별자로로 사용하면 된다.
- 핵심이 되는 상품 엔터티의 주 식별자는 상품번호 단독 속성이 되는 것이 바람직 하다.
- 이럴 경우 상품번호 속성 값에 체계(의미)를 부여해서 단독 주 식별자로 만들 수 있다.
- 상품 종류코드 값이 바뀌더라도 주 식별자 값은 바꾸지 않아도 된다. 데이터의 유일성을 보장하기 위해 주 식별자에 의미가 포함 될 수 있다.
주 식별자 속성에 논리적으로 널(NULL)값이 존재하지 않도록 선정
- 주 식별자 속성 값에는 논리적인 널(NULL) 데이터를 사용할 수 없다.
- 널(NULL)은 모르는 값을 의미한다. 알 수 없는 값으로는 인스턴스를 식별할 수 없으므로 모르는 값이 주 식별자가 될 수는 업ㅈㅅ다.
- 논리적인 널(NULL)값은 업무에 의해서 발생하기 보다 데이터 통합이나 데이터 관리 측변에서 발생할 대가 있다.
- 유사한 엔터티를 통합하는 과정에서 주 식별자에 널(NULL) 값이 필요할 수 있다.
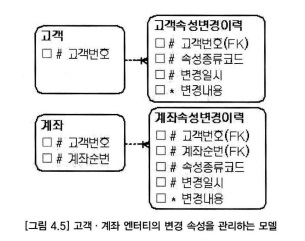
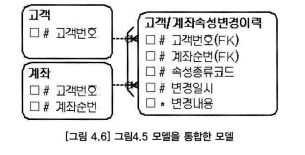
- 계좌순번 속성은 계좌 엔터티에만 해당하는 속성이므로, 고객 엔터티의 속성값이 변경될 때는 논리적인 NULL(계좌순번 '00')의 약속한 값을 사용
최소한의 속성이 포함되도록 선정
- 엔터티의 주 식별자가 여러 속성으로 구성돼 있고, 하위(자식) 엔터티가 많다면 주 식별자를 간략하게 만드는 것이 좋다.
- 주 식별자에 속한 속성이 많으면 모델의 가독성이 떨어 지며, 조인 구문도 복잡해 진다.
- 최하위 엔터티가 아니라면 주 식별자는 최소한의 속성으로 구성하는 것이 유리하다.
업무적으로 활용도가 높은 속성으로 선정
- 가능한 업무 식별자를 그대로 사용하는 것이 좋다.
- 업무에서 사용된다는 말은 그 속성으로 조회가 자주 된다는 의미이므로, 많은 화면에서 자주 조회되면 주 식별자로 조ㅓ회하는 것이 가장 효율적이다.
- 인조 식별자를 사용해 조회하면 필요한 데이터를 찾아가는 한 번의 과정을
업무 식별자와 인조 식별자가 혼합되지 않도록 선정
- 고객번호와 '순번' 속성이 주 식별자로 많이 사용하나 '순번' 속성을 부분 인조 식별자라고 한다.
- 부분 인조 식별자는 사용하지 않는 것이 바람직 하다.
슈퍼 식별자가 되지 않도록 선정
- 주 식별자를 구성하는 속성의 숫자는 가능한 적을수록 좋고, 슈퍼 식별자(Super Identifier)가 사용되면 안되는 것은 자명하다.
- 슈퍼 식별자는 주 식별자에 다른 속성을 추가해서 만든 식별자다.
최소 길이가 되도록 선정
- 주 식별자의 속성 값의 길이는 최대한 짧아야 효율적이다.
- 주 식별자의 길이가 길면 많은 블록을 사용하고, 인덱스의 깊이(Depth)를 깊게 만들어 가능한 짧은 길이를 주 식별자로 사용하는 것이 좋다.
- 데이터 타입도 신중히 정해야 한다. VARCHAR 타입보다는 NUMBER 타입이 저장공간이 절약 된다.
주 식별자 속성 값은 가능한 고정 길이가 되도록 선정
- 주 식별자 속성 값은 가능한 고정길이여야 한다.
- 통합 엔터티의 주 식별자의 길이는 달라 질 수 있다.
주 식별자 속성은 전사에서 한 번만 사용되도록 선정
- 서브타입 엔터티나 엔터티를 수직 분할한 일대일 관계의 엔터티등의 주 식별자는 같을 수 있다.
- 근본적으로 같은 집합을 의미할 때를 제외하고 주 식별자가 같지 않도록 설계 하는 것이 바람직 하다.
암호화 대상 속성이 포함되지 않도록 선정
업무를 대표할 수 있는 속성으로 선정
4.7 주 식별자를 단순하게 설계해야 하는 이유
- 주 식별자에 속한 속성이 많으면 가독성이 떨어짐
- 하위에 존재하는 행위 엔터티나 집계 엔터티라면 별문제가 없으나, 최상단에 위치하는 엔터티의 주 식별자가 복잡하면 문제가 커 질 수 있다.
- 조인 구문이 복잡해져 쿼리가 길어 진다.
- 주 식별자 인덱스가 커져 성능에 악영향을 미칠 수 있다.
4.8 주 식별자 선정 절차
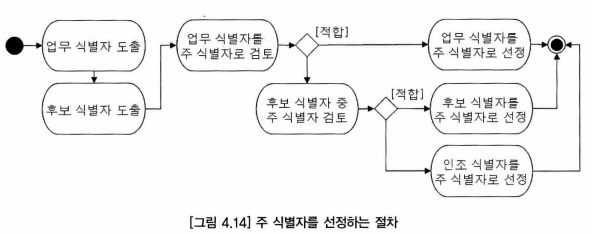
- 업무 식별자가 도출되지 않는 한 최종적인 식별자인 주 식별자는 결정될 수 없다.
- 업무 식별자를 도출한 후에 후보 식별자를 도출해야 한다.
4.9 복잡한 주 식별자
기준 데이터를 관리할 때
- 업무의 기준이 되는 데이터를 관리하는 엔터티이고, 기준이 복잡함에 따라 주 식별자가 복잡해지는 경우가 있다.
- 기준 데이터를 관리하는 엔터티는 보통 하위 엔터티 이므로 주 식별자가 복잡해 지는 것은 문제가 되지 않는다.
- 업무 식별자가 복잡하다는 이유로 인조 식별자를 사용하면, 기준이 되는 속성(결정자)과 기준에 의한 결과를 저장하는 속성(종속자)사이에 혼란이 생길 수 있다.
집계 데이터를 관리할 때
인스턴스를 생성하는 기준이 복잡할 때
- 데이터를 관리하려는 상세 수준에 따라서 주 식별자가 복잡해 질 수 있다.
교차 엔터티일 때
- 교차 엔터티는 일반적으로 양쪽 엔터티의 주 식별자를 식별자로서 상속받기 때문에 주 식별자가 복잡하다.
슈퍼 식별자가 사용될 때
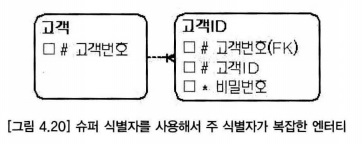
- 고객ID 엔터티에서 고객별로 고객 ID가 여러 개 존재할 수 있더라도, 고객 ID가 유일하다면 고객 ID 속성이 단독으로 주 식별자여야 한다.
- 고객ID 엔터티처럼 고객번호가 주 식별자에 포함돼 있다면, 다른 고객이 같은 ID를 사용할 수 있다는 것을 의미하기도 한다.
- 고객ID 엔터티의 주 식별자는 고객 ID 속성이고 고객번호 속성은 일반 속성으로 관리돼야 한다.
- 고객ID 엔터티의 주 식별자를 모호하게 정하는 이유는 고객ID 엔터티에 대한 정의 자첼르 명확하게 하지 못했을 수도 있고, 인덱스의 사용 편의성을 위해 주 식별자를 선정했을 수도 있다.
- 슈퍼 식별자를 채택해서 주 식별자가 복잡해지는 사례는, 조회에 사용되는 속성을 주 식별자에 포함시킬 때 많이 발생한다.
- WHERE 조건과 SELECT 구문에 사용된 속성을 전부 인덱스에 포함시킨 커버링 인덱스를 주 식별자로 사용하려는 의도나, 인덱스를 여러 개 만들지 않으려는 의도에서 슈퍼 식별자를 사용하는데 어떤 경우에도 슈퍼 식별자는 사용하지 않아야 한다.
주 식별자 상속이 지속적으로 이루어질 대
- 주 식별자로 상속되는 것이 사용하기 편리해 무조건 상속하면 자연히 주 식별자는 복잡해 진다. 상속과 단절이 적절하게 이루어져야 한다.
- 업무 식별자가 복잡하지만, 하위 엔터티가 존재하지 않으면 복잡한 주 식별자를 그대로 사용하는 것이 바람직 하다.
- 인조 식별자를 채택하면 인덱스만 하나 더 생기며 업무 식별자를 구분하기 어려워지는 단점이 생길 수 있다.
- 상세 논리 모델링이 끝나고 나서 대상 엔터티를 추출해 업무 식별자가 복잡한 것은 맞는지, 슈퍼 식별자가 사용된 것은 아닌지, 인조 식별자를 채택하면 안되는지 등을 다시 검토해 보는 것도 좋다.
4.10. 복합 주 식별자의 속성 순서
- 주 식별자가 여러 속성으로 구성된 복합 주 식별자일 때는 조회 성능을 고려하여 속성의 순서를 결정해야 한다.
- 분석.설계 단계에서는 해당 엔터티를 대상으로 자주 사용되는 조건을 파악하거나, 최소한 주요 화면을 확인해서라도 주 식별자의 속성 순서를 결정해야 한다.
- 주요 요건을 위주로 직관적으로 판단하더라도 완전하진 않지만 무난하게 결정할 수 있다.
- 검색 대상을 처음부터 줄이기 위해 분포도를 고려해야 한다.
- WHERE 조건에서 '='나 'BETWEEN'등이 사용되는 속성이 주 식별자의 맨 앞에 존재해야 한다.
4.11. 교차 엔터티의 주 식별자
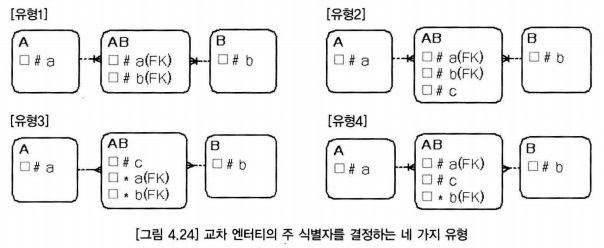
- 유형1은 교차 엔터티의 가장 기본적인 유형으로 양쪽 상위(부모) 엔터티의 주 식별자만으로 교차 엔터티의 주 식별자를 구성하는 모델

- 한 사원은 여러 프로젝트에 참여할 수 있으며 프로젝트에는 여러 사원이 참여 할 수 있다.
- 사원이 같은 프로젝트에 여러 번 속할 수 있다면, 프로젝트인력 엔터티의 성격이 변경되며, 양쪽 엔터티의 주 식별자만으로는 인스턴스를 식별할 수 없으므로 일자 성격의 속성이 주 식별자에 포함돼야 한다.
- 상위(부모) 엔터티의 주 식별자만으로 교차 엔터티의 주 식별자를 구성할 대는, 업무적으로 기준 성격이 강한 상위(부모) 엔터티의 주 식별자를 먼저 위치시킨다.

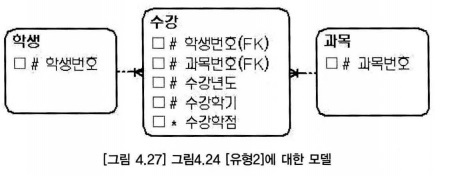
- 상위 엔터티의 주 식별자만으로 교차 엔터티의 인스턴스를 유일하게 식별할 수 없을 때 유형2 모델을 사용해야 한다.
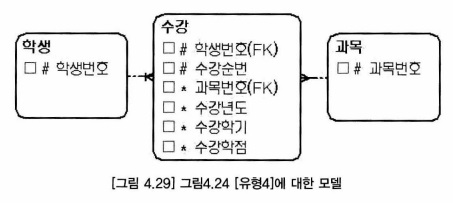
- 수강 엔터티에는 야쪽 상위 엔터티의 주 식별자(학생번호, 과목번호)와 자체업무 식별자(수강년도, 수강학기)가 혼합된 주 식별자를 사용
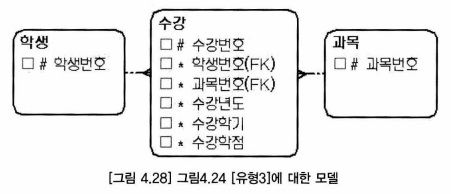
- 유형3 모델은 인조 식별자를 사용하는 모델이다.
- 교차 엔터티의 하위 엔터티가 존재하면 주 식별자를 단순하게 만들기 위해 수강 엔터티와 같이 인조 식별자를 사용 할 수 있다.
- 부분 인조 식별자를 사용하는 모델로서, 양쪽 상위(부모) 엔터티의 주 식별자 중에서 자주 사용하는 한쪽 부모 엔터티의 주 식별자만 상속하면서 순번 속성을 추가하는 모델
- 복잡한 주 식별자를 단순하게 만들려는 의도로 사용

- 한 사원은 여러 계좌를 관리할 수 있고, 한 계좌에는 관계된 사원이 여러 명 있을 수 있기 때문에 M:M 관계의 모델이다.
- 사원 속성이 주 식별자에 포함되지 않은 변형된 모델로서 업무 요건에 따라서 주 식별자가 달라진 모델

- 특정계좌와 연관된 사원은 관리사원.유치사원.주문사원 등 여러명이 존재할 수 있으며, 같은 계좌에 대해 관리사원등은 한 명만 존재하고, 한 사원이 관리사원과 주문사원이 될 수 없는 경우
4.12. 사원 엔터티의 주 식별자와 사원의 정의에 대해서

- 사원 데이터는 고객 엔터티에 통합하지 않고 개별적인 엔터티로 설계하는 것이 일반적
- 주 식별자인 사원번호에는 어떤 체계도 없는 것이 바람직 하며, 무의미한 값을 사용하는 것이 좋다.
- 한번 부여된 사원번호는 재입사 여부와 무관하게 지속해서 사용해야 한다. 입사일자/퇴사일자 등 변경사항은 사원이력 엔터티에서 별도록 관리 한다.
- 사원번호에 의미가 포함됐기 때문에 잘못된 설계이기도 하지만, 근본적으로 사원 엔터티에 대한 정의가 모호하기 때문에 잘못된 설계다.
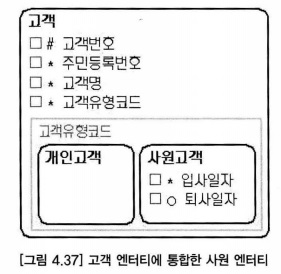
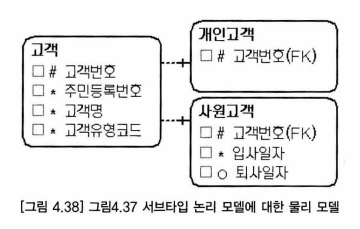
- 사원 데이터가 고객 엔터티에 통합
- 사원이 고객에 통합되면 고객번호와 조인해서 사원 정보를 알게 된다.
- 사원번호는 사원을 상징하는 업무 식별자일 수 있고, 고객번호와 구분할 필요도 있으며, 고객번호는 보통 길어서 사원을 관리하는 번호로 사용하기에 불편할 수도 있다.
- 실무에서는 사원번호의 상징성 때문에 그림 4.39 모델이 많이 사용 된다.
- 고객번호 속성에는 유니크 인덱스를 생성해서 중복되는 고객번호가 생기지 않도록 해야 한다.
4.13. 식별자 종류 - 인조 식별자(Artificial Identifier)
- 인조 식별자는 임의로 생성한 식별자를 의미한다.
- 후보 식별자 중에서 주 식별자로 사용할 마땅한 후보가 없을 때, 순번 성격의 속성을 추가해서 식별자로 사용한다.
- 모든 후보 식별자를 분석한 후 주 식별자로 사용할 최적의 후보가 없을 때 인조 식별자를 사용한다.
- 인조 식별자 속성은 사원번호로 하고, 그 속성에는 의미 없는 번호를 사용한다.
- 인조 식별자를 사용하면 주 식별자가 단순해 진다.
- 인조 식별자만으로는 업무를 파악하기 어렵고, 행위 엔터티등에서 인조 식별자를 사용하면 업무에 대한 가독성이 현저히 떨어진다.
- 업무와의 결합도를 감소시켜 모델의 확장성을 증가 시키기도 한다.
- 업무 변경이 예상된다면 인조 식별자를 사용하여 유연한 모델이 되도록 해야 한다.
- 인조 식별자는 검색 조건에 사용되지 않는다.
- 인조 식별자를 채택하면 업무 식별자에 유니크 인덱스를 생성해야 하므로 인덱스를 하나 더 관리해야 한다.
- 인조 식별자를 오용 하는 경우
- 인조 식별자의 무분별한 사용
- 식별자에 의미를 부여
- 인조 식별자가 사용되기 까지의 순서
- 후보(업무) 식별자 도출
- 도출된 후보(업무) 식별자 중에 주 식별자로 적당한 후보가 있는지 검토
- 적당한 후보가 없다면 인조 식별자 사용
- 하위 엔터티가 많은 주요 엔터티는 가능한 빨리 인조 식별자를 선택하는 것이 좋다.
- 후보 식별자를 검토할 때, 인조 식별자를 도입해야 하는지를 동시에 검토하는 것이 좋다.
4.14. 인조 식별자를 사용해야 좋을 때
주 식별자가 복잡하면서 하위 엔터티가 다수 존재할 때
업무를 직관적으로 만들어 주는 번호를 사용할 때
- 계좌번호와 같이 일반화된 용어를 주 식별자로 사용하면 업무가 직관적으로 연상된다.
적당한 후보 식별자가 없을 때
모델을 유연하게 설계해야 할 때
- 업무 식별자를 주 식별자로 사용한 상태에서는 주 식별자를 바꿀 정도로 업무가 바뀌더라도 주 식별자를 변경하기는 사실상 어렵다.
- 인조 식별자를 사용한 상태라면 주 식별자에는 변함없이 업무 식별자에 생성한 유니크 인덱스만 변경하면 된다.
4.15. 업무 식별자와 인조 식별자의 혼합
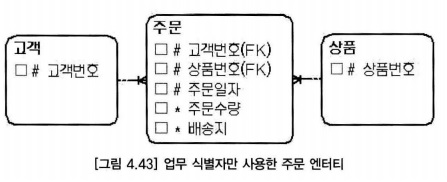
- 한 고객이 하루에 같은 상품을 두 번 이상 주문할 수 없다면 주문 엔터티의 업무 식별자는 고객번호, 상품번호, 주문일자가 된다.
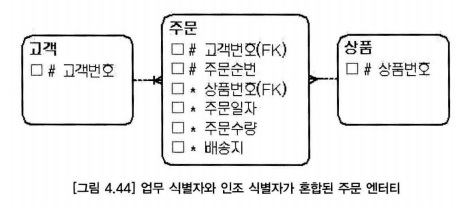
- 고객 번호 속성은 업무 식별자에 해당하고, 주문순번 속성은 고객별로 순차적으로 증가하는 순번을 의미하므로 인조 식별자에 해당
- 업무 식별자와 인조 식별자를 혼합해서 사용하면 바람직하지 않는 이유
- 요건을 알기 어려워 가독성이 떨어짐
- 엔터티 성격이 모호해짐
- 모델 관리가 복잡해짐
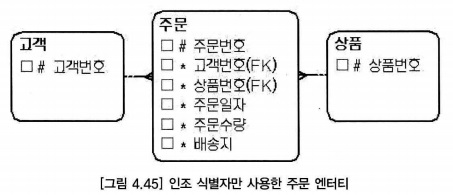
- 인조 식별자만으로 주 식별자를 사용해야 한다.
- 주문 엔터티의 주문순번 속성은 고객별로 데이터가 여러번 발생하기 때문에 유일성을 보장하기 위한 용도로 사용하는 인조 식별자(부분 인조 식별자)다.
- 주문 순번 속성이 고객이 주문한 진짜 순서를 의미하면 업무 식별자에 가깝지만,주문횟수 등의 일반 ㅅ혹성으로 설계 하는 것이 바람직 하다.
- 식별자에 주문순번 속성을 사용해서 인스턴스의 유일성을 보장하기 위한 목적과 혼란을 일으킬 필요는 없다.
- 부분 인조 식별자를 불가피하게 사용할 경우도 있는데, 고객별.계좌별로 조회하는 쿼리가 많고, 성능을 최우선으로 고려해야 한다면 고객번호나 계좌번호 속성이 주 식별자에 포함된다.
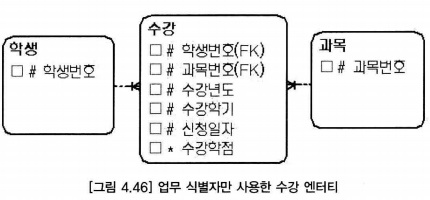
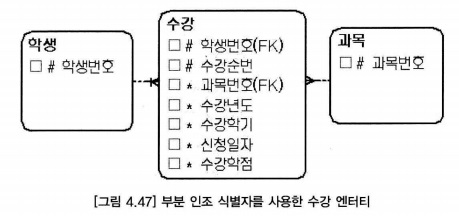
- 수강 엔터티의 하위 엔터티가 많고, 업무가 학생번호 속성을 사용한다면(학생번호 속성으로 정렬을 자주하며 빠르게 해야 한다면), 수강 엔터티와 같이 부분 인조 식별자를 사용할 수 있다.
식별자 종류 - 대리 식별자(Alternate Identifier)
- 대리 식별자는 주 식별자로 선택되지 않은 후보 식별자다.
- 대리 식별자를 선정하는 과정
- 후보 식별자를 선정한다. 후보 식별자가 여러 개 있다.
- 후보 식별자 중에서 주 식별자로 선정할 후보가 있는지를 판단한다.
- 후보 식별자 중에서 주 식별자가 있다면 나머지는 대리 식별자가 된다.
- 후보 식별자 중에 주 식별자가 없다면 인조 식별자를 채택한다.
- 인조 식별자를 채택하면 후보 식별자는 전체가 대리 식별자가 된다.
- 대리 식별자를 결국 후보 식별자와 같은 역할을 하므로, 유니크 인덱스를 생성한다.
4.17. 식별자 종류 = 슈퍼 식별자(Super Identifier)
- 슈퍼 식별자는 주 식별자에 다른 속성을 추가해서 만든 식별자를 의미한다.
- 슈퍼 식별자를 구성하고 있는 속성 중에서 새로운 인스턴스를 생성하는 데 영향을 미치지 않는 속성을 제외하면 후보 식별자가 된다.
- 후보 식별자에 대한 이해가 부족하기 때문에 사용된다.
- 검색과 관련돼 있어 WHERE 구문에 사용된 속성을 전부 인덱스에 포함시켜 커버링 인덱스를 생성하면 빠른 성능을 얻을 수 있어 사용한다.
- 인덱스를 하나 더 생성하는 것에 대한 거부 반응이 주 식별자에 인덱스 대상 속성을 추가하게 하기도 한다.
- 식별자를 제대로 분석하지 못했기 때문에 사용된다.
- 주 식별자는 인스턴스를 생성하는 기준과 인스턴스를 식별하는 역할만을 해야 한다.
- 인덱스의 역할을 하는 것이 주 식별자가 아니다.
- 슈퍼 식별자를 사용하면 엔터티 성격이 불문명해진다.
- 인스턴스를 발생시키는 기준, 즉 업무 식별자가 명확해야 엔터티의 성격이 분명해 진다.
- 슈퍼 식별자를 사용하면 데이터 성격이 점점 모호해 지면서 엔터티의 성격이 변질될 수 있다.
4.18. 속성 종류 - 기초 속성(Basic Attribute)
- 엔터티의 본질을 설명하는 속성
- 이 기초속성을 보면 엔터티의 정의를 알 수 있다.
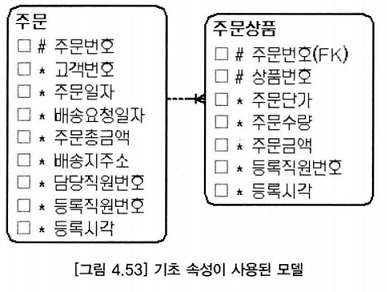
- 주문 엔터티의 주문번호, 고객번호, 주문일자, 배송요청일자, 배송지주소 속성이 기초 속성이다.
- 엔터티가 어느 주제 영역(ERD)에 속해야 하는지에 대한 오너십이 모델 오너십인데, 모델 오너십을 정하는 기준이 기초 속성이다.
- 기초 속성의 값은 주로 데이터베이스를 사용하는 사용자의 입력이라는 행위에 의해서 생서오디므로, 기초 속성의 값을 생성하는 영역에서 모델 오너십을 가져야 한다.
4.19. 속성 종류 - 관계 속성(Relationship Attribute)
- 관계 속성은 타 엔터티와의 관계를 알기 위해 사용하는 외래식별자 소성이다.
- ERD에서 관계선이 생략될 수는 있어도 관계 속성이 생략되면 안된다.
- 관계 속성은 참조되는 엔터티와 존재 종속 관계면 관계 속성은 엔터티의 본질을 의미하므로 기초 속성이기도 하다.
- 부모 엔터티가 없으면 자식 엔터티가 존재할 수 없는 관계를 종속 관계라고 한다. 자식 엔터티는 부모 엔터티에 존재 종속되므로 홀로 존재할 수 없다.
- 엔터티 간 관계가 존재 종속 관계가 아니고 단지 참조만 하는 관계라면 관계 속성은 기초 속성이 아니다.참조하는 엔터티의 본질을 정의하는 속성이 아니기 때문이다.
4.20. 소성 종류 - 추출 속성(Derived Attribute)
- 추출 속성은 이미 존재하는 속성으로 재생할 수 있는 속성이다.
- 추출 속성은 기존에 존재하는 원본 속성의 값을 연산해서 생성할 수 있는 속성이다.
- 추출 속성은 원본 속성에 종속돼 있다.
- 추출 속성을 사용하는 가장 큰 목적은 데이터 조회 시간을 단축하기 위함이다.
- 추출 속성의 문제점은 정합성이 저하될 수 있다는 것이다.
- 원본 데이터와 정합성을 맞춰야 하는데 문제만 아니라면 추출 속서은 제한 없이 사용할 수 있을 것이다.
- 추출 속성은 주 식별자로 사용하면 안 된다.
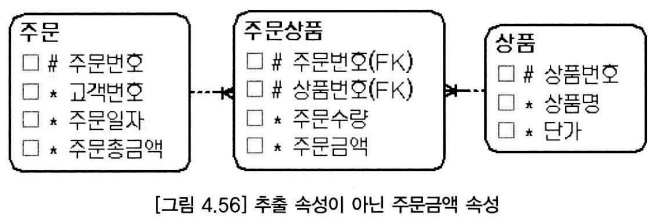
- 추출 속성은 다른 속성 값에서 재현할 수 있는 속성인데, 만약 재현할 수 없다면 추출 속성이 아니다.
- 주문금액은 추출(수량*단가) 속성이지만 추출 속성이 아니다.
- 상품 엔터티의 단가 속성은 현재 시점의 단가이기 때문에 주문상품 엔터티의 주문수량과 상품 엔터티의 단가를 사용해서는 주문금액을 재생할 수 없다.
- 상품 엔터티의 이력 엔터티가 있다면, 주문금액 속성은 추출 속성이다.
- 잔고.잔금 속성은 추출 속성이지만 원본 내역에서 매번 게산해서 사요할 수 없어 추출 속성으로 채택해 미리 계산해서 사용한다.
- 이런 속성은 기초 속성이기도 해서 개념 모델에 표현될 수 있는 핵심적인 속성이다.
- 추출속성과 유사한 중복 속성은 원본 속성을 그대로 복사해서 사용하는 속성이다.
- 추출 속성은 연산에 의해 생성된 속성이다.
- 추출 속성은 데이터 정합성 문제 때문에 사용하지 않는 것이 원칙이다.
만약 조회 성능 문제가 발생해 이를 해결하기 위해 추출 속성을 사용하더라도 정합성은 철저히 맞춰야 한다.
4.21 속성 종류 - 시스템 속성
- 시스템 속성은 데이터에 대한 추적.감시를 위해 사용하는 속성이다.
- 해당 인스턴스를 누가 생성하고 언제 생성 했는지, 누가 언제 수정했는지를 관리하는 속성이다.
- 일반적으로 전체 엔터티에 존재하며, 엔터티마다 다른 의미로 사용하지 않고 같은 목적을 사용한다.
- 시스템 속성의 개수는 가능한 적어야 한다.
- 데이터를 추적할 수 있는 용도로만 사용하는 것이 바람직하며, 업무적인 의미를 부여해 업무적으로 사용하지 않는 것이 좋다.
- 시스템 속성을 삭제하고도 업무에 지장을 주지 않도록 설계하는 것이 좋다.
- DB에 테이블로 생성하기 바로 직전에 시스템 속성을 추가하는 것이 가장 바람직하다.
- 시스템 속성은 엔터티의 제일 하단에 위치한다.
4.22. 추출 속성의 종류 - 중복 속성(Redundant Attribute)
- 중복 속성을 제거하는 것이 관계형 데이터 모델링의 중요한 목적 중 하나다.
- 이미 존재하는 속성의 값을 중복해서 사용하는 속성
- 중복 속성을 사용하는 이유는 상위 엔터티와의 조인을 피하려고 하기 때문이다.
4.23. 시점 데이터가 중복 속성이다?
- 데이터가 발생할 시점의 값을 관리하는 속성은 주의해야 한다.
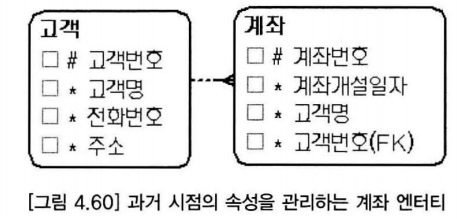
- 계좌를 개설할 때의 고객명을 의미할 수도 있으므로 중복 속성이라고 볼 수 없다.
- 시점 데이터란 의미에는 고객 엔터티의 고객명 속성 값이 변경되더라도 계좌 엔터티의 고객명 속성은 변경되면 안 된다는 의미가 포함되어 있다.
- 데이터가 발생한 시점의 데이터는 시간이 흐르면 이력 데이터가 된다. 이력 데이터를 관리하지 않고 시점 데이터만을 관리하는 것은 바람직 하지 않다.
4.24. 중복 속성을 사용할 수 있는 경우
- 중복 속성을 사용했을 때의 가장 커다란 문제점은 데이터 정합성이 깨질 수 있다는 것이며, 저장공간을 많이 차지해서 성능에 악영향을 끼친다는 것이다.
- 값이 변하지 않는 속성은 중복 속성으로 사용할 수 있다.
- 값이 변경될 가능성이 아주 낮은 속성이 있다면, 하위 엔터티에 중복 속성으로 사용해도 부작용이 줄어든다.
- 데이터 정합성을 맞춰야 하는 대상이 적은 경우도 중복 속성을 사용할 때 부작용을 최소화 할 수 있다.
- 엔터티 간의 관계가 참조 관계일 때보다는 종속 관계일 때가 비교적 중복 속성을 채택하기 적당하다.
- 참조 관계일 대는, 상위 엔터티는 주로 실체 엔터티고 하위 엔터티는 트랜잭션 데이터를 관리하는 행위 엔터티다.
- 이런 이유로 인스턴스가 많은 하위 엔터티에 중복 속성을 사용하면 부작용이 더 커지게 된다.
- 종속 관계 일 때는 인스턴스가 적으므로 중복 데이터도 덜 발생한다.
- 중복 데이터의 용량을 줄이는 것 또한 의미가 있으므로 중복해서 사용할 속성의 길이도 가능한 한 짧아야 좋다.
4.25 단일 값(Single-Valued) 소성 & 다가(Multivalued) 속성
- 단일 값 속성은 한 시점에 하나의 값만을 가지는 속성이다.
- 데이터는 원자값이어야 한다는 원칙을 지킨 정상적인 속성이다.
- 다가 속성은 유사한 성격의 값을 복수로 가지고 있는 속성을 의미한다.
- 한 속성에 유사한 종류의 값이 여러 개 존재하는 속성이다.
- 복합 속성은 전화번호 속성과 같이 두 개 이상의 세부 속성으로 구성된 속성을 말한다.
- 복합 속성과 다가 속성은 1정규화와 관련된 속성이다.
- 일반적인 다가 속성은 여러 개의 값을 한 속성에 물리적으로 저장하는 것이다.
- 예) 취미를 '100,101,102'와 같은 형태로 관리
- 물리 적으로 하나의 값을 가지는데 여러 종류의 값을 의미할 때
- 고객전화번호 속성에 집전화번호/사무실 전화번호를 저장하면 두 종류의 의미를 사용 하는 것
- 의도적으로 데이터를 통합하여 일반화한 것이 아니라면, 하나의 속성에 여러 의미가 존재할 수 있도록 속성을 정의하는 것은 좋지 않다.
- 의도적으로 다가 속성을 사용하는 경우가 종종 있다.
- 한 속서에 가입일자와 탈퇴일자를 같이 관리할 대는, 이를 구분하는 코드와 함께 적용일자 등의 일반적인 속성을 사용한다.
- 상호 배타 속성으로 하나의 속성에는 하나의 의미만 가지도록 사용하는 것이 원칙이나, 전략적으로 상호 배타 속성을 사용할 대도 있다.
- 물리적 다가 속성에는 비트값을 사용할 대도 있다.
- 값의 자릿수에 미리 의미를 부여해서 한바이트가 하나의 값을 의미하도록 사용
- 코드 속성에 여러 개의 코드값을 저장해 사용하기도 한다.
- '1352'등과 같이 저장하여 자릿수마다 하나의 의미를 부여해 사용
- 최종 모델에 다가 속성은 사용하지 않는 것이 원칙이다.
- 개념 모델링이나 초기 논리 모델링 단게에서는 다가 소성이 사용되기도 한다.
- 다가 속성은 모델링하는 과정에서는 발생할 수 있지만 최종 물리 모델에서 다가 속성이 존재하면 일반적으로 잘못된 모델이다.
- HOME
- [종료]구루비 DB 스터디
- 2015년 상반기 - 오라클 데이터베이스 스터디
- 4.1 속성에 대한 사설