14S_병렬 쿼리 (by kkabong) [2015.01.13]
병렬쿼리
병렬쿼리를 사용하면,
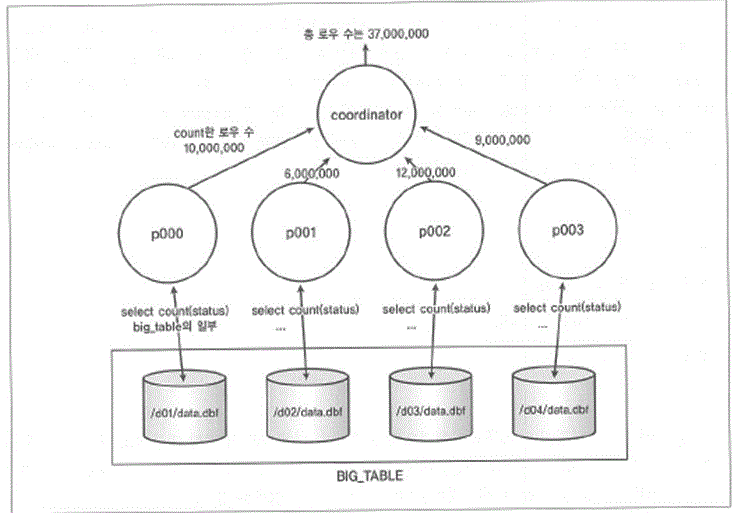
1. 여러 개의 병렬세션을 사용해서 Big_Table을 중복되지 않는 작은 단위로 분할한 후
2. 각 병렬세션들이 테이블을 읽고 해당 로우를 Count할 것을 요청한다.
3. 병렬쿼리 '코디네이터'세션은 각각의 병렬 세션으로부터 Count결과를 받아서 합산한 이후
4. 클라이언트 어플리케이션에 최종 결과값을 전달
일반 실행계획과 비교
SQL> explain plan into sys.plan_table$ for select count(status) from big_table;
Explained.
SQL> select * from table(dbms_xplan.display('sys.plan_table$', null, null));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 599409829
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 35641 (1)| 00:07:08 |
| 1 | SORT AGGREGATE | | 1 | 6 | | |
| 2 | TABLE ACCESS FULL| BIG_TABLE | 9992K| 57M| 35641 (1)| 00:07:08 |
--------------------------------------------------------------------------------
SQL> alter table big_table parallel; --> 기본 병렬도 사용(필자가 선호하는 방식)
Table alerted.
SQL> select DEGREE from dba_tables where table_name = 'BIG_TABLE'
DEGREE
--------------------
DEFAULT
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 4947 (1)| 00:01:00 | | | |
| 1 | SORT AGGREGATE | | 1 | 6 | | | | | |
| 2 | PX COORDINATOR | | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | 6 | | | Q1,00 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | 1 | 6 | | | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 9992K| 57M| 4947 (1)| 00:01:00 | Q1,00 | PCWC | |
| 6 | TABLE ACCESS FULL| BIG_TABLE | 9992K| 57M| 4947 (1)| 00:01:00 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------
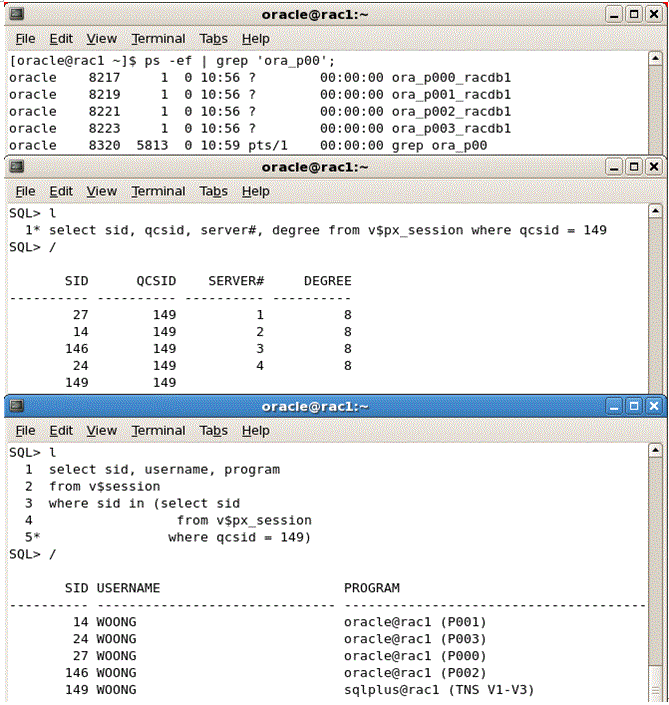
병렬실행 시 세션과 OS 모니터링
병렬실행 시 적절한 I/O환경
병렬 처리를 수행할 때 일반적으로 데이터가 가능한 한 많은 물리적 장치에 분산되어 있어야 최적화된다.
. RAID 스트라이핑 (striping) 디스크 시용
. 디스크의 내장형 스트라이핑 (striping) 에 ASM 사용
. 파티셔닝을 통해 BIG_TABLE을 여러 디스크에 물리적으로 분리
. 한 개의 테이블스페이스에 여러 데이터 파일로 구성하여 여러 데이터 파일에 익스텐트를 할당하도록 구현하는 것(segment striping)
병렬 쿼리에서 필요한 두 가지 사실
1. 병렬쿼리는 대량의 작업에서 수행되어야만 한다
-- 이것은 전형적인 OLTP 시스템에서는 병렬 쿼리를 적용하는 것이 해결책이 아님을 의미
2. CPU, I/O, 메모리와 같은 충분한 여유 자원이 확보된 경우에 수행되어야만 한다.
-- 이 중 어떠한 하나라도 만족하지 않는다면 병렬 쿼리는 자원활용의 한계에 부딪히게 되어 전체적인 성능과 수행 시간에 부정적인 영향을 미칠 것이다.
1cpu에서의 병렬실행
이론적으로 한 개의 CPU를 가진 장비에서도 병렬 쿼리의 효과를 볼 수 있다.
한 개의 CPU를 장착한 장비에서 하나의 명령이 CPU를 100% 사용한다고 확신할 수는 없다.
병렬 쿼리는 장비 상의 자원 최대한 활용할 수 있기 때문에 CPU를 100% 사용하게 할 수 있다.
하지만 한 개의 CPU를 가진 장비에서 두 개의 병렬쿼리를 동시에 수행하여 네 개의 세션이 발생했다면 아마도 응답 시간은 병렬 쿼리를 사용하지 않을 때보다 더 길어질 것이다. 한정된 자원을 확보하기 위한 프로세스가 많아질수록 모든 요청을 만족시키는 시간은 늘어날 것이기 때문이다
PSQ (Parallel Statement Queuing)
- PSQ를 사용할 때 데이터베이스는 병렬 세션 수를 제한하고,추가적인 병렬 요청을 실행 큐에 배치한다
- CPU 자원이 고갈되면 데이터베이스는 새로운 실행 요청이 활성화되지 못하도록 한다.
- 자원 사용이 가능해지면 큐에 있던 쿼리를 수행하기 시작한다
- 큐에서 대기하는 것이 발생하긴 하지만 결국 경합 없이 빠른 결과를 얻을 수 있다.