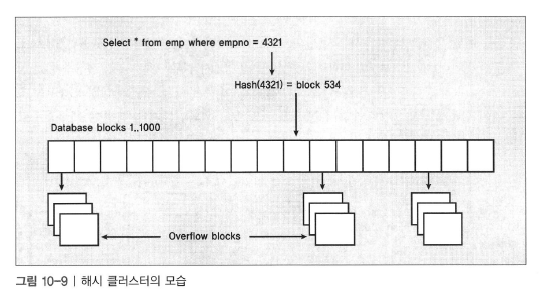
해시 클러스터 테이블
-- 클러스터 생성
CREATE CLUSTER hash_cluster(hash_key NUMBER) HASHKEYS 1000 SIZE 8192;
-- 테이블 생성
CREATE TABLE hashed_table
( x NUMBER
, data1 VARCHAR2(4000)
, data2 VARCHAR2(4000)
)
CLUSTER hash_cluster(x)
;
해시 클러스터 테이블 요약
- 해시 클러스터는 클러스터 인텍스를 시용하지 않는점을 제외하면, 인텍스 클러스터와 개념이 유사하다.
- 해시 클러스터는 데이터가 곧 인텍스가 된다.
- 클러스터 키는 블록 주소로 해시되고 데이터가 그 블록에 있으리라는 것을 예상할 수 있다.
해시 클러스터에 대해 기억해야할중요한내용은 다음과같다.
- 해시 클러스터는 시작부터 공간을 바로 할당된다.
- 오라클은 HASHKEYS/trunc(blocksize/SIZE)값을 구해서 할당하고 공간을 바로 확보한다.
- 처음에 테이블이 클러스터에 생성되자마자 전체 스캔이 발생하면 할당된 전체 블록을 읽을 것이다 이러한 특성은 다른 유형의 테이블과 다르다.
- HASHKEY 값은 고정 크기다.
- 해시 테이블의 크기를 바꾸려면 클러스터 를 재생성해야 한다.
- 이것은 어쨌든 클러스터에 저장할수 있는 데이터량에 제한이 발생하는 것은 아니며, 단지 유일한 해시키 값의 숫자를 제한하는 것 이다.
- 이 점은 해시값이 너무 작게 설정 되어 있다면, 의도하지 않은 해시 충돌을 일으켜 성능에 영향을 미치게 될 것이다.
- 클러스터 키를 이용한 부분 범위 읽기 (RANGE SCAN)는 가능하지 않다.
- cluster-key BETWEEN 50 AND 60과 같은 범위 조건은 해싱 알고리즘을 이용하여 처리할 수 없다
- 50과 60 사이는 대단히 많은 숫자가 존재하기 때문에 시스템이 각각의 값을 모두 해싱해서 데이터가 있는지 알아봐야 하는 것은 불가능하기 때문이다
- 클러스터 키로 부분 범위를 읽고자 하고 일반적인 인텍스가 없다면, 클러스터는 전제 스캔이 발생할 것 이다.
해시 클러스터는 다음과 같은 경우에 적합하다.
- 테이블에 얼마나 많은 데이터가 발생될 것인지 정확하게 알고 있거나 혹은 구체적인 데이터 발생 최대값을 알고 있는 경우다
- HASHKEY의 크기와 SIZE 파라미터를 적절히 구성하는 것이 재생성을 막는 중요한 과제다.
- DML, 특히 삽입이 추출에 비해 적은 경우다.
- 이것이 의미하는 것은, 신규 데이터 생성과 최적화된 데이터 추출 간에 균형을 이루어야 한다는 것이다.
- 가벼운 삽입은 데이터 추출 패턴에 따라 한사용자당 100,000 번이 될 수 있고, 다른 경우에는 100번이 될 수 있다.
- 변경 작업은 HASHKEY를 변경하지 않는 한 중요한 오버헤드가 아니며 키 변경을 통해 로우 이동을 일으키는 것은 바람직하지 않다
- HASHKEY 조건으로 빈번하게 데이터를 액세스하는 경우다.
- 예를 들어 부품 테이블을 가지고 있고, 부품은 부품 변호로 항상 액세스된다고 하자. 이 때 검색 테이블은 해시 클러스터 가 적합할 수 있다.