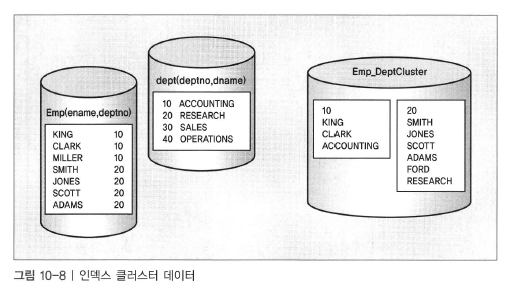
인덱스 클러스터 테이블
- MSSQL, Sybase 의 클러스터 인덱스는 오라클의 클러스터와는 다르다. 오라클의 IOT 와 유사.
- 오라클의 클러스터는 공통의 컬럼을 사용하는 테이블 그룹을 함께 저장하며, 연관된 데이터를 동일 블록에 함께 저장하도록 하는 방식이다.
-- 클러스터 생성
CREATE CLUSTER emp_dept_cluster(deptno NUMBER(2)) SIZE 1024;
SIZE 옵션은 클러스터의 가장 중요한파라미터다.
- 한 블록에 저장할 수 있는 최대 클러스터 키의 수를 결정하며, 공간 사용에 가장 큰 영향을 미친다.
- 크기를 너무 크게 잡아서 각 블록에 단지 몇 개의 키만을 가지도록 한다면 필요한 공간보다 더 많은 공간을 사용하게 될 것이고
- 너무 작게 잡아서 과도한 데이터 체이닝이 발생한다면 하나의 블록에 데이터가 함께 저장된다는 클러스터의 장점에 반하는 결과가 초래할 것이다.
-- 클러스터 인덱스 생성
CREATE INDEX emp_dept_cluster_idx ON CLUSTER emp_dept_cluster;
-- 테이블 생성, Dept
CREATE TABLE dept
( deptno NUMBER(2) PRIMARY KEY
, dname VARCHAR2(14)
, loc VARCHAR2(13)
)
CLUSTER emp_dept_cluster(deptno)
;
-- 테이블 생성, Emp
CREATE TABLE emp
( empno NUMBER PRIMARY KEY
, ename VARCHAR2(10)
, job VARCHAR2(9)
, mgr NUMBER
, hiredate DATE
, sal NUMBER
, comm NUMBER
, deptno NUMBER(2) REFERENCES dept(deptno)
)
CLUSTER emp_dept_cluster(deptno)
;
클러스터를 사용하지 않아야 하는 경우.
- 클러스터 테이블에 대량의 수정이 발생할 수 있는 경우
- 인텍스 클러스터는 DML 문의 성능, 특히 INSERT 문의 성능에 부정적인 영향을 미칠 수 있다.
- 클러스터 테이블에 대하여 전체 스캔을 수행할 때
- 단순히 한 테이 블을 전체 스캔하는 것보다 많은 테이블을 전체 스캔해야 한다.
- 테이블을 파티션해야 하는 경우
- 클러스터에 있는 테이블은 파티션을 구성할 수 없으며, 클러스터 도마찬가지다.
- 빈번하게 TRUNCATE와 데이터 적재를 수행해야 하는 경우
- 클러스터에 있는 테이블은 TRUNCATE할 수 없다.
클러스터를 사용을 고려 하는 경우.
- 논리적으로 연관성이 높아 함께 조인된 결과정보를 자주 읽는다면 클러스터가 적합한 방법이 될 수 있다.
인덱스 클러스터 테이블 요약
- 클러스터 테이블은 물리적으로 데이터를 미리 조인할 수 있게 한다.
- 동일한 데이터베이스 블록에 관련된 많은 테이블의 데이터를 함께 저장하기 위해서 클러스터를 사용한다.
- 클러스터는 항상 함께 조인되거나 관련된 데이터의 집합(부서 10에 있는 모든 사람 등)을 얻기 위한 읽기 중심 의 수행에 적합하다.
- 클러스터 테이블은 오라클이 캐시해야 하는 블록의 수를 감소시킨다.
- 클러스터 테이블은 동일 부서에 있는 사원 10명을 위해서 10개 블록을 캐시하지 않고, 하나의 블록에 저장하여 버퍼 캐시의 효율성을 증대시킬 수 있다.
- 부정적인 측면으로는 SIZE 파라미터를 정확하게 계산하여 설정하지 않는다면 공간활용에 비효율이 발생하고 대량의 DML 수행 시에는 성능이 느려질 수 있다.