- 작업시 생성되는 리두가 얼마나 되는지 측정할 필요가 있다.
- LGWR 은 오라클 인스턴스에서 하나만 존재한다.
- LGWR 은 리두관리, 커밋요청 작업을 한다.
- LGWR 이 수행하는 일이 많을수록 시스템은 느려진다.
리두 측정하기
- conventional path INSERT (버퍼캐시 경유) VS direct-path INSERT 생성되는 리두 의 차이점
Conventional path INSERT
SQLPLUS >set autot traceonly statistic
SQLPLUS >truncate table t ;
Table truncated.
SQLPLUS >insert into t
2 select * from big_table ;
565568 rows created.
Statistics
----------------------------------------------------------
654 recursive calls
35161 db block gets
14419 consistent gets
3 physical reads
59319436 redo size <-------------- 59MB 정도의 리두가 생성됨.
837 bytes sent via SQL*Net to client
790 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
565568 rows processed
direct-path INSERT
- 필자는 NOARCHIVELOG 모드 데이터베이스에서 테스트하였다.
- 테스트DB 가 ARCHIVELOG 모드여서 테이블만 nologging 으로 변경하고 실행했다.
SQLPLUS >truncate table t ;
Table truncated.
SQLPLUS >alter table t nologging ;
Table altered.
SQLPLUS >insert /*+ APPEND */ into t
2 select * from big_table ;
565568 rows created.
Statistics
----------------------------------------------------------
777 recursive calls
5788 db block gets
6116 consistent gets
2 physical reads
153404 redo size <-------------- 리두가 153KB 생성되었다.
825 bytes sent via SQL*Net to client
804 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
7 sorts (memory)
0 sorts (disk)
565568 rows processed
-- ====================================
-- 추가테스트
-- ====================================
SQLPLUS >truncate table t ;
Table truncated.
-- t 테이블은 logging 모드 테이블이다.
-- 데이터베이스는 ARCHIVELOG 모드이다.
SQLPLUS >insert /*+ APPEND */ into t
2 select * from big_table ;
565568 rows created.
Statistics
----------------------------------------------------------
736 recursive calls
5790 db block gets
6068 consistent gets
2 physical reads
61532396 redo size <----------------
823 bytes sent via SQL*Net to client
804 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
565568 rows processed
SQLPLUS >truncate table t ;
Table truncated.
SQLPLUS >insert /*+ APPEND NOLOGGING */ into t
2 select * from big_table ;
565568 rows created.
Statistics
----------------------------------------------------------
736 recursive calls
5791 db block gets
6068 consistent gets
2 physical reads
61532396 redo size <--------
824 bytes sent via SQL*Net to client
814 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
565568 rows processed
리두 로그를 생성하지 못하도록 막을 수 있을까?
아니오.
- 리두로깅은 데이터베이스의 핵심기능.
- 9i 릴리즈 2 에서는 데이터베이스를 FORCE LOGGING 모드로 변경 가능. 모든작업이 로깅된다.
- SELECT FORCE_LOGGING FROM V$DATABASE ; 로 확인가능.
- Data Guard 를 지원한다.
SQL에서 NOLOGGING 설정
- NOLOGGING : 리두를 아예 생성하지 않는다는 의미가 아님. 상당히 적은 양의 리두를 생성한다.
- NOLOGGING 옵션 없이 CTAS로 테이블 생성시 리두 발생 확인
SQLPLUS >select log_mode from v$database ;
LOG_MODE
------------
ARCHIVELOG
SQLPLUS >drop table t purge ;
Table dropped.
SQLPLUS >variable redo number
SQLPLUS >exec :redo := get_stat_val('redo size');
PL/SQL procedure successfully completed.
SQLPLUS >create table t
2 as select * from all_objects ;
Table created.
SQLPLUS >exec dbms_output.put_line( (get_stat_val('redo size')-:redo) || ' bytes of redo generated ...') ;
1996548 bytes of redo generated ...
PL/SQL procedure successfully completed.
-- 1.9 MB 정도의 리두 생성됨.
- NOLOGGING 옵션 사용하여 CTAS로 테이블 생성시 리두 발생 확인
SQLPLUS >drop table t purge ;
Table dropped.
SQLPLUS >variable redo number
SQLPLUS >exec :redo := get_stat_val ('redo size');
PL/SQL procedure successfully completed.
SQLPLUS >create table t
2 NOLOGGING
3 as
4 select * from all_objects;
Table created.
SQLPLUS >set serveroutput on
SQLPLUS >exec dbms_output.put_line( (get_stat_val('redo size')-:redo)|| ' bytes of redo generated..');
78644 bytes of redo generated ..
PL/SQL procedure successfully completed.
-- 78KB 정도의 리두 생성됨.
- NOARCHIVELOG 모드 데이터베이스에서였다면 차이가 없었을 것.
- (NOARCHIVELOG 모드일 경우 CREATE TABLE 은 데이터 딕셔너리 변경 이외에 나머지는 로깅되지 않는다.)
NOLOGGING 작업 주의사항
- 백업 복구 담당자와 반드시 논의후 사용한다.
- 어느정도 리두는 생성 된다. (데이터 딕셔너리를 보고하기 위한 것)
- NOLOGGING 이후에 일어나는 DML작업은 리두로깅 된다.
- (direct-path load 로 sql loader를 사용 / insert append 문법으로 direct-path insert 만 로깅안함)
- ARCHIVELOG 모드 데이터베이스에서는 NOLOGGING 작업으로 생성된 데이터에 대한 백업 기준을 정해야 한다.
- 백업파일에 없을 경우, 리두로그파일에도 없어서 데이터 복구 방법이 없다.
인덱스에 NOLOGGING 설정하기
- 인덱스나 테이블을 NOLOGGING 모드로 변경한 이후 rebuild 시 로깅되지 않는다.
-- 1. LOGGING 으로 INDEX Rebuild
SQLPLUS >create index t_idx on t (object_name) ;
Index created.
SQLPLUS >variable redo number
SQLPLUS >exec :redo := get_stat_val('redo size');
PL/SQL procedure successfully completed.
SQLPLUS >alter index t_idx rebuild ;
Index altered.
SQLPLUS >exec dbms_output.put_line( (get_stat_val('redo size')-:redo) || ' bytes of redo generated ...') ;
9733976 bytes of redo generated ...
PL/SQL procedure successfully completed.
-- 9MB 리두 생성됨
-- 2. NOLOGGING 으로 변경 후 INDEX Rebuidl
SQLPLUS >alter index t_idx nologging ;
Index altered.
SQLPLUS >exec :redo := get_stat_val('redo size');
PL/SQL procedure successfully completed.
SQLPLUS >alter index t_idx rebuild ;
Index altered.
SQLPLUS >exec dbms_output.put_line( (get_stat_val('redo size')-:redo) || ' bytes of redo generated ...') ;
77800 bytes of redo generated ...
PL/SQL procedure successfully completed.
-- 77KB 리두 생성됨.
-- 이 상태에서 백업 없이 장애발생 시, t_idx 인덱스는 데이터를 잃게된다.
NOLOGGING 요약 (NOLOGGING으로 할 수 있는 작업)
- 인덱스 생성과 rebuild
- /*+ APPEND */ 힌트 또는 SQL Loader direct-path INSERT 로 벌크INSERT.
- 주의 : 테이블 데이터는 리두로깅 안되나, 인덱스 변경에 대한 리두는 생성된다.
- LOB 작업 (대용량객체의 update)
- CREATE TABLE AS SELECT 를 이용한 테이블 생성
- MOVE, SPLIT 과 같은 ALTER TABLE 작업들
- 적절한 NOLOGGING 작업은 리두로그양을 줄임으로서 작업을 극적으로 개선할 수 있다.
- ex) 테이블을 다른 테이블스페이스로 옮길 때
- 그러나 복구에 문제가 생길 수 있으므로 주의한다.
왜 새로운 로그를 할당할 수 없는가 ?
alert.log

- DBWR이 리두로그에 의해 보호되는 데이터에 대한 체크포인트를 완료하지 않았거나
- ARCH가 리두로그 파일을 아카이브 저장소에 복제 완료하지 않았을 때 발생되는 메시지.
- 온라인 리두로그파일을 재사용하려고 하는데
- 체크포인트가 완료되지 않았거나 / 아키이빙이 안되고 있을 경우 리두 로그파일을 안전하게 사용할 수 있을 때까지 대기한다.
- 리두 로그 파일 크기를 매우 작게 잡을 경우 발생할 수 있음.
해결방안
- DBWR 속도를 빠르게 한다.
- DBWR I/O 슬레이브 또는 DBWR 프로세스를 여러개 띄워 비동기I/O가 가능하도록 DBWR튜닝.
- 리두 로그 파일을 추가하라.
- 'Checkpoint not complete' 발생 빈도를 최대로 줄일 수 있다.
- 시스템 멈춤 현상을 제거한다.
- 로그 파일을 좀 더 크게 재생성하라.
- 로그파일 채우는 시간과 재사용하는 시간 간격을 늘려준다.
- 리두로그파일을 대량으로 소모하는 작업이 많을 경우 ARCH가 아카이빙하는 시간을 충분히 벌 수 있다.
- 체크포인트 발생 시간 간격도 늦출 수 있다.
- 체크포인트가 좀 더 빈번하게 일어나도록 하라.
- 블록 버퍼캐시를 작게 잡거나, DBWR 이 더티블록을 자주 플러시하도록 강제(파라미터 변경)하라.
- 복구 시 적용하는 리두로그 양이 적어짐.
- 단점은 버퍼캐시의 본래 효과를 발휘하지 못함.
블록 클린아웃
블록 클린아웃
- '락킹' 관련 정보를 제거. (트랜잭션에 의해 설정된 Lock을 해제하고 블록 헤더에 커밋 정보를 기록)
- 버퍼캐시의 10% 를 초과하는 블록은 다음 번 액세스 시 클린아웃(트랜잭션 정보 제거) 될 수 있다.
- 블록 클린아웃 시 리두를 생성, dirty 상태가 아닌 블록을 dirty 상태로 만든다.
- direct-path load 작업 수행 / load 작업 후 테이블 분석으로 DBMS_STAT 수행하면 일반적으로 블록이 클린된다.
커밋 클린아웃
- 블록이 SGA에 있고 액세스 가능할 경우 해당 블록을 재방문하여 클린아웃 하는 것.
- SELECT문이 클린아웃할 필요없이 커밋 시점에 클린아웃하는 최적의 방법.
클린아웃 동작 테스트 : SELECT 시 리두가 생성되는 것을 확인하는 테스트.
- 조건
- DB_CACHE_SIZE 16MB ( 8KB 블록 * 2048개 )
- 한 블록에 정확히 한 로우가 들어가도록 테이블을 생성
- 테이블에 로우를 10000개 채우고 커밋
- 블록 10000개는 2048개의 10% 를 초과하므로 커밋 시 dirty블록 모두 클린아웃할 수 없다.
- 커밋완료시점까지 생성된 리두 양을 측정, 각 블록을 방문하는 SELECT 가 생성하는 리두 양을 측정한다.
- SGA 자동 메모리 관리 비활성화. (버퍼캐시 크기가 임의로 증가될 수 있으므로)
테스트 결과로 예상하는 것
- SELECT 만 해도 리두를 생성할 것이다.
- dirty 블록을 방문하는 순간 DBWR 가 블록을 다시 디스크에 기록하게 한다. (블록 클린아웃에 기인)
- 쿼리시 하드파싱되지 않도록 DBMS_STAT 수행. 하드파싱 동안 통계정보를 갖지않는 객체를 스캔한다. (결과는 아직 데이터가 없으니 실패함)

- 722KB 리두 생성됨. 기본키 인덱스를 읽고 테이블 T를 읽는동안 변경된 블록헤더의 리두이다.
- 버퍼 캐시 블록을 100,000개 보다 많이 수용하도록 설정 후 테스트하면 SELECT 문 실행 시 리두를 거의 또는 아예 생성하지 않음을 확인할 수 있다. (dirty 블록을 클린아웃 할 필요 없기 때문)
- 이런 클린아웃 매커니즘은 대용량 INSERT/UPDATE/DELETE 후 많은 데이터베이스 블록에 영향을 미친다. (캐시의 10%를 넘어가는 블록은 명백히 커밋 클린아웃 되지 않는다.)
- 대량DML 이후 블록을 조회하는 첫 번째 쿼리가 리두를 생성, 그 블록을 diry 상태로 바꾼다.
- OLTP 환경에서는 지연된 블록클린아웃 현상을 보기 힘들다. 작고 간단한 트랜잭션이 대부분이기 때문.
- CTAS, direct-path 로 적재된 데이터는 모두 클린 블록을 만든다.
- 대량 데이터 적재 -> 적재한 데이터에 UPDATE 실행 -> 클린아웃이 필요한 블록이 생산됨.
- 통계정보를 수집하는 DBMS_STAT 유틸리티 실행 시 모든 블록을 클린아웃한다.
로그 경합
- 'log file sync' / 'log file parallel write' 이벤트에 대한 대기시간으로 로그 경합을 확인할 수 있다.
로그 경합의 원인
- 어플리케이션에서 잦은 커밋
- 느린 디바이스에 리두 저장
- 자주 액세스 되는 다른 파일과 같은 디바이스에 리두 저장
- 로그 디바이스를 버퍼링 방식으로 마운트 (OS버퍼링 + DB리두로그 버퍼 = 중복된 버퍼링 시 시스템 지연)
- RAID-5 처럼 느린 RAID 기술로 리두로그 저장 (RAID5 쓰기성능 최악)
디스크 배치 권고
- 디스크 쓰기 경합을 최소화 한다.
- 리두 로그 그룹 1 : 디스크 1 과 3
- 리두 로그 그룹 2 : 디스크 2 와 4
- 아카이브 : 디스크 5와 선택적 디스크 6(용량 큰 디스크)
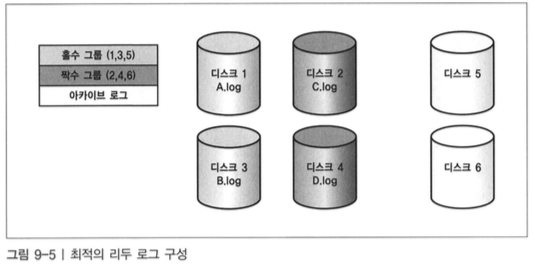
- 멤버 A, B (리두로그 그룹1) : 디스크 1,3
- 멤버 C, D (리두로그 그룹2) : 디스크 2,4
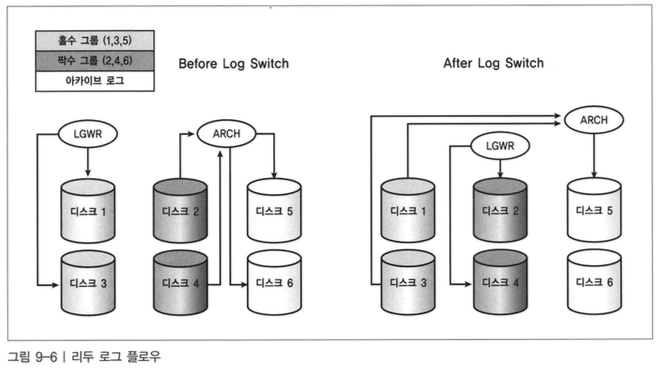
- ARCH 와 LGWR 간 경합이 존재하지 않도록 한다.
임시 테이블과 리두/언두
- 이번 절에서는 "로깅과 관련해서 임시테이블은 어떻게 동작하는가" 에 대해 알아본다.
- 10장 데이터베이스 테이블에서 임시테이블의 모든것을 다룰 것이다.
- 임시테이블의 데이터 블록에 대해서는 리두를 생성하지 않는다. -> 복구 불가.
- 임시테이블의 데이터 블록을 변경하면 리두를 생성하지 않는다. 그러나 언두를 생성한다. -> 언두에 대한 리두는 어느정도 발생.
- 언두 발생 이유 : 트랜잭션 내 savepoint 까지 롤백할 수 있기 때문에 필요하다.
- 임시테이블에서 발생되는 언두에 대한 리두로깅을 측정하는 테스트.
SQLPLUS >create table perm
2 ( x char(2000),
3 y char(2000),
4 z char(2000) )
5 /
Table created.
SQLPLUS >create global temporary table temp
2 ( x char(2000),
3 y char(2000),
4 z char(2000) )
5 on commit preserve rows
6 /
Table created.
create or replace procedure do_sql (p_sql in varchar2 )
as
l_start_redo number;
l_redo number;
begin
l_start_redo := get_stat_val('redo size');
execute immediate p_sql;
commit ;
l_redo := get_stat_val('redo size') - l_start_redo ;
dbms_output.put_line
( to_char(l_redo,'99,999,999') || ' bytes of redo generated for "' ||
substr(replace(p_sql, chr(10), ' ' ), 1, 25) || '" ... ') ;
end;
/
Procedure created.
- PERM, TEMP 테이블 대상으로 동일INSERT/UPDATE/DELETE 실행
SQLPLUS > set serveroutput on format wrapped
SQLPLUS > begin
do_sql ( 'insert into perm
select 1, 1, 1
from all_objects
where rownum <= 500' );
do_sql ( 'insert into temp
select 1, 1, 1
from all_objects
where rownum <= 500' );
dbms_output.new_line ;
do_sql('update perm set x = 2');
do_sql('update temp set x = 2');
dbms_output.new_line ;
do_sql('delete from perm');
do_sql('delete from temp');
dbms_output.new_line ;
end;
/
-- 결과
3,120,244 bytes of redo generated for "insert into perm " ...
41,332 bytes of redo generated for "insert into temp " ...
2,126,084 bytes of redo generated for "update perm set x = 2" ...
1,067,252 bytes of redo generated for "update temp set x = 2" ...
3,200,608 bytes of redo generated for "delete from perm" ...
3,156,716 bytes of redo generated for "delete from temp" ...
결과정리
- INSERT
- 일반테이블 : 많은 리두 생성 / 임시테이블 : 리두 거의 생성안함.
- 임시테이블에서는 언두만 로깅되며, INSERT 는 언두 데이터가 거의 일반,임시테이블에 모두 거의 없다.
- UPDATE
- 일반테이블 : 리두양이 임시테이블보다 약 두개 정도 생성됨. / 임시테이블 : after image(리두) 가 저장안되므로 두배차이.
- DELETE
- 일반테이블/임시테이블 모두 비슷하다. DELETE 에 대한 언두는 크기 때문에 일반,임시테이블 대상으로 비슷한 양이 생성된다.
- INSERT 는 언두와 리두를 거의 또는 아예 만들지 않는다.
- DELETE 는 일반 테이블과 동일한 양의 리두를 생성한다.
- UPDATE 는 일반 테이블 리두 양의 반 정도를 생성한다.
- 임시테이블에 인덱스가 있을 경우, 인덱스 변경에 대한 언두(언두에 대한 리두 까지) 생성된다.
SQLPLUS >create index perm_idx on perm(x) ;
Index created.
SQLPLUS >create index temp_idx on temp(x);
Index created.
..
8,613,908 bytes of redo generated for "insert into perm " ...
3,029,920 bytes of redo generated for "insert into temp " ...
7,632,424 bytes of redo generated for "update perm set x = 2" ...
5,210,624 bytes of redo generated for "update temp set x = 2" ...
4,310,508 bytes of redo generated for "delete from perm" ...
4,252,840 bytes of redo generated for "delete from temp" ...
- 임시테이블에 인덱스 추가 시 생성되는 언두(리두) 양이 이전 결과보다 많아짐을 확인할 수 있다.
- INSERT 를 언두 하는 것은 쉽지만 (0 byte로 되돌림) DELETE 를 언두하는 것은 기존 데이터의 bytes 수 만큼의 데이터를 INSERT 하는 것이므로 이 리두는 중요하다.
- 임시테이블의 DELETE 는 피하자.
- 커밋하거나 세션이 끝났을 때 임시테이블이 자동으로 비워지는 옵션을 선택하여 언두를 전혀 생성하지 않도록 하자.
- 임시테이블을 수정하는 것은 가급적 피하자. INSERT, SELECT 작업으로만 사용해야 한다.
- 리두를 생성하지 않는 임시테이블만의 장점을 최대로 활용할 수 있다.



