테이블 Random 액세스 부하,. (by aini79) [2014.06.27]
04. 테이블 Random 액세스 부하
(1) 인덱스 ROWID에 의한 테이블 액세스
- 쿼리에서 참조되는 컬럼이 인덱스에 모두 포함되지 않는 경우 인덱스 스캔 -> 테이블 Random 액세스 일어남

ROWID
- 인덱스에 저장
- 흔히 '물리적 주소정보' - 오브젝트 번호, 데이터파일 번호, 블록번호 등의 물리적 요소로 구성
- 때로 '논리적 주소정보' - 물리적 위치정보로 구성되지만 인덱스에서 테이블 레코드로 직접 연결되는 구조는 아니기 때문
메인 메모리 DB와의 비교
- 메인메모리DB의 개요
- 메인메모리DB(MMDB,MainMemoryDB)의 정의
- 데이터베이스 전체를 주기억장치에 상주시킨 데이터베이스
- 서버가 부팅됨과 동시에 데이터베이스 전체를 메인메모리에 상주 시킨 후, 데이터베이스 연산을 수행하는 시스템
- MMDB 특징
- 모든 연산을 메인 메모리에서 수행, 디스크 I/O 발생하지 않음
- 데이터 조작을 위해 디스크에 접근 할 필요성이 없기 때문에 속도가 향상 됨
- 주 기억 장치에 휘발성으로인한 오류 회복이 주요 해결 과제임
- 메인메모리DB(MMDB,MainMemoryDB)의 정의
- MMDB의 구조

- 메인메모리DB와디스크기반DB 비교

※ 버퍼캐시히트율이 99% 이상인 오라클 DB라면 메모리상에서 I/O가 수행될텐데도 메모리 DB만큼 빠르지는 않다. 그 이유는?
- MMDB의 인덱스는 데이터를 버퍼캐시에 로딩시 실시간으로 생성 -> 메모리상의 주소정보, 즉 포인터를 담는다. 전화번호에 비유.
- 오라클의 인덱스는 포인터로 연결 불가, DBA(Data Block Address) 를 해시 키 값으로 삼아 해싱 알고리즘을 통해 버퍼 블록을 찾는다. 우편주소에 비유.
인덱스 rowid에 의한 테이블 액세스 구조
- 오라클도 포인터로 빠르게 액세스 하는 버퍼 Pinning 기법을 사용하지만 반복적으로 읽힐 가능성이 큰 블록에 대해서만 일부 적용
(ex. 인덱스를 스캔하면서 테이블을 액세스할 때의 인덱스 리프블록) - 일반적인 인덱스 rowid에 의한 테이블 액세스는 고비용
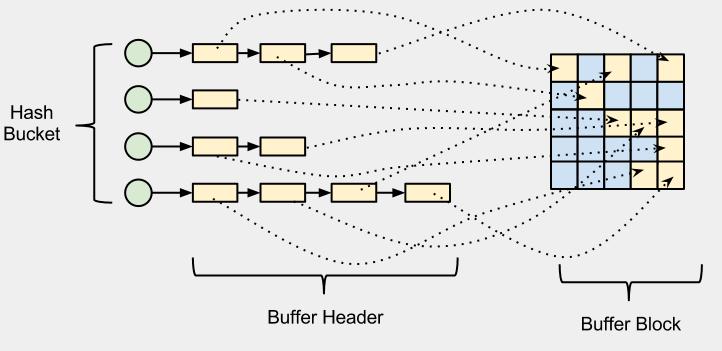
최악의 경우
- 인덱스에서 하나의 rowid를 읽고 DBA(Data Block Address, 디스크 상의 블록 위치 정보)를 해시 함수에 적용해 해시 값을 확인
- 해시 값이 가리키는 해시 체인에 대한 래치(-> cache buffers chains 래치)를 얻으려고 시도.
하나의 cache buffers chains 래치가 여러 개 해시 체인을 동시에 관리함 - 다른 프로세스가 래치를 잡고 있으면 래치가 풀렸는지 확인하는 작업을 일정 횟수(기본 설정은 2,000번) 만큼 반복
- 그러고도 실패하면 CPU를 OS에 반환하고 잠시 대기 상태로 빠지는데, 이때 latch free(10g 부터는 latch: cache buffers chains으로 세분화) 대기 이벤트 발생
- 정해진 시간 동안 잠을 자다가 깨어나서 다시 래치 상태를 확인하고, 게속해서 래치가 풀리지 않으면 또다시 대기 상태로 빠질 수 있음
- 래치가 해제되었다면 래치를 재빨리 획득하고 원하던 해시 체인으로 진입
- 거기서 데이터 블록이 찾아지면 래치를 해제하고 바로 읽으면 되는데, 앞서 해당 블록을 액세스한 프로세스가 아직 일을 마치지 못해 버퍼 Lock을 쥔 상태라면 또 다시 대기
(이때 나타나는 대기 이벤트가 buffer busy waits) - 블록 읽기를 마치고 나면 버퍼 Lock을 해제해야 하므로 다시 해시 체인 래치를 얻으려고 시도, 이때 또다시 경합이 발생할 수 있음
--> 해시 체인을 스캔했는데 데이터 블록을 찾지 못했다면
- 디스크로부터 블록을 퍼 올리기 위해 Free 버퍼를 할당 받아야 하므로 LRU 리스트를 스캔, 이를 위해 cache buffer lru chain 래치를 얻어야 함.
래치 경합이 심할 때는 latch free 이벤트(10g 부터 latch: cache buffers lru chain 으로 세분화)가 나타날 수 있음 - LRU 리스트를 정해진 임계치만큼 스캔했는데도 Free 상태의 버퍼를 찾지 못하면 DBWR에게 Dirty 버퍼를 디스크에 기록해 Free 버퍼를 확보해 달라는 신호를 보냄.
그 후 해당 작업이 끝날 때까지 잠시 대기 상태에 빠짐(free buffer waits 대기 이벤트) - Free 버퍼를 할당받은 후에는 I/O 서브시스템에 I/O 요청을 하고 다시 대기상태에 빠짐(db file sequential read 대기 이벤트)
- 마지막으로, 읽은 블록을 LRU 리스트 상에서 위치를 옮기기 위해 cache buffers lru chain 래치를 얻어야 하는데 원활하지 못할 때는 latch free 이벤트 나타남
(!) 최악의 상황이긴 하나, 오라클에서 하나의 레코드를 찾아가는 데 있어 가장 빠르다고 알려진 rowid에 의한 테이블 액세스가 경우에 따라 이렇게까지 고비용이라는 사실을 염두에 두어야 한다.
(2) 인덱스 클러스터링 팩터
군집성 계수(= 데이터가 모여있는 정도)
- 클러스터링 팩터(Clustering Factor, CF): 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도
- CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋음
- 인덱스 CF가 가장 좋은 상태 - 인덱스 레코드 정렬 순서와 거기서 가리키는 테이블 레코드 정렬 순서가 100% 일치

- 인덱스 CF가 가장 안 좋은 상태 - 인덱스 레코드 정렬 순서와 거기서 가리키는 테이블 레코드 정렬 순서가 전혀 일치하지 않음

클러스터링 팩터 조회
-- 테이블 레코드가 object_id 순으로 입력되도록 t 테이블 생성
create table t
as
select * from all_objects
order by object_id;
-- object_id와 object_name 각각에 대한 인덱스 생성
create index t_object_id_idx on t(object_id);
create index t_object_name_idx on t(object_name);
-- 통계정보 수집
exec dbms_stats.gather_table_stats(user, 'T');
SQL> select i.index_name, t.blocks table_blocks, i.num_rows, i.clustering_factor
2 from user_tables t, user_indexes i
3 where t.table_name = 'T'
4 and i.table_name = t.table_name;
INDEX_NAME TABLE_BLOCKS NUM_ROWS CLUSTERING_FACTOR
------------------------------------------------------------ ------------ ---------- -----------------
T_OBJECT_NAME_IDX 242 18100 7988
T_OBJECT_ID_IDX 242 18100 242
- clustering_factor 수치가 table_blocks 에 가까울수록 데이터가 잘 정렬돼 있음을 의미, num_rows에 가까울수록 흩어져 있음을 의미
※ 인덱스 통계를 수집할 때 clustering_factor 계산을 위해 오라클이 사용하는 로직
1. counter 변수를 하나 선언
2. 인덱스 리프 블록을 처음부터 끝까지 스캔하면서 인덱스 rowid로부터 블록 번호를 취함
3. 현재 읽고 있는 인덱스 레코드의 블록 번호가 바로 직전에 읽은 레코드의 블록 번호와 다를때마다 counter 변수 값을 1씩 증가
4. 스캔을 완료하고서, 최종 counter 변수 값을 clustering_factor로서 인덱스 통계에 저장
- 측정된 CF 값은 옵티마이저가 (테이블 Full Scan과 비교해) 인덱스 Range Scan을 통한 테이블 액세스 비용을 평가하는 데에 사용
비용 = blevel + -- 인덱스 수직적 탐색 비용
(리프 블록 수 x 유효 인덱스 선택도) + -- 인덱스 수평적 탐색 비용
(클러스터링 팩터 x 유효 테이블 선택도) -- 테이블 Random 액세스 비용
- blevel : 리프 블록에 도달하기 전 읽게 될 브랜치 블록 개수
- 유효 인덱스 선택도 : 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율(%)
- 유효 테이블 선택도 : 전체 레코드 중에서 인덱스 스캔을 완료하고서 최종적으로 테이블을 방문할 것으로 예상되는 비율(%) |
클러스터링 팩터와 물리적 I/O
- "인덱스 CF가 좋다" = 인덱스 정렬 순서와 테이블 정렬 순서가 서로 비슷하다는 것
- 블록 단위로 이루어지는 I/O에서 인덱스를 통해 하나의 레코드를 읽으면 같은 블록에 속한 다른 레코드들도 함께 캐싱
- CF가 좋은 인덱스 였다면 그 레코드들도 가까운 시점에 읽힐 가능성이 높다
- 인덱스를 스캔하면서 읽는 테이블 블록들의 캐시 히트율이 높아지므로 물리적인 디스크 I/O 횟수가 감소
- 값이 같은 레코드들이 서로 멀리 떨어져 있다면 논리적으로 더 많은 블록을 읽어야 하므로 물리적인 디스크 I/O 횟수도 같이 증가
- 또 앞서 읽었던 테이블 블록을 다시 방문하고자 할 때 이미 캐시에서 밀려나고 없다면 같은 블록을 디스크에서 여러 번 읽게 되므로 I/O 효율은 더 나빠짐
클러스터링 팩터와 논리적 I/O
- 인덱스 CF = "인덱스를 경유해 테이블 전체 로우를 액세스할 때 읽을 것으로 예상되는 논리적인 블록 개수"
- CF도 궁극적으로 물리적 I/O 비용을 평가하기 위한 수단
- 옵티마이저가 사용하는 비용 계산식은 기본적으로 물리적인 I/O만을 고려(논리적 I/O가 모두 물리적 I/O를 수반한다고 가정)
- 그러나 논리적 I/O가 100% 물리적 I/O를 수반한다는 가정은 매우 비현실적
(앞서 읽었던 테이블 블록을 다시 읽을 때 실제로는 캐싱된 블록을 읽을 가능성이 훨씬 높음) - 캐싱 효과를 예측하기가 매우 어렵기 때문에 옵티마이저는 CF를 통해 계산된 논리적 I/O 횟수를 그대로 물리적 I/O 횟수로 인정하고 인덱스 비용을 평가
- 즉, 인덱스 통계의 clustering_factor는 인덱스를 통해 테이블을 액세스할 때 예상되는 논리적 I/O 개수를 더 정확히 표현함
SQL> select /*+ index(t t_object_id_idx) */ count(*) from t
2 where object_name >= ' '
3 and object_id >= 0;
Rows Row Source Operation
------- -----------------------------------------------------------------------
1 SORT AGGREGATE (cr=282 pr=0 pw=0 time=18049 us)
18100 TABLE ACCESS BY INDEX ROWID T (cr=282 pr=0 pw=0 time=20561 us cost=282 size=452500 card=18100)
18100 INDEX RANGE SCAN T_OBJECT_ID_IDX (cr=40 pr=0 pw=0 time=7932 us cost=40 size=0 card=18100)
- 테이블을 액세스하는 단계에서 읽은 블록 수는 240(=282-40)개로서, 앞에서 인덱스 통계에서 보았던 clustering_factor 수치와 정확히 일치한다.
SQL> select /*+ index(t t_object_name_idx ) */ count(*) from t
2 where object_name >= ' '
3 and object_id >= 0;
Rows Row Source Operation
------- -----------------------------------------------------------------------
1 SORT AGGREGATE (cr=8065 pr=0 pw=0 time=33698 us)
18100 TABLE ACCESS BY INDEX ROWID T (cr=8065 pr=0 pw=0 time=45303 us cost=8067 size=452500 card=18100)
18100 INDEX RANGE SCAN T_OBJECT_ID_IDX (cr=77 pr=0 pw=0 time=15329 us cost=77 size=0 card=18100)
- 테이블을 액세스하는 단계에서 읽은 블록 수는 7988(=8065-77)개로서, 역시 앞에서 보았던 clustering_factor 수치와 일치한다.
버퍼 Pinning에 의한 논리적 I/O 감소 원리
- 똑같은 개수의 레코드를 읽는데 인덱스 CF에 따라 논리적 블록 I/O 수가 심하게 차이나는 이유?
-> 연속된 인덱스 레코드가 같은 블록을 가리킨다면 래치 획득 과정을 생략하고 버퍼를 Pin한 상태에서 읽기 때문에 논리적 블록 읽기(Logical Reads) 횟수가 증가하지 않는다.
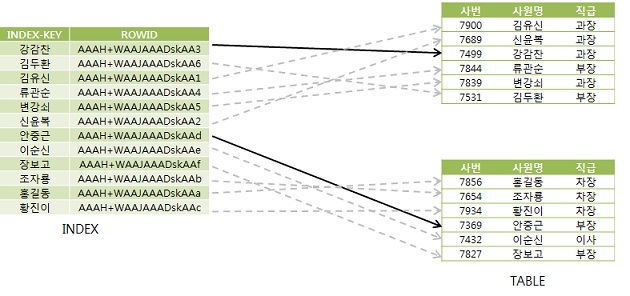
- 실선은 해시체인래치 획득 후 블록 액세스, 점선은 래치 획득 없이 버퍼를 Pin한 상태에서 액세스
- 두번째 '김두환'을 위해 테이블 블록을 읽을 때는 블록을 Pin 한 상태에서 액세스하기 때문에 논리적인 블록 I/O를 일으키지 않는다
- '안중근'에 도달해서야 다른 테이블 블록을 가리키므로 래치를 얻어 새로운 블록을 읽는다
- CF가 좋아(완전히 같은 순서로 정렬돼 있을 필요는 없으며 같은 테이블 블록에 모여있기만 하면 됨) Random 블록 I/O가 단 2회만 발생
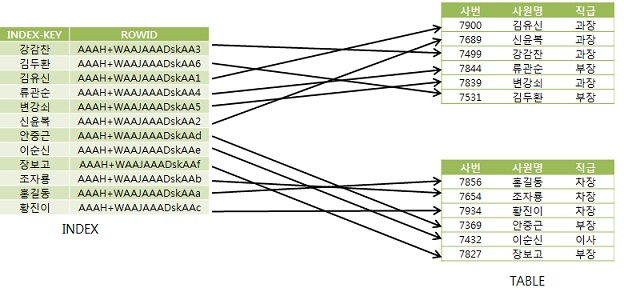
- 모두 실선 -> 매번 해시 체인 래치 획득 과정을 거쳐 무겁게 논리적 블록 읽기 수행
(3) 인덱스 손익분기점
- Index Range Scan에 의한 테이블 액세스가 Table Full Scan 보다 느려지는 지점
인덱스에 의한 액세스가 Full Table Scan 보다 더 느려지게 만드는 가장 핵심적인 두 가지 요인
- 인덱스 rowid에 의한 테이블 액세스는 Random 액세스, Full Table Scan은 Sequential 액세스
- 디스크 I/O시, 인덱스 rowid에 의한 테이블 액세스는 Single Block Read 방식, Full Table Scan은 Multiblock Read 방식
- 일반적으로 5 ~ 20%
- CF가 나쁘면 손익 분기점은 5% 미만, 심할 때는 1% 미만
- CF가 좋을 때는 90%까지 올라는 가는 경우도 있음
※ p.75~77 손익분기점 테스트 참조
- 인덱스 손익분기점은 데이터 상황에 따라 크게 달라지므로 정해진 수치 또는 범위를 정해놓고 효용성을 판단하면 틀리기 쉽다
- 테이블 스캔이 항상 나쁜 것은 아니며, 인덱스 스캔이 항상 좋은 것도 아니다.
- 테이블 Reorg로의 CF 향상은 최후의 수단
손익분기점을 극복하기 위한 기능들
1. IOT(Index-Organized Table)
- 테이블 자체가 인덱스 구조이므로 항상 정렬된 상태 유지
- 인덱스 리프블록 = 데이터블록
- 테이블 레코드를 읽기 위한 추가적인 Random 액세스 불필요
2. 클러스터 테이블(Clustered Table)
- 키 값이 같은 레코드는 같은 블록에 모이도록 저장
- 클러스터 인덱스를 이용할 때는 테이블 Random 액세스가 키 값별로 한 번씩만 발생
- 클러스터에 도달해서는 Sequential 방식으로 스캔하기 때문에 넓은 범위를 읽더라도 비효율 없음
3. 파티셔닝
- 읽고자 하는 데이터가 많을 경우 인덱스를 이용하지 않는 편이 낫지만, Full Scan도 난감
- 대량 범위 조건으로 자주 사용되는 컬럼 기준으로 테이블을 파티셔닝하면 Full Table Scan 하더라도 일부 파티션만 읽고 멈출 수 있다
- 클러스터는 기준 키 값이 같은 레코드를 블록 단위로 모아 놓지만, 파티셔닝은 세그먼트 단위로 모아 놓는다