2.쿼리변환 (by dolphhong) [2013.11.15]
제 2 절 쿼리변환
1. 쿼리변환이란 ?
- 쿼리변환(Query Transformation)
: 옵티마이저가 SQL을 분석하여 의미적으로 동일한 결과를 리턴하면서, 더 나은 성능이 기대되는 형태로 재작성하는 것. - DBMS 버전이 올라갈수록 종류가 다양해지고 적극적인 시도가 이루어지고 있다.
- 비용기반 옵티마이저의 서브엔진으로 Query Transformer, Estimator, Plan Generator 가 있는데, 이 중 Query Transformer 가 그런 역할을 담당한다.
- 쿼리 변환은 두 가지 방식으로 작동한다.
- 휴리스틱(Heuristic) 쿼리 변환 : 결과 보장된다면 무조건 쿼리 변환을 수행. 일종의 규칙 기반(Rule-based) 최적화 기법.
- 비용기반(Cost-based) 쿼리 변환 : 변환된 쿼리의 비용이 더 낮을 때만 그것을 사용하고, 그렇지 않을 때는 원본 쿼리 그대로 두고 최적화를 수행.
2. 서브쿼리 Unnesting
- 중첩된 서브쿼리 (Nested Subquery) 를 풀어내는 것으로, 메인 쿼리와 같은 레벨로 풀어낸다면 다양한 액세스 경로와 조인 메소드를 평가할 수 있다.
- 조인형태로 변환하면 더 나은 실행계획을 찾을 가능성이 높아진다. (옵티마이저가 조인테크닉을 많이 가지고 있기 때문)
- 예제 쿼리
select * from emp a
where exists (
select 'x' from dept
where deptno = a.deptno
)
and sal >
( select avg(sal) from emp b
where exists (
select 'x' from salgrade
where basal between local and sisal
and grade = 4 )
)
- 위 쿼리를 논리적인 포함관계 상자로 표현하면 아래와 같다.
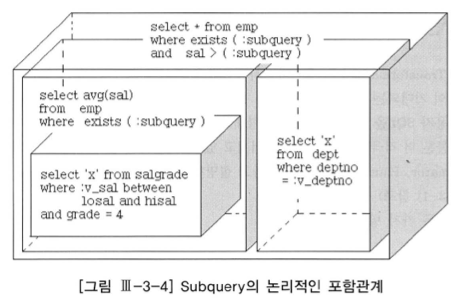
- 중첩된 서브쿼리 (nested subquery) 는 메인쿼리와 부모와 자식이라는 종속적, 계층적 관계가 존재한다.
- 처리과정은 IN, Exists 를 불문하고 필터 방식이어야 한다. ( 메인 쿼리에서 읽히는 레코드마다 서브쿼리를 반복 수행하며 조건에 맞지 않는 데이터를 골라내야 한다. )
- 서브쿼리 처리 시 필터 방식이 항상 최적 수행속도를 보장하는 것은 아니므로 옵티마이저는 아래 둘 중 하나를 선택한다.
- 동일한 결과를 보장하는 조인문으로 변환 후 최적화. 이를 서브쿼리 Unnesting 이라 한다.
- 서브쿼리를 Unnesting 하지 않고 원래대로 둔 상태에서 최적화 한다. 메인쿼리와 서브쿼리를 별도의 서브 플랜(Subplan) 으로 구분해 각각 최적화를 수행하며, 이 때 서브쿼리에 필터(Filter) 오퍼레이션이 나타난다.
- 위 1번의 서브쿼리 Unnesting : 서브쿼리 간의 계층구조를 풀어, 같은 레벨 (Flat한 구조)로 만들어 준다는 의미로 서브쿼리 Flattening 이라고도 부른다.
- 위 2번의 Unnesting 하지 않고 쿼리 블록별 최적화 한다면 각각 최적 쿼리문 전체의 최적을 달성하지 못할 때가 많다. Plan Generator 가 매우 제한적인 범위 내에서 실행계획을 생성한다.
- 서브쿼리 Unnesting 작동 방식
select * from emp
where deptno in ( select deptno from dept)
- Unnesting 하지 않고 최적화 한다면 아래와 같이 필터 방식 실행계획을 수립한다.

- Unnesting 하지 않은 서브쿼리를 수행할 때는 메인쿼리에서 읽히는 레코드마다 값을 넘기면서 서브쿼리를 반복 수행한다. ( 내부적으로 IN 서브쿼리를 Exists 서브쿼리로 변환한다 - Predicate 정보 )
서브쿼리가 Unnesting 되면 변환된 쿼리는 아래와 같은 조인문 형태가 된다.
select *
from ( select deptno from dept ) a , emp b
where b.deptno = a.deptno
- 뷰 Merging 과정을 거치면 아래와 같은 형태가 된다.
select emp.* from dept, emp
where emp.deptno = dept.deptno
- 서브쿼리 Unnesting 된 경우 실행계획이다. 서브쿼리임에도 일반적인 Nested Loop 조인 방식으로 수행된 것을 볼 수 있다.

- 주의 : 서브쿼리 Unnesting 한 결과가 항상 더 나은 성능을 보장 하는 것은 아니다.
최근 옵티마이저는 서브쿼리를 Unnesting 했을 때 쿼리 수행 비용이 더 낮은지 비교하여 적용 여부를 판단한다. - Oracle 은 이러한 경우 사용자가 직접 핸들링 할 수 있도록 힌트를 제공한다.
- unnest : 서브쿼리 Unnesting 하여 조인방식을 최적화하도록 유도.
- no_unnest : 서브쿼리를 그대로 둔 상태로 필터 방식으로 최적화하도록 유도.
- 서브쿼리가 M쪽 집합이거나 Nounique 인덱스일 때
- 위 예제는 메인쿼리의 emp 테이블과 서브쿼리의 dept 테이블이 M:1 관계라 일반 조인문으로 변경하여도 쿼리 결과가 보장된다.
- 만일 서브쿼리 쪽 테이블의 조인 컬럼에 PK/Unique 제약 또는 Unique 인덱스가 없다면, 일반 조인문처럼 하면 어떻게될까 ?
< 사례1 >
select * from dept
where deptno in ( select deptno from emp )
- 1쪽 집합 기준으로 M쪽 집합을 필터링 하는 형태이므로, 서브쿼리쪽 emp 테이블
dept 테이블이 기준 집합이므로 Unique 인덱스가 없다.
dept 테이블이 기준 집합으로, 결과집합은 이 테이블의 총 건수를 넘지 않아야 한다.
옵티마이저가 아래와 같은 일반 조인문으로 변환하면 M쪽 집합인 emp 테이블 단위의 결과집합이 만들어지므로 결과 오류가 생긴다.
- 1쪽 집합 기준으로 M쪽 집합을 필터링 하는 형태이므로, 서브쿼리쪽 emp 테이블
select *
from ( select deptno from emp ) a, dept b
where b.deptno = a.deptno
< 사례2 >
select * from emp
where deptno in ( select deptno from dept )
- 위 쿼리 M쪽 집합을 드라이빙해 1쪽 집합을 서브쿼리로 필터링하도록 작성되어서 조인문으로 변경하더라도 결과 오류는 발생하지 않는다.
- dept 테이블 deptno 컬럼에 PK/Unique 제약이나 Unique 인덱스가 없드면 옵티마이저는 emp 와 sept 간 관계를 알 수 없어서 조인문으로 쿼리 변환을 시도하지 않는다.
- 이럴 경우 옵티마이저는 두 가지 방법 중 하나를 선택하는데, Unnesting 후 어느쪽 집합을 먼저 드라이빙 하느냐에 따라 달라진다.
- 1쪽 집합인지 확신할 수 없는 서브쿼리 쪽 테이블이 드라이빙된다면, 먼저 sort unique 오퍼레이션을 수행하여 1쪽 집합을 만든 후 조인한다.
- 메인 쿼리 쪽 테이블이 드라이빙 된다면 세미조인(Semi Join) 방식으로 조인한다.
- Sort Unique 오퍼레이션 방식
alter table dept drop primary key ;
create index dept_deptno_idx on dept(deptno);
select * from emp
where deptno in ( select deptno from dept ) ;

- dept 테이블은 Unique 한 집합이나, 이를 확신할 수 없어 sort unique 오퍼레이션이 수행되었다.
아래는 동일 형태로 쿼리 변환이 일어난 것이다.
select b.*
from ( select /*+ no_merge */ distinct deptno from dept order by deptno) a, emp b
where b.deptno = a.deptno
- 세미 조인(Semi Join) 방식

- NL 세미조인 수행 시 sort unique 오퍼레이션을 수행하지 않아도 결과집합이 M쪽 집합으로 확장되는 것을 방지하는 알고리즘을 사용한다.
- 기본적으로 NL조인과 동일한 프로세스이나, Outer (=Driving) 테이블의 한 로우가 Inner 테이블의 한 로우와 조인 성공 시 진행을 멈추고 Outer 테이블의 다음 로우를 계속 처리하는 방식이다.
- 아래 pseudo 코드 참고
for (i=0; i++) { // outer loop
for (j=0; j++) { // inner loop
if (i==j) break ;
}
}
h2. 3. 뷰 Merging
< 쿼리1 >
{code:sql}
select *
from ( select * from emp where job ='SALESMAN') a
, ( select * from dept where loc ='CHICAGO' ) b
where a.deptno = b.deptno
< 쿼리2 >
select *
from emp a, dept b
where a.deptno = b.deptno
and a.job ='SALESMAN'
and b.loc ='CHICAGO'
- 사람의 눈으로 보기에는 쿼리1 처럼 인라인 뷰를 사용하면 내용파악이 쉬우나, 옵티마이저 입장에서는 가급적 쿼리2 처럼 블록을 풀어내려는 습성을 갖기는다.
- 그렇기 때문에 쿼리1 의 뷰 쿼리 블록은 액세스 쿼리 블록(뷰 참조하는 쿼리블록) 과의 Merge 과정을 거쳐 쿼리2 형태로 변환되며 이를 뷰 Merging 이라 한다.
create or replace view emp_salesman
as
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where job ='SALESMAN' ;
- 위 emp_salesman 보와 조인하는 조인문 (아래)
select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
from emp_salesman e, dept d
where d.deptno = e.deptno
and e.sal >= 1500 ;
- 뷰 Merging 하지 않고 그대로 최적화 하면 아래와 같은 실행계획이 만들어짐.

- 뷰 Merging 작동하면 변환된 쿼리는 아래와 같은 모습이다.
select e.empno, e.ename, e.job, e.mgr, e.sal, d.dname
from emp e, dept d
where d.deptno = e.deptno
and e.job = 'SALESMAN'
and e.sal >= 1500
- 실행계획 또한 일반 조인문 처리하는 것과 동일한 형태가 된다.


- 단순한 부는 Merging 하여도 성능이 나빠지지 않으나, 복잡한 연산을 포함하는 뷰를 Merging 하면 성능이 나빠질 수 있다.
- group by 절
- select-list 에 distinct 연산자 포함
- 뷰 Merging 여부를 실행계획에서 이를 읽어내는 것이 중요하며, 뷰 Merging 여부에 따른 쿼리 수행비용을 고려하여 튜닝을 시행해야 한다.
- Oracle 힌트로는 merge, no_merge 힌트로 이를 제어한다.
- 집합(set) 연산자(union, union all, intersect, minus)
- connect by 절
- ROWNUM pseudo 컬럼
- select-list 에 집계함수 (avg, count, max, min, sum) 사용
- 분석 함수 (Analytic Function)
4. 조건절 Pushing
- 옵티마이저 뷰 처리에 1차 - 뷰 Merging 을 고려하고
조건절(Predicate) Pusing 을 시도할 수 있다. 이는 뷰를 참조하는 쿼리 블록의 조건절을 뷰 쿼리 블록 안으로 밀어넣는 기능이다. - 조건절이 가능한 빨리 처리되도록 뷰 안으로 밀어넣으면, 뷰 안에서 처리일량 최소화되고, 리턴 결과 건수를 줄여서 다음단계 일량을 줄일 수 있다.
- 조건절(Predicate) Pushdown : 쿼리 블록 밖의 조건절을 쿼리 블록 안으로 밀어 넣는 것
- 조건절(Predicate) Pullup : 쿼리 블록 안의 조건절을 쿼리 블록 밖으로 내오는 것을 말하며, 이를 다시 다른 쿼리 블록에 Pushdown 하는데 사용
- 조인 조건(Join Predicate) Pushdown : NL Join 수행 중 드라이빙 테이블에서 읽은 값을 건건히 Inner 쪽 (=right side) 뷰 쿼리 블록 내로 밀어 넣는 것
가. 조건절(Predicate) Pushdown
- group by 절 포함한 뷰를 처리 시, 쿼리블록 밖의 조건절을 쿼리 블록 안으로 밀어넣으면 group by 할 데이터량을 줄일 수 있다.

- 뷰 내부에는 조건절이 없어서 쿼리 변환 동작하지 않으면 emp 테이블 Full Scan -> Group by 하고 deptno=30 조건으로 필터링 했을 것이다.
- 조건절 Pushing 이 작동하여, EMP_DEPTNO_IDX 인덱스를 사용하였다.
- 조인절로 테스트


- Predicate Information 에서 인라인 뷰에 deptno=30 조건절을 적용하여 데이터량을 줄여 group by 조인연산을 수행함.
- '조건절 이행' 쿼리변환이 먼저 일어나서 인라인뷰에 조건절이 pushdown 되었다.
- b.deptno=30 조건이 조인 조건을 a 쪽에 전이되어 a.deptno=30 조건절이 내부적으로 생성된 것이다.
select b.deptno, b.dname, a.avg_sal
from ( select deptno, avg(sal) avg_sal from emp group by deptno) a
, dept b
where a.deptno = b.deptno
and b.deptno = 30
and a.deptno = 30
나. 조건절(Predicate) Pullup
- 조건을 쿼리블록 밖으로 꺼내는 것으로, 이를 다시 다른 쿼리 블록에 Pushdown 하는데 사용한다.


- 인라인 뷰 e2 에서 deptno=10 조건이 없으나, Predicate Information 을 보면 양쪽 모두 이 조건이 EMP_DEPTNO_IDX 인덱스 액세스 조건으로 사용된 것을 볼 수 있다.
- 아래 형태로 쿼리가 변환된 것이다.

다. 조인 조건(Join Predicate) Pushdown
- 조인 조건절을 뷰 쿼리 블록 안으로 밀어 넣는 것.
- NL Join 수행 중 드라이빙 테이블에서 읽은 조인 컬럼 값을 Inner 쪽 (=right side) 뷰 쿼리 블록 내에서 참조할 수 있게 하는 기능.
- group by 절 포함한 뷰 액세스 단계에서 view pushed predicate 오퍼레이션 (id=3)
아래쪽에 EMP_DEPTNO_IDX 인덱스 사용이 확인되는데, 이는 dept 테이블로부터 넘겨진 deptno 에 대해서만 group by 를 수행함을 의미한다.

- Oracle 11g 에서야 구현되었고 이는 부분범위 처리가 필요한 상황에서 유용하다.
- 10g 이하 버전에서 수행 시 조인조건 Pushdown 동작하지 않아서 emp 쪽 인덱스를 Full Scan 한다.
( deptno 마다 emp 테이블 전체를 group by 하는 것은 성능상 불리하다 )
- 10g 이하여도 스칼라 서브쿼리로 변환하면 부분범위 처리가 가능하다.
select d.deptno, d.dname
, (select avg(sal) from emp where deptno = d.deptno )
from dept d
- 집계함수가 여러개일 경우 emp 에서 같은 범위를 반복적 액세스하여 비효율이 생긴다.

- 이럴 때는 구하고자 하는 값을 모두 결합하고, 바깥쪽 액세스 쿼리에서 substr 함수로 분리한다.

5. 조건절 이행
- 조건절 이행(Transitive Predicate Generation, Transive Closure)
- A=B 이고 B=C 이면 A=C 이다. 라는 추론을 통해 새로운 조건절을 내부적으로 생성해주는 쿼리변환이다.
- A 테이블에 사용된 필터 조건이 조인 조건절을 타고 반대편 B 테이블에 대한 필터 조건으로 이행될 수 있다. 한 테이블 내에서도 두 컬럼간 관계정보를 이용하여 조건절이 이행된다.
select * from dept d, emp e
where e.job = 'MANAGER'
and e.deptno = 10
and d.deptno = e.deptno
- deptno = 10 은 emp 테이블에 대한 필터 조건이다.
아래 실행계획에서 Predicate 정보를 확인하면 dept 테이블에도 동일 필터 조건이 추가된 것을 볼 수 있다.
- e.deptno = 10 이고 e.deptno = d.deptno 이브로 d.deptno = 10 으로 추론되었고, 이 조건절 이행을 통해 쿼리가 아래와 같이 변환되었다.
select * from dept d, emp e
where e.job = 'MANAGER'
and e.deptno = 10
and d.deptno = 10
- 위와 같이 변환 시 Hash 조인 또는 Sort Merge 조인을 수행 전 emp, dept 테이블에 각각 필터링을 적용하여 조인되는 데이터량을 줄일 수 있다.
- dept 테이블 액세스를 위한 인덱스 사용을 추가로 고려할 수 있게 되어 더 좋은 실행계획을 수립할 가능성이 커진다.
6. 불필요한 조인 제거
- 조인 제거(Join Elimination)
- 1:M 관계의 두 테이블을 조인 시 쿼리문에서 조인문을 제외한 어디에서도 1쪽 테이블을 참조하지 않으면,
쿼리 수행 시 결과집합에 영향이 없으므로 1쪽 테이블은 읽지 않아도 된다.
이 특성을 이용해서 M쪽 테이블만 읽도록 쿼리를 변환한다.
- 1:M 관계의 두 테이블을 조인 시 쿼리문에서 조인문을 제외한 어디에서도 1쪽 테이블을 참조하지 않으면,
select e.empnom e.name, e.deptno, e.sal, e.hiredate
from dept d, emp e
where d.deptno = e.deptno

- emp 테이블만 액세스 한 것을 볼 수 있다.
- Oracle 10g 이상부터 적용, SQL Server 는 오래 전부터 적용돼 온 기능.
- 조인 제거 기능 동작을 위해서는 PK, FK제약이 설정되어 있어야 한다.

- FK 설정되어 있어도 emp 테이블의 deptno 컬럼이 Null 허용 컬럼이면 결과가 다르다.
- 조인 컬럼 값이 Null 인 레코드는 조인에 실패해야 하는데, 옵티마이저가 조인문을 함부로 제거하면 이 레코드들이 결과집합에 포함되므로 오류 방지를 위해 옵티마이저가 내부적으로 e.deptno is not null조건을 추가한다.
- Outer 조인일 경우 not null 제약, is not null 조건, FK제약이 없어도 논리적으로 조인 제거가 가능하나 Oracle 10g 까지는 아래와 같이 조인 제거가 일어나지 않음.

- 11g 에서는 불필요한 Inner 쪽 테이블 제거 기능이 구현되었다.

- SQL Server 에서 테스트 시 Inner 쪽 테이블 제거되었다.

7. OR 조건을 Union 으로 변환
select * from emp
where job='CLERK' or deptno = 20
- 위 쿼리는 OR 조건으로 Full Table Scan 처리될 것 이다.
( job 컬럼 인덱스, deptno 컬럼 인덱스가 있을 경우 둘이 결합하고 비트맵 연산을 통해 테이블 액세스 대상을 필터링하는 Index Combine 이 작동할 수 있다.) - job, deptno 에 각각 생성된 인덱스를 사용하고자 한다면 union all 형태로 바꿔준다.
select * from emp
where job='CLERK'
union all
select * from emp
where deptno = 20
and LNNVL(job='CLERK')
- 옵티마이저가 쿼리를 바꿔주는 작업을 'OR-Expansion' 이라 한다.
OR-Expansion 쿼리 변환이 일어났을 때 실행계획과 Predicate 정보이다.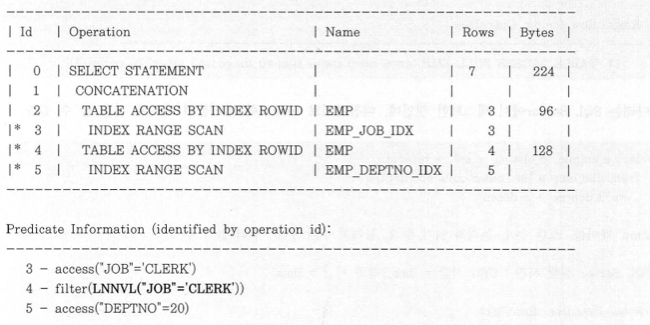
- job, deptno 컬럼을 선두로 갖는 인덱스 사용 (EMP_DEPTNO_IDX)
- union all 위쪽 브랜치는 job='CLERK' 만, 아래쪽은 deptno=20 인 집합만 읽는다.
- 각각 다른 인덱스를 사용하지만 emp 테이블 액세스가 두번 일어난다.
- 중복 액세스 되는 영역 (deptno=20 이면서 job='CLERK') 의 데이터 비중이 작을수록 효과적이다.
- 중복 액세스 되더라도 중복 없애게 하려고 Oracle 이 내부적으로 LNNVL 함수를 사용하였다.
- job <> 'CLERK' 이거나 job is null 인 집합만 읽으려는 것이고 이 함수는 조건식이 false 이거나 알수없는 값일 경우 true 리턴한다.
- Oracle 에서 OR-Expansion 제어를 위해 use_concat, no_expand 를 사용한다.
use_concat : OR-Expansion 유도 / no_expand : OR-Expansion 방지
select /*+ USE_CONCAT */ * from emp
where job = 'CLERK' or deptno = 20 ;
select /*+ NO_EXPAND */ * from
where job ='CLERK' or deptno = 20 ;
8 기타 쿼리 변환
가. 집합 연산을 조인으로 변환
- Intersect 나 Minus 같은 집합 연산을 조인 형태로 변환하는 것.
- deptno = 10 에 속한 사원들의 job, mgr 을 제외하고 나머지 job, mgr 집합을 찾는 쿼리로,
각각 Sort Unique 연산을 수행 후 Minus 연산을 수행하는 것을 볼 수 있다.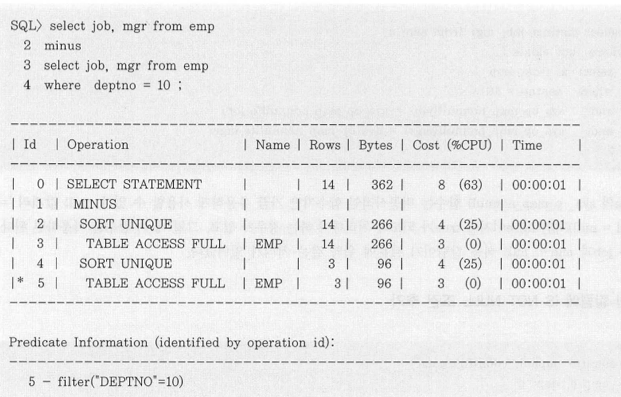
- 아래는 Minus 를 조인 형태로 변환했을 때 실행계획이다.
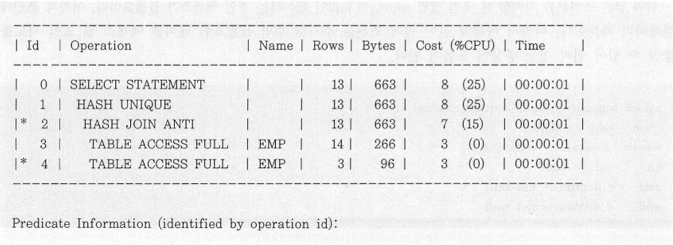

- 해리 Anti 조인 수행 후 중복 값 제거를 위한 Hash Unique 연산을 수행하는 것을 볼 수 있다.
아래 쿼리 형태로 변환이 일어난 것이다.
- Oracle 의 sys_p_map_nonnull 함수는 비공식적 함수. null 값 끼리 = (equal) 비교 (null = null) 하면 false 이나 true 가 되도록 처리해야 하는 경우 이 함수를 사용한다.
- 위 쿼리에서는 job, mgr 이 null 허용컬럼이라 위와 같이 처리되었다.
나. 조인 컬럼에 IS NOT NULL조건 추가
select count(e.empno), count(d.dname)
from emp e, dept d
where d.deptno = e.deptno
and sal <= 2900
- 위 쿼리에서 조인 컬럼 deptno 가 null 인 데이터는 조인 액세스가 불필요하다. ( 조인이 실패하기 때문 )
- 아래와 같이 필터 조건을 주면 불필요한 테이블 액세스 및 조인 시도를 줄일 수 있어 성능 향상에 도움이 된다.
select count(e.empno), count(d.dname)
from emp e, dept d
where d.deptno = e.deptno
and sal <= 2900
and e.deptno is not null
and d.deptno is not null
- is not null 조건은 옵티마이저가 필요하다고 판단되면 ( Oracle 의 경우 null 비중이 5% 이상일 경우) 내부적으로 추가해 준다.
다. 필터 조건 추가
select * from emp
where sal between :mn and :mx
- 위 쿼리에서 바인드 변수로 between검색 쿼리를 수행할 때 사용자가 :mx 보다 :mn 변수에 더 큰 값을 입력하면 쿼리 결과는 공집합이다.
- 쿼리를 수행하면서 공집합을 출력하는 비합리적 수행을 줄이기 위해,
Oracle 9i 부터 옵티마이저가 임의로 필터 조건식을 추가해 준다.
- (아래) :mn 에 5000, :mx 에 100 입력 후 수행 시 블록I/O가 전혀 발생하지 않음.
Table Full Scan 수행 시 필터 처리가 일어나는 것 처럼 보이지만, 실제로는 Table Full Scan 이 생략된 것이다.
라. 조건절 비교 순서

- 위 데이터를 아래 SQL 로 검색 시 B 컬럼에 대한 조건식을 먼저 평가하는 것이 유리하다.
- 대부분 B = 1000 조건 만족하지 않아 A 컬럼 비교연산 수행하지 않아도 된다.
SELECT * FROM T
WHERE A = 1
AND B = 1000 ;
- 반대로 A = 1 조건식 먼저 평가하게 되면, B 컬럼 비교연산까지 수행해야 하므로 CPU 사용량이 늘어난다.
아래와 같은 조건절을 처리할 때도 부등호를 먼저 평가 하느냐, like 조건을 먼저 평가 하느냐에 따라 일량의 차이가 생긴다.
- 최신 옵티마이저는 비교 연산해야할 일량을 고려해 선택도가 낮은 컬럼 조건식부터 처리하도록 내부적으로 순서를 조정한다.