제 3절 동시성 제어
- 동시성 제어(Concurrency Control) : 동시에 작동하는 다중 트랜잭션의 상호 간섭 작용에 대해 데이터베이스를 보호하는 것.
이를 위해 모든 DBMS가 Lock 기능을 제공한다. - 여러 사용자가 데이터를 동시에 액세스 하는 것 처럼 보이나, 내부적으로는 하나씩 실행되도록 트랜잭션을 직렬화 한다.
- set transaction 명령어를 이용해 트랜잭션 격리성 수준을 조정한다.
- SQL Server 는 기본 트랜잭션 격리성 수준인 Read Committed 상태에서는 레코드를 읽고 다음 레코드로 이동하자 마자 공유 Lock 을 해제하나,
Repeatable Read 로 올리면 트랜잭션을 커밋될 때 까지 공유 Lock을 유지한다. - 동시성 제어가 어려운 이유는 동시성(Concurrency) 과 일관성(Consistency)은 Trade-off 관계이기 때문이다.
- 동시성을 높이려고 Lock 사용을 최소화 하면 일관성 유지가 어렵고, 일관성을 높이려고 Lock 을 적극적으로 사용하면 동시성이 저하된다.
- 동시에 실행되는 트랜잭션 수를 최대화 하고 입력, 수정, 삭제, 검색 시 데이터 무결성이 유지되도록 해야 한다.
- set transaction 명령으로 모든 동시성 제어 문제를 해결할 수 없다.
n-Tier 아키텍쳐에서는서로 다른 Connection 을 통해 처리될 수 있기 때문이다. - DB연결에 사용하는 라이브러리나 그리드(Grid) 컴포넌트가 동시성 제어기능도 하지만, 많은 경우 트랜잭션의 동시성을 개발자가 직접 구현해야만 한다.
1. 비관적 동시성 제어 vs. 낙관적 동시성 제어
가. 비관적 동시성 제어
- 사용자들이 같은 데이터를 동시에 수정할 것이라 가정한다.
따라서 데이터를 읽는 시점에 Lock 을 걸고 트랜잭션이 완료될 때 까지 이를 유지한다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적
from 고객
where 고객번호 = :cust_num for update ;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트 where 고객번호 = :cuts_num;
- select 시점에 Lock을 거는 비관적 동시성 제어는 동시성을 심각하게 떨어뜨릴 수 있다.
- 아래와 같이 wait , no wait 옵션을 함께 사용하는 것이 좋다.
for update no wait // 대기없이 Exception 을 던짐
for update wait 3 // 3초 대기 후 Exception 을 던짐 |
- SQL Server 에서도 for update절을 사용하 수 있으나, 커서를 명시적으로 선언할 때만 가능하다.
SQL Server에서는 비관적 동시성 제어를 구현할 때 holdlock 이나 updlock 힌트를 사용하는 것이 편리하다.
나. 낙관적 동시성 제어
- 사용자들이 같은 데이터를 동시에 수정하지 않을 것이라고 가정한다.
따라서 데이터를 읽을 때는 Lock 을 설정하지 않는다. 대신 수정 시점에 다른 사용자에 의해 값이 변경되었는지 반드시 검사해야 한다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적
from 고객
where 고객번호 = :cust_num ;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트
where 고객번호 = :cust_num
and 적립포인트 = :a
and 방문횟수 = :b
and 최근방문일시 = :c
and 구매실적 = :d ;
if sql%rowcount = 0 then
alert ('다른 사용자에 의해 변경되었습니다.');
end if ;
- 최종 변경 일시를 관리하는 컬럼이 있다면 아래와 같이 더 간단하게 구현할 수 있다.
select 적립포인트, 방문횟수, 최근방문일시, 구매실적, 변경일시
into :a, :b, :c, :d, :mod_dt
from 고객
where 고객번호 = :cust_num ;
-- 새로운 적립포인트 계산
update 고객 set 적립포인트 = :적립포인트, 변경일시 = SYSDATE
where 고객번호 = :cuts_num
and 변경일시 = :mod_dt ; // 최종 변경일시가 앞서 읽은 값과 같은지 비교
2. 다중버전 동시성 제어
가. 일반적인 Locking 매커니즘의 문제점
- 동시성 제어의 목표 : 동시 실행 트랜잭션 수를 최대화 하면서 입력, 수정, 삭제, 검색 시 데이터 무결성이 유지되도록 한다.
- 읽기 작업에 공유 Lock 사용하는 Locking 매커니즘에서 읽기/쓰기 작업이 서로 방해를 일으켜 동시성에 문제가 생길 수 있다.
- 데이터 일관성 문제가 생기는 경우, 이를 해결하기 위해 Lock 을 오랫동안 유지하거나 테이블 레벨 Lock 사용해야 하므로 동시성을 더 심각하게 떨어뜨림
- 이런 경우를 예를 들면 아래와 같다.

- 잔고 총합을 구하는 쿼리가 TX1 트랜잭션에서 수행됨
TX1> select sum(잔고) from 계좌 ;
- 이후 계좌이체를 처리하는 TX2 트랜잭션에서 작업 시작
TX2> update 계좌 set 잔고 = 잔고 + 100 where 계좌번호 = 7 ; -- (1)
TX2> update 계좌 set 잔고 = 잔고 - 100 where 계좌번호 = 3 ; -- (2)
TX2> commit;
- TX1 : 2 번 계좌까지 읽는다. 잔고 총합 2,000 원.
- TX2 : (1) 번 update 실행, 7번 계좌 잔고 1,100원. 아직 커밋안됨
- TX1 : 6 번 계좌까지 읽는다. 잔고 총합 5,000 원.
- TX2 : (2) 번 update 실행, 3번 계좌는 900원, 7번 계좌는 1,100인 상태에서 커밋.
- TX1 : 10번 계좌까지 읽는다. 7번 계좌 잔고 1,100원으로 바꾼 TX2 가 커밋되어서 이 값을 읽어 구한 잔고 총합 10,100 원.
- TX2 트랜잭션 실행 직전 잔고 총합은 10,000원. TX2 트랜잭선 완료 후 총합도 10,000 원. 10,100원 결과는 일관성 없이 구해진 값이다.
- 이를 해결하는 방법 : 트랜잭션 격리성 수준을 상향 조정 하는 것이다.
Read Committed 수준에서는 읽는 순간에만 공유 Lock 을 걸고 다음 레코드로 이동 시 Lock 을 해제하기 때문에 이런 현상이 발생한다. - Repeatable Read 로 올리면 TX1 쿼리 진행되는 동안에는 읽은 레코드가 공유 Lock이 계속 유지되고, 쿼리 종료 후 다음 쿼리 진행되는 동안에도 유지된다.
- 트랜잭션 격리성 수준을 상향조정하면 일관성이 높아지지만, Lock 이 더 오래 유지됨으로 인해 동시성 저하되어 교착상태가 발생할 가능성도 커진다.
나. 다중버전 동시성 제어
- Oracle 은 버전 3부터 다중버전 동시성 제어(Multiversion Concurrency Control, 이하 MVCC) 매커니즘을 사용.
- MS SQL Server 도 2005 버전부터, IBM DB2 도 9.7 버전부터 동시성 제어 매커니즘을 제공하기 시작.
{info:title=MVCC 매커니즘} - 데이터 변경 시 마다, 변경사항을 Undo 영역에 저장한다.
- 데이터를 읽다가 쿼리(트랜잭션) 시작 시점 이후에 변경된(변경 진행 중 혹은 이미 커밋된) 값을 발견 시 ,
Undo 영역에 저장된 정보를 이용해 쿼리(트랜잭션) 시작 시점의 일관성 있는 버전 (CR Copy)을 생성하고 그것을 읽는다.
{info} - 변경 진행중인 레코드를 만나도 대기하지 않기 때문에 동시성 측면에서 유리하다.
- 사용자에게 데이터 기준 시점이 쿼리(트랜잭션) 시작 시점으로 고정되어 일관성 측면에서도 유리하다.
- MVCC 에는 Undo 블록 I/O, CR Copy 생성, CR 블록 캐싱 등 부가 작업으로인한 오버헤드 발생 단점이 있다.
- Oracle 은 Undo 데이터를 Undo 세그먼트를 저장, SQL Server 는 tempdb에 저장한다.
- MVCC 를 이용한 읽기 일관성에는 문장수준 , 트랜잭션 수준 2가지가 있다.
다. 문장수준 읽기 일관성
- 다른 트랜잭션에 의해 데이터의 추가, 변경, 삭제가 발생하더라도 단일 SQL문 내에서 일관성 있게 값을 읽는 것을 말한다. 일관성 기준 시점은 쿼리 시작 시점이 된다.
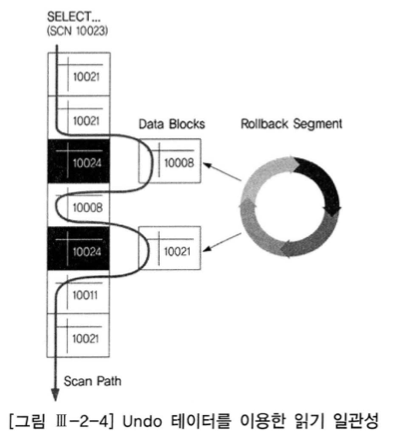
- 10023 시점 시작 쿼리가 10023 시점 이후에 변경된 데이터 블록을 만나면, Rollback Segment(=Undo) 세그먼트에 저장된 정보 이용해
10023 이전 시점으로 되돌려 값을 읽는다. - SQL Server 에서 문장수준 읽기 일관성 모드로 DB 운영 하려면 아래 명령을 수행한다.
| alter database <데이터베이스 이름> set read_committed_snapshot on ; |
라. 트랜잭션 수준 읽기 일관성
- 다른 트랜잭션에 의해 데이터의 추가, 변경, 삭제 발생하더라도 트랜잭션 내에서 일관성 있게 값을 읽는 것.
- 기본 트랜잭션 격리성 수준 (Read Committed) 에서 완벽한 문장수준 읽기 일관성을 보장하는 MVCC 매커니즘도 트랜잭션 수준의 읽기 일관성을 보장하지 않는다.
트랜잭션 수준으로 완벽한 읽기 일관성을 보장 받으려면 Serializable Read 로 격리성 수준을 올려야 한다. - Serializable Read 로 상향조정하면, 일관성 기준 시점은 트랜잭션 시작 시점이 된다. 트랜잭션이 진행되는 동안 자신이 발생시킨 변경사항은 그대로 읽는다.
- SQL Server 에서 트랜잭션 읽기 일관성 모드로 DB운영 시 아래 명령을 수행.
| alter database <데이터베이스 이름> set allow_snapshot_isolation on ; |
- 그리고 트랜잭션 시작 전, 격리성 수준을 snapshot 으로 변경해주면 된다.
set transaction isolation level snapshot
begin tran
select ... ;
update ... ;
commit ;
마. Snapshot too old
- Undo 를 활용하여 높은 수준의 동시성과 읽기 일관성 유지하는 대신, 일반적인 Locking 매커니즘에 없는 Snapshot too old 에러가 MVCC 에서 발생한다.
- Undo 영역에 저장된 Undo 정보가 다른 트랜잭션에 의해 재사용돼 필요한 CR Copy 를 생성할 수 없을 때 발생한다.
- Snapshot too old 에러 발생 가능성을 줄이기 위한 방법은 아래와 같다.
- Undo 영역 크기를 증가시킨다.
- 불필요하게 커밋을 자주 수행하지 않는다.
- fetch across commit 형태의 프로그램 작성을 피해 다른 방식으로 구현한다. ANSI 표준에 따름녀 커밋 이전에 열려있던 커서는 더는 Fetch 하면 안된다.
- 트랜잭션이 몰리는 시간 대에 오래 걸리는 쿼리가 같이 수행되지 않도록 시간조정한다.
- 큰 데이블을 일정 범위로 나누어 읽어 단계적으로 실행할 수 있도록 코딩한다. Snapshot too old 발생 횟수를 줄이고, 문제 발생 시 특정 부분부터 다시 시작할 수 있어 유리하다. (일관성 문제가 없을 때 만 적용한다)
- 오랜 시간에 걸쳐 블록을 여러번 방문하는 Nested Loop 형태 조인문, 인덱스 경유 테이블 액세스 수반하는 프로그램 여부를 체크하고 이를 회피하도록 (조인 메소드 변경, Full table scan 등) 을 찾는다.
- 소트 부하를 감수하더라도 order by 를 강제 삽입하여 소트연산이 발생하도록 한다.
- 대량 업데이트 후 곧바로 테이블, 인덱스 Full Scan 하도록 쿼리를 수행하는 것도 해결 방법이 될 수 있다.
select /*+ full(t) */ count(*) from table_name t
select count(*) from table_name where index_column > 0