Contents
Index Range Scan
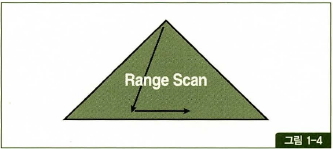
- Index Range Scan 은 인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위만 스캔하는 방식.
SQL> create index emp_deptno_idx on scott.emp(deptno);
Index created.
SQL>
SQL> set autotrace on
SQL> select * from scott.emp where deptno = 20;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ---------- ---------- ---------- ----------
7369 SMITH CLERK 7902 1980-12-17 800 20
7566 JONES MANAGER 7839 1981-04-02 2975 20
7788 SCOTT ANALYST 7566 1987-04-19 3000 20
7876 ADAMS CLERK 7788 1987-05-23 1100 20
7902 FORD ANALYST 7566 1981-12-03 3000 20
Execution Plan
----------------------------------------------------------
Plan hash value: 2468466201
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 435 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 435 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPTNO_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=20)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
17 recursive calls
0 db block gets
29 consistent gets
0 physical reads
0 redo size
1241 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
5 rows processed
Index Full Scan
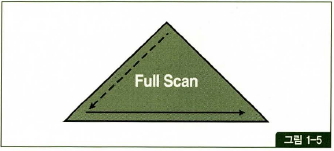
- Index Full Scan 은 수직적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식
- 대게는 데이터 검색을 위한 최적의 인덱스가 없을때 차선으로 선택된다.
SQL> create index emp_idx on scott.emp (ename , sal);
Index created.
SQL>
SQL> select * from scott.emp
2 where sal > 2000
3 order by ename;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ---------- ---------- ---------- ----------
7698 BLAKE MANAGER 7839 1981-05-01 2850 30
7782 CLARK MANAGER 7839 1981-06-09 2450 10
7902 FORD ANALYST 7566 1981-12-03 3000 20
7566 JONES MANAGER 7839 1981-04-02 2975 20
7839 KING PRESIDENT 1981-11-17 5000 10
7788 SCOTT ANALYST 7566 1987-04-19 3000 20
6 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 737262432
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 522 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 6 | 522 | 2 (0)| 00:00:01 |
|* 2 | INDEX FULL SCAN | EMP_IDX | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SAL">2000)
filter("SAL">2000)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
13 recursive calls
0 db block gets
27 consistent gets
0 physical reads
0 redo size
1287 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
6 rows processed
- 인덱스 선두 컬럽이 조건절에 없으면 Table Fulll Scan 을 고려하지만 비용이 크다면 대부분 레코드를 필터링 하고 일부에 대해서만 테이블 액세스가 발생라도록 Index Full Scan 을 한다.
SQL> select * from scott.emp where sal > 5000 order by ename;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 737262432
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 87 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 87 | 2 (0)| 00:00:01 |
|* 2 | INDEX FULL SCAN | EMP_IDX | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SAL">5000)
filter("SAL">5000)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
5 recursive calls
0 db block gets
9 consistent gets
0 physical reads
0 redo size
799 bytes sent via SQL*Net to client
508 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
- Index Full Scan 은 결과집합이 인덱스 컬럼 순으로 정렬 됨으로 Sort Order By 연산을 생략할 목적으로 사용된다.
 ** Sort 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 을 선택.
** Sort 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 을 선택.- 사용자가 데이터 읽기를 멈추지 않고 끝까지 fetch 한다면 Full Table Scan 한것보다 더 많은 I/O를 일으킨다.
Index Unique Scan
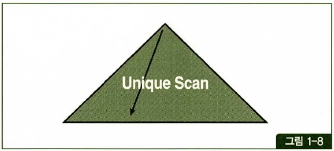
- Index Unique Scan 은 수직적 탐색만으로 데이터를 찾는 스캔 방식.
- Unique Index 가 존재하는 컬럼은 중복 값이 발생하지 않도록 DBMS가 데이터 정합성을 관리해 준다.
따라서 해당 인덱스 키 컬럼을 모두 '=' 조건으로 검색할 때는 데이터를 한 건 찾는순간 더이상 탐색할 필요가 없다.
SQL> select empno, ename from scott.emp where empno = 7788;
EMPNO ENAME
---------- ----------
7788 SCOTT
Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 20 | 2 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7788)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
597 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
- Unique Index 라도 범위검색 조건으로 검색할 때는 Index Range Scan 으로 처리된다.
Index Skip Scan
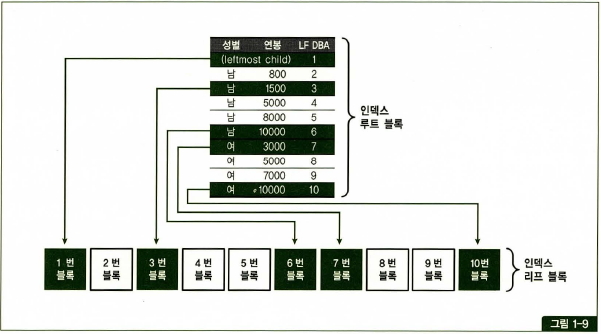
- Index Skip Scan 은 선두 컬럼이 조건절에 빠졌어도 인덱스를 활용하는 새로운 스캔방식
Root 또는 Brench 블록에서 읽은 컬럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 가능성이 있는 리프 블록만 골라서 액세스 하는 방식- 첫번째 리프 블록과 마지막 리프 블록을 항상 방문한다.
- 후미 컬럼이 조건절에 들어가야함.
- 리프 블록에 있는 정보만으로 다음에 방문해야 할 블록을 찾는 방법은 없다. 항상 그 위쪽에 있는 브랜치 블록을 재방문 해서 다음 방문할 리프 블록에 대한 정보를 얻는다.
- Buffer Pinning 방식을 이용해 Branch 버퍼를 Pinning 한 채로 리프 블록을 방문했다 다시 Branch 블록을 찾는 과정으로 Branch 블록을 재방문 한다.
- 쿼리 작성자가 조건식을 직접 추가해 주면 Index Skip Scan 을 이용하지 않아도 Range Scan 으로 빠르게 결과 집합을 보장할수 있다.
- 단 명시된 값의 종류가 더이상 늘지 않아야 한다.
Index Fast Full Scan
- Index Fast Full Scan 은 Index Full Scan 보다 빠르다. 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문.
Index Range Scan Descending
- Index Range Scan 과 동일한 스캔 방식이나 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는다.
And-Equal, Index Combine, Index Join
And-Equal, Index Combine, Index Join : 두 개 이상 인덱스를 함께 사용할 수 있는 방법
- And-Equal
- 8i도입되어 10g 부터 폐기 됨
- 인덱스 스캔량이 아무리 많더라도 두 인덱스를 결합하고 나서의 테이블 액세스량이 소량일 때 효과 있음
- 조건 : 단일 컬럼의 non-unique index & 인덱스 컬럼에 대한 조건절이 "="이어야 함
- Test
set autotrace traceonly explain
select /*+ and_equal(e emp_deptno_idx emp_job_idx) */ * from emp e where deptno=30 and job='SALESMAN';
Execution Plan
----------------------------------------------------------
Plan hash value: 2839249562
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 32 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 32 | 3 (0)| 00:00:01 |
| 2 | AND-EQUAL | | | | | |
|* 3 | INDEX RANGE SCAN | EMP_JOB_IDX | 3 | | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_DEPTNO_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("JOB"='SALESMAN' AND "DEPTNO"=30)
3 - access("JOB"='SALESMAN')
4 - access("DEPTNO"=30)
- Index Combine : 비트맵 인덱스 이용
- 목적 : 데이터 분포도가 좋지 않은 두 개 이상의 인덱스를 결합해 테이블 random 액세스량 줄이기
- 조건절이 "='일 필요가 없고, non-unique index일 필요가 없음
- "_b_tree_bitmap_plans=true"일 때만 작동. 9i 이후는 true가 기본값임
- Test
set autotrace traceonly explain
select /*+ index_combine(e emp_deptno_idx emp_job_idx) */ * from emp e where deptno=30 and job='SALESMAN';
Execution Plan
----------------------------------------------------------
Plan hash value: 2413831903
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 32 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 32 | 4 (0)| 00:00:01 |
| 2 | BITMAP CONVERSION TO ROWIDS | | | | | |
| 3 | BITMAP AND | | | | | |
| 4 | BITMAP CONVERSION FROM ROWIDS| | | | | |
|* 5 | INDEX RANGE SCAN | EMP_JOB_IDX | | | 1 (0)| 00:00:01 |
| 6 | BITMAP CONVERSION FROM ROWIDS| | | | | |
|* 7 | INDEX RANGE SCAN | EMP_DEPTNO_IDX | | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("JOB"='SALESMAN')
7 - access("DEPTNO"=30)
1단계 : 일반 B*Tree 인덱스를 스캔하면서 각 조건에 만족하는 레코드의 rowid 목록 얻기(INDEX RANGE SCAN)
2단계 : 1단계에서 얻은 rowid목록을 가지고 비트맵 인덱스 구조 만들기(BITMAP CONVERSION FROM ROWIDS)
3단계 : 비트맵 인덱스에 대한 bit-wise operation 수행(BITMAP AND)
4단계 : bit-wise operation 수행 결과가 true인 비트 값들을 rowid 값으로 환산해 최종적으로 방문할 테이블 rowid 목록 얻기(BITMAP CONVERSION TO ROWIDS)
5단계 : rowid를 이용해 테이블 액세스(TABLE ACCESS BY INDEX ROWID)
- Index Join
- 한 테이블에 속한 여러 인덱스를 이용해 테이블 액세스 없이 결과집합을 만들 때 사용하는 인덱스 스캔 방식
- Hash join 매카니즘 사용
- 쿼리에 사용된 컬럼들이 인덱스에 모두 포함될 때만 작동(둘 중 어느 한쪽에 포함 되기만 하면 됨)
- Test
set autotrace traceonly explain
select /*+ index_join(e emp_deptno_idx emp_job_idx) */ * from emp e where deptno=30 and job='SALESMAN';
Execution Plan
----------------------------------------------------------
Plan hash value: 2211876416
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 32 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 32 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_JOB_IDX | 3 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPTNO"=30)
2 - access("JOB"='SALESMAN')
set autotrace traceonly explain
select /*+ index_join(e emp_deptno_idx emp_job_idx) */ deptno,job from emp e where deptno=30 and job='SALESMAN';
Execution Plan
----------------------------------------------------------
Plan hash value: 3557895725
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 3 (34)| 00:00:01 |
|* 1 | VIEW | index$_join$_001 | 1 | 9 | 3 (34)| 00:00:01 |
|* 2 | HASH JOIN | | | | | |
|* 3 | INDEX RANGE SCAN| EMP_JOB_IDX | 1 | 9 | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN| EMP_DEPTNO_IDX | 1 | 9 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("JOB"='SALESMAN' AND "DEPTNO"=30)
2 - access(ROWID=ROWID)
3 - access("JOB"='SALESMAN')
4 - access("DEPTNO"=30)
1단계 : 크기가 비교적 작은 쪽 인덱스(emp_job_idx)에서 키 값과 rowid를 얻어 PGA 메모리에 해시 맵 생성
(해시 키 = rowid 가 사용)
2단계 : 다른 쪽 인덱스(emp_dept_idx)를 스캔하면서 먼저 생성한 해시 맵에 같은 rowid 값을 갖는 레코드가 있는지 탐색
3단계 : rowid끼리 조인에 성공한 레코드만 결과집합에 포함 : 이 rowid가 가리키는 테이블은 각 인덱스 컬럼에 대한 검색 조건을 모두 만족한다