인덱스를 이용한 소트 연산 대체
- 인덱스는 항상 키 컬럼 순으로 정렬된 상태 유지 : sort 연산 생략 가능
PK 컬럼에 distinct 쿼리 수행
- 특징 : sort unique 명령 생략 = sort unique nosort
- sort 수행 없이 인덱스를 이용해 unique한 집합 출력
SQL> SELECT DISTINCT empno FROM emp;
Execution Plan
----------------------------------------------------------
Plan hash value: 179099197
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> SELECT DISTINCT empno FROM emp ORDER BY empno;
Execution Plan
----------------------------------------------------------
Plan hash value: 179099197
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> CREATE TABLE emp1 AS SELECT * FROM emp;
테이블이 생성되었습니다.
SQL> CREATE INDEX idx_emp1 ON emp1(empno);
인덱스가 생성되었습니다.
SQL> SELECT DISTINCT empno FROM emp1;
Execution Plan
----------------------------------------------------------
Plan hash value: 3282348538
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 182 | 4 (25)| 00:00:01 |
| 1 | HASH UNIQUE | | 14 | 182 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP1 | 14 | 182 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT DISTINCT empno FROM emp1 ORDER BY empno;
Execution Plan
----------------------------------------------------------
Plan hash value: 2849225206
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 182 | 5 (40)| 00:00:01 |
| 1 | SORT UNIQUE | | 14 | 182 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP1 | 14 | 182 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
- sort order by 대체
- 특징 : 정렬해야 할 대상 레코드는 무수히 많고, 그 중 일부만 읽고 멈출 수 있는 업무에서만 유리
인덱스를 스캔하면서 결과집합을 끝까지 fetch한다면 오히려 I/O 및 리소스 사용 측면에서 손해.
대상 레코드가 소량일 때는 정렬이 발생하더라도 부하가 크지 않아 개선 효과도 미미함
SQL> CREATE TABLE customer
2 AS
3 SELECT LEVEL custid
4 , CHR(64 + CEIL(LEVEL / 100)) region
5 , dbms_random.string('U', 4) name
6 , ROUND(dbms_random.value(10, 70)) age
7 FROM dual
8 CONNECT BY LEVEL <= 1000
9 ;
테이블이 생성되었습니다.
SQL> CREATE INDEX customer_x01 ON customer(region);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM customer
3 WHERE region = 'A'
4 ORDER BY custid
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3806818772
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 198K| 3 (34)| 00:00:01
| 1 | SORT ORDER BY | | 100 | 198K| 3 (34)| 00:00:01
| 2 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 100 | 198K| 2 (0)| 00:00:01
|* 3 | INDEX RANGE SCAN | CUSTOMER_X01 | 100 | | 1 (0)| 00:00:01
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("REGION"='A')
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> CREATE INDEX customer_x02 ON customer(region, custid);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM customer
3 WHERE region = 'A'
4 ORDER BY custid
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 2477059019
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 198K| 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 100 | 198K| 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | CUSTOMER_X02 | 100 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("REGION"='A')
Note
-----
- dynamic sampling used for this statement (level=2)
SQL>
- sort group by 대체
- 특징 : sort group by nosort
인덱스를 이용한 nosort 방식으로 수행될 때는 group by 명령에도 불구하고 부분범위 처리가 가능해져 성능 개선 가능
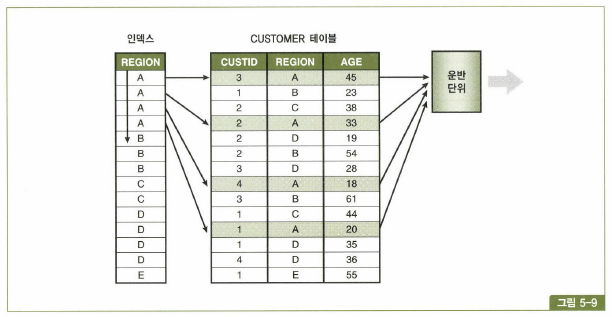
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 GROUP BY region
6 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3656427734
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | HASH GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 GROUP BY region
6 ORDER BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3481805491
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | SORT GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3656427734
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | HASH GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ORDER BY region
8 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3481805491
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | SORT GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT /*+ first_rows(10) */ region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 89828339
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 3 (0)| 00:00:01 |
| 1 | SORT GROUP BY NOSORT | | 1000 | 16000 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
|* 3 | INDEX FULL SCAN | CUSTOMER_X02 | 1 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
- 인덱스가 Sort 연산을 대체하지 못하는 경우
- 옵티마이져모드가 all_rows 인 경우 풀스캔 가능성이 더 커진다. 풀스캔시 Sort 연산 수행
- 옵티마이져모드가 first_rows 인 경우 인덱스스캔 가능성이 더 커진다. 인덱스 스캔시 Sort 연산 대체
- 인덱스 항목이 NOT NULL 이 아닌 경우 : 인덱스만으로 모든 행을 가져오지 못하므로 인덱스 못탐(널 행 제외)
- 결합인덱스의 경우엔 널값도 저장된다(순서상 맨 아래쪽에 저장) 따라서 다음의 경우 Sort 연산 대체 안됨
- ORDER BY 컬럼 NULLS FIRST
- ORDER BY 컬럼 DESC NULLS LAST
SQL> CREATE INDEX emp_deptno_ename_idx ON emp(deptno, ename);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3268462453
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename NULLS FIRST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 4293037890
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 5 | 190 | 3 (34)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename NULLS LAST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3268462453
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename DESC
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3122309019
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename DESC NULLS LAST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 4293037890
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 5 | 190 | 3 (34)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPTNO"=30)