8. 고급 조인 테크닉 (by sunshiny) [2012.10.20]
(1) 누적 매출 구하기
create table month_sales
as
select deptno as "지점"
, row_number() over (partition by deptno order by empno) as "판매월"
, round(dbms_random.value(500, 1000)) as "매출"
from emp
order by deptno
;
-- 테이블 조회
select *
from month_sales
;
지점 판매월 매출
---------- ---------- ----------
10 1 895
10 2 560
10 3 551
20 1 948
20 2 992
20 3 852
20 4 950
20 5 836
30 1 871
30 2 681
30 3 993
30 4 518
30 5 551
30 6 846
오라클 8i부터 제공되기 시작한 분석함수(Analytic Function)를 이용하면 아래와 같이 간단하게 각 지점별로 판매월과 함께 증가하는 누적매출(running total) 결과를 얻을 수 있다.
select "지점", "판매월", "매출"
, sum("매출") over (partition by "지점" order by "판매월"
range between unbounded preceding and current row
) as "누적매출"
5 from month_sales
6 ;
지점 판매월 매출 누적매출
---------- ---------- ---------- ----------
10 1 895 895
10 2 560 1455
10 3 551 2006
20 1 948 948
20 2 992 1940
20 3 852 2792
20 4 950 3742
20 5 836 4578
30 1 871 871
30 2 681 1552
30 3 993 2545
30 4 518 3063
30 5 551 3614
30 6 846 4460
아래는 부등호 조인을 통해 지점별 누적매출을 구하는 방법을 예시
select t1."지점", t1."판매월", min(t1."매출") as 매출, sum(t2."매출") as 누적매출
from month_sales t1, month_sales t2
where t2."지점" = t1."지점"
and t2."판매월" <= t1.판매월
group by t1."지점", t1."판매월"
order by t1."지점", t1."판매월"
;
지점 판매월 매출 누적매출
---------- ---------- ---------- ----------
10 1 895 895
10 2 560 1455
10 3 551 2006
20 1 948 948
20 2 992 1940
20 3 852 2792
20 4 950 3742
20 5 836 4578
30 1 871 871
30 2 681 1552
30 3 993 2545
30 4 518 3063
30 5 551 3614
30 6 846 4460
(2) 선분이력 끊기
선분이력 레코드를 가공해야 할 때가 있는데, 월말 기준으로 선분을 끊는 경우를 살펴보자.
본론으로 들어가기에 앞서, 두 선분이 겹치는 구간에 대한 시작일자 및 종료일자 선택 규칙에 대해 살펴보자.
시간을 나타내는 두 개의 선분이 서로 겹치는 모습을 표현하면, 아래의 그림 (a),(b),©,(d)처럼 네 가지 패턴이 있다.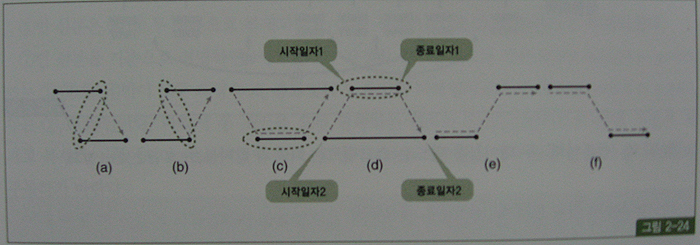
'월도'와 '선분이력' 테이블 생성
create table 월도(기준월, 시작일자, 종료일자)
as
select '200906', '20090601', '20090630' from dual union all
select '200907', '20090701', '20090731' from dual union all
select '200908', '20090801', '20090831' from dual union all
select '200909', '20090901', '20090930' from dual union all
select '200910', '20091001', '20091030' from dual
;
create table 선분이력 (상품번호, 시작일자, 종료일자, 데이터)
as
select 'a', '20090713', '20090808', 'a1' from dual union all
select 'a', '20090809', '20090820', 'a2' from dual union all
select 'a', '20090821', '20091007', 'a3' from dual
;
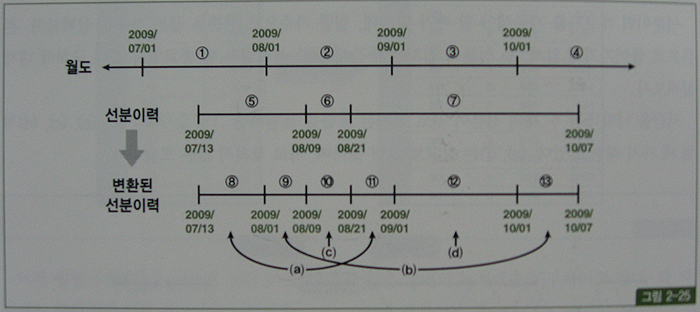
select a.기준월, b.시작일자, b.종료일자, b.상품번호, b.데이터
from 월도 a, 선분이력 b
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
order by a.기준월, b.시작일자
;
기준월 시작일자 종료일자 상품번호 데이터
------------ ---------------- --------- --------- ----
200907 20090713 20090808 A A1 ----- 5 -> 8
200908 20090713 20090808 A A1 ----- 5 -> 9
200908 20090809 20090820 A A2 ----- 6 -> 10
200908 20090821 20091007 A A3 ----- 7 -> 11
200909 20090821 20091007 A A3 ----- 7 -> 12
200910 20090821 20091007 A A3 ----- 7 -> 13
5번 선분은 8,9 두 선분으로 복제되었고, 7번 선분은 11,12,13 세 선분으로 복제되었다.
7번 선분을 기준으로 설명하면, 시작일자가 자신의 종료일자보다 작은 월도(b.종료일자 >= a.시작일자)는 1,2,3,4번이 모두 해당되고, 종료일자가 자신의 시작일자보다 큰 월도(b.시작일자 <= a.종료일자)는 2,3,4번이다.
따라서 두 조건을 모두 만족하는 월도는 2,3,4번이므로 7번 선분은 세개로 복제가 이루어진다.
선분이력이 여러 개 생기더라도 기준월은 각각 다른 값을 가진다는 점에 주목하기 바란다.
여섯 개 선분의 시작일자와 종료일자를 구하는 것이 숙제인데, 이를 위해 8~13번 선분을 그림 2-24에 예시한 스타일로 분류하면 다음과 같다.
- 변환된 8번과 11번 선분은 스타일 (a)에 속한다.
- 변환된 9번과 13번 선분은 스타일 (b)에 속한다.
- 변환된 10번 선분은 스타일 ©에 속한다.
- 변환된 12번 선분은 스타일 (d)에 속한다.
(a), (b), ©, (d) 스타일별로 특징을 정리했던 표를 이용하면 조금 전 쿼리에서 얻은 여섯 개 선분의 시작일자와 종료일자를 쉽게 구할 수 있다.
아래 쿼리의 수행 결과를 보면, 그림 2-25 하단에 있는 '변환된 선분이력'과 똑같은 결과집합인 것을 알 수 있다.
SELECT 상품번호
,case when lst = 시작일자1 and gst = 종료일자2 then 시작일자2 -- 스타일a
when lst = 시작일자2 and gst = 종료일자1 then 시작일자1 -- 스타일b
when lst = 시작일자1 and gst = 종료일자1 then 시작일자2 -- 스타일c
when lst = 시작일자2 and gst = 종료일자2 then 시작일자2 -- 스타일d
end 시작일자
,case when lst = 시작일자1 and gst = 종료일자2 then 종료일자2 -- 스타일a
when lst = 시작일자2 and gst = 종료일자1 then 종료일자1 -- 스타일b
when lst = 시작일자1 and gst = 종료일자1 then 종료일자2 -- 스타일c
when lst = 시작일자2 and gst = 종료일자2 then 종료일자2 -- 스타일d
end 종료일자
,데이터
FROM (
SELECT b.상품번호,b.데이터,a.기준월
,a.시작일자 시작일자1,b.시작일자 시작일자2
,a.종료일자 종료일자1,b.종료일자 종료일자2
,least(a.시작일자,a.종료일자,b.시작일자,b.종료일자) lst
,greatest(a.시작일자,a.종료일자,b.시작일자,b.종료일자) gst
FROM 월도 a, 선분이력 b
WHERE b.시작일자 <= a.종료일자
AND b.종료일자 >= a.시작일자
)
;
상품번호 시작일자 종료일자 데이터
--------- ---------- -------------- ----------
A 2009/07/13 2009/07/31 A1
A 2009/08/01 2009/08/08 A1
A 2009/08/09 2009/08/20 A2
A 2009/08/21 2009/08/31 A3
A 2009/09/01 2009/09/30 A3
A 2009/10/01 2009/10/07 A3
(3) 데이터 복제를 통한 소계 구하기
쿼리를 작성하다 보면 데이터 복제 기법을 활용해야 할 때가 많다. 데이터복제를 위해 일부러 카티션 곱(Cartesian Product)을 발생시켜 복제하기도 한다.
전통적으로 많이 쓰던 방식은 복제용 테이블(copy_t)을 미리 만들어두고 이를 활용하는 것이다.
SQL>create table copy_t (no number, no2 varchar2(2));
Table created.
SQL>insert into copy_t
2 select rownum, lpad(rownum,2,'0') from all_tables where rownum<=31;
31 rows created.
SQL>commit;
Commit complete.
SQL>alter table copy_t add constraint copy_t_pk primary key(no);
Table altered.
SQL>create unique index copy_t_no2_idx on copy_t(no2);
Index created.
-- 아래 쿼리를 실행하면 emp 테이블에 있는 14개의 레코드가 3개씩 총 42개로 복제된다.
SQL>select *
2 from emp a, copy_t b
3 where b.no<=3
4 ;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO NO NO
---------- ---------- --------- ---------- ------------ ---------- ---------- ---------- ---------- --
7369 SMITH CLERK 7902 17-DEC-80 800 20 1 01
7369 SMITH CLERK 7902 17-DEC-80 800 20 2 02
7369 SMITH CLERK 7902 17-DEC-80 800 20 3 03
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30 1 01
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30 2 02
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30 3 03
.
.
.
42 rows selected.
-- 오라클 9i부터는 dual테이블에 start with절 없이 connect by 구문을 사용하면 두 개의 집합이 자동으로 만들어진다.
SQL>select rownum from dual connect by level <= 2;
ROWNUM
----------
1
2
-- 이 방법을 사용해 emp 테이블을 복제하는 방법은 아래와 같다.
SQL>select *
2 from emp a,
3 (select rownum from dual connect by level <= 2) b
4 order by empno
5 ;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ROWNUM
---------- ---------- --------- ---------- ------------ ---------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20 1
7369 SMITH CLERK 7902 17-DEC-80 800 20 2
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30 2
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30 1
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30 1
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30 2
.
.
.
28 rows selected.
데이터 복제 기법을 활용하면 아래와 같이 단일 SQL로도 부서별 소계를 구할 수 있다.
SQL>break on 부서번호
SQL>column 부서번호 format 9999
SQL>column 사원번호 format a10
SQL>select deptno 부서번호
2 , decode(no, 1, to_char(empno), 2, '부서계') 사원번호
3 , sum(sal) 급여합, round(avg(sal)) 급여평균
4 from emp a, (select rownum no from dual connect by level <= 2)
5 group by deptno, no, decode(no, 1, to_char(empno), 2, '부서계')
6 order by 1, 2;
부서번호 사원번호 급여합 급여평균
-------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
17 rows selected.
이처럼 group by를 잘 구사하면 우리가 원하는 데이터 집합을 자유자재로 가공해 낼 수 있다.
아래는 세 개로 복제하고서 총계까지 구하는 사례다.
SQL>column 부서번호 format a10
SQL>select decode(no, 3, null, to_char(deptno)) 부서번호
2 , decode(no, 1, to_char(empno), 2, '부서계', 3, '총계') 사원번호
3 , sum(sal) 급여합, round(avg(sal)) 급여평균
4 from emp a, (select rownum no from dual connect by level <= 3)
5 group by decode(no, 3, null, to_char(deptno))
6 , no, decode(no, 1, to_char(empno), 2, '부서계', 3, '총계')
7 order by 1, 2;
부서번호 사원번호 급여합 급여평균
---------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
총계 29025 2073
18 rows selected.
표준 rollup 구문을 사용하면 데이터 복제 기법을 쓰지 않고도 아래와 같이 간편하게 소계및 총계를 구할 수 있다.
SQL>break on 부서번호
SQL>column 부서번호 format 9999
SQL>column 사원번호 format a10
SQL>select deptno 부서번호
2 , case when grouping(empno) = 1 and grouping(deptno) = 1 then '총계'
3 when grouping(empno) = 1 then '부서계'
4 else to_char(empno) end 사원번호
5 , sum(sal) 급여합, round(avg(sal)) 급여평균
6 from emp
7 group by rollup(deptno, empno)
8 order by 1, 2;
부서번호 사원번호 급여합 급여평균
-------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
총계 29025 2073
18 rows selected.
(4) 상호배타적 관계의 조인
상호배타적 관계 : 어떤 엔터티가 두 개 이상의 다른 엔터티의 합집합과 관계를 갖는 것
ERD에 아래처럼 아크(Arc) 관계로 표시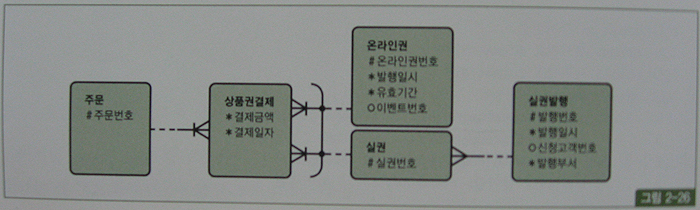
실제 데이터베이스로 구현할때, 상품권결제 테이블은 아래 두가지 방법으로 구축한다.
1. 온라인권번호, 실권번호 두 컬럼을 따로 두고, 레코드별로 둘 중 하나의 컬럼에만 값을 입력한다. Outer 조인 이용
SELECT /*+ ordered use_nl(b) use_nl(c) use_nl(c) use_nl(d) */
a.주문번호, a.결제일자, a.결제금액
, NVL(b.온라인권번호, c.실권번호) 상품권번호
, NVL(b.발행일시, d.발행일시) 발행일시
FROM 상품권결제 a, 온라인권 b, 실권 c, 실권발행 d
WHERE a.결제일자 BETWEEN :dt1 AND :dt2
AND b.온라인권번호(+) = a.온라인권번호
AND c.실권번호(+) = a.실권번호
AND d.발행번호(+) = c.발행번호;
2. 상품권구분과 상품권번호 컬럼을 두고, 상품권구분이 1일때는 온라인권번호를 입력하고 2일 때는 실권번호를 입력한다. Union all 이용
SELECT x.주문번호, x.결제일자, x.결제금액, y.온라인권번호 상품권번호, y.발행일시, ...
FROM 상품권결제 x, 온라인권 y
WHERE x.상품권구분 = '1'
AND x.결제일자 BETWEEN :dt1 AND :dt2
AND y.온라인권번호(+) = x.상품권번호
UNION ALL
SELECT x.주문번호, x.결제일자, x.결제금액, y.실권번호 상품권번호, z.발행일시, ...
FROM 상품권결제 x, 실권 y, 실권발행 z
WHERE x.상품권구분 = '2'
AND x.결제일자 BETWEEN :dt1 AND :dt2
AND y.실권번호(+) = x.상품권번호
AND z.발행번호(+) = y.발행번호;
* 쿼리를 위아래 두번 수행하지만, 인덱스구성에 따라 처리 범위는 달라진다.
1. (상품권구분 + 결제일자) : 읽는 범위 중복 없음
2. (결제일자 + 상품권구분) : 인덱스 스캔범위에 중복 발생
3. (결제일자) : 상품권구분을 필터링하기 위한 테이블 Random 액세스까지 중복 발생
3. 중복 액세스에 의한 비효율 제거
SELECT /*+ ordered use_nl(b) use_nl(c) use_nl(c) use_nl(d) */
a.주문번호, a.결제일자, a.결제금액
, NVL(b.온라인권번호, c.실권번호) 상품권번호
, NVL(b.발행일시, d.발행일시) 발행일시
FROM 상품권결제 a, 온라인권 b, 실권 c, 실권발행 d
WHERE a.결제일자 BETWEEN :dt1 AND :dt2
AND b.온라인권번호(+) = DECODE(a.상품권구분, '1', a.상품권번호)
AND c.실권번호(+) = DECODE(a.상품권구분, '2', a.상품권번호)
AND d.발행번호(+) = c.발행번호;
(5) 최종 출력 건에 대해서만 조인하기
화면 페이지 처리시 흔히 사용되는 방식이다.
SELECT *
FROM (
SELECT ROWNUM NO, 등록일자, 번호, 제목
, 회원명, 게시판유형명, 질문유형명, COUNT(*) OVER() CNT
FROM(
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
FROM 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
)
WHERE ROWNUM <= 31
)
WHERE NO BETWEEN 21 AND 30
전체 게시판 데이터는 수백만 건이고, 특정 게시판 유형(게시판유형 = :TYPE)에 속하는 데이터는 평균 10만 건에 이른다.
게다가 회원, 게시판유형, 질문유형 3개 테이블과 조인까지 수행하므로 성능이 좋을리 없다.
인덱스 구성은 아래와 같아서 소트 오퍼레이션이 불가피하다.
>> 게시판_X01 : 게시판유형 + 등록일자 DESC + 번호
실행계획을 보면(교재참고 p.313), 10만 건을 읽어 나머지 세 테이블과의 조인을 모두 완료한 후에 소트 단계에서 stopkey가 작동(id=5)하고 있다.
Execution Plan
--------------------------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 VIEW
2 1 WINDOW (BUFFER)
3 2 COUNT (STOPKEY)
4 3 VIEW
5 4 SORT (ORDER BY STOPKEY)
6 5 NESTED LOOPS
7 6 NESTED LOOPS
8 7 NESTED LOOPS
9 8 TABLE ACCESS (BY LOCAL INDEX ROWID) OF '게시판' (TABLE)
10 9 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
11 10 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 7 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 6 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
튜닝을 위해 게시판_X01 인덱스에 질문유형 컬럼을 추가하자.
인덱스 컬럼 순서를 바꾸는 결정을 하기는 쉽지 않지만 뒤쪽에 추가하는 것은 그다지 어렵지 않다.
>> 게시판_X01 : 게시판유형 + 등록일자 DESC + 번호 + 질문유형
위처럼 인덱스를 구성했다면 게시판 테이블로부터 '게시판유형 = :TYPE' 조건에 해당하는 레코드를 찾는 작업은 인덱스 내에서 해결 가능하다.
아래처럼 인덱스만 읽도록 쿼리를 작성
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
읽은 레코드를 정렬하는 작업은 피할 수 없지만, 인덱스 블록만 읽으면 되기 때문에 이전보다 훨씬 빠르게 수행될 것이다.
다른 세 개 테이블과의 조인 컬럼, 그리고 select-list에서 참조되는 컬럼을 어떻게 읽어올 것인지가 문제인데, 이들 컬럼은 페이지 처리가 모두 완료되 최종 결과집합으로 확정된 10건에 대해서만 액세스하면 된다.
그럴 목적으로 인덱스를 스캔할 때 rowid 값을 같이 읽어온 것이다. 최종적으로 완성된 쿼리는 아래와 같다.
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) ROWID(A) */
A.등록일자, B.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, X.CNT
FROM (
SELECT RID, ROWNUM NO, COUNT(*) OVER() CNT
FROM (
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
)
WHERE ROWNUM <= 31
) X, 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
Execution Plan
---------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 NESTED LOOPS
2 1 NESTED LOOPS
3 2 NESTED LOOPS
4 3 NESTED LOOPS
5 4 VIEW
6 5 COUNT (STOPKEY)
7 6 VIEW
8 7 SORT (ORDER BY STOPKEY)
9 8 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
10 4 TABLE ACCESS (BY USER ROWID) OF '게시판' (TABLE) -- BY USER ROWID
11 3 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 2 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 1 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
게시판 테이블을 두 번 읽도록 쿼리를 작성했지만 인라인 뷰 내에서는 인덱스만 읽도록 했고, 두 번째 게시판 테이블(A)을 액세스할 때는 앞서 읽은 rowid 값으로 직접 액세스하기 때문에 인덱스를 경유해 한 번만 테이블을 액세스하는 것과 같은 일량이다.
실행계획에 'TABLE ACCESS BY INDEX ROWID'가 아니라 'TABLE ACCESS BY USER ROWID'로 표시된 것에 주목하자.
조인 컬럼이 null 허용일때는 결과가 달라질 수 있다.
회원, 게시판유형, 질문유형 테이블과의 조인 컬럼인 작성자번호, 게시판유형, 질문유형이 null 허용 컬럼이 존재하는지 확인해 봐야 한다.
업무적으로 null 값이 허용되지 않는데도 컬럼에 not null 제약을 설정하지 않는 경우가 매우 흔하기 때문이다.
그리고, 이들 컬럼이 null 값이라고 해서 게시판 출력 리스트에서 제외되는 것이 업무적으로 맞는지 확인해 볼 필요가 있다.
아마도 Outer 조인을 했어야 옳은데, 개발자가 간과한 경우일 수 있다.
위 쿼리에 아래처럼 Outer 기호( + )만 붙여주면 된다.
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호(+) = A.작성자번호
AND C.게시판유형(+) = A.게시판유형
AND D.질문유형(+) = A.질문유형
반정규화는 성능을 위한 최후의 수단
정규화된 모델로는 제대로된 성능을 내기 어려울 때만 반정규화를 단행하는 것이 관계형 데이터베이스를 구현하는 정석이다.
그럼에도 성능이 좋지 않을 것을 예단하고 논리 데이터 모델링 단계에서 미리 반정규화를 실시하는 설계자나 개발팀을 자주 본다.
예를 들어, page. 317의 그림 2-27과 같은 업무연락 메시지 게시판을 구현하기 위한 데이터 모델을 열어보면 영락없이 그림 2-28처럼 발송메시지건수, 수신인수 같은 추출(derived)속성들이 설계되 있다.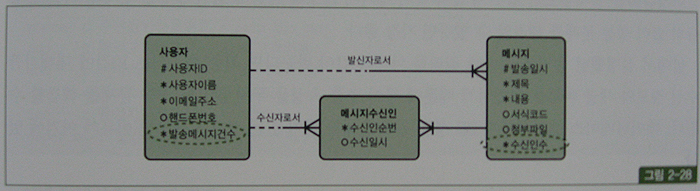
page. 317의 그림2-27과 같은 업무를 아래와 같은 SQL로 개발했다면 수신확인자수와 수신대상자수를 세고 새글여부를 확인하는 스칼라 서브쿼리 때문에 성능 문제를 겪었을 것이고, 이를 해결하지 못하면 위의 그림과 같이 설계하기 마련이다.
SELECT ..
FROM (
SELECT ..
FROM (
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) FROM 메시지수신인 ..) 수신확인자수
, ( SELECT COUNT(*) FROM 메시지수신인 ..) 수신대상자수
, ( CASE WHEN EXISTS ( SELECT 'x' FROM 메시지수신인
WHERE 발신자ID = a.발신자ID
AND 발송일시 = a.발송일시
AND 수신자ID = :로그인사용자ID
AND 수신일시 IS NULL ) THEN 'Y' END ) 새글여부
FROM 메시지 a, 사용자 b
ORDER BY a.발송일시 DESC
) a
WHERE rownum <= 10
)
WHERE no between 1 and 10;
위와 같은 추출 속성을 도입하면 메시지를 수신할 때마다 메시지 테이블의 수신인수를 갱신해주는 DML도 같이 작성해야 한다.
문제는 일상적이지 않은 업무로 데이터 정합성이 훼손될 수 있다는데 있다.
예를 들어 사용자가 탈퇴하면 메시지 수신인수도 일괄적으로 갱신해 주어야 하는데, 그런 처리를 실수로 빠뜨리기 쉽다.
반정규화를 실시했으면 업무 규칙 누락이 생기지 않도록 꼼꼼히 점검해야 한다.
최종 출력되는 10건에 대해서만 수신정보와 새글 여부를 확인하는 방식으로 쿼리 변경하여 성능 문제 해결
(스칼라 서브쿼리를 맨 바깥의 SELECT LIST에서 처리함)
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) || '/' || COUNT(*) FROM 메시지수신인 ..) 수신확인
, ( CASE WHEN EXISTS ( .. ) THEN 'Y' END ) 새글여부
FROM (
SELECT ROWNUM NO, ...
FROM ( SELECT 발신인ID, a,발송일시, a.제목 FROM 메시지 ORDER BY a.발송일시 DESC )
WHERE ROWNUM <= 30
) a, 사용자 b
WHERE NO BETWEEN 21 AND 30;
AND .........
(6) 징검다리 테이블 조인을 이용한 튜닝
from절에 조인되는 테이블 개수를 늘려 성능을 향상시키는 사례( 교재 page. 319~ )
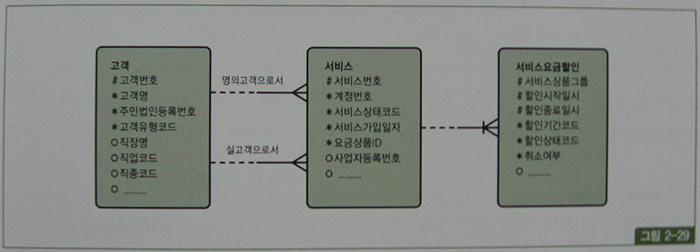
위의 데이터 모델에서 고객의 할인혜택을 조회하는 쿼리
SELECT /*+ ordered use_nl(s r)*/
c.고객번호, s.서비스번호, s.서비스구분
, s.서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s.명의고객번호 = c.고객번호
and r.서비스번호 = s.서비스번호
and r.서비스상품그룹 = '3001'
and r.할인기간코드 = '15'
order by r.할인종료일자 desc, s.서비스번호
인덱스 구성
고객_N1 : 주민법인등록번호
서비스_N2 : 명의고객번호 + 서비스번호
서비스요금할인_PK : 서비스요금할인_PK + 서비스상품그룹
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드
위의 쿼리 수행시 : 서버 구간에서만 28초가 걸리고, 블록 I/O는 226,672나 발생.
아래 그림은 Row Source Operation(p.320 실행계획)의 처리과정을 표현한 것이고, 각 오퍼레이션 단계에서의 출력 건수와 블록 I/O 발생량을 함께 표시하였다.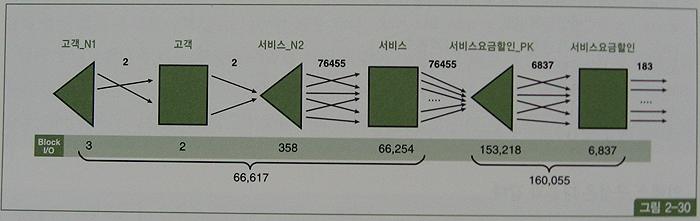
최종 건수는 183건에 불과 하지만, 고객 테이블을 먼저 드라이빙해 서비스 테이블과 NL 조인하는 과정에서 66,617개의 블록 I/O가 발생했고, 이어서 서비스요금할인 테이블과 NL 조인하는 과정에서 160,055개의 블록 I/O가 추가로 발생.
총 블록 I/O 개수는 226,672
아래는 조인 순서를 바꿔 서비스요금할인 테이블이 먼저 드라이빙 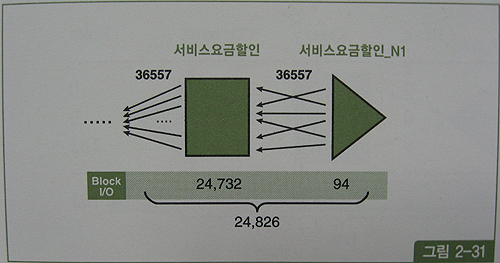
그림과 같이 할인기간코드 = '15' AND 서비스상품그룹코드 = '3001' 조건에 부합하는 레코드는 36,557건
테이블 액세스 하는 단계에서 24,826개의 블록I/O 발생, 조인순서를 바꾸더라도 조인액세스량 줄이기는 어렵다.
해시조인유도시 91,443(= 66,617 + 24,826)개의 블록I/O 발생 짐작.
I/O가 절반이상 줄기 때문에 조금은 빨라지겠지만, 속도는 만족스럽지 못함.
최종결과 건수는 얼마되지 않으면서, 필터 조건만으로 각 부분을 따로 읽으면 결과 건수가 아주 많을 때 튜닝하기가 가장 어려움.
이유는 NL 조인 과정에서 Random I/O 부하가 심하게 발생하기 때문이며, 어느 쪽으로 드라이빙하더라도 결과는 마찬가지.
튜닝을 위해 서비스요금할인_N1 인덱스에 아래와 같이 '서비스번호' 컬럼을 추가
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드 + 서비스번호
서비스와 서비스요금할인을 한 번씩 더 조인하도록 쿼리를 아래처럼 변경
SELECT /*+ ordered use_hash(r_brdg) rowid(s) rowid(r) */ ------------------- 1
c.고객번호, s.서비스번호, s.서비스구분
, s.서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c
, 서비스 s_brdg, 서비스요금할인 r_brdg ------------------------------ 2
, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s_brdg.명의고객번호 = c.고객번호
and r_brdg.서비스번호 = s_brdg.서비스번호
and r_brdg.서비스상품그룹 = '3001'
and r_brdg.할인기간코드 = '15'
and s.rowid = s_brdg.rowid --------------------------------- 3
and r.rowid = r_brdg.rowid -------------------------------- 4
order by r.할인종료일자 desc, s.서비스번호
실행결과(p.322)
튜닝 전에 226,672개 블록을 읽으면서 27.8초 걸리던 쿼리가 857개 블록을 읽으면서 0.12초만에 수행.
'서비스'와 '서비스요금할인' 테이블을 한 번씩 더 조인(from절 2번)함으로써 I/O가 줄면서 성공적으로 튜닝.
양쪽 테이블에서 인덱스만 읽은 결과끼리 먼저 조인하고 최종 결과집합 183건에 대해서만 테이블을 액세스하도록 한 것이 핵심 아이디어(서비스요금할인_N1 인덱스에 '서비스번호' 추가).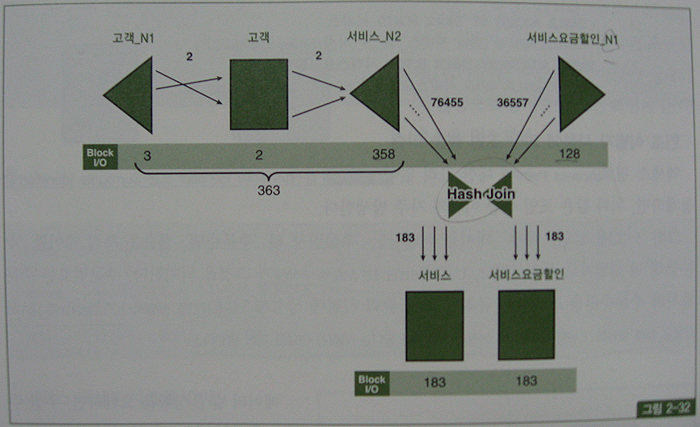
고객 테이블과 서비스_N2 인덱스를 조인할 때는 블록 I/O가 총 363번 발생.
서비스요금할인_N1 인덱스만 읽을 때도 블록 I/O는 128개(94개에서 128개로 늘어난 이유는 서비스번호 컬럼을 추가했기 때문)
인덱스에서 얻어진 집합끼리 조인할 때는 대량 데이터 조인이므로 해시 조인 방식을 사용(쿼리에서 1번)
인덱스에 없는 컬럼 값들을 읽으려고 테이블을 액세스할 때는 추가적인 인덱스 탐색 없이 인덱스에서 읽은 rowid 값을 가지고 직접 액세스(쿼리에서 3번과 4번, Table Access By User ROWID)
인조 식별자 사용에 의한 조인 성능 이슈
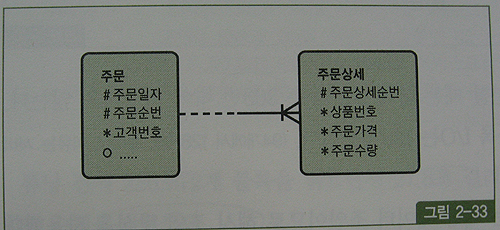
위 그림은 '주문' 테이블 식별자인 '주문일자'와 '주문순번' 컬럼을 자식 테이블 '주문상세'의 식별자로 상속시킴(UID Bar)
아래는 특정주문일자에 발생한 특정상품 주문금액 집계 쿼리(주문일자평균 100,000건, 상품번호 1000건, 상품번호별 하루평균 600건의 데이터)
주문상세 쪽 인덱스를 상품번호 + 주문일자 또는 주문일자 + 상품번호 순으로 구성. -- 자세한 설명은 4장 5절 '조건절 이행' 참조
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문일자 = 주문상세.주문일자
and 주문.주문순번 = 주문상세.주문순번
and 주문.주문일자 = '20090315'
and 주문상세.상품번호 = 'AC001'
반면, 아래 그림처럼 '주문번호'라는 인조 식별자 컬럼을 따로 둔다면 주문상세 테이블에 '주문일자' 속성이 상속되지 않음으로 조인 과정에 큰 비효율 발생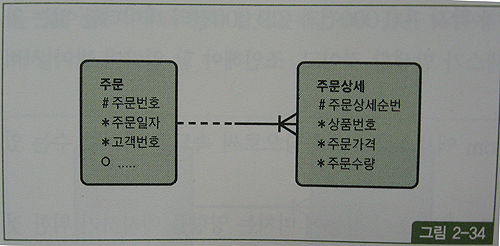
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문번호 = 주문상세.주문번호
and 주문.주문일자 = '20090315'
AND 주문상세.상품번호 = 'AC001'
인덱스 구성
주문_PK : 주문번호
주문_X01 : 주문일자
주문상세_PK : 주문번호 + 주문일자
주문상세_X01 : 상품번호
주문 테이블에서 읽은 100,000건에 대해 주문상세 쪽으로 100,000번의 조인 액세스가 일어남.
주문상세_PK 인덱스를 거쳐 주문상세 테이블을 100,000번 액세스하고서 상품번호 = 'AC001' 조건을 필터링 하고 나면 최종적으로 600건 정도만 남고 모두 버려짐.
주문상세_X01 또는 주문_X01 인덱스에 주문번호를 추가하고 이 인덱스를 이용하면 테이블 Random 액세스를 줄일 수 있지만 조인 시도 횟수는 줄지 않음.
해시 조인으로 유도하더라도 인덱스를 거쳐 각각 100,000건과 219,000건의 데이터를 읽는 과정에서 이미 상당량의 테이블 Random 액세스 발생할 것이고, 조인해야 할 일량이 많아 서버 리소스(CPU, 메모리)를 많이 사용하게 됨.
위 상황에서는 '주문일자' 컬럼을 주문상세 테이블로 반정규화하는 것이 가장 효과적인 해법일 것이다.
인조 식별자를 둘 때 주의 사항
장점
1. 단일 컬럼으로 구성되므로 테이블 간 연결 구조가 단순해지고, 인덱스 저장공간이 최소화된다.
2. 다중 컬럼으로 조인할 때보다 조인 연산을 위한 CPU사용량이 조금 줄 수 있다.
단점
1. 조인 연산 횟수와 블록 I/O 증가로 시스템 리소스를 낭비한다.
2. 실질 식별자를 찾기 어려워 데이터 모델이 이해하기 어려워진다.
TIP
1. 논리적인 데이터 모델링 단계에서는 가급적 인조 식별자를 두지 않는 것이 좋다.
2. 의미상 주어에 해당하는 속성들을 식별자로 사용했다가 물리 설계 단계에서 저장 효율과 액세스 효율 등을 고려해서 결정한다.
(7) 점이력 조회
데이터 변경이 발생할 때마다 변경일자와 함께 새로운 이력 레코드를 쌓는 방식을 점이력이라고 함.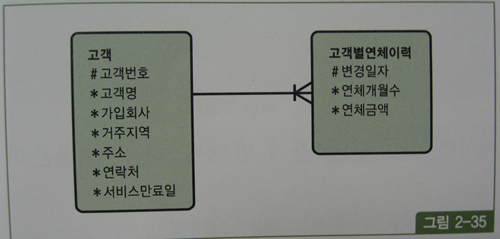
점이력 모델에서 이력을 조회할 때 흔히 아래와 같이 서브쿼리를 이용함
찾고자 하는 시점(서비스만료일) 보다 앞선 변경일자 중 가장 마지막 레코드를 찾는 것
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ max(변경일자)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 13 | | |
| 7 | FIRST ROW | | 5039 | 65507 | 3 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN (MIN/MAX)| 고객별연체이력_IDX01 5039 | 65507 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
서브쿼리 내에서 서비스만료일보다 작은 레코드를 모두 스캔하지 않고 오라클이 인덱스를 거꾸로 스캔하면서 가장 큰 값 하나만을 찾는 방식
(7번재 라인 First row, 8번째 라인 min/max, 오라클8 버전에서 구현)
서브쿼리를 아래와 같이 바꿔줄 수 있지만 실제 수행해 보면 서브쿼리 내에서 액세스되는 인덱스 루트 블록에 대한 버퍼 Pinning효과가 사라져 블록 I/O가 더 많이 발생
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ index_desc(b 고객별연체이력_IDX01 */ 변경일자
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1);
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
|* 6 | COUNT STOPKEY | | | | | |
|* 7 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | 26 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
고객별연체이력_idx 인덱스를 두 번 액세스하는 비효율은 피할 수 없음
Index_desc 힌트와 rownum <=1 조건 사용시, 주의사항
인덱스 구성이 변경되면 쿼리 결과가 틀리게 될 수 있음을 반드시 기억 해야함
first row(min/max) 알고리즘이 작동할 때는 반드시 min/max 함수를 사용하는 것이 올바른 선택
낮은 성능 때문에 어쩔수 없이 Index(또는 index_desc) + rownum조건을 써야만 하는 경우는
프로그램 목록을 관리했다가 인덱스 구성 변경시 확인하는 프로세스를 반드시 거쳐야함.
참고로, min 또는 max 함수 내에서 컬럼을 가공하면 first row 알고리즘이 작동하지 않는다.
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ substr(max(변경일자 || 연체개월수), 9)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 3836 (1)| 00:00:47 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 16 | | |
| 7 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 5039 | 80624 | 38 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 907 | | 6 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
스칼라 서브쿼리도 아래와 같이 max함수 사용하고 싶지만 first row 알고리즘이 작동하지 않아 부득이하게 index_desc힌트와
ronum 조건을 사용한 경우
select .....
,(selct substr(max(변경일자 || 연체금액), 9) from ...)
from 고객 a where .....
스칼라 서브쿼리로 변환하면 인덱스를 두번 액세스하지 않아도 되기 때문에 I/O를 그만큼 줄일 수 있음
여기서도 인덱스 루트 블록에 대한 버퍼 Pinning 효과는 사라진 것(10번 액세스하면서 30개 블록 I/O발생, 인덱스 height = 3)
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70';
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 430 | 2 (0)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN DESCENDING| 고객별연체이력_IDX01| 907 | | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
고객별연체이력 테이블로부터 연체금액 하나만 읽기 때문에 스칼라 서브쿼리로 변경하기가 수월했다
두개이상 컬럼을 읽어야 한다면 스칼라 서브쿼리 내에서 필요한 컬럼 문자열을 연결하고, 메인쿼리에서 substr함수로 잘라쓰는 방법을 사용해야 한다.
select 고객명, 거주지역, 주소, 연락처
, to_number(substr(연체, 3)) 연체금액
, to_number(substr(연체, 1, 2)) 연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */
lpad(연체개월수, 2) || 연체금액
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일
and rownum <= 1) 연체
from 고객 a
where 가입회사 = 'C70'
);
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 700 | 2 (0)| 00:00:01 |
| 1 | VIEW | | 10 | 700 | 2 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
이력 테이블에서 읽어야 할 컬럼 개수가 많다면 일일이 문자열로 연결하는 작업은 여간 번거롭지 않다.
스칼라 서브쿼리에서 rowid값만 취하고 고객별연체이력을 한번더 조인하는 방법을 생각해볼수 있다.
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid;
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 7381K| 12 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 100K| 7381K| 12 (0)| 00:00:01 |
| 2 | VIEW | | 10 | 560 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY USER ROWID | 고객별연체별이력 | 10079 | 187K| 1 (0)| 00:00:01 | --
------------------------------------------------------------------------------------------
고객별연체이력 테이블과 조인을 두 번 했지만 실행계획상 으로는 조인을 한 번만 한 것과 일량이 같다.
스칼라 서브쿼리 수행부분이 'VIEW'에 감춰져 보이지 않지만, 인덱스 이외의 컬럼을 참조하지 않았으므로 인덱스만 읽었을것이다.
거기서 얻은 rowid값으로 바로 테이블을 엑세스(Table Access by User ROWID)하기 때문에
일반적인 NL조인과 같은 프로세스(Outer 인덱스 -> Outer 테이블 -> Inner인덱스 -> Inner테이블)로 진행된다.
스칼라 서브쿼리를 이용하지 않고 아래와 같이 SQL을 구사해도 같은 방식으로 처리.
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <= 1);
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 957 | 59334 | 312 (0)| 00:00:04 |
| 1 | NESTED LOOPS | | 9574K| 566M| 12 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY USER ROWID | 고객별연체이력| 1007K| 18M| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN | 고객별연체이력| 2 | 38 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
고객(a)에서 읽은 고객번호로 서브쿼리 쪽 고객별연체이력©과 조인하고, 거기서 얻으 rowid값으로 고객별연체이력(b)을 곧바로
액세스한다. a와 b간에 따로 조인문을 기술하는 것은 불필요하다.
고객별연체이력을 두 번 사용했지만 실행계획 상으로는 한 번만 조인하면서 일반적인 NL조인과 같은 프로세스
(Outer인덱스 -> Otuer 테이블 -> Inner인덱스 -> Inner테이블)로 진행되는 것에 주목하기 바란다.
정해진 시점 기준으로 조회
앞에서는 가입회사 = 'C70'에 속하는 고객 수가 10명.
만약 가입회사별 고객수가 많아지면 서브쿼리 수행횟수가 늘어나 Random I/O부하도 심해질 것이다.
가입회사 조건절없이 모든 고객을 대상으로 이력을 조회한다면 ?
고객 테이블로부터 읽히는 미지의 시점(서비스 만료일)을 기준으로 이력을 조회하는 경우이기 때문에 위와 같이 Random 액세스 위주의 서브쿼리를 쓸수 밖에 없다.
정해진 시점을 기준으로 조회하는 경우라면 서브쿼리를 쓰지 않음으로써 Random 액세스 부하를 줄일 방법들이 몇가지 생긴다.
select /*+ full(a) full(b) full(c) use_hash(a b c) no_merge(b) */
a.고객명, a.거주지역, a.주소, a.연락처, c.연체금액, c.연체개월수
from 고객 a
,(select 고객번호, max(변경일자) 변경일자
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b, 고객별연체이력 c
where b.고객번호 = a.고객번호
and c.고객번호 = b.고객번호
and c.변경일자 = b.변경일자;
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 1 | HASH JOIN | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 2 | HASH JOIN | | 10 | 490 | 809 (5)| 00:00:10 |
| 3 | TABLE ACCESS FULL | 고객 | 10 | 300 | 3 (0)| 00:00:01 |
| 4 | VIEW | | 10 | 190 | 805 (4)| 00:00:10 |
| 5 | HASH GROUP BY | | 10 | 130 | 805 (4)| 00:00:10 |
|* 6 | TABLE ACCESS FULL| 고객별연| 9881 | 125K| 804 (4)| 00:00:10 |
| 7 | TABLE ACCESS FULL | 고객별연| 1007K| 18M| 788 (2)| 00:00:10 |
---------------------------------------------------------------------------------
가장 단순하게 작성된 위 쿼리는 고객별연체이력 테이블을 두번 Full Scan하는 비효율을 가짐
select a.고객명, a.거주지역, a.주소, a.연락처
, to_number(substr(연체, 11)) 연체금액
, to_number(substr(연체, 9, 2)) 연체개월수
from 고객 a
,(select 고객번호, max(변경일자 || lpad(연체개월수, 2) || 연체금액 ) 연체
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b
where b.고객번호 = a.고객번호;
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 251 | 15311 | 395 (1)| 00:00:05 |
| 1 | HASH GROUP BY | | 251 | 15311 | 395 (1)| 00:00:05 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 988 | 18772 | 39 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 9881 | 588K| 393 (0)| 00:00:05 |
| 4 | TABLE ACCESS FULL | 고객 | 10 | 420 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력| 988 | | 5 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
이력 테이블에서 읽어야 할 컬럼 개수가 많다면 위와 같이 일일이 문자열로 연결하는 작업은 여간 번거롭지 않음
그때는 아래와 같이 분석함수를 이용하는 것이 편하고, 수행 속도 면에서도 전혀 불리하지 않음
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, row_number() over (partition by 고객번호 order by 변경일자 desc) no
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.no = 1;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 810K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 810K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 521K| | 865 (4)| 00:00:11 |
|* 4 | WINDOW SORT PUSHED RANK| | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL | 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
---------------------------------------------------------------------------------------------
아래와 같이 max함수를 이용할 수도 있지만 방금처럼 row_number를 이용하는 것이 더 효과적인데, 자세한 원리는 5장 6절에서 설명.
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, max(변경일자) over (partition by 고객번호) max_dt
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.변경일자 = b.max_dt;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 781K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 781K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 492K| | 865 (4)| 00:00:11 |
| 4 | WINDOW SORT | | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL| 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
----------------------------------------------------------------------------------------
(8) 선분이력 조인
단일 선분이력을 조회하는 기본 패턴과 인덱스 스캔 효율을 높이는 방안에 대해서는 1장에서 자세히 설명함.
과거/현재/미래의 임의 시점 조회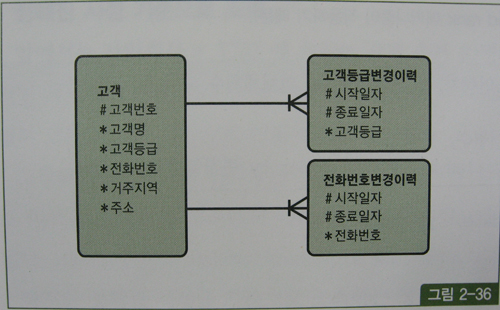
그림 2-36과 같이 고객등급과 전화번호 변경이력을 관리하는 두 선분이력 테이블이 있다고 하자.
고객과 이 두 선분이력 테이블을 조인해서 2004년 9월 1일 시점 데이터를 조회할 때는 아래와 같이 쿼리하면 된다.
물론 :dt 변수에는 '20040901'(시작일자, 종료일자가 문자열 컬럼일 때)을 입력한다.
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 = 123
and c1.고객번호 = c.고객번호
and c2.고객번호 = c.고객번호
and :dt between c1.시작일자 and c1.종료일자
and :dt between c2.시작일자 and c2.종료일자
123번 고객의 등급과 전화번호 변경이력 레코드를 수평선상에 펼쳐 시계열적으로 표현했을 때 그림 2-37과 같다면, 위 쿼리 결과로서 고객등급은 'B', 고객전화번호는 '987-6543'으로 조회될 것이다.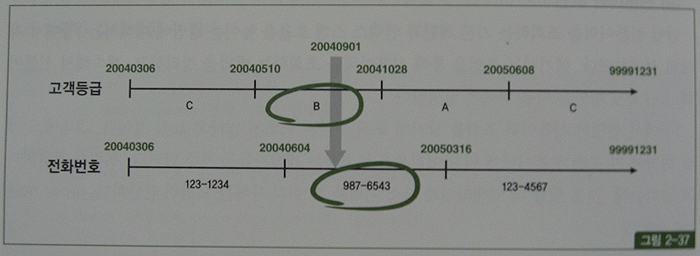
현재 시점 조회
위 쿼리를 이용해 과거, 현재, 미래 어느 시점이든 조회할 수 있지만, 만약 미래 시점 데이터를 미리 입력하는 예약 기능이 없다면 "현재 시점(즉, 현재 유효한 시점)" 조회는 아래와 같이 '=' 조건으로 만들어 주는 것이 효과적이다.
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 = 123
and c1.고객번호 = c.고객번호
and c2.고객번호 = c.고객번호
and c1.종료일자 = '99991231'
and c2.종료일자 = '99991231'
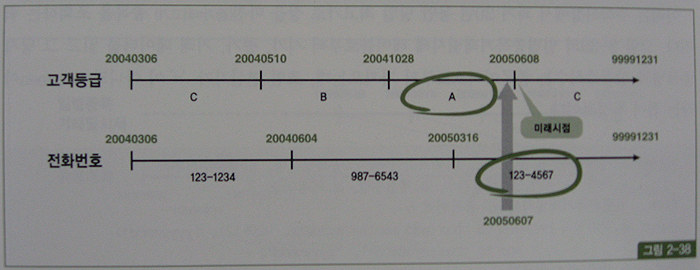
현재가 2005년 6월 7일인데 그림 2-38처럼 미래 시점인 6월 8일 데이터를 미리 입력해두는 기능이 있다면, 현재 시점을 조회할 때 아래와 같이 sysdate와 between을 사용해야만 한다.
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 = 123
and c1.고객번호 = c.고객번호
and c2.고객번호 = c.고객번호
and to_char(sysdate, 'yyyymmdd') between c1.시작일자 and c1.종료일자
and to_char(sysdate, 'yyyymmdd') between c2.시작일자 and c2.종료일자
Between 조인
지금까지는 선분이력 조건이 상수였다.
즉, 조회 시점이 정해져 있었다.
그림 2-39에서 만약 우측(일별종목거래 및 시세)과 같은 일별 거래 테이블로부터 읽히는 미지의 거래일자 시점으로 선분이력(종목이력)을 조회할 때는 어떻게 해야 할까?
이때는 between 조인을 이용하면 된다.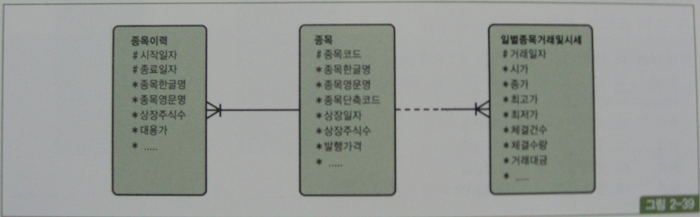
아래는 주식시장에서 과거 20년 동안 당일 최고가로 장을 마친(종가=최고가) 종목을 조회하는 쿼리다.
그림 2-39의 일별종목거래및시세 테이블로부터 시가, 종가, 거래 데이터를 읽고 그 당시 종목명과 상장주식수는 종목이력으로부터 가져오는데, 조인 연산자가 '=' 이 아니라 between이라는 점이 특징적이다.
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수
, a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_months(sysdate, -20*12), 'yyyymmdd')
and to_char(sysdate-1, 'yyyymmdd')
and a.종가 = a.최고가
and b.종목코드 = a.종목코드
and a.거래일자 between b.시작일자 and b.종료일자
이런 식으로 조회하면 현재(=최종) 시점의 종목명을 가져오는 것이 아니라 그림 2-40에서 보는 것처럼 거래가 일어난 바로 그 시점의 종목명을 읽게 된다.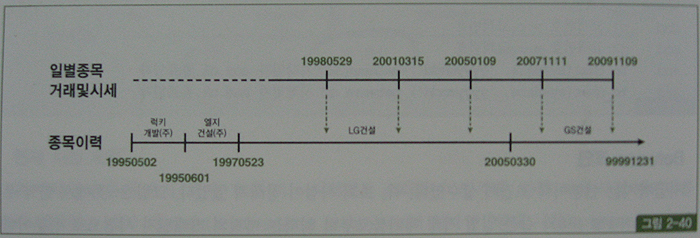
거래 시점이 아니라 현재(=최종) 시점의 종목명과 상장주식수를 출력하려면 between 조인 대신 아래와 같이 상수 조건으로 입력해야 한다(그림 2-41 참조).
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수
, a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_months(sysdate, -20*12), 'yyyymmdd')
and to_char(sysdate-1, 'yyyymmdd')
and a.종가 = a.최고가
and b.종목코드 = a.종목코드
and to_char(sysdate, 'yyyymmdd') between b.시작일자 and b.종료일자
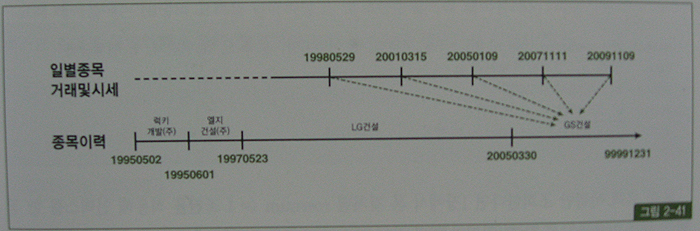
위 쿼리는 종목 테이블을 종목이력과 통합해 하나로 설계했을 때 사용하는 방식이다.
그림 2-39처럼 종목과 종목이력을 따로 설계했을 때는 최종 시점을 위해 종목 테이블과 조인하면 된다.
(9) 선분이력 조인 튜닝
정해진 시점을 기준으로 선분이력과 단순 조인할 때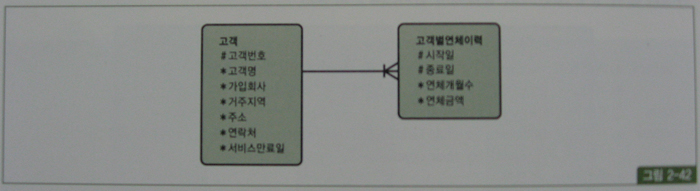
그림 2-42와 같은 모델 하에서 아래처럼 특정 회사(예, 가입회사 = 'C70')를 통해 가입한 모든 고객의 연체금액을 조회하는 경우를 생각해 보자.
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일
위 쿼리를 수행해 보면, 'C70' 회사를 통해 가입한 모든 고객에 대해 시작일이 2005년 1월 31일보다 작거나 같은 이력을 모두 스캔하거나(인덱스 구성상 시작일이 종료일보다 선행 컬럼일 때), 종료일이 2005년 1월 31일보다 크거나 같은 이력을 모두 스캔(종료일이 시작일보다 선행 컬럼일 때)하게 된다.
아래와 같이 실제 테이블을 만들고 쿼리를 수행하면서 비효율 발생 원인과 튜닝 방안에 대해 살펴보자.
create table 고객
as
select empno 고객번호, ename 고객명, 'C70' 가입회사
, '서울' 거주지역, '...' 주소, '123-' || empno 연락처
, to_char(to_date('20050101','yyyymmdd')+rownum*20000,'yyyymmdd') 서비스만료일
from emp
where rownum <= 10;
create index 고객_idx01 on 고객(가입회사);
create table 고객별연체이력
as
select a.고객번호, b.시작일, b.종료일, b.연체개월수, b.연체금액
from 고객 a
,(select to_char(to_date('20050101', 'yyyymmdd')+rownum*2, 'yyyymmdd') 시작일
, to_char(to_date('20050102', 'yyyymmdd')+rownum*2, 'yyyymmdd') 종료일
, round(dbms_random.value(1, 12)) 연체개월수
, round(dbms_random.value(100, 1000)) * 100 연체금액
from dual
connect by level <= 100000) b;
고객 테이블에는 10명의 고객을 입력하고, 고객별연체이력 테이블에는 고객마다 10만개의 이력 레코드를 입력하였다.
select min(시작일) MN_시작일, max(시작일) MX_시작일 from 고객별연체이력;
MN_시작일 MX_시작일
---------------- ----------------
20050103 25520801
위 쿼리 결과에서 보듯 2005년 1월 3일부터 2552년 8월 1일까지의 이력 데이터가 들어있다.
먼저 인덱스를 고객번호 + 종료일 + 시작일 순으로 구성해 보자.
create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 종료일, 시작일);
아래는 SQL 트레이스를 활성화하고서 실제 쿼리르 수행한 결과다.
-- Oracle Release 10g
SQL> select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
2 from 고객 a, 고객별연체이력 b
3 where a.가입회사 = 'C70'
4 and b.고객번호 = a.고객번호
5 and '20050131' between b.시작일 and b.종료일;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.41 0.40 4619 4636 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.42 0.40 4619 4636 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=4636 pr=4619 pw=0 time=273 us)
21 NESTED LOOPS (cr=4634 pr=4619 pw=0 time=4334 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=223 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=116 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=4630 pr=4619 pw=0 time=706 us)(object id 117505)
고객 테이블에 입력돼 있는 단 10명의 연체이력을 조회하는데, 고객별연체이력_idx01 인덱스 스캔 단계에서만 4,630개의 블록 I/O가 발생하였다.
고객마다 종료일이 2005년 1월 31일보다 크거나 같은 이력을 모두 스캔한 것이다.
인덱스를 아래와 같이 바꿔주면 시작일이 2005년 1월 31일보다 작거나 같은 이력을 찾을 것이고, 여기에 해당하는 데이터가 매우 소량이므로 인덱스 스캔량이 획기적으로 줄 것이다.
SQL> drop index 고객별연체이력_idx01;
인덱스가 삭제되었습니다.
SQL> create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 시작일, 종료일);
인덱스가 생성되었습니다.
아래는 인덱스 구성을 바꾸고서 실제 쿼리한 결과다.
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 30 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 30 0 10
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=30 pr=0 pw=0 time=172 us)
21 NESTED LOOPS (cr=28 pr=0 pw=0 time=1836 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=242 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=173 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=24 pr=0 pw=0 time=259 us)(object id 117506)
예상했던 대로 고객별연체이력_idx01 인덱스를 스캔하는 단계에서 블록 I/O가 24개만 발생하였다.
'C70' 회사를 통해 가입한 고객만 조회하는 것이 아니라 만약 아래와 같이 전체 고객을 대상으로 조회할 때는 Random 액세스 위주의 NL 조인보다 해시 조인을 이용하는 것이 유리하다.(예제 데이터에는 모든 고객의 가입회사가 'C70' 이므로 성능 차이가 없겠지만.)
select /*+ ordered use_hash(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 2 32 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.00 2 32 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=32 pr=2 pw=0 time=2657 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=91 us)
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=29 pr=2 pw=0 time=166 us)
10 INDEX SKIP SCAN 고객별연체이력_IDX01 (cr=27 pr=2 pw=0 time=662 us)(object id 117506)
해시 조인을 이용하면 전체 이력 레코드를 Full Scan 하는 비용은 있을지언정 해시 조인 과정에서의 비효율은 없다.
고객별연체이력을 해시 테이블로 빌드하더라도 각 고객별로 한 건의 이력 레코드만 해시 테이블에 담기 때문이며, 뒤에서 보겠지만 between 조인일 때는 전 구간이력 레코드를 해시 테이블로 빌드함으로 인해 엄청난 비효율을 수반하기도 한다.
Between 조인 튜닝 - 조회 대상이 많지 않을 때
앞에서 정해진 시점을 기준으로 선분이력과 단순 조인할 때의 튜닝 방안을 살펴보았다.
문제는, 아래와 같이 미지의 값(고객 테이블에서 실시간으로 읽히는 값)으로 between 조인하는 경우다.
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and a.서비스만료일 between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.16 0.15 0 2571 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.16 0.15 0 2571 0 10
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=2571 pr=0 pw=0 time=3026 us)
21 NESTED LOOPS (cr=2561 pr=0 pw=0 time=58935 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=145 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=75 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=2557 pr=0 pw=0 time=152588 us)(object id 117506)
고객 테이블에는 서비스만료일이 아래와 같이 '20591005'부터 '25520801'까지 10개의 값(고객이 단 10명뿐이므로)이 들어있다.
SQL> select min(서비스만료일) 최소만료일, max(서비스만료일) 최대만료일 from 고객;
최소만료일 최대만료일
---------------- ----------------
20591005 25520801
이런 상태에서 조금 전 보았던 between 조인을 수행한다면, 고객에서 읽힌 값이 '25520801'일 때는 거의 처음부터 끝까지 스캔하고서야 조건을 만족하는 이력 데이터를 찾을 수 있다.
현재의 인덱스 구성상 시작일자가 종료일자보다 선행컬럼이기 때문이다.
반대로, '20591005'일 때는 스캔량이 그리 많지 않을 것이다.
조인문을 스칼라 서브쿼리나 중첩된 서브쿼리(nested subquery) 형태로 바꾼다면 각 고객별로 단 하나의 이력만 읽도록 rownum <= 1 조건을 추가해 줄 수 있다.
다행히 위에서는 고객별연체이력 테이블로부터 연체금액 하나만 읽기 때문에 아래와 같이 스칼라 서브쿼리로 간단히 변경할 수 있다.
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 1 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 1 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=40 pr=1 pw=0 time=722 us)
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=40 pr=1 pw=0 time=636 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=1 pw=0 time=548 us)(object id 117506)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=46 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=208 us)(object id 117502)
위 Row Source Operation에서 보듯, 쿼리를 바꾸고 rownum <= 1 조건을 사용했더니 고객별 연체이력_idx01 인덱스 스캔 단계에서 블록 I/O가 30개만 발생하였다.
연체금액과 연체개월수, 두 컬럼을 읽고자 한다면, 컬럼들을 문자열로 연결하고서 바깥 쪽 액세스 쿼리에서 substr 함수로 잘라 쓰거나, 아래와 같이 스칼라 서브쿼리에서 rowid 값만 취하고 고객별연체이력을 한 번 더 조인하는 방법을 쓸 수 있다.
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.00 0 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=247 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=171 us)(object id 117506)
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=115 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=190 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=126 us)(object id 117502)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=375 us)
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=247 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=171 us)(object id 117506)
스칼라 서브쿼리 대신 일반 서브쿼리로부터 읽은 rowid로 테이블을 직접 액세스 하는 방법
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 A, 고객별연체이력 B
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index_desc(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=115 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=199 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=126 us)(object id 117502)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=376 us)
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=245 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=169 us)(object id 117506)
Between 조인 튜닝 - 조회 대상이 많지만 대상별 이력 레코드가 많지 않을 때
전체 고객을 대상으로 한다면 Random 액세스 위주의 NL 조인보다 아래처럼 해시 조인을 이용하는 것이 효과적이다.
select /*+ ordered use_hash(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 1.06 1.03 4702 4725 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 1.06 1.03 4702 4725 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=4725 pr=4702 pw=0 time=115957 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=117 us)
1000000 TABLE ACCESS FULL 고객별연체이력 (cr=4722 pr=4702 pw=0 time=1000046 us)
Between 조인 튜닝 - 대상별 이력 레코드가 많을 때
지금까지 설명한 선분이력 조인 튜닝 방안을 요약해 보면 다음과 같다.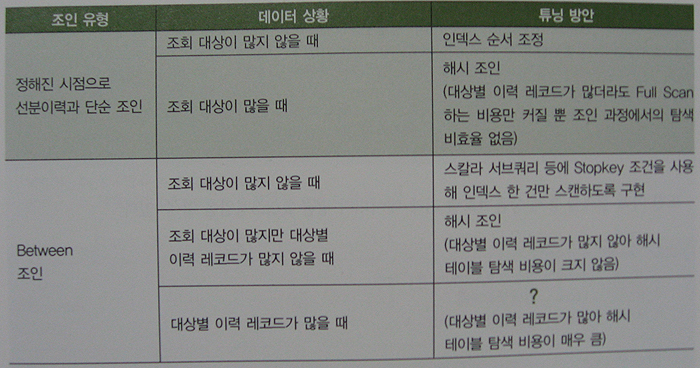
'대상별 이력 레코드가 많을 때의 between 조인'이 가장 튜닝하기가 어렵다.
대량의 선분이력을 해시 조인하는데 각 해시 버컷에 많은 이력 레코드가 달리는 구조라면 매번 그것들을 스캔하면서 이력을 탐색하기 때문에 비효율이 생긴다.
필자의 제안, 두 개 이상 월에 걸치는 이력이 생기지 않도록 매월 말일 시점에 강제로 이력을 끊어주는 것
between 조인에 의한 스캔 범위가 한 달을 넘지 않도록 새로운 조인 조건절을 추가해 줄 수 있다.
해시 체인을 스캔하는 비효율을 완전히 없앨 수는 없지만 최대 31개가 넘지 않도록 제한하려는 것이다.
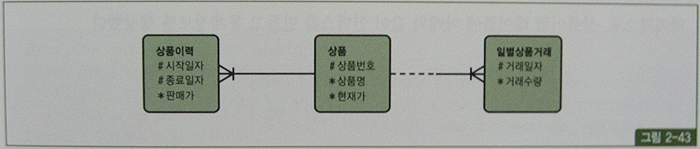
성능 비교를 위해 그림 2-43과 같은 형태로 테이블을 만들어 보자.
SQL> create table 일별상품거래
2 as
3 select 'A' || lpad(b.no, 4, '0') 상품번호, a.거래일자, round(dbms_random.value(1, 100)) 거래수
량
4 from (select to_char(sysdate - rownum, 'yyyymmdd') 거래일자
5 from dual
6 connect by level <= 3653) a
7 ,(select rownum no from dual connect by level <= 100) b
8 ;
테이블이 생성되었습니다.
SQL> create table 상품이력
2 as
3 select 상품번호
4 ,(case when 거래일자 = min(거래일자) over (partition by 상품번호) then 최소일자 else 거래
일자 end) 시작일자
5 ,(case when 거래일자 = max(거래일자) over (partition by 상품번호) then '99991231' else to_
char(to_date(거래일자, 'yyyymmdd') + 3, 'yyyymmdd') end) 종료일자
6 , round(dbms_random.value(100, 10000), -2) 판매가
7 from (
8 select 상품번호, 거래일자, mod(rownum, 4) no
9 from (
10 select 상품번호, 거래일자
11 from 일별상품거래
12 order by 상품번호, 거래일자
13 )
14 ), (select min(거래일자) 최소일자 from 일별상품거래)
15 where no = 1
16 ;
테이블이 생성되었습니다.
SQL> select count(distinct 상품번호) 상품수, count(*)
2 from 일별상품거래;
상품수 COUNT(*)
---------- ----------
100 365300
-- 상품번호별 거래 데이터가 평균 3,653건
SQL> select avg(cnt)
2 from (select 상품번호, count(*) cnt
3 from 일별상품거래
4 group by 상품번호);
AVG(CNT)
----------
3653
-- 상품이력 테이블에는 상품별로 평균 913건의 이력이 존재
-- 평균적으로 4일에 한 번(=3,653/913)씩 이력 데이터가 생성된 셈
SQL> select avg(cnt)
2 from (
3 select 상품번호, count(*) cnt
4 from 상품이력
5 group by 상품번호
6 )
7 ;
AVG(CNT)
----------
913.25
-- 상품이력 테이블에 인덱스를 만들고 통계정보 생성
SQL> create index 상품이력_idx on 상품이력(상품번호, 시작일자, 종료일자);
인덱스가 생성되었습니다.
SQL> exec dbms_stats.gather_table_stats(user, '일별상품거래');
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL> exec dbms_stats.gather_table_stats(user, '상품이력');
PL/SQL 처리가 정상적으로 완료되었습니다.
인덱스는 NL 조인으로 수행할 때의 속도도 함께 비교하려고 만든 것이며, 과거부터 최근 이력까지 골고루 조회할 것이므로 컬럼 순서는 중요치 않다.
아래는 Nl 조인 방식으로 between 조인을 수행한 결과다.
select /*+ leading(b) use_nl(a) index(a 상품이력_idx)*/
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 56.92 55.60 1 1900386 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 56.93 55.61 1 1900386 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1900386 pr=1 pw=0 time=55609298 us)
365300 TABLE ACCESS BY INDEX ROWID 상품이력 (cr=1900386 pr=1 pw=0 time=58082932 us)
730601 NESTED LOOPS (cr=1535086 pr=1 pw=0 time=2210032 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365356 us)
365300 INDEX RANGE SCAN 상품이력_IDX (cr=1533917 pr=1 pw=0 time=52300282 us)(object id 117596)
아래는 stopkey 조건을 적용한 서브쿼리로부터 rowid를 읽어 직접 이력 테이블을 액세스하는 방식
-- 튜닝한 선분이력 조회 (NL 조인 및 rowid 이용)
-- (참고로, 아래 쿼리는 SQL 트레이스 걸면 매우 오래 걸리지만 그냥 수행하면 굉장히 빠르게 조회됩니다.
-- 9i, 10g, 11g에서 공통적으로 나타나는 현상이며, 버그라고 생각됩니다.)
select /*+ ordered use_nl(b) rowid(b) */
sum(a.거래수량) 총거래수량
, sum(a.거래수량 * b.판매가) 총판매금액
, round(avg(a.거래수량 * b.판매가)) 평균판매금액
from 일별상품거래 a, 상품이력 b
where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
from 상품이력 c
where 상품번호 = a.상품번호
and a.거래일자 between c.시작일자 and c.종료일자
and rownum <= 1)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 12.53 12.23 0 1462640 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 12.53 12.23 0 1462640 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1462640 pr=0 pw=0 time=12235960 us)
365300 NESTED LOOPS (cr=1462640 pr=0 pw=0 time=12785586 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365350 us)
365300 TABLE ACCESS BY USER ROWID 상품이력 (cr=1461471 pr=0 pw=0 time=10969772 us)
365300 COUNT STOPKEY (cr=1096171 pr=0 pw=0 time=7270114 us)
365300 INDEX RANGE SCAN DESCENDING 상품이력_IDX (cr=1096171 pr=0 pw=0 time=4678008 us)(object id 117596)
SQL> ALTER SESSION SET SQL_TRACE=FALSE;
세션이 변경되었습니다.
SQL> set timing on
SQL> set autotrace traceonly
SQL> select /*+ ordered use_nl(b) rowid(b) */
2 sum(a.거래수량) 총거래수량
3 , sum(a.거래수량 * b.판매가) 총판매금액
4 , round(avg(a.거래수량 * b.판매가)) 평균판매금액
5 from 일별상품거래 a, 상품이력 b
6 where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
7 from 상품이력 c
8 where 상품번호 = a.상품번호
9 and a.거래일자 between c.시작일자 and c.종료일자
10 and rownum <= 1)
11 ;
경 과: 00:00:12.57
Execution Plan
----------------------------------------------------------
Plan hash value: 3446302624
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 101G (1)|999:59:59 |
| 1 | SORT AGGREGATE | | 1 | 33 | | |
| 2 | NESTED LOOPS | | 34G| 1047G| 370K (1)| 01:14:05 |
| 3 | TABLE ACCESS FULL | 일별상품 | 369K| 6503K| 268 (3)| 00:00:04 |
| 4 | TABLE ACCESS BY USER ROWID | 상품이력 | 92162 | 1350K| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN DESCENDING| 상품이력_| 2 | 54 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(ROWNUM<=1)
6 - access("상품번호"=:B1 AND "C"."종료일자">=:B2 AND "C"."시작일자"<=:B3)
filter("C"."종료일자">=:B1)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1462640 consistent gets
0 physical reads
0 redo size
482 bytes sent via SQL*Net to client
392 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> set autotrace off;
SQL> select /*+ ordered use_nl(b) rowid(b) */
2 sum(a.거래수량) 총거래수량
3 , sum(a.거래수량 * b.판매가) 총판매금액
4 , round(avg(a.거래수량 * b.판매가)) 평균판매금액
5 from 일별상품거래 a, 상품이력 b
6 where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
7 from 상품이력 c
8 where 상품번호 = a.상품번호
9 and a.거래일자 between c.시작일자 and c.종료일자
10 and rownum <= 1)
11 ;
총거래수량 총판매금액 평균판매금액
---------- ---------- ------------
18429240 9.3271E+10 255327
경 과: 00:00:12.57
위의 결과는 SQL 트레이스의 영향이 없이 동일한 수행속도.
SQL 트레이스를 걸면 쿼리가 비정상적으로 오래 걸릴 때가 가끔 있고, 대개는 버그에 의한 것이다.
SQL 트레이스를 걸지 않은 정상적인 상태가 기준이어야 하므로 (위 예제의 55초에서 12초로) 수행 속도가 감소했다고 평가할 수 있다.
대량 데이터를 조인할 때 NL 조인은 비효율적이므로 이번에는 해시 조인으로 바꿔서 수행해보자.
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 137.28 134.13 0 1578 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 137.29 134.13 0 1578 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1578 pr=0 pw=0 time=134135617 us)
365300 HASH JOIN (cr=1578 pr=0 pw=0 time=135619021 us)
91325 TABLE ACCESS FULL 상품이력 (cr=409 pr=0 pw=0 time=91375 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365358 us)
인덱스 기반의 between 조인할 땝다 더 오래 걸렸다.
이유는, 각 상품별 이력이 평균 913건이나 되기 때문이다. 즉, 해시 테이블 탐색 비용이 매우 높은 것이 원인이다.
선분 형태의 이력이지만 한 달 범위를 넘지 않도록 했기 때문에 아래와 같이 '=' 조인문을 하나 더 추가해 줄 수 있다.
상품번호 외에 월 조건까지 해시 키 값으로 사용하게 되었으므로 해시 버킷에서 스캔해야 할 양은 최대 31개를 넘지 않는다.
SQL> create table 상품이력2
2 as
3 select 상품번호
4 ,(case when 거래일자 = min(거래일자) over (partition by 상품번호) then 최소일자 else to_ch
ar(거래일자, 'yyyymmdd') end) 시작일자
5 ,(case when 거래일자 = max(거래일자) over (partition by 상품번호) then '99991231' else to_
char(lead(거래일자) over (partition by 상품번호 order by 거래일자)-1, 'yyyymmdd') end) 종료일자
6 , round(dbms_random.value(100, 10000), -2) 판매가
7 from (
8 select 상품번호, to_date(거래일자, 'yyyymmdd') 거래일자, mod(rownum, 4) no
9 from (
10 select 상품번호, 거래일자
11 from 일별상품거래
12 order by 상품번호, 거래일자
13 )
14 ), (select min(거래일자) 최소일자 from 일별상품거래)
15 where no = 1 or to_char(거래일자, 'dd') = '01'
16 ;
테이블이 생성되었습니다.
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력2 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
and trunc(to_date(b.거래일자, 'yyyymmdd'), 'mm') = trunc(to_date(a.시작일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 1 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 3.15 3.06 187 1617 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 3.15 3.07 187 1618 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1617 pr=187 pw=0 time=3068575 us)
365300 HASH JOIN (cr=1617 pr=187 pw=0 time=4638547 us)
100325 TABLE ACCESS FULL 상품이력2 (cr=448 pr=187 pw=0 time=100489 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365370 us)
상품이력2 테이블에서 출력된 건수는 앞에서보다 9,000(=100,325-91,325)건 더 많아졌지만 성능은 비교할 수 없이 빨라졌다.
두 번째 방안은, 두 개 이상 월에 걸치는 이력이 없도록 쿼리 시점에 선분이력을 변환해 주는 것이다.
그런 다음 조인하는 방법은 앞에서와 같고, 마찬가지로 해시 체인을 스캔하는 양은 최대 31개로 제한될 것이다.
SQL> select * from 월도 order by 1;
기준월 시작일자 종료일자
------------ ---------------- ----------------
199211 19921101 19921130
199212 19921201 19921231
199301 19930101 19930131
199302 19930201 19930228
199303 19930301 19930331
199304 19930401 19930430
199305 19930501 19930531
199306 19930601 19930630
199307 19930701 19930731
199308 19930801 19930831
199309 19930901 19930930
...
...
241 개의 행이 선택되었습니다.
아래와 같이 부등호 조건으로 '월도' 테이블과 '상품이력' 테이블을 조인하면 '(2) 선분이력 끊기'에서 자세히 설명했듯이 두개 이상 월에 걸친 상품이력이 여러 개로 복제 된다.
select a.기준월, b.시작일자, b.종료일자
from 월도 a, 상품이력 b
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
상품이력이 여러 개 생기더라도 기준월은 각각 다른 값을 가지므로 거래월과 '=' 조인할 수 있다.
예를 들어, 20090821 ~ 20091007 기간에 해당하는 상품이력이 있다면 아래 표와 같은 데이터가 만들어질 것이다.
select /*+ ordered use_merge(b) use_hash(c) */
sum(c.거래수량) 총거래수량
, sum(c.거래수량 * b.판매가) 총판매금액
, round(avg(c.거래수량 * b.판매가)) 평균판매금액
from 월도 a, 상품이력 b, 일별상품거래 c
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
and c.상품번호 = b.상품번호
and c.거래일자 between b.시작일자 and b.종료일자
and a.기준월 || '01'
= trunc(to_date(c.거래일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 1 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 4 19.58 19.10 0 3162 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 8 19.58 19.11 0 3163 0 2
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1581 pr=0 pw=0 time=9534623 us)
365300 HASH JOIN (cr=1581 pr=0 pw=0 time=11090507 us)
100325 MERGE JOIN (cr=412 pr=0 pw=0 time=6135538 us)
241 SORT JOIN (cr=3 pr=0 pw=0 time=1093 us)
241 TABLE ACCESS FULL 월도 (cr=3 pr=0 pw=0 time=290 us)
100325 FILTER (cr=409 pr=0 pw=0 time=405580 us)
5590350 SORT JOIN (cr=409 pr=0 pw=0 time=11341081 us)
91325 TABLE ACCESS FULL 상품이력 (cr=409 pr=0 pw=0 time=91346 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365367 us)
이 방식을 사용하면 '일별상품거래'와 조인할 때는 빠르지만, '월도' 테이블과 조인하는 과정에서 오히려 병목이 생길 수 있다.
Between 조인 튜닝 요약
대상별 이력 레코드가 많을 때의 between 조인은 좋은 성능을 내기가 쉽지 않음을 알 수 있다.(해당하는 마스터 테이블 이력이라면 월말 시점마다 선분을 끊어주는 것을 고려)
마스터 데이터 건수가 적으면서 변경이 잦은 경우라면 매일 전체 대상 집합을 새로 저장하는 이력 관리 방식(스냅샷 형태)도 고려해 볼 수 있다.
(10) 조인에 실패한 레코드 읽기
조인에 실패했을 때, 정해진 특정 레코드에서 가져온 값을 보여주고 싶을때,
예를 들어, cdr_rating(CDR 과금) 테이블에 아래와 같이 국가와 지역별 요금 정보가 입력돼 있다.
SQL> select 국가코드, '''' || 지역 || '''', 요금 from cdr_rating ;
국가 ''''||지역||'''' 요금
---- ------------------------ ----------
82 'A' 100
82 'B' 200
82 'C' 500
82 'D' 300
82 'E' 100
84 'A' 300
84 'B' 500
84 'C' 400
84 ' ' 800
86 'A' 500
86 'B' 200
국가 ''''||지역||'''' 요금
---- ------------------------ ----------
86 ' ' 700
12 개의 행이 선택되었습니다.
국가코드 82(한국)는 모든 지역에 대한 요금정보를 갖고 있다.
하지만 국가코드 84(베트남)의 경우 A, B, C가 아닌 지역에 대해서는 일괄적으로 800원을 부과하려고 위와 같이 공백문자(' ')로 입력해둔 것이다.
국가코드 86(중국)도 A, B가 아닌 지역에 대해서는 일괄적으로 700원이 부과된다.
아래는 cdr(통화내역) 테이블에 입력된 정보를 출력한 것이다.
SQL> select * from cdr;
통화시간 국가 지역
------------------------------ ---- --------------------
20050315 010101 82 A
20050315 020101 82 B
20050315 030101 82 C
20050315 040101 84 A
20050315 050101 84 B
20050315 060101 84 C
-- cdr_rating에 매칭되는 정보 없음
20050315 070101 84 D
20050315 080101 84 E
--
20050315 090101 86 A
20050315 100101 86 B
-- cdr_rating에 매칭되는 정보 없음
20050315 110101 86 C
20050315 120101 86 D
20050315 130101 86 E
20050315 140101 86 F
--
이제 cdr과 cdr_rating 두 테이블을 조인해 2005년 3월 15일 시점 통화내역과 요금정보를 출력하려 하는데, 일반적인 조인문을 사용하면 아래와 같이 조인에 실패한 통화내역은 출력되지 않는다.
SQL> select /*+ ordered use_nl(r) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and c.국가코드 = r.국가코드
6 and c.지역 = r.지역 ;
통화시간 국가 지역 요금
------------------------------ ---- -------------------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 300
20050315 050101 84 B 500
20050315 060101 84 C 400
20050315 090101 86 A 500
20050315 100101 86 B 200
8 개의 행이 선택되었습니다.
cdr을 기준으로 Outer 조인하면 통화내역은 모두 출력되겟지만 기타지역 통화내역에 대한 요금 정보가 Null로 출력된다.
SQL> select /*+ ordered use_nl(r) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and c.국가코드 = r.국가코드(+)
6 and c.지역 = r.지역(+) ;
통화시간 국가 지역 요금
------------------------------ ---- -------------------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 300
20050315 050101 84 B 500
20050315 060101 84 C 400
20050315 070101 84 D
20050315 080101 84 E
20050315 090101 86 A 500
20050315 100101 86 B 200
20050315 110101 86 C
20050315 120101 86 D
20050315 130101 86 E
20050315 140101 86 F
14 개의 행이 선택되었습니다.
어떻게 쿼리해야 조인에 실패했을 때 지역이 공백(' ')인 요금 정보를 가져올 수 있을까? 아래와 같이 쿼리하면 된다.
SQL> select /*+ ordered use_nl(r) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and (r.국가코드, r.지역) =
6 (select c.국가코드, max(지역)
7 from cdr_rating
8 where 국가코드 = c.국가코드
9 and 지역 in (' ', c.지역) ) ;
통화시간 국가 지역 요금
------------------------------ ---- -------------------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 300
20050315 050101 84 B 500
20050315 060101 84 C 400
20050315 070101 84 D 800
20050315 080101 84 E 800
20050315 090101 86 A 500
20050315 100101 86 B 200
20050315 110101 86 C 700
20050315 120101 86 D 700
20050315 130101 86 E 700
20050315 140101 86 F 700
14 개의 행이 선택되었습니다.
9i 까지는 use_concat 힌트를 이용해 아래와 같이 쿼리할 수 있었다.
IN-List가 concatenation(or-expansion) 방식으로 풀리면 뒤쪽에 있는 값이 먼저 실행되는 특징을 이용하는 것이다.
SQL> select /*+ ordered use_nl(r) index(r pk_cdr_rating) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and (r.국가코드, r.지역) =
6 (select /*+ use_concat */ c.국가코드, 지역
7 from cdr_rating
8 where 국가코드 = c.국가코드
9 and 지역 in (' ', c.지역)
10 and rownum <= 1) ;
통화시간 국가 지역 요금
------------------------------ ---- -------------------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 800
20050315 050101 84 B 800
20050315 060101 84 C 800
20050315 070101 84 D 800
20050315 080101 84 E 800
20050315 090101 86 A 700
20050315 100101 86 B 700
20050315 110101 86 C 700
20050315 120101 86 D 700
20050315 130101 86 E 700
20050315 140101 86 F 700
10g부터는 일반적인 use_concat 힌트로는 OR-Expansion이 일어나지 않기 때문에 위와 같은 기법을 쓸 수가 없다.
use_concat에 특별한 인자를 넣어 위와 같은 방식으로 유도할 순 있지만(4장 7절 참조) CPU 비용모델에서는 통계정보상 카디널리티가 작은 값이 먼저 실행되기 때문에 결과가 보장되질 않는다.
따라서 10g에서 위와 같은 기법을 사용하려면 아래와 같이 ordered_predicates 힌트(4장 12절'(3) 조건절 비교 순서' 참조)를 사용하거나 no_cpu_costing 힌트를 이용해 I/O 비용 모델로 바꿔줘야 한다.
SQL> set autotrace traceonly
SQL> select /*+ ordered use_nl(r) index(r pk_cdr_rating) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and (r.국가코드, r.지역) =
6 (select /*+ use_concat(@subq 1) qb_name(subq) ordered_predicates */ c.국가코드, 지역
7 from cdr_rating
8 where 국가코드 = c.국가코드
9 and 지역 in (' ', c.지역)
10 and rownum <= 1) ;
14 개의 행이 선택되었습니다.
Execution Plan
----------------------------------------------------------
Plan hash value: 1842647818
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 42 | 15 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 42 | 15 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_CDR | 14 | 266 | 1 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| CDR_RATING | 1 | 23 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PK_CDR_RATING | 1 | | 0 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
| 6 | CONCATENATION | | | | | |
|* 7 | FILTER | | | | | |
|* 8 | INDEX UNIQUE SCAN | PK_CDR_RATING | 1 | 10 | 0 (0)| 00:00:01 |
|* 9 | FILTER | | | | | |
|* 10 | INDEX UNIQUE SCAN | PK_CDR_RATING | 1 | 10 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C"."통화시간" LIKE '20050315%')
filter("C"."통화시간" LIKE '20050315%')
4 - access(("R"."국가코드","R"."지역")= (SELECT /*+ USE_CONCAT (1) QB_NAME ("SUBQ") */
:B1,"지역" FROM "CDR_RATING" "CDR_RATING"???)
5 - filter(ROWNUM<=1)
7 - filter(ROWNUM<=1)
8 - access("국가코드"=:B1 AND "지역"=:B2)
9 - filter(ROWNUM<=1)
10 - access("국가코드"=:B1 AND "지역"=' ')
filter(LNNVL("지역"=:B1))
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
38 consistent gets
0 physical reads
0 redo size
907 bytes sent via SQL*Net to client
392 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
아래는 인덱스를 두 번 액세스하지 않고 서브쿼리에서 얻은 rowid로 테이블을 직접 액세스하도록 최종적으로 튜닝한 것이다.
SQL> select /*+ ordered use_nl(r) rowid(r) */
2 c.통화시간, c.국가코드, c.지역, r.요금
3 from cdr c, cdr_rating r
4 where c.통화시간 like '20050315%'
5 and r.rowid =
6 (select /*+ use_concat(@subq 1) qb_name(subq) ordered_predicates */ rowid
7 from cdr_rating
8 where 국가코드 = c.국가코드
9 and 지역 in (' ', c.지역)
10 and rownum <= 1
11 ) ;
14 개의 행이 선택되었습니다.
경 과: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 1791744221
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 88 | 15 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 168 | 7392 | 15 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_CDR | 14 | 266 | 1 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY USER ROWID| CDR_RATING | 12 | 300 | 1 (0)| 00:00:01 |
|* 4 | COUNT STOPKEY | | | | | |
| 5 | CONCATENATION | | | | | |
|* 6 | FILTER | | | | | |
|* 7 | INDEX UNIQUE SCAN | PK_CDR_RATING | 1 | 22 | 0 (0)| 00:00:01 |
|* 8 | FILTER | | | | | |
|* 9 | INDEX UNIQUE SCAN | PK_CDR_RATING | 1 | 22 | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C"."통화시간" LIKE '20050315%')
filter("C"."통화시간" LIKE '20050315%')
4 - filter(ROWNUM<=1)
6 - filter(ROWNUM<=1)
7 - access("국가코드"=:B1 AND "지역"=:B2)
8 - filter(ROWNUM<=1)
9 - access("국가코드"=:B1 AND "지역"=' ')
filter(LNNVL("지역"=:B1))
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
48 recursive calls
0 db block gets
92 consistent gets
0 physical reads
0 redo size
907 bytes sent via SQL*Net to client
392 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed