PLSQL 함수의 특징과 성능 부하 (by bshman) [2012.06.18]
PLSQL 함수의 특징과 성능 부하
(1)PL/SQL 함수의 특징
1. 인터프리터 언어다.
SQL> show parameter plsql
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
plsql_ccflags string
plsql_code_type string INTERPRETED
plsql_compiler_flags string INTERPRETED, NON_DEBUG
plsql_debug boolean FALSE
plsql_native_library_dir string
plsql_native_library_subdir_count integer 0
plsql_optimize_level integer 2
plsql_v2_compatibility boolean FALSE
plsql_warnings string DISABLE:ALL
2. Oracle Forms, Oracle Reports 같은 제품에서도 수행될 수 있도록 설계
3. PL/SQL엔진(가상머신, Virtual machine)만 있으면 어디서든 실행가능.
4. native 코드로 완전 컴파일된 내장 함수에 비해 많이 느리다.
5. 매번 SQL 실행엔진과 PL/SQL 가상머신 사이에 컨텍스트 스위칭이 일어난다.
h2.(2)Recursive Call을 포함하지 않는 함수의 성능 부하
| 내장함수 TO_CHAR와 사용자정의한 함수를 사용했을때 차이{code:sql} SQL> create or replace function data_to_char(p_Dt date) return varchar2 2 as 3 begin 4 return to_char(p_dt,'yyyy/mm/dd hh24:mi:ss'); 5 end; 6 / |
|---|
함수가 생성되었습니다.
SQL> create table t (no number, char_time varchar2(21));
테이블이 생성되었습니다.
경 과: 00:00:00.01
-- 내장함수사용
SQL> insert into t
2 select rownum no,
3 to_char(sysdate+rownum, 'yyyy/mm/dd hh24:mi:ss') char_time
4 from dual
5 connect by level <= 1000000;
1000000 개의 행이 만들어졌습니다.
경 과: 00:01:52.21
-- 사용자가만든 함수사용
SQL> insert into t
2 select rownum no,
3 data_to_char(sysdate+rownum) char_time
4 from dual
5 connect by level <= 1000000;
1000000 개의 행이 만들어졌습니다.
경 과: 00:03:27.40
h2.(3) Recursive Call를 포함 하는 함수의 성능 부하
|| select 문 삽입후 테스트 {code:sql}
- 책에 소스 오류있슴.
SQL> create or replace function date_to_char(p_dt date) return varchar2
2 as
3 l_empno number;
4 begin
5 select 1 into l_empno from dual;
6
7 return to_char(p_dt,'yyyy/mm/dd hh24:mi:ss');
8 end;
9 /
함수가 생성되었습니다.
경 과: 00:00:00.03
SQL> delete from t;
2000000 행이 삭제되었습니다.
경 과: 00:01:27.14
SQL> insert into t
2 select rownum no,
3 date_to_char(sysdate+rownum) char_time
4 from dual
5 connect by level <= 1000000;
1000000 개의 행이 만들어졌습니다.
경 과: 00:01:51.39
- 트레이스결과
SELECT 1
FROM
DUAL
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1000001 15.09 12.98 0 0 0 0
Fetch 1000000 10.64 8.73 0 0 0 1000000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2000002 25.73 21.71 0 0 0 1000000
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 73 (recursive depth: 1)
Rows Row Source Operation
------- ---------------------------------------------------
1000000 FAST DUAL (cr=0 pr=0 pw=0 time=6174443 us)
h2.(4) 함수를 필터 조건으로 사용할 때 주의 사항
| 함수를 where절에 필터조건으로 사용할때{code:sql} SQL> create or replace function emp_avg_sal return number 2 is 3 l_avg_sal number; 4 begin 5 select avg(sal) into l_avg_sal from emp; 6 7 return l_avg_sal; 8 end; 9 / |
|---|
함수가 생성되었습니다.
SQL> create index emp_x01 on emp(sal);
인덱스가 생성되었습니다.
SQL> create index emp_x02 on emp(deptno);
인덱스가 생성되었습니다.
SQL> create index emp_x03 on emp(deptno, sal);
인덱스가 생성되었습니다.
SQL> create index emp_x04 on emp(deptno, ename, sal);
인덱스가 생성되었습니다.
||<케이스1 : 인덱스를 사용하지 않고 Full Scan할때는 읽은 전체 건수만큼 함수호출> {code:sql}
select /*+ full(emp) */ * from emp
where sal >= emp_avg_sal
-------------------------------------
SELECT AVG(SAL)
FROM
EMP
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 15 0.01 0.02 0 0 0 0
Fetch 14 0.00 0.00 0 98 0 6
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 30 0.03 0.02 0 98 0 6
| <케이스 2 : 인덱스를 이용하도록 하면 함수호출이 한번일어난다.> {code:sql} select /*+ index(emp(sal)) */ * from emp where sal >= emp_avg_sal |
|---|
call count cpu elapsed disk query current rows
---
--
--
--
--
--
--
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 4 0 6
---
--
--
--
--
--
--
total 4 0.00 0.00 0 4 0 6
||<케이스 3 : 조건절에 deptno = 20 추가, exp_x02인덱스이용하여 조회> {code:sql}
SQL> select /*+ index(emp, emp_x02) */ * from emp
2 where sal >= emp_avg_sal <-- 필터링 건수 3건
3 and deptno =20;
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 37 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_X02 | 5 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SAL">="EMP_AVG_SAL"())
2 - access("DEPTNO"=20)
테이블액세스 하는 횟수만큼 5번 함수호출이 일어난걸 확인할수있다.
| <케이스 4 : deptno + sal 순으로 구성된 emp_x03 인덱스이용 {code:sql} SQL> select /*+ index(emp(deptno, sal) */ * from emp 2 where sal >= emp_avg_sal 3 and deptno =20; |
|---|
---
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
---
| 0 | SELECT STATEMENT | 1 | 37 | 2 (0) | 00:00:01 | |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 37 | 2 (0) | 00:00:01 |
| INDEX RANGE SCAN | EMP_X03 | 1 | 1 (0) | 00:00:01 |
---
Predicate Information (identified by operation id):
---
2 - access("DEPTNO"=20 AND "SAL">="EMP_AVG_SAL"() AND "SAL" IS NOT NULL)
sal >= 까지 조건까지 인덱스 조건으로 사용으로 함수호출이 한번 일어난걸확인
||<케이스 5 : 조건은 같고, deptno 와 sal 컬럼중간인 ename 컬럼이 낀 emp_x04 인덱스사용 {code:sql}
SQL> select /*+ index(emp(deptno, ename, sal)) */ * from emp
2 where sal >= emp_avg_sal
3 and deptno =20;
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 37 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_X04 | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=20 AND "SAL">="EMP_AVG_SAL"())
filter("SAL">="EMP_AVG_SAL"())
첫번째 액세스 단계에서 1번
필터 단계에서 나머지 4건을 찾는동안 4번 , deptno = 20 범위를 넘어 더이상 조건을 만족하는 레코드가
없음을 확인하는 one-plus 스캔과정에서 1번, 하여 총6번의 함수 호출이 일어난다고 하는데 1번만 발생.
| <케이스 6 : = 조건이 아닌경우 {code:sql} SQL> select /*+ index(emp(deptno, sal)) */ * from emp 2 where sal >= emp_avg_sal 3 and deptno >=10; |
|---|
---
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
---
| 0 | SELECT STATEMENT | 1 | 37 | 2 (0) | 00:00:01 | |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 1 | 37 | 2 (0) | 00:00:01 |
| INDEX RANGE SCAN | EMP_X03 | 1 | 1 (0) | 00:00:01 |
---
Predicate Information (identified by operation id):
---
2 - access("DEPTNO">=10 AND "SAL">="EMP_AVG_SAL"() AND "DEPTNO" IS NOT NULL)
filter("SAL">="EMP_AVG_SAL"())
인덱스 스캔할 첫 번째 레코드를 액세스하는 단계에서 1번
deptno >= 10 조건을 만족하는 나머지 13건을 스캔하는 동안 13번
하여 총 14번 스캔이 말생한다고 하는데 테스트 결과는 한번만 나왔다.
- 대용량테이블에서 조건절과 인덱스 구성에 따라 성능 차이가 매우 크게나타날 수 있음을 확인할수있다.
h2.(5) 함수와 읽기 일관성
{code:sql}
SQL> create table lookuptable(key number, value varchar2(100));
테이블이 생성되었습니다.
SQL> insert into lookuptable values (1, 'BSHMAN');
1 개의 행이 만들어졌습니다.
SQL> commit;
커밋이 완료되었습니다.
SQL> create or replace function lookup(l_input number) return varchar2
2 as
3 l_output lookuptable.value%TYPE;
4 begin
5 select value into l_output from lookuptable where key = l_input;
6 return l_output;
7 end;
8 /
함수가 생성되었습니다.
SQL> update lookuptable
2 set value ='BSH';
1 행이 갱신되었습니다.
SQL> commit;
커밋이 완료되었습니다.
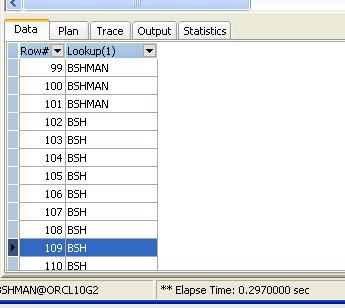
(6) 함수의 올바른 사용 기준
적당히 알아서 잘써야한다.(때와 장소를 맞쳐서 개발자님이 만들어주세요,)
뒷장에서 나오겟지만, 개발자입장에서는 함수하나로 모든걸 컨트롤할수있는걸
속도때문에 개발의 효율성을 떨어트리는 일이 발생되므로 좀 계륵이지 않을수없다.