SQL 처리과정 (by nav012) [2012.05.11]
SQL 처리 과정
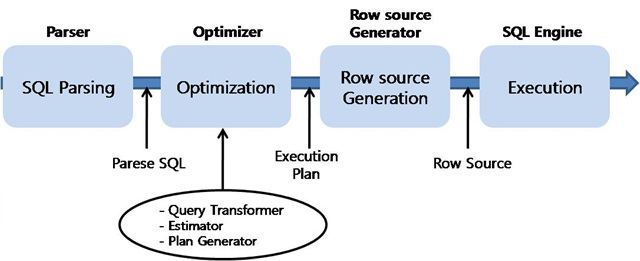
1. SQL 처리 과정을 요약하면 아래와 같다.
- SQL 문을 실행
- SQL Parsing
- SQL 이 메모리(Libeary cache) 에 있는지 확인
--> 있으면 : 바로 실행
--> 없으면 : 최적화 > Row 소스 생성 > 실행
SQL> alter session set events '10046 trace name context forever, level 12';
SQL> exit
[TEST10]clt585av13:/lim/admin/TEST10/udump> tkprof test10_ora_18030.trc
output = lc_test
TKPROF: Release 10.2.0.4.0 - Production on Sat May 12 02:28:52 2012
Copyright (c) 1982, 2007, Oracle. All rights reserved.
[TEST10]clt585av13:/lim/admin/TEST10/udump> vi lc_test
********************************************************************************
SQL> select * from TAX_TAB where rownum <3;
select *
from
TAX_TAB where rownum <3
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 1 3 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.00 0.00 1 3 0 0
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 124
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
SQL*Net more data to client 1 0.00 0.00
db file sequential read 1 0.00 0.00
********************************************************************************
- Misses in library cache during parse - 라이브러리 캐시에서 찾지 못한(miss) 횟수
- Parse call - sql parse 횟수
--> SQL 첫 수행시만 Libeary cache 에서 정보를 찾지 못해 SQL 을 캐싱
--> 이후 파스 시에는 Libeary cache 에 있는 SQL Object 재 사용
2. SQL 실행단계 상세 과정
- Parse 시 거치는 단계
1) SQL Parser
- 사용자가 전달 한 SQL 을 가장 먼저 받아서 처리하는 엔진
- SQL 구성 요소 분석, 파싱하여 파싱 트리 생성
- Syntax 체크 - SQL 문법 오류 없는지 (SELECT TO_DATE('12/05/12', 'YYYY/MM/DD') FROM DUAL;)
- Semantic 체크 - SQL 의 의미상 오류 없는지 (권한 없는 요청, 존재하지 않는 테이블 참조)
- SQL 이 Shared Pool에 캐싱되어 있는지 확인
- SQL 이 있으면 기존 SQL 커서 재 사용 하여 바로 실행 단계로 이동(Soft Parse)
SQL 문장이 없거나,
SQL 문장이 LC 안에 일치하더라도 Parshing Schema 가 다르거나,
ex) SCOTT.EMP Table 과 HR.EMP Table 이 공존 할 경우
Select * from EMP; 를 SCOTT 이 수행했는지 HR 이 수행 했는지에 따라 달라짐
옵티마이저 관련 설정(Parameter 등) 이 다르면
새로운 SQL 커서 생성을 위해 SQL Parser 는 옵티마이저에게 다음 수행 단계를 넘긴다
2) Otimizer
- 시스템 통계, Object 통계정보 기반으로 수행 경로 비교하여 가장 효율적 실행 계획 선택 해 주는 엔진
- 3가지 SUB 엔진을 가지고 있다
Query Transformer 트랜스포머
SQL 최적화 하기 쉬운 형태로 변환
Plan Generator
실행계획 후보군 생성
Estimator
수행 각 단계의 선택도, 카디널리티, 비용 고려하여 수행 시 드는 총 비용 계산
오브젝트 통계 정보, 시스템 성능 통계, 메모리, CPU, Single block read time, Multiblock read time 등등 이용
- 짧은 시간 안에 모든 경우의 수를 만들어 내고 비용 계산 하는 것은 힘들다
h6 적응적 탐색 전략(Adaptive Search Stratigy) 사용
최적화 시간/총 수행 예상 시간 이 일정 비율 넘지 안토록
최적의 수행 계획이 될 가능성이 있는 것부터 순서대로 비용 계산
3) Row Source Generation
- 최적화 거친 개념적인 실행계획을 실재 수행 가능한 코드 프로시져 형태로 변환
3. 결론은...
- 위 과정을 모두 거쳐야 하므로 하드 파싱은 비용 소모가 큰 작업이다 - 특히 CPU
- Shared Pool 및 Library cache 에 발생하는 래치도 CPU소모를 높인다
- Hard Parse 수행 시 마다 데이터 딕셔너리 조회도 많이 한다
- --> 한번 파스해서 만들어 놓은 커서는 재 사용 할 수록 이익이다