2.3.5 세미조인 (by oracleclub) [2011.10.07]
http://www.ssiso.net/cafe/club/club1/board1/content.php?board_code=oracle%7Cexora&idx=31520&club=oracle&cp=1&cb=1&search=&search_word
http://ukja.tistory.com/141
http://scidb.tistory.com/79
http://scidb.tistory.com/entry/SubQuery-Using-Method-1
http://scidb.tistory.com/entry/Hash-Join-Right-SemiAntiOuter-의-용도
http://scidb.tistory.com/search/Early%20Filter%20서브쿼리
2.3.5 세미(Semi) 조인
- 세미조인이란? 말 그대로 조인과 유사한 데이타 연결( 서브쿼리를 사용했을 때 메인 쿼리와 연결하는 처리를 의미 )
2.3.5.1 세미 조인의 개념 및 특징
세미 조인의 개념.?
- 세미 조인이란 말은 본래 분산질의를 효율적으로 수행하기 위하여 도입된 개념이다.
- 분산질의 : 두 테이블 간에 조인을 할 때 한 테이블을 다른 사이트에 전송하기 전에 먼저 조인에 필요한 속성만을 추출(프로젝션)하여 전송한 후
조인에 성공한 로우의 집합만을 다시 전송함으로써 네트워크를 통해 전송되는 데이터의 양을 줄이고자 하는 개념으로 도입
| 분산질의 |
|---|
| {CODE:SQL} – Mgr : M 사이트 – Emp : E 사이트 |
SELECT mgr.name, emp.name
FROM mgr, emp
WHERE mgr.sal < emp.sal;
| {CODE} 1 : M 사이트에서 SELECT sal FROM mgr 질의문을 수행한다 2 : 조인 속성만 추출( Projection) 하여 E 사이트로 전송하고 이를 mgrP라고 하자 3 : E 사이트에서 SELECT name, sal FROM emp WHERE sal > mgrP.sal를 수행한다. 4 : 3의 결과를 상대적으로 작은 양일 것이고 이를 M 사이트로 전송한다. |
여기서 설명하는 세미조인?
- 분산질의의 효율적인 수행을 위해 수행하는 협의의 조인만을 말하는 것이 X
- 주로 서브쿼리르 사용했을 때 메인 쿼리와의 연결을 하기 위해 적용되는 광범위한 유사 조인을 의미하고 있다.
조인된 결과 집합의 차이
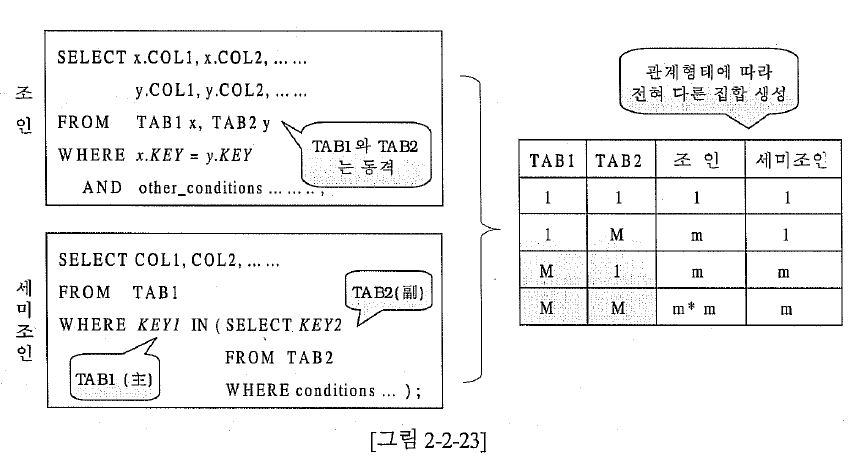
- 조인 : 수학적 곱셈 연산관 유사함
- 세미조인 : 언제나 메인쿼리의 집합과 동일함.
2.3.5.2 세미조인의 실행 계획
- 원리적인 측면에서 볼 때는 결코 일반적인 조인의 범주를 벗어 나지 않는다고 하였다.
그렇다면 결국 가장 보편적인 조인이 Nested Loops 조인이었듯이 세미 조인에서도 대부분의 경우는 Nested Loops조인과 매우 유사하게 처리된다는 것을 뜻한다.
가) Nested Loop형 세미조인
- 제공자 : 서브쿼리가 먼저 수행되어 SELECT-List의 견결고리 값을 상수값으로 만들고, 이것을 메인쿼리 연결고리에 대응시키는 방법
- 확인자 : 메인쿼리가 먼저 수행되어 상수값이 된 연결고리 값을 서브쿼리의 연결고리( 서브쿼리 SELECT-List에 있는 컬럼 )에 제공하는 방법
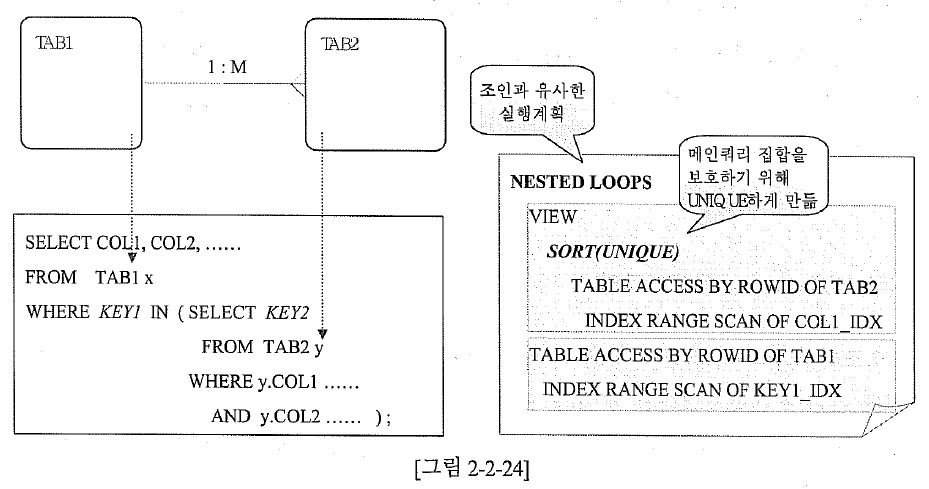
| 그림 2-2-24 준비스크립트 |
|---|
| {CODE:SQL} |
11:45:32 SQL> SELECT * FROM V$VERSION WHERE ROWNUM <= 1;
BANNER
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bi
DROP TABLE TAB1 PURGE;
DROP TABLE TAB2 PURGE;
CREATE TABLE TAB1 AS
SELECT LEVEL KEY1
, '상품'||LEVEL COL1
, TRUNC( dbms_random.value( 1,7 ) ) * 500 + TRUNC( dbms_random.value( 1,3 ) ) * 750 COL2
FROM DUAL
CONNECT BY LEVEL <= 10000;
CREATE TABLE TAB2 AS
SELECT LEVEL KEY1
, TRUNC(dbms_random.value( 1, 10000 ) ) KEY2
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 1000 ) COL1
, 'A' COL2
FROM DUAL
CONNECT BY LEVEL <= 100000;
CREATE INDEX KEY1_IDX ON TAB1( KEY1 );
CREATE INDEX COL1_IDX01 ON TAB2( COL1, COL2 );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB1' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB2' );
SQL> DESC TAB2;
이름 널? 유형
-
-
KEY1 NUMBER
KEY2 NUMBER
COL1 DATE
COL2 CHAR(1)
SQL> SELECT /*+ gather_plan_statistics */ COUNT( DISTINCT KEY2 )
2 FROM TAB2 A
3 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
4 AND COL2 = 'A';
COUNT(DISTINCTKEY2)
---
1810
경 과: 00:00:00.02
SQL> @xplan
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | SORT GROUP BY | 1 | 1 | 1 | 00:00:00.01 | 15 | 83968 | 83968 | 73728 (0) | |
| FILTER | 1 | 2000 | 00:00:00.01 | 15 | |||||
| 3 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 |
-
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
4 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
| {CODE} |
| NO_HINT 옵티마이져가 서브쿼리를 조인으로 변형시킴 ( 그림 2-2-24 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT KEY2
4 FROM TAB2 B
5 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND COL2 = 'A' ) ;
COUNT(*)
--
1810
경 과: 00:00:00.02
SQL> @xplan
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 41 | ||||
| FILTER | 1 | 1810 | 00:00:00.01 | 41 | |||||
| HASH JOIN RIGHT SEMI | 1 | 1830 | 1810 | 00:00:00.01 | 41 | 1517K | 1517K | 1277K (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 | 00:00:00.01 | 26 |
--
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
| {CODE} * HASH JOIN SEMI ( Semi/Anti/Outer ) : Oracle 10g * Semi/Anti Join의 단점을 보안 * Semi/Anti Join의 단점.? Semi/Anti Join의 경우 서브쿼리는 항상 후행집합이 될수 밖에 없다. Hash Outer Join의 경우도 마찬가지로(+) 표시가 붙는 쪽의 집합은 항상 후행집합이 될 수 밖에 없다. 하지만 10g 부터 Hash join Right( Semi/Anti/Outer ) 기능이 나오게 되면서 서브쿼리 혹은 아우터 Join 되는쪽의 집합이 선행집합이 될 수 있다. * Right.? left 집합 대신에 right( 후행집합 )을 선행집합으로 하겠다는 뜻이다. |
| HASH JOIN RIGHT SEMI을 힌트로 유도하는 법( 그림 2-2-24 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ HASH_SJ */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
--
1810
경 과: 00:00:00.01
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 40 | ||||
| FILTER | 1 | 1810 | 00:00:00.01 | 40 | |||||
| HASH JOIN RIGHT SEMI | 1 | 1830 | 1810 | 00:00:00.01 | 40 | 1517K | 1517K | 1274K (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 | 00:00:00.01 | 25 |
--
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
| {CODE} |
| UNNEST 유도( 그림 2-2-24 ) : ㅠㅠ 쿼리 블럭명을 지정해야것군. ( 제공자 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ UNNEST */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
--
1810
경 과: 00:00:00.01
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 41 | ||||
| FILTER | 1 | 1810 | 00:00:00.01 | 41 | |||||
| HASH JOIN RIGHT SEMI | 1 | 1830 | 1810 | 00:00:00.01 | 41 | 1517K | 1517K | 1552K (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 | 00:00:00.01 | 26 |
--
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
| {CODE} |
| UNNEST 유도( 그림 2-2-24 ) : 옵티마이져가 서브쿼리를 조인으로 변형시킴 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics UNNEST( @SUB ) */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB )*/ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
--
1810
경 과: 00:00:00.01
SQL> @XPLAN
– KEY1_IDX 인덱스가 유니크인덱스가 아니라서 패스트 풀스켄으로 옵티마이져 선택해서 해쉬로 풀리는 듯.
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 41 | ||||
| FILTER | 1 | 1810 | 00:00:00.01 | 41 | |||||
| HASH JOIN | 1 | 2000 | 1810 | 00:00:00.01 | 41 | 1517K | 1517K | 1292K (0) | |
| 4 | SORT UNIQUE | 1 | 2000 | 1810 | 00:00:00.01 | 15 | 83968 | 83968 | 73728 (0) | |
| 5 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| 7 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 | 00:00:00.01 | 26 |
---
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
| {CODE} * Unnesting 서브쿼리 : 옵티마이져가 서브 쿼리를 조인으로 변형시킴 * 서브쿼리를 조인으로 바꾸는 방식 ( 일반적으로 서브쿼리의 테이블이 Driving이된다. ) * 오라클은 서브쿼리를 인라뷰로 바꾸고 서브쿼리 집합이 DISTINCT하지 않을 경우 Sort Unique나 Hash Unique작업을 추가로 진행한다. * 힌트 : 유도 힌트 : /*+ unnest */ ( 서브쿼리에 사용하거나 메인 쿼리에서 쿼리 블럭 힌트( qb_name )를 사용하여야 한다. ) 방지 힌트 : /*+ no_unnest */ ( 서브쿼리에 사용 ) |
| DROP INDEX KEY1_IDX ( KEY1_IDX 인덱스가 유니크인덱스가 아니라서 패스트 풀스켄으로 옵티마이져 선택해서 해쉬로 풀리는 듯.) |
|---|
| {CODE:SQL} |
DROP INDEX KEY1_IDX
CREATE UNIQUE INDEX KEY1_IDX ON TAB1( KEY1 )
| {CODE} |
| UNNEST 유도( 그림 2-2-24 ) ^^ |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics UNNEST( @SUB )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB ) */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
--
1810
경 과: 00:00:00.01
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 1827 | ||||
| FILTER | 1 | 1810 | 00:00:00.01 | 1827 | |||||
| 3 | NESTED LOOPS | 1 | 2000 | 1810 | 00:00:00.01 | 1827 | ||||
| 4 | SORT UNIQUE | 1 | 2000 | 1810 | 00:00:00.01 | 15 | 83968 | 83968 | 73728 (0) | |
| 5 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| INDEX UNIQUE SCAN | KEY1_IDX | 1810 | 1 | 1810 | 00:00:00.01 | 1812 |
---
Predicate Information (identified by operation id):
---
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
7 - access("KEY1"="KEY2")
| {CODE} |
| 옵티마이져가 변형한쿼리 |
|---|
| {CODE:SQL} SQL> SELECT /*+ gather_plan_statistics LEADING( B A ) USE_NL( A B ) / COUNT() 2 FROM TAB1 A 3 , (SELECT DISTINCT KEY2 4 FROM TAB2 B 5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) 6 AND B.COL2 = 'A' ) B 7 WHERE A.KEY1 = B.KEY2; |
COUNT(*)
--
1810
경 과: 00:00:00.01
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 1827 | |
| 2 | NESTED LOOPS | 1 | 1829 | 1810 | 00:00:00.01 | 1827 | |
| 3 | VIEW | 1 | 1829 | 1810 | 00:00:00.01 | 15 | |
| 4 | HASH UNIQUE | 1 | 1829 | 1810 | 00:00:00.01 | 15 | |
| FILTER | 1 | 2000 | 00:00:00.01 | 15 | ||
| 6 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 |
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 |
| INDEX UNIQUE SCAN | KEY1_IDX | 1810 | 1 | 1810 | 00:00:00.01 | 1812 |
-
Predicate Information (identified by operation id):
---
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
7 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
8 - access("A"."KEY1"="B"."KEY2")
| {CODE} | NO_UNNEST ( Filter 서브쿼리 : 쿼리 변형없음 ) |
|---|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
--
1801
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:12.22 | 138K | |
| FILTER | 1 | 1801 | 00:00:13.86 | 138K | ||
| 3 | TABLE ACCESS FULL | TAB1 | 1 | 10000 | 10000 | 00:00:00.01 | 33 |
| FILTER | 10000 | 1801 | 00:00:12.21 | 138K | ||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 10000 | 1 | 1801 | 00:00:12.18 | 138K |
| INDEX SKIP SCAN | COL1_IDX01 | 10000 | 46 | 18M | 00:00:00.09 | 74061 |
---
Predicate Information (identified by operation id):
---
2 - filter( IS NOT NULL)
4 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
5 - filter("KEY2"=:B1)
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND
"B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
| {CODE} * Filter 서브쿼리 : 쿼리변형이 없음 * 흔히 말하는 확인자 서브쿼리임.( 메인쿼리의 값을 제공받아 서브쿼리에서 체크하는 방식임 * 위의 1번 2번과 다르게 Plan에 메인 쿼리와 서브쿼리의 Join이 없고 Filter 로 나온다. * Filter SubQuery의 특징은 메인쿼리의 From 절에 있는 모든 테이블을 엑세스후에 가장 마지막에 서브쿼리가 실행된다. * 힌트: 특별한 힌트없음 다만 /*+ no_unnest */ 를 사용하여 SubQuery Flattening 을 방지하고 메인쿼리로부터 제공되는 서브쿼리의 조인컬럼에 인덱스가 생성되어 있으면됨. |
| 바로 위 쿼리 플렌 보충 쿼리들.. |
|---|
| {CODE:SQL} 바로 위 쿼리 플렌 보충 쿼리 1 SQL> SELECT /*+ gather_plan_statistics */ KEY1 2 FROM TAB1 A 3 WHERE KEY1 = 1 4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2 5 FROM TAB2 B 6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) 7 AND B.COL2 = 'A' 8 ) ; |
KEY1
--
1
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--
| INDEX UNIQUE SCAN | KEY1_IDX | 1 | 1 | 1 | 00:00:00.01 | 15 |
| FILTER | 1 | 1 | 00:00:00.01 | 13 | ||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 1 | 1 | 00:00:00.01 | 13 |
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 46 | 1685 | 00:00:00.01 | 7 |
--
--바로 위 쿼리 플렌 보충 쿼리 2
SQL> SELECT /*+ gather_plan_statistics */ KEY1
2 FROM TAB1 A
3 WHERE KEY1 = 2
4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
5 FROM TAB2 B
6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
7 AND B.COL2 = 'A'
8 ) ;
KEY1
--
2
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--
| INDEX UNIQUE SCAN | KEY1_IDX | 1 | 1 | 1 | 00:00:00.01 | 15 |
| FILTER | 1 | 1 | 00:00:00.01 | 13 | ||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 1 | 1 | 00:00:00.01 | 13 |
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 46 | 1745 | 00:00:00.01 | 7 |
--
--바로 위 쿼리 플렌 보충 쿼리 3
SQL> SELECT /*+ gather_plan_statistics */ KEY1
2 FROM TAB1 A
3 WHERE KEY1 IN ( 1, 2 )
4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
5 FROM TAB2 B
6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
7 AND B.COL2 = 'A'
8 ) ;
KEY1
--
1
2
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---
| 1 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 31 | ||
| INDEX RANGE SCAN | KEY1_IDX | 2 | 1 | 2 | 00:00:00.01 | 31 |
| FILTER | 2 | 2 | 00:00:00.01 | 26 | ||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 2 | 1 | 2 | 00:00:00.01 | 26 |
| INDEX SKIP SCAN | COL1_IDX01 | 2 | 46 | 3430 | 00:00:00.01 | 14 |
---
| {CODE} | 다른 방법은 없는가.? Driving Semi Join |
|---|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics SEMIJOIN_DRIVER(@SUB) */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB )* */ KEY2
4 FROM TAB2 B
5 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND COL2 = 'A' ) ;
COUNT(*)
--
1810
경 과: 00:00:00.02
SQL> @xplan
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.02 | 2020 | ||||
| 2 | BITMAP CONVERSION COUNT | 1 | 2000 | 1 | 00:00:00.02 | 2020 | ||||
| 3 | BITMAP MERGE | 1 | 1 | 00:00:00.02 | 2020 | 1024K | 512K | 416K (0) | ||
| 4 | BITMAP KEY ITERATION | 1 | 2000 | 00:00:00.02 | 2020 | |||||
| FILTER | 1 | 2000 | 00:00:00.01 | 15 | |||||
| 6 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.01 | 15 | |||
| INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 | 00:00:00.01 | 8 | |||
| 8 | BITMAP CONVERSION FROM ROWIDS | 2000 | 2000 | 00:00:00.01 | 2005 | |||||
| INDEX RANGE SCAN | KEY1_IDX | 2000 | 2000 | 00:00:00.01 | 2005 |
-
Predicate Information (identified by operation id):
---
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
7 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
9 - access("KEY1"="KEY2")
| {CODE} * Semi Join의 변형된 형태로서 Hash Join의 장점( 조인건수의 최소화 )과 Nested Loop Join의 장점( 성행테이블의 상수화 되어 후행 테이블에서 인덱스를 효율적으로 사용)을 합친 개념이다. * Driving Semi Join이라는 Title 자체의 의미대로 Semi Join이 Driving집합이 되는것은 당연하다. * BITMAP KEY ITERATION : INLIST ITERATOR Operation 같다고 볼수있다. * _b_tree_bitmap_plans = true * Oracle 9i이상 * 오라클 정식 힌트가 아님( ㄷㄷ ) |
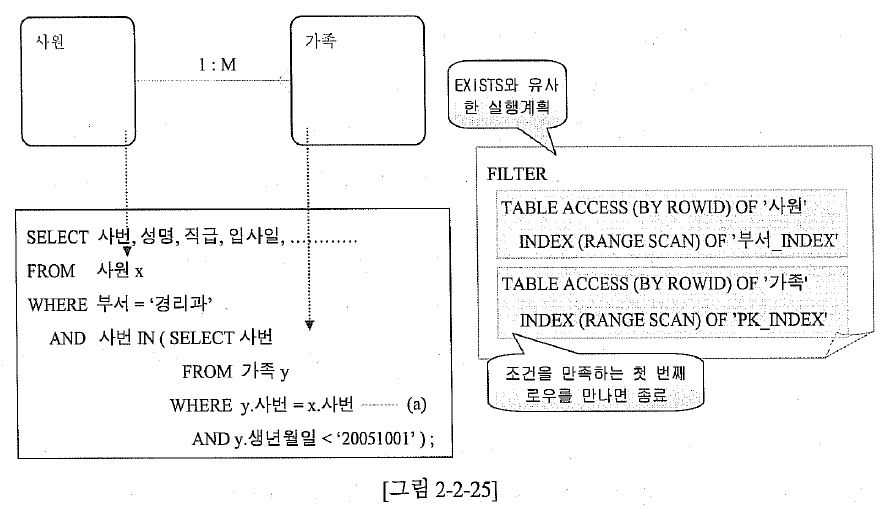
| 그림 2-2-25 준비스크립트 |
|---|
| {CODE:SQL} |
DROP TABLE 사원 PURGE;
DROP TABLE 가족 PURGE;
CREATE TABLE 사원 AS
SELECT LEVEL AS 사번
, '아무개'||LEVEL AS 성명
, TRUNC( dbms_random.value( 1,7 ) ) 직급
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 10000 ) 입사일
, DECODE( TRUNC( dbms_random.value( 1,32 ) ), 1, 'DB1팀', 2, 'DB2팀', 3, 'DB3팀'
, 4, '시스템1팀', 5, '시스템2팀', 6, '시스템3팀'
, 7, '경리1과', 8, '경리2과', 9, '경리3과', 10, '경리과', 11, '경리4과'
, 12, '개발1팀', 13, '개발2팀', 14, '개발3팀', 15, '개발4팀', 16, '개발5팀', 17, '개발6팀'
, 18, 'MD1팀', 19, 'MD2팀', 20, 'MD3팀', 21, 'MD4팀'
, 22, '디자인1팀', 23, '디자인2팀', 24, '디자인3팀', 25, '디자인4팀'
, 26, '멀티미디어1팀', 27, '멀티미디어2팀', 28, '멀티미디어3팀'
, 29, '모바일1팀'
, 30, '웹모바일팀'
, 31, '마케팅팀'
, 32, '기획팀' ) 부서
FROM DUAL
CONNECT BY LEVEL <= 1000000
CREATE TABLE 가족 AS
SELECT 사번, LV 가족번호, '아무개'||LV 성명
, '19'|| TRUNC( dbms_random.value( 50,110 ) )|| TO_CHAR( TRUNC( dbms_random.value( 1,12 ) ), 'FM09' )|| TO_CHAR( TRUNC( dbms_random.value( 1,28 ) ), 'FM09' ) 생년월일
FROM 사원 A
, (SELECT LEVEL LV FROM DUAL CONNECT BY LEVEL <= 10 ) B
WHERE A.직급 >= B.LV
CREATE INDEX 부서_INDEX ON 사원 ( 부서, 사번 )
CREATE UNIQUE INDEX PK_INDEX ON 가족 ( 사번, 가족번호 )
SQL> SELECT 부서, COUNT(*)
2 FROM 사원
3 GROUP BY 부서
4 ;
부서 COUNT(*)
-
--
멀티미디어1팀 31437
시스템2팀 31200
개발4팀 31232
시스템3팀 31172
DB3팀 30931
MD3팀 30972
경리1과 31134
개발1팀 31243
웹모바일팀 31341
개발2팀 31302
모바일1팀 31425
부서 COUNT(*)
-
--
경리3과 31263
개발3팀 31554
기획팀 31291
경리2과 31012
MD1팀 31160
DB2팀 31518
디자인2팀 31272
멀티미디어2팀 31276
경리4과 31075
개발5팀 31409
개발6팀 31425
부서 COUNT(*)
-
--
DB1팀 31310
디자인1팀 31094
멀티미디어3팀 31227
시스템1팀 31249
디자인3팀 31237
마케팅팀 31364
경리과 31346
MD2팀 31126
MD4팀 31113
디자인4팀 31290
32 개의 행이 선택되었습니다.
경 과: 00:00:00.38
SQL>
| {CODE} | 그림 2-2-25 실행 |
|---|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics / COUNT()
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
--
30828
SQL> @xplan
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.69 | 14633 | 9632 | ||||
| HASH JOIN SEMI | 1 | 26199 | 30828 | 00:00:00.40 | 14633 | 9632 | 1935K | 1935K | 2195K (0) | |
| INDEX RANGE SCAN | 부서_INDE | 1 | 26199 | 31346 | 00:00:00.01 | 103 | 0 | |||
| TABLE ACCESS FULL | 가족 | 1 | 2901K | 3175K | 00:00:00.02 | 14530 | 9632 |
--
Predicate Information (identified by operation id):
---
2 - access("사번"="사번")
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
| {CODE} |
| 너 왜 인덱스 안타냐?? 더 고비용이냐?? ㅠ( 음.. NL 더 고비용이군 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics / COUNT()
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ INDEX( Y PK_INDEX ) */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
--
30828
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.35 | 96727 | 17 | |
| 2 | NESTED LOOPS SEMI | 1 | 26199 | 30828 | 00:00:00.34 | 96727 | 17 | |
| INDEX RANGE SCAN | 부서_INDE | 1 | 26199 | 31346 | 00:00:00.01 | 103 | 0 |
| TABLE ACCESS BY INDEX ROWID | 가족 | 31346 | 2901K | 30828 | 00:00:00.31 | 96624 | 17 |
| INDEX RANGE SCAN | PK_INDEX | 31346 | 1 | 33915 | 00:00:00.15 | 62709 | 15 |
-
Predicate Information (identified by operation id):
---
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
5 - access("사번"="사번")
| {CODE} * 서브쿼리 내에 메인 쿼리의 컬럼이 존재 한는것은 곧 종속성을 의미한다. ( 이 서브쿼리는 논리적으로 절대 먼저 수행 될 수 없도록 종속되었다는 것이다. * 위 쿼리는 잘못된 SQL이다. 왜? (a)라인을 삭제하면 연결이 안 될 것이라고 생각 |
| 음.. (a)을 배재함.. ( 으흠.. ) |
|---|
| {CODE:SQL} SQL> SELECT /*+ gather_plan_statistics LEADING( @SUB ) / COUNT() 2 FROM 사원 X 3 WHERE 부서 = '경리과' 4 AND 사번 IN (SELECT /*+ QB_NAME( SUB ) */ 사번 5 FROM 가족 Y 6 WHERE 1 = 1 --Y.사번 = X.사번 --(a) 7 AND Y.생년월일 < '20051001' ); |
COUNT(*)
--
30828
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.61 | 14633 | ||||
| HASH JOIN SEMI | 1 | 26199 | 30828 | 00:00:00.35 | 14633 | 1935K | 1935K | 2187K (0) | |
| INDEX RANGE SCAN | 부서_INDE | 1 | 26199 | 31346 | 00:00:00.01 | 103 | |||
| TABLE ACCESS FULL | 가족 | 1 | 2901K | 3175K | 00:00:00.01 | 14530 |
-
Predicate Information (identified by operation id):
---
2 - access("사번"="사번")
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
| {CODE} | 강제로 해쉬 조인 라이트 세미는 못푸는 것인가.?? |
|---|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) / COUNT()
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ QB_NAME( SUB ) */ 사번
5 FROM 가족 Y
6 WHERE 1 = 1 --Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
--
30828
SQL> @xplan
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:01:38.58 | 14633 | 12586 | 4371 | |||||
| HASH JOIN RIGHT SEMI | 1 | 26199 | 30828 | 00:01:38.20 | 14633 | 12586 | 4371 | 84M | 7739K | 111M (1) | 39936 | |
| TABLE ACCESS FULL | 가족 | 1 | 2901K | 3175K | 00:01:22.56 | 14530 | 8215 | 0 | ||||
| INDEX RANGE SCAN | 부서_INDE | 1 | 26199 | 31346 | 00:00:00.01 | 103 | 0 | 0 |
---
Predicate Information (identified by operation id):
---
2 - access("사번"="사번")
3 - filter("Y"."생년월일"<'20051001')
4 - access("부서"='경리과')
| {CODE} |
| ( 참고 ) Early Filter 서브쿼리 제공자 쿼리로 보이지만 확인자 쿼리라고함. |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics / COUNT()
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ NO_UNNEST PUSH_SUBQ */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
--
30828
경 과: 00:00:00.37
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.35 | 128K | |
| INDEX RANGE SCAN | 부서_INDE | 1 | 1310 | 30828 | 00:00:00.34 | 128K |
| TABLE ACCESS BY INDEX ROWID | 가족 | 31346 | 29019 | 30828 | 00:00:00.30 | 127K |
| INDEX RANGE SCAN | PK_INDEX | 31346 | 12806 | 33915 | 00:00:00.14 | 94053 |
Predicate Information (identified by operation id):
---
2 - access("부서"='경리과')
filter( IS NOT NULL)
3 - filter("Y"."생년월일"<'20051001')
4 - access("사번"=:B1)
| {CODE} * Early Filter 서브쿼리 : 쿼리변형 없음 * Filter SubQuery와 같은 방식이지만 서브 쿼리를 최대한먼저 실행하여 데이터를 걸러낸다. * 힌트 : 메인 쿼리에 push_subq 힌트사용 ( 10g 이후부터는 서브쿼리에 힌트사용해야함 ) * 주의사항 : 많은 튜닝책에서 "Push_subq 힌트를 사용하면 제공자 서브쿼리를 유도한다" 라고 되어 있으나 이는 잘못된 것이다. push_subq힌트를 사용하면 확인자 서브쿼리( Filter 서브쿼리)를 유도하지만 최대한 먼저 수행한다. * Early Filter 서브쿼리 효과는 최소 메인 절에 두가지 테이블이 존재 해야만 눈으로 확인 할수있다. * http://scidb.tistory.com/entry/SubQuery-Using-Method-1 * http://scidb.tistory.com/entry/Using-sub-query-method-Filter-Access-sub-Query |
| 그림 2-2-25 ( 위 쿼리가 정말 Early Filter 서브쿼리인가? ( 솔까 잘모르지만.. 테스트 결과 맞는거 같다. ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics / COUNT()
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ NO_UNNEST NO_PUSH_SUBQ */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
--
30828
경 과: 00:00:00.37
SQL> @XPLAN
Plan hash value: 2622244588
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.36 | 128K | |
| FILTER | 1 | 30828 | 00:00:00.37 | 128K | ||
| INDEX RANGE SCAN | 부서_INDE | 1 | 26199 | 31346 | 00:00:00.01 | 103 |
| TABLE ACCESS BY INDEX ROWID | 가족 | 31346 | 29019 | 30828 | 00:00:00.30 | 127K |
| INDEX RANGE SCAN | PK_INDEX | 31346 | 12806 | 33915 | 00:00:00.14 | 94053 |
Predicate Information (identified by operation id):
---
2 - filter( IS NOT NULL)
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
5 - access("사번"=:B1)
| {CODE} |
막연하게 연결고리가 많으면 많을수록 유리할거라는 어느 통신사 사례
| 준비 스크립트 |
|---|
| {CODE:SQL} |
CREATE TABLE 고객 AS
SELECT LEVEL 고객번호
, LEVEL 납입자
FROM DUAL
CONNECT BY LEVEL <= 1000000; --100만건
CREATE TABLE 청구 AS
SELECT B.고객번호
, A.청구년월
, 0 입금액
FROM (SELECT '2005'||TO_CHAR( LEVEL , 'FM09' ) 청구년월
FROM DUAL
CONNECT BY LEVEL <= 12 ) A
, ( SELECT * FROM 고객 ) B --1200만건
CREATE INDEX 고객_INDEX01 ON 고객( 납입자 );
CREATE INDEX 청구_INDEX01 ON 청구( 고객번호, 청구년월 );
CREATE INDEX 청구_INDEX02 ON 청구( 청구년월, 고객번호 );
SQL> SELECT *
2 FROM 고객
3 WHERE 납입자 = 1000;
고객번호 납입자
--
--
1000 1000
| {CODE} |
| 오티마이져가 UNNEST 선택함 ( 책하곤 틀리게 잘풀린다. ㅠㅠ ) |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.04 | 10 | 3 | ||||
| 2 | NESTED LOOPS | 1 | 1 | 1 | 00:00:00.02 | 7 | 2 | ||||
| 3 | SORT UNIQUE | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | 9216 | 9216 | 8192 (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | |||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1 | 1 | 00:00:00.02 | 3 | 2 |
---
Predicate Information (identified by operation id):
---
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
| {CODE} |
| NO_UNNEST ( 청구_INDEX02 ) |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NO_UNNEST */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @xplan
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:13.77 | 4003K | 3196 | |
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 67149 | 1 | 00:00:13.77 | 4003K | 3196 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:06.59 | 4000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:04.15 | 3000K | 0 |
---
Predicate Information (identified by operation id):
---
2 - access("청구년월"='200503')
filter( IS NOT NULL)
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
| {CODE} |
| NO_UNNEST ( 청구_INDEX01 ) |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NO_UNNEST */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:17.11 | 4031K | 31441 | |
| FILTER | 1 | 1 | 00:00:17.11 | 4031K | 31441 | ||
| TABLE ACCESS FULL | 청구 | 1 | 575K | 1000K | 00:00:01.30 | 31508 | 31441 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:07.22 | 4000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:04.46 | 3000K | 0 |
---
Predicate Information (identified by operation id):
---
2 - filter( IS NOT NULL)
3 - filter("청구년월"='200503')
4 - filter("고객번호"=:B1)
5 - access("납입자"=1000)
| {CODE} |
| 불필요한 연결고리 제거 |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.01 | 10 | ||||
| 2 | NESTED LOOPS | 1 | 1 | 1 | 00:00:00.01 | 7 | ||||
| 3 | SORT UNIQUE | 1 | 1 | 1 | 00:00:00.01 | 4 | 9216 | 9216 | 8192 (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 |
--
Predicate Information (identified by operation id):
---
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
| {CODE} |
UNNEST 말고 다른효율적인 방법은 없는것인가??
| NESTED LOOPS SEMI |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX01 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NL_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:24.92 | 3031K | 31246 | |
| 2 | NESTED LOOPS SEMI | 1 | 1 | 1 | 00:00:24.92 | 3031K | 31246 | |
| TABLE ACCESS FULL | 청구 | 1 | 1342K | 1000K | 00:00:09.04 | 31508 | 31246 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:08.62 | 3000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:03.62 | 2000K | 0 |
---
Predicate Information (identified by operation id):
---
3 - filter("청구년월"='200503')
4 - filter("고객번호"="고객번호")
5 - access("납입자"=1000)
-- 청구_INDEX02
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NL_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL>
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:09.18 | 3003K | |
| 2 | NESTED LOOPS SEMI | 1 | 1 | 1 | 00:00:09.18 | 3003K | |
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1000K | 00:00:00.01 | 3207 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:08.27 | 3000K |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:03.38 | 2000K |
--
Predicate Information (identified by operation id):
---
3 - access("청구년월"='200503')
4 - filter("고객번호"="고객번호")
5 - access("납입자"=1000)
| {CODE} |
| 그럼 청구_INDEX02을 사용해서 HASH JOIN SEMI로 풀면.? ( HASH JOIN SEMI 를 원했는데 오티마이져가 HASH JOIN RIGHT SEMI로 풀었다 ) |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ HASH_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.26 | 3214 | ||||||||||||||||
| HASH JOIN RIGHT SEMI | 1 | 1 | 1 | 00:00:00.26 | 3211 | 1035K | 1035K | 324K (0) | <-- | 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | ||||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | |||||||||||||||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1000K | 00:00:00.01 | 3207 |
-
Predicate Information (identified by operation id):
---
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
| {CODE} |
| 그럼 청구_INDEX02을 사용해서 HASH JOIN SEMI로 풀면.? |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 ) LEADING( X) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ HASH_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp |
-
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:05.95 | 3212 | 3503 | 3503 | ||||||||||||||||||||
| HASH JOIN SEMI | 1 | 1 | 1 | 00:00:05.95 | 3211 | 3503 | 3503 | 50M | 5133K | 69M (0) | 36864 | <-- |
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1000K | 00:00:00.01 | 3207 | 0 | 0 | |||||
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | 0 | |||||||||||||||||||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | 0 |
-
Predicate Information (identified by operation id):
---
2 - access("고객번호"="고객번호")
3 - access("청구년월"='200503')
5 - access("납입자"=1000)
| {CODE} |
| 그럼 청구_INDEX02을 사용해서 MERGE JOIN SEMI로 풀면.? |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ MERGE_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
Plan hash value: 2507689243
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.01 | 11 | ||||
| 2 | MERGE JOIN SEMI | 1 | 1 | 1 | 00:00:00.01 | 10 | ||||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1001 | 00:00:00.01 | 6 | |||
| SORT UNIQUE | 1001 | 1 | 1 | 00:00:00.01 | 4 | 73728 | 73728 | ||
| 5 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 |
--
Predicate Information (identified by operation id):
---
3 - access("청구년월"='200503')
4 - access("고객번호"="고객번호")
filter("고객번호"="고객번호")
6 - access("납입자"=1000)
| {CODE} |
| 그럼 청구_INDEX02을 사용해서 고객 테이블을 선두테이블로 먼저 드라이빙 해서 MERGE JOIN SEMI로 풀면.?( 별짓 다해두 안됨 ) |
|---|
| {CODE:SQL} |
– 1
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) INDEX( X@MAIN 청구_INDEX02 ) MERGE_SJ( @SUB ) QB_NAME( MAIN ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB )*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000 );
1 행이 갱신되었습니다.
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.01 | 11 | ||||
| 2 | MERGE JOIN SEMI | 1 | 1 | 1 | 00:00:00.01 | 10 | ||||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1001 | 00:00:00.01 | 6 | |||
| SORT UNIQUE | 1001 | 1 | 1 | 00:00:00.01 | 4 | 73728 | 73728 | ||
| 5 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 |
--
Predicate Information (identified by operation id):
---
3 - access("청구년월"='200503')
4 - access("고객번호"="고객번호")
filter("고객번호"="고객번호")
6 - access("납입자"=1000)
– 2
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) INDEX( X@MAIN 청구_INDEX02 ) HASH_SJ( @SUB ) QB_NAME( MAIN ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB )*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000 );
1 행이 갱신되었습니다.
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:01.43 | 3212 | 5 | ||||
| HASH JOIN RIGHT SEMI | 1 | 1 | 1 | 00:00:01.43 | 3211 | 5 | 1035K | 1035K | 310K (0) | |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | |||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1342K | 1000K | 00:00:00.01 | 3207 | 5 |
--
Predicate Information (identified by operation id):
---
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
| {CODE} |
| 번외편 SEMIJOIN_DRIVER( 안풀림 ) |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics SEMIJOIN_DRIVER(@SUB ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.91 | 10 | ||||
| 2 | NESTED LOOPS | 1 | 1 | 1 | 00:00:00.90 | 7 | ||||
| 3 | SORT UNIQUE | 1 | 1 | 1 | 00:00:00.86 | 4 | 9216 | 9216 | 8192 (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.86 | 4 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1 | 1 | 00:00:00.04 | 3 |
--
Predicate Information (identified by operation id):
---
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
| {CODE} |
| 번외편 SWAP_JOIN_INPUTS |
|---|
| {CODE:SQL} SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) QB_NAME( MAIN ) */ 청구 X 2 SET 입금액 = NVL( 입금액, 0 ) + 50000 3 WHERE 청구년월 = '200503' 4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호 5 FROM 고객 Y 6 WHERE 납입자 = 1000); |
1 행이 갱신되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:00.14 | 10 | 3 | ||||
| 2 | NESTED LOOPS | 1 | 1 | 1 | 00:00:00.12 | 7 | 2 | ||||
| 3 | SORT UNIQUE | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | 9216 | 9216 | 8192 (0) | |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | 0 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | |||
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 1 | 1 | 00:00:00.12 | 3 | 2 |
---
Predicate Information (identified by operation id):
---
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
--음.. 좀더 공격적인 힌트
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS( @SUB Y ) LEADING( @SUB Y ) HASH_SJ( @SUB ) INDEX( X 청구_INDEX02 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:01.24 | 36800 | ||||
| HASH JOIN RIGHT SEMI | 1 | 1 | 1 | 00:00:01.24 | 36799 | 1035K | 1035K | 340K (0) | |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 1 | 1 | 1 | 00:00:00.01 | 4 | |||
| INDEX RANGE SCAN | 고객_INDEX0 | 1 | 1 | 1 | 00:00:00.01 | 3 | |||
| INDEX FULL SCAN | 청구_INDEX0 | 1 | 575K | 1000K | 00:00:01.00 | 36795 |
-
Predicate Information (identified by operation id):
---
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
filter("청구년월"='200503')
| {CODE} |
| Filter 서브쿼리 |
|---|
| {CODE:SQL} |
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX01 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:24.74 | 4038K | 38444 | |
| INDEX FULL SCAN | 청구_INDEX0 | 1 | 28751 | 1 | 00:00:24.74 | 4038K | 38444 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:07.15 | 4000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:04.40 | 3000K | 0 |
---
Predicate Information (identified by operation id):
---
2 - access("청구년월"='200503')
filter(("청구년월"='200503' AND IS NOT NULL))
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
| {CODE} |
| INDEX FULL SCAN 다른 방법은 없는것인가?? 유니크 인덱스가 없어서 그런거 같다.. 생성 |
|---|
| {CODE:SQL} |
DROP INDEX 청구_INDEX01
CREATE UNIQUE INDEX 청구_INDEX02 ON 청구( 고객번호, 청구년월 );
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX02 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-- 아니군요 ㅠ
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:09.54 | 4036K | 47 | |
| INDEX FULL SCAN | 청구_INDEX0 | 1 | 28751 | 1 | 00:00:09.54 | 4036K | 47 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:06.99 | 4000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:04.28 | 3000K | 0 |
---
Predicate Information (identified by operation id):
---
2 - access("청구년월"='200503')
filter(("청구년월"='200503' AND IS NOT NULL))
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
| {CODE} | 선두 컬럼이 알수 없으니 풀스캔으로 타는것 같다. 청구_INDEX03 ON 청구( 청구년월, 고객번호 ) 확인자( Early Filter 서브쿼리 ) |
|---|---|
| {CODE:SQL} |
CREATE INDEX 청구_INDEX03 ON 청구( 청구년월, 고객번호 );
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX03) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
Plan hash value: 483576752
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---
| 1 | UPDATE | 청구 | 1 | 0 | 00:00:17.10 | 4003K | 3059 | |
| INDEX RANGE SCAN | 청구_INDEX0 | 1 | 28751 | 1 | 00:00:17.10 | 4003K | 3059 |
| TABLE ACCESS BY INDEX ROWID | 고객 | 1000K | 1 | 1 | 00:00:06.98 | 4000K | 0 |
| INDEX RANGE SCAN | 고객_INDEX0 | 1000K | 1 | 1000K | 00:00:04.27 | 3000K | 0 |
---
Predicate Information (identified by operation id):
---
2 - access("청구년월"='200503')
filter( IS NOT NULL)
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
| {CODE} |
나) Sort Merge형 세미조인
- 세미조인 : 조인형태가 가지는 고유한 장.단점이나 적용기준들도 거의 그대로 통용된다. 이 말은 곧 세미 조인에서도 상황에 따라 적절한 조인 형식을 적용하여야 함을 의미한다.
연결고리의 이상이 발생하거나 대량의 데이터를 연결해야 할 때는 세미 조인에서도 Sort Merge 형 조인이 적용 될 수 있다. - 사원 테이블과 근태 테이블은 연결고리인 '부서코드'에서 볼때는 M:M 관계를 가지고 있지만 서브 쿼리 특성상 항상 메이쿼리의 집합은 보존되므로 물로 결과는 M:1 조인과 동일핟.
| 준비스크립트 |
|---|
| {CODE:SQL} |
DROP TABLE 사원 PURGE;
CREATE TABLE 사원 AS
SELECT 사번
, 성명
, 직급
, 입사일
, 부서코드
, DECODE( 부서코드, 1, 'DB1팀', 2, 'DB2팀', 3, 'DB3팀'
, 4, '시스템1팀', 5, '시스템2팀', 6, '시스템3팀'
, 7, '경리1과', 8, '경리2과', 9, '경리3과', 10, '경리과', 11, '경리4과'
, 12, '개발1팀', 13, '개발2팀', 14, '개발3팀', 15, '개발4팀', 16, '개발5팀', 17, '개발6팀'
, 18, 'MD1팀', 19, 'MD2팀', 20, 'MD3팀', 21, 'MD4팀'
, 22, '디자인1팀', 23, '디자인2팀', 24, '디자인3팀', 25, '디자인4팀'
, 26, '멀티미디어1팀', 27, '멀티미디어2팀', 28, '멀티미디어3팀'
, 29, '모바일1팀'
, 30, '웹모바일팀'
, 31, '마케팅팀'
, 32, '기획팀' ) 부서
FROM (SELECT LEVEL AS 사번
, '아무개'||LEVEL AS 성명
, TRUNC( dbms_random.value( 1,7 ) ) 직급
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 10000 ) 입사일
, TRUNC( dbms_random.value( 1,32 ) ) 부서코드
FROM DUAL
CONNECT BY LEVEL <= 1000000
)
CREATE UNIQUE INDEX 사원_PK ON 사원 ( 사번 )
--CREATE INDEX 부서_INDEX_01 ON 사원 ( 부서코드, 직급 );
CREATE TABLE 근태 AS
SELECT A.사번
, B.부서코드
, A.근태유형
, A.일자
FROM (SELECT TRUNC( dbms_random.value( 1,1000000 ) ) 사번
, DECODE( A.JOIN_C, 1,'무단결근',2,'조퇴', 3,'지각', 4,'지각', 5,'지각', 6, '연차', 7, '연차', 8,'휴가', 9,'휴가',10, '지각') 근태유형
, A.일자
FROM (SELECT TRUNC( dbms_random.value( 1,10 ) ) JOIN_C --
, TO_CHAR( TO_DATE( '20050101', 'YYYYMMDD') + LEVEL -1, 'YYYYMMDD' ) 일자
FROM DUAL
CONNECT BY LEVEL <= 365--TO_DATE( '20050630', 'YYYYMMDD') - TO_DATE( '20050501', 'YYYYMMDD')
) A
, (SELECT LEVEL LV FROM DUAL CONNECT BY LEVEL <= 6 ) B
WHERE A.JOIN_C >= B.LV
) A
, 사원 B
WHERE A.사번 = B.사번
CREATE INDEX 유형_일자_INX ON 근태 ( 근태유형, 일자 )
SQL> SELECT COUNT(*) FROM 근태
2 ;
COUNT(*)
--
1574
| {CODE} |
| p. 591 테스트 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics QB_NAME( MAIN ) LEADING( B@SUB ) UNNEST( @SUB ) USE_MERGE( B@SUB A@MAIN ) / COUNT()
2 FROM 사원 A
3 WHERE 부서코드 IN ( SELECT /*+ QB_NAME( SUB ) */ 부서코드
4 FROM 근태 B
5 WHERE 일자 BETWEEN '20050601' AND '20050612'
6 AND 근태유형 = '지각' )
7 AND 직급 >= 3;
COUNT(*)
--
365514
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.43 | 6336 | ||||
| 2 | MERGE JOIN | 1 | 351K | 365K | 00:00:02.44 | 6336 | ||||
| 3 | SORT JOIN | 1 | 10 | 17 | 00:00:00.01 | 3 | 2048 | 2048 | 2048 (0) | |
| 4 | SORT UNIQUE | 1 | 19 | 17 | 00:00:00.01 | 3 | 9216 | 9216 | 8192 (0) | |
| 5 | TABLE ACCESS BY INDEX ROWID | 근태 | 1 | 19 | 19 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 유형_일자_ | 1 | 19 | 19 | 00:00:00.01 | 2 | |||
| SORT JOIN | 17 | 573K | 365K | 00:00:01.03 | 6333 | 13M | 1381K | 11M (0) | |
| TABLE ACCESS FULL | 사원 | 1 | 573K | 666K | 00:00:01.33 | 6333 |
--
Predicate Information (identified by operation id):
---
6 - access("근태유형"='지각' AND "일자">='20050601' AND "일자"<='20050612')
7 - access("부서코드"="부서코드")
filter("부서코드"="부서코드")
8 - filter("직급">=3)
| {CODE} |
| p. 592 책처럼 실행계획으로 나오려면... |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics LEADING( A ) USE_MERGE( B ) / COUNT()
2 FROM 사원 A
3 , (SELECT DISTINCT 부서코드
4 FROM 근태 B
5 WHERE 일자 BETWEEN '20050601' AND '20050612'
6 AND 근태유형 = '지각' ) B
7 WHERE A.부서코드 = B.부서코드
8 AND 직급 >= 3;
COUNT(*)
--
365514
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:06.96 | 6336 | ||||
| 2 | MERGE JOIN | 1 | 351K | 365K | 00:00:05.50 | 6336 | ||||
| 3 | SORT JOIN | 1 | 573K | 666K | 00:00:01.72 | 6333 | 13M | 1381K | 11M (0) | |
| TABLE ACCESS FULL | 사원 | 1 | 573K | 666K | 00:00:02.00 | 6333 | |||
| SORT JOIN | 666K | 19 | 365K | 00:00:04.28 | 3 | 73728 | 73728 | ||
| 6 | VIEW | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 7 | HASH UNIQUE | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 8 | TABLE ACCESS BY INDEX ROWID | 근태 | 1 | 19 | 19 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 유형_일자_ | 1 | 19 | 19 | 00:00:00.01 | 2 |
---
Predicate Information (identified by operation id):
---
4 - filter("직급">=3)
5 - access("A"."부서코드"="B"."부서코드")
filter("A"."부서코드"="B"."부서코드")
9 - access("근태유형"='지각' AND "일자">='20050601' AND "일자"<='20050612')
| {CODE} * HASH UNIQUE ( SORT UNIQUE ) : '1' 집합을 만든다 ( 메인 쿼리 보존 ) * Sort Merge형식으로 수행 될 때는 다른 집합에서 수해오딘 결과를 받아서 처리할 수 없으므로 독자적으로 처리범위를 충분히 줄일 수 있을 때 효과적이며 * 랜덤 액세스가 줄어들기 때문에 경우에 따라서는 매우 효과적일 수도 있다는 장점은 일반적인 조인 시와 동일하다.( ㅡㅡ ) * 예를 들어 앞서 예를 든 SQL의 서브쿼리에 GROUP BY가 있었다고 가정해보자. 그 결과는 이미 가공된 결과의 집합이므로 인덱스를 사용할 수 없다 그러나 GROUP BY에 의해 집합의 크기가 줄어 들었으므로 조인의 량은 감소한다. 이런 경우에는 Sort Merge형 세미 조인이 나름대로 가치가 있다. 물론 이런 경우에도 서브 쿼리를 인라인뷰로 만들어 일반 조인으로 연결하는 것도 내용적으로 거의 동일하다. 연결고리의 조건 조건에 'NOT'을 사용한 경우에도 이러한 형태의 연결이 나타날 수 있다. 여기에 대한 상세한 내용은 '부정형( ANTI ) 세미조인( Page 599 ~ 605 )에서 설명될 것이다. |
참고 사이트
http://scidb.tistory.com/search/SORT
Sort Merge Join에 대한 오만과 편견
1. 양쪽 집합이 Full Table Scan을 사용하면 조인순서에 상관없이 일량이 동일하므로 처리시간도 동일하다.
2. 조인순서에 상관없이 Sort량은 동일하다
3. 부분범위처리가 안된다.
4. Full Scan이 발생하면 인덱스를 사용할 수 없으므로 항상 Sort 작업을 동반한다.
5. Sort Merge Join 대신 Catesian Merge Join이 나오면 조인 조건이 빠진 악성 SQL이다.
6. 조인 컬럼 기준에 Sort되므로 Order by절과 조인 컬럼이 일치해야만 Sort가 발생하지 않는다.
왜 뜬꿈없이 오만과 편견이냐? 책에서 Sort Merge 조인으로 실행계획이 수립 되어서 테스트 중 결과가 도출되어 겸사겸사 설명까지 첨부.으흠.
2. 조인순서에 상관없이 처리시간과 Sort량 동일 할까? ( 맛베기.. 시간이 없어요 남음할게요.. ㅠ )
| p. 592 책처럼 실행계획으로..LEADING( 사원 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics LEADING( A ) USE_MERGE( B ) / COUNT()
2 FROM 사원 A
3 , (SELECT DISTINCT 부서코드
4 FROM 근태 B
5 WHERE 일자 BETWEEN '20050601' AND '20050612'
6 AND 근태유형 = '지각' ) B
7 WHERE A.부서코드 = B.부서코드
8 AND 직급 >= 3;
COUNT(*)
--
365514
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:06.92 | 6336 | ||||
| 2 | MERGE JOIN | 1 | 351K | 365K | 00:00:05.42 | 6336 | ||||
| 3 | SORT JOIN | 1 | 573K | 666K | 00:00:01.63 | 6333 | 13M | 1381K | 11M (0) | |
| TABLE ACCESS FULL | 사원 | 1 | 573K | 666K | 00:00:01.33 | 6333 | |||
| SORT JOIN | 666K | 19 | 365K | 00:00:04.33 | 3 | 73728 | 73728 | ||
| 6 | VIEW | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 7 | HASH UNIQUE | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 8 | TABLE ACCESS BY INDEX ROWID | 근태 | 1 | 19 | 19 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 유형_일자_ | 1 | 19 | 19 | 00:00:00.01 | 2 |
---
Predicate Information (identified by operation id):
---
4 - filter("직급">=3)
5 - access("A"."부서코드"="B"."부서코드")
filter("A"."부서코드"="B"."부서코드")
9 - access("근태유형"='지각' AND "일자">='20050601' AND "일자"<='20050612')
| {CODE} |
| p. 592 책처럼 실행계획으로..LEADING( 근태 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics LEADING( B ) USE_MERGE( A B ) / COUNT()
2 FROM 사원 A
3 , (SELECT DISTINCT 부서코드
4 FROM 근태 B
5 WHERE 일자 BETWEEN '20050601' AND '20050612'
6 AND 근태유형 = '지각' ) B
7 WHERE A.부서코드 = B.부서코드
8 AND 직급 >= 3;
COUNT(*)
--
365514
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.41 | 6336 | ||||
| 2 | MERGE JOIN | 1 | 351K | 365K | 00:00:02.44 | 6336 | ||||
| 3 | SORT JOIN | 1 | 19 | 17 | 00:00:00.01 | 3 | 2048 | 2048 | 2048 (0) | |
| 4 | VIEW | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 5 | HASH UNIQUE | 1 | 19 | 17 | 00:00:00.01 | 3 | ||||
| 6 | TABLE ACCESS BY INDEX ROWID | 근태 | 1 | 19 | 19 | 00:00:00.01 | 3 | |||
| INDEX RANGE SCAN | 유형_일자_ | 1 | 19 | 19 | 00:00:00.01 | 2 | |||
| SORT JOIN | 17 | 573K | 365K | 00:00:01.02 | 6333 | 13M | 1381K | 11M (0) | |
| TABLE ACCESS FULL | 사원 | 1 | 573K | 666K | 00:00:01.33 | 6333 |
---
Predicate Information (identified by operation id):
---
7 - access("근태유형"='지각' AND "일자">='20050601' AND "일자"<='20050612')
8 - access("A"."부서코드"="B"."부서코드")
filter("A"."부서코드"="B"."부서코드")
9 - filter("직급">=3)
| {CODE} |
다) 필터(Filter)형 세미조인
- 필터 : 말 그대로 '골라내는 작업'방법을 말한다.
- 확인자 역할 : 먼전 수행하여 엑세스한 결과를 서브쿼리를 통해 체크하여 취할 것인지, 아니면 버려야 할 것인지를 결정하는 역할이다.
이 형식의 세미조인은 이러한 작업을 보다 효율적으로 수행하기 위해 버퍼( Buffer ) 내에 이전의 값을 저장해 두었다가
대응되는 집합을 엑세스하기 전에 먼저 저장된 값과 비교함으로써 액세스를 최소화하는 방법이다. - 조인 : 연결된 로우들을 다음 단계의 처리를 위해 보관할 필요가 있지만 필터처리에서는 단지 선별을 위해서만 사용하므로 체크에 필요로 하지만
필터처리에서는 단지 선별을 위해서만 사용하므로 체크에 필요한 최소의 정보만 잠시 저장되어 있을 뿐이다.
| 준비 스크립티 |
|---|
| {CODE:SQL} |
DROP TABLE "ORDER" PURGE
DROP TABLE DEPT PURGE
CREATE TABLE "ORDER" AS
SELECT LEVEL SEQNO
, TO_CHAR( ( SYSDATE - 100 ) - 1 / 1440 / ( 60 / ( 1000001 - LEVEL )), 'YYYYMMDDHH24MISS' ) ORDDATE
, TO_CHAR( TRUNC( dbms_random.value( 1,12 ) ), 'FM0009' ) SALDEPTNO
FROM DUAL
CONNECT BY LEVEL <= 1000000
CREATE TABLE DEPT AS
SELECT TO_CHAR( LEVEL, 'FM0009' ) DEPTNO
, '부서'|| TO_CHAR( LEVEL, 'FM0009' ) AS DEPTNAME
, TRUNC( dbms_random.value( 1,4 ) ) TYPE1
FROM DUAL
CONNECT BY LEVEL <= 12
CREATE INDEX ORDDATE_INDEX ON "ORDER"( ORDDATE )
CREATE INDEX ORDDATE_INDEX_01 ON "ORDER"( ORDDATE, SALDEPTNO )
CREATE UNIQUE INDEX DEPT_PK ON DEPT ( DEPTNO )
SQL> SELECT *
2 FROM (SELECT *
3 FROM "ORDER"
4 ORDER BY SEQNO ASC
5 )
6 WHERE ROWNUM <= 10;
SEQNO ORDDATE SALDE
--
--
-
1 20110616073831 0001
2 20110616073832 0008
3 20110616073833 0002
4 20110616073834 0007
5 20110616073835 0005
6 20110616073836 0001
7 20110616073837 0010
8 20110616073838 0011
9 20110616073839 0006
10 20110616073840 0007
10 개의 행이 선택되었습니다.
SQL> SELECT SUBSTR( ORDDATE, 1,8 ), MAX(SEQNO), COUNT(*)
2 FROM "ORDER"
3 GROUP BY SUBSTR( ORDDATE, 1,8 )
4 ORDER BY MAX(SEQNO);
SUBSTR(ORDDATE,1 MAX(SEQNO) COUNT(*)
--
--
20110616 58889 58889
20110617 145289 86400
20110618 231689 86400
20110619 318089 86400
20110620 404489 86400
20110621 490889 86400
20110622 577289 86400
20110623 663689 86400
20110624 750089 86400
20110625 836489 86400
20110626 922889 86400
SUBSTR(ORDDATE,1 MAX(SEQNO) COUNT(*)
--
--
20110627 1000000 77111
12 개의 행이 선택되었습니다.
SQL> SELECT * FROM DEPT
2 ;
DEPTN DEPTNAME TYPE1
-
-
--
0001 부서0001 3
0002 부서0002 2
0003 부서0003 1
0004 부서0004 1
0005 부서0005 2
0006 부서0006 3
0007 부서0007 3
0008 부서0008 3
0009 부서0009 3
0010 부서0010 3
0011 부서0011 3
DEPTN DEPTNAME TYPE1
-
-
--
0012 부서0012 2
12 개의 행이 선택되었습니다.
| {CODE} |
| p.593 그림 실행 스크립트( NO_HINT ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.11 | 757 | 374 | ||||
| 2 | NESTED LOOPS | 1 | 17623 | 15832 | 00:00:00.19 | 757 | 374 | ||||
| 3 | SORT UNIQUE | 1 | 2 | 2 | 00:00:00.01 | 3 | 0 | 9216 | 9216 | 8192 (0) | |
| TABLE ACCESS FULL | DEPT | 1 | 2 | 2 | 00:00:00.01 | 3 | 0 | |||
| INDEX RANGE SCAN | ORDDATE_INDEX_01 | 2 | 8812 | 15832 | 00:00:00.13 | 754 | 374 |
---
Predicate Information (identified by operation id):
---
4 - filter("Y"."TYPE1"=1)
5 - access("ORDDATE" LIKE '20110621%' AND "Y"."DEPTNO"="X"."SALDEPTNO")
filter(("ORDDATE" LIKE '20110621%' AND "Y"."DEPTNO"="X"."SALDEPTNO"))
| {CODE} |
| p. 594 그림 실행 스크립트 ( ORDDATE_INDEX( ORDDATE ) ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ NO_UNNEST NO_PUSH_SUBQ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.15 | 697 | 313 | |
| FILTER | 1 | 15832 | 00:00:00.21 | 697 | 313 | ||
| 3 | TABLE ACCESS BY INDEX ROWID | ORDER | 1 | 96928 | 86400 | 00:00:00.95 | 675 | 313 |
| INDEX RANGE SCAN | ORDDATE_INDEX | 1 | 96928 | 86400 | 00:00:00.26 | 316 | 313 |
| TABLE ACCESS BY INDEX ROWID | DEPT | 11 | 1 | 2 | 00:00:00.01 | 22 | 0 |
| INDEX UNIQUE SCAN | DEPT_PK | 11 | 1 | 11 | 00:00:00.01 | 11 | 0 |
--
Predicate Information (identified by operation id):
---
2 - filter( IS NOT NULL)
4 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
5 - filter("Y"."TYPE1"=1)
6 - access("Y"."DEPTNO"=:B1)
| {CODE} * 1) 'ORDDATE_INDEX'를 86400 개까지 차례로 범위처리를 하면서 86400 건의 'ORDER' 테이블의 로우를 읽어 내려 간다. * 2) 대응되는 DEPT 테이블을 연결한다. * 3) 그렇다면 'ORDER' 테이블에서 엑세스한 86400 개의 각각의 로우에 대해서 메번 서브쿼리가 수행되어 EXISTS를 체크했다 * 4) 그러므로 'DEPT' 테이블을 액세스하는 서브쿼리도 86400 번 수행되어야 할 것이다. * 5) 그런데 'DEPT' acess 5을 살펴보면 이 메인쿼리가 'DEPT' 테이블을 엑세스한것은 단 11회에 불과 하다. |
| NL SEMI ( ORDDATE_INDEX ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ NL_SJ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @xplan
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.12 | 688 | |
| 2 | NESTED LOOPS SEMI | 1 | 709 | 15832 | 00:00:00.17 | 688 | |
| 3 | TABLE ACCESS BY INDEX ROWID | ORDER | 1 | 3899 | 86400 | 00:00:00.61 | 675 |
| INDEX RANGE SCAN | ORDDATE_INDEX | 1 | 3899 | 86400 | 00:00:00.26 | 316 |
| TABLE ACCESS BY INDEX ROWID | DEPT | 11 | 1 | 2 | 00:00:00.01 | 13 |
| INDEX UNIQUE SCAN | DEPT_PK | 11 | 1 | 11 | 00:00:00.01 | 2 |
-
Predicate Information (identified by operation id):
---
4 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
5 - filter("Y"."TYPE1"=1)
6 - access("Y"."DEPTNO"="X"."SALDEPTNO")
| {CODE} |

그림 2-2-26 설명
- 1) 먼저 ORDDATE_INDEX 에서 '20110621%'를 만족하는 첫 번재 로우를 읽고 그 ROWID로 ORDER 테이블의 해당 로우를 엑세스한다.
- 2) 그 로우가 가지고 있는 SALDEPTNO 와 버퍼에 있는 DEPT와 비교한 결과가 같지 않으므로 DEPT 테이블의 기본키를 이용해 액세스한 후 TYPE='1'을 체크한다.
체크를 하여 조건을 만족하면 운반단위에 태우고 아니면 버린다. - 3) 액세스한 DEPT테이블의 비교 컬럼값들을 버퍼에 저장한다.
- 4) ORDDATE_INDEX의 두번재 로우에 대한 ORDER 테이블 로우를 액세스한 후 버퍼와 체크한다. 이때 ORDER테이블의 SALDEPTNO와 버퍼의 DEPT가 동일하면 버퍼와의 비교만 수행하며,
DEPT 테이블은 액세스하지 않는다.
버퍼의 DEPT와 일치히지 않을 때는 DEPT 테이블을 액세스하여 체크 조건을 비교하고 그 값을 다시 버퍼에 저장한다.
버퍼는 하나의 값만 저장 할수 있으므로 앞서 저장된 값은 갱신된다.
그림에는 처음에 버퍼에 있던 '11,1'이 '22,2'로 바뀌어진 것을 표현하였다. - 5) 이와 같은 방법으로 ORDDATE_INDEX의 처리범위가 완료될 때까지 수행한다.
- 메인 쿼리에서 엑세스되는 로우가 서브 쿼리에서 비교할 컬럼( 연결고리 )으로 정렬되어 있다면 서브 쿼리의 테이블 엑세스 양은 많이 감소시킬 수 있다.
- 즉, 선행처리되는 ORDER 테이블의 연결고리인 SALDEPTNO가 만약에 'ORDERDATE + SALDEPTNO'로 인덱스가 되어 있다면
, 그림에서 처럼 '11'이 모든 끝난 다음에 '22'가 나타날 것이므로 DEPT를 액세스하러 가는 경우가 최소화 될 것이다. ( 정말... ?? ) - 그러나 극단저긴 경우를 가정해보자. 만약 SALDEPT가 매번 바뀌었다고 한다면 항상 버퍼에 저장된 것과 일치하지 않을 것이므로 버퍼를 활용한 이득을 전혀 얻을 수 없다.
물론 이것은 최악의 경우를 가정한 것이므로 대부분의 경우는 최소한 유리하게 된다고 말 할 수 있다. ( 이처럼 서브쿼리를 확인자 역할로만 사용하고자 한다면 FILTER형 세미조인을 활용하는 것이 나쁠 것이 없다. - 그러나 무조건 그렇게 생각하는 것도 약간의 문제는 잇다. 그림에서 볼 수 있듯이 이 처리방식은 개념적으로는 NL형시과 유사하므로 램덤액세스가 증가할 가능성이 있다.
물론 버퍼만 체크하는 경우가 많다면 걱정할 것이 없겠지만 그렇지 않을 때는 Sort Merge이나 해쉬 조인이 되도록 하는 것이 보다 유리할 것이다.
일반적으로 EXISTS 서브 쿼리를 사용할 경우는 대부분 Filter 처리 방식으로 실행계획이 수립되므로 필요하다면 인라인뷰를 활용한 조이문을 사용하느게 좋다. ( 정말..?? )
먼가 이상 하지 않나요?? ( 물론 제가 잘못 이해 할 수도 있습니다. )
- 현재 ORDER Table 데이타 상황은 책에서 말한 필터를 사용할 경우 최악의 상황인데.. 딱 11번만 서브쿼리르 엑세스 했습니다.
- 그래서 찾아봤습니다. ( _query_execution_cache_max_size )
- 아 그리고 세미조인도 캐쉬영역을 사용하는 것 같습니다.
{CODE:SQL}
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) */ *
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND ROWNUM <= 50
5 ORDER BY ORDDATE ASC;
SEQNO ORDDATE SALDE
--
--
-
404490 20110621000000 0008
404491 20110621000001 0007
404492 20110621000002 0002
404493 20110621000003 0004
404494 20110621000004 0005
404495 20110621000005 0001
404496 20110621000006 0002
404497 20110621000007 0008
404498 20110621000008 0007
404499 20110621000009 0011
404500 20110621000010 0009
SEQNO ORDDATE SALDE
--
--
-
404501 20110621000011 0010
404502 20110621000012 0008
404503 20110621000013 0007
404504 20110621000014 0003
404505 20110621000015 0003
404506 20110621000016 0006
404507 20110621000017 0011
404508 20110621000018 0009
404509 20110621000019 0009
404510 20110621000020 0004
404511 20110621000021 0004
SEQNO ORDDATE SALDE
--
--
-
404512 20110621000022 0004
404513 20110621000023 0008
404514 20110621000024 0002
404515 20110621000025 0001
404516 20110621000026 0006
404517 20110621000027 0004
404518 20110621000028 0001
404519 20110621000029 0009
404520 20110621000030 0003
404521 20110621000031 0011
404522 20110621000032 0010
SEQNO ORDDATE SALDE
--
--
-
404523 20110621000033 0002
404524 20110621000034 0001
404525 20110621000035 0011
404526 20110621000036 0007
404527 20110621000037 0008
404528 20110621000038 0009
404529 20110621000039 0011
404530 20110621000040 0004
404531 20110621000041 0003
404532 20110621000042 0009
404533 20110621000043 0010
SEQNO ORDDATE SALDE
--
--
-
404534 20110621000044 0001
404535 20110621000045 0003
404536 20110621000046 0008
404537 20110621000047 0008
404538 20110621000048 0003
404539 20110621000049 0007
50 개의 행이 선택되었습니다.
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) */ DISTINCT SALDEPTNO
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%' ;
SALDE
-
0008
0010
0009
0001
0011
0006
0005
0007
0002
0004
0003
11 개의 행이 선택되었습니다.
SQL> select ksppinm name,
2 ksppstvl value,
3 decode(bitand(ksppiflg/256,1),1,'true','false') ses_modifiable,
4 decode(bitand(ksppiflg/65536,3),1,'immediate',2,'deferred',3,'immediate','false') sys_modifiable,
5 ksppdesc description
6 from sys.x$ksppi i, sys.x$ksppcv v
7 where i.indx = v.indx
8 and i.ksppinm like '%_query_execution_cache_max_size%';
NAME
VALUE
SES_M SYS_MODIF
-
-
DESCRIPTION
_query_execution_cache_max_size
65536 <--
true deferred
max size of query execution cache
{CODE}
- 결론 : 버퍼는 1개가 아니다.
| p. 594 그림 실행 스크립트 ( ORDDATE_INDEX_01( ORDDATE ) ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX_01 ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ NO_UNNEST NO_PUSH_SUBQ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.10 | 399 | 3 | |
| FILTER | 1 | 15832 | 00:00:00.16 | 399 | 3 | ||
| INDEX RANGE SCAN | ORDDATE_INDEX_01 | 1 | 3899 | 86400 | 00:00:00.26 | 377 | 3 |
| TABLE ACCESS BY INDEX ROWID | DEPT | 11 | 1 | 2 | 00:00:00.01 | 22 | 0 |
| INDEX UNIQUE SCAN | DEPT_PK | 11 | 1 | 11 | 00:00:00.01 | 11 | 0 |
-
Predicate Information (identified by operation id):
---
2 - filter( IS NOT NULL)
3 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
4 - filter("Y"."TYPE1"=1)
5 - access("Y"."DEPTNO"=:B1)
| {CODE} |
| NL SEMI ( ORDDATE_INDEX_01 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX_01 ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ NL_SJ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.08 | 390 | |
| 2 | NESTED LOOPS SEMI | 1 | 709 | 15832 | 00:00:00.13 | 390 | |
| INDEX RANGE SCAN | ORDDATE_INDEX_01 | 1 | 3899 | 86400 | 00:00:00.26 | 377 |
| TABLE ACCESS BY INDEX ROWID | DEPT | 11 | 1 | 2 | 00:00:00.01 | 13 |
| INDEX UNIQUE SCAN | DEPT_PK | 11 | 1 | 11 | 00:00:00.01 | 2 |
Predicate Information (identified by operation id):
---
3 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
4 - filter("Y"."TYPE1"=1)
5 - access("Y"."DEPTNO"="X"."SALDEPTNO")
| {CODE} |
라) 해쉬( Hash )형 세미조인
- 필터 형식으로 처리되는 세미 조인은 랜덤 위주의 액세스가 발생하므로 만약 대량의 연결을 시도했을 때는 커다란 부담이 될 가능성이 충분히 있다.
- 물론 이런 문제를 해결하기 위해 Sort Merge형으로 실행을 유도할 수도 있겠지만, 일반적으로 해쉬 조인이 수행속도에 유리한 경우가 많기 때문에 이를 활용할 가치가 있다.
| HASH JOIN SEMI |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) LEADING( A ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ HASH_SJ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.12 | 678 | ||||||||||||||||
| HASH JOIN SEMI | 1 | 709 | 15832 | 00:00:00.15 | 678 | 3256K | 1861K | 6674K (0) | <-- | 3 | TABLE ACCESS BY INDEX ROWID | ORDER | 1 | 3899 | 86400 | 00:00:00.60 | 675 | ||||
| INDEX RANGE SCAN | ORDDATE_INDEX | 1 | 3899 | 86400 | 00:00:00.26 | 316 | |||||||||||||||
| TABLE ACCESS FULL | DEPT | 1 | 2 | 2 | 00:00:00.01 | 3 |
Predicate Information (identified by operation id):
---
2 - access("Y"."DEPTNO"="X"."SALDEPTNO")
4 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
5 - filter("Y"."TYPE1"=1)
| {CODE} |
| HASH JOIN RIGHT SEMI ( 적은 테이블을 선행 테이블로... ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND EXISTS ( SELECT /*+ HASH_SJ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
15832
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.10 | 678 | ||||||||||||||||
| HASH JOIN RIGHT SEMI | 1 | 709 | 15832 | 00:00:00.14 | 678 | 1396K | 1396K | 474K (0) | <-- |
| TABLE ACCESS FULL | DEPT | 1 | 2 | 2 | 00:00:00.01 | 3 | ||||
| 4 | TABLE ACCESS BY INDEX ROWID | ORDER | 1 | 3899 | 86400 | 00:00:00.60 | 675 | |||||||||||||||
| INDEX RANGE SCAN | ORDDATE_INDEX | 1 | 3899 | 86400 | 00:00:00.26 | 316 |
Predicate Information (identified by operation id):
---
2 - access("Y"."DEPTNO"="X"."SALDEPTNO")
3 - filter("Y"."TYPE1"=1)
5 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
26 개의 행이 선택되었습니다.
| {CODE} * 수행속도 향상의 요건 : 1) 대량의 연결을 해야 하고 메모리 내에 충분한 해쉬 영역 * 제약 조건 : 1) 서브쿼리에는 하나의 테이블만 존재해야만 한다 2) 서브쿼리 내에 또 다시 서브쿼리를 사용했을 때는 적용이 불가능하다 3) 연결고리의 연산자는 반드시 '='이 되어야 한다. 4) 서브쿼리 내에 GROUP BY, CONNECT BY, ROWNUM을 사용할 수 없다. * 부분 범위 가능 요건 : 어느 한쪽 집합이 메모리 내의 해쉬 영역에 내포 될 수 있으면 부분범위 처리가 가능하다 ( ???? ) 이러한 경우는 온라인 애플리케이션의 경우 대량량 데이터라 하더라도 아주 빠른 수행 속도를 보장 받을 수가 있다. |
마) 부정형( Anti ) 세미조인
- '111'이 아닌 것을 찾겟다고 한다면 우리가 찾아야 할 대상이 어떤 값이 존재하는지 알 수 없으므로 연결을 위한 상수값을 제공하기가 여의치 않다.
- 그러나 약간만 생각을 바꾸어 보면 길이 없는 것도 아니다. 학창시절 수학시간에서 배웠던 상식적인 개념을 생각해 보자.
- 가령, '10-X'라는 수식이 있을때 'X'에 있는 마이너스를 플러스(+)로 바꾸는 방법이 있다. ( '10-(+X)' )
- 즉, 조인의 비교연산자는 'NOT'을 사용하지 않는 긍정형을 쓰고, 이것을 괄호로 묶는 것( 인라인뷰 )을 'NOT IN' 이나 'NOT EXISTS'로 비교하는 방법을 사용하면 된다.
- 다시 말해서 집합간의 연결은 기존의 세미조인으로 실시하고, 그 결과는 판정만 반대로 하는 방식을 적용하기 때문에 앞서 설명했던 세미조인과 매우 유사하다고 할 수 있다.
- 여기서 'IN' 이나 'EXISTS'와 같은 비교 연산자의 의미는 어떤 것을 찾고자 하는 것이 아니라 단지 기술한 서브쿼리의 결과가 'TRUE'인지 'FAULT'인지를 판정하는 불린 연산을 뜻한다.
- 항상 확인자의 역할을 담당 할 수 밖에 없다.
| 준비 스크립트 ( 위에 테이블 재사용 ( 편의상 ) ) |
|---|
| {CODE:SQL} |
DROP TABLE TAB1 PURGE;
DROP TABLE TAB2 PURGE;
CREATE TABLE TAB1 AS
SELECT LEVEL KEY1
, '상품'||LEVEL COL1
, TRUNC( dbms_random.value( 1,7 ) ) * 500 + TRUNC( dbms_random.value( 1,3 ) ) * 750 COL2
FROM DUAL
CONNECT BY LEVEL <= 10000;
CREATE TABLE TAB2 AS
SELECT LEVEL KEY1
, TRUNC(dbms_random.value( 1, 10000 ) ) KEY2
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 1000 ) COL1
, 'A' COL2
FROM DUAL
CONNECT BY LEVEL <= 100000;
CREATE INDEX TAB1_COL1 ON TAB1( COL1 );
CREATE INDEX TAB2_COL1 ON TAB2( COL1 );
CREATE INDEX TAB2_KEY2 ON TAB2( KEY2, COL1 );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB1' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB2' );
| {CODE} |
| p. 600 실습 스크립트 ( 확인자 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 NOT IN ( SELECT KEY2
5 FROM TAB2 B
6 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
899
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:01.12 | 15487 | ||
| FILTER | 1 | 899 | 00:00:00.99 | 15487 | |||
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |
| FILTER | 1112 | 213 | 00:00:01.11 | 15278 | |||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1112 | 1 | 213 | 00:00:01.10 | 15278 | |
| INDEX RANGE SCAN | TAB2_COL1 | 1112 | 2000 | 2001K | 00:00:04.01 | 8184 | (a) -- |
Predicate Information (identified by operation id):
---
2 - filter( IS NULL)
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
6 - filter(LNNVL("KEY2"<>:B1))
7 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} * 서브쿼리가 확인자로 풀림 * (a)서브쿼리의 처리주관 인덱스는 연결고리인 KTAB2_KEY2 인덱스가 아니라 TAB2_COL1 사용 되고 있다. * 이거슨 서브쿼리가 계속해서 동일한 범위를 반복해서 치리하게 된다는것을 의미한다. ( 부정형에는 캐쉬가 먹지 않는가.?? 위경우는 TAB1.KEY1경우가 유니크하기때문에... ) * 만약 인덱스가 ( KEY2, COL1 )로 구성되었거나 COL1에 인덱스가 없다면 당연히 KEY2 인덱스를 사용하는 실행계획이 작성된다. * 이것은 옵티마이저의 잘못이다. ( 데이터베이스 버전에따라 나타나지 않을 수도 있다. ) |
| 잘못된 실행 계획이 수립되는 것을 방지하는 바람직 SQL ( TAB2_COL1 풀림 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND NOT EXISTS ( SELECT/*+ */ 'X'
5 FROM TAB2 B
6 WHERE A.KEY1 = B.KEY2
7 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
899
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 224 | |||||
| HASH JOIN ANTI | 1 | 1 | 899 | 00:00:00.01 | 224 | 1517K | 1517K | 1182K (0) | ||
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | ||||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | ||||
| 5 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.02 | 15 | ||||
| INDEX RANGE SCAN | TAB2_COL1 | 1 | 2000 | 2000 | 00:00:00.01 | 8 | <-- ㅡㅡ^ |
Predicate Information (identified by operation id):
---
2 - access("A"."KEY1"="B"."KEY2")
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
6 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} |
- 책에서는 필터형으로 설명이되었는데 옵티마이져는 해쉬 조인 안티를 선택하였다.
- 옵티마이져가 해쉬를 선택한 이유는 ? 서브쿼리를 한번만 액세스 하기 때문이다.( 주관 )
| 잘못된 실행 계획이 수립되는 것을 방지하는 바람직 SQL ( TAB2_KEY2 유도 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND NOT EXISTS ( SELECT/*+ INDEX( B TAB2_KEY2 ) */ 'X'
5 FROM TAB2 B
6 WHERE A.KEY1 = B.KEY2
7 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
899
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.08 | 531 | ||||
| HASH JOIN ANTI | 1 | 1 | 899 | 00:00:00.08 | 531 | 1517K | 1517K | 1182K (0) | |
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |||
| INDEX FULL SCAN | TAB2_KEY2 | 1 | 2000 | 2000 | 00:00:00.08 | 322 |
Predicate Information (identified by operation id):
---
2 - access("A"."KEY1"="B"."KEY2")
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
filter(("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!)))
| {CODE} |
왜 TAB2_COL1 인덱스를 선택하였나??
{CODE:SQL}
SQL> SELECT/*+ INDEX( B TAB2_KEY2 ) / COUNT()
2 FROM TAB2 B
3 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE );
COUNT(*)
--
2000
SQL> SELECT COUNT(*)
2 FROM TAB2
3 WHERE KEY2 IN (
4 SELECT/*+ INDEX( B TAB2_KEY2 ) */ DISTINCT KEY2
5 FROM TAB2 B
6 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
19431
{CODE}
그럼 이제 책에서 말하는 필터형으로 풀어보자.!
| p. 601 실행 스크립트 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND NOT EXISTS ( SELECT/*+ NO_UNNEST NO_PUSH_SUBQ */ 'X'
5 FROM TAB2 B
6 WHERE A.KEY1 = B.KEY2
7 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
899
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.03 | 2434 | ||
| FILTER | 1 | 899 | 00:00:00.03 | 2434 | |||
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |
| FILTER | 1112 | 213 | 00:00:00.02 | 2225 | |||
| INDEX RANGE SCAN | TAB2_KEY2 | 1112 | 1 | 213 | 00:00:00.01 | 2225 | <-- 굿잡 - |
Predicate Information (identified by operation id):
---
2 - filter( IS NULL)
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
6 - access("B"."KEY2"=:B1 AND "COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} * 필터형으로 푸니 책에서 말씀하신데로 잘 풀리는구나... ( 버전에 따라 틀리수도 있다 ) * 선행 집한에서 상수값을 제공받아 처리한다.( 확인자 ) * 이런한 처리는 랜덤 액세스가 증가한다는 단점을 가지고 있기 때문에 상수값을 제공받았을 때 수행되는 처리량과 독자적으로 수행할 때의 처리량을 비교하여 판단해야 한다. * 이 실행계획읜 장점은 부분범위 처리가 가능하다는 것이다. ( 운반단위 ) |
| 보너스.. NL_AJ로 풀면 어떤가..?? |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND NOT EXISTS ( SELECT/*+ NL_AJ */ 'X'
5 FROM TAB2 B
6 WHERE A.KEY1 = B.KEY2
7 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
899
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.02 | 1324 | |
| 2 | NESTED LOOPS ANTI | 1 | 1 | 899 | 00:00:00.02 | 1324 | |
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 |
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 |
| INDEX RANGE SCAN | TAB2_KEY2 | 1112 | 2000 | 213 | 00:00:00.01 | 1115 |
-
Predicate Information (identified by operation id):
---
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - access("A"."KEY1"="B"."KEY2" AND "COL1">=TRUNC(SYSDATE@!-1) AND
"COL1"<=TRUNC(SYSDATE@!))
| {CODE} |
부정형이 일반 조인이랑 같은 방식이라면 캐쉬도 되는건가??
{CODE:SQL}
SQL> SELECT /*+ gather_plan_statistics INDEX( X ORDDATE_INDEX ) / COUNT()
2 FROM "ORDER" X
3 WHERE ORDDATE LIKE '20110621%'
4 AND NOT EXISTS ( SELECT /*+ NL_AJ */ 'O'
5 FROM DEPT Y
6 WHERE Y.DEPTNO = X.SALDEPTNO
7 AND Y.TYPE1 = 1 );
COUNT(*)
--
70568
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.14 | 688 | |
| 2 | NESTED LOOPS ANTI | 1 | 3190 | 70568 | 00:00:00.35 | 688 | |
| 3 | TABLE ACCESS BY INDEX ROWID | ORDER | 1 | 3899 | 86400 | 00:00:00.78 | 675 |
| INDEX RANGE SCAN | ORDDATE_INDEX | 1 | 3899 | 86400 | 00:00:00.26 | 316 |
| TABLE ACCESS BY INDEX ROWID | DEPT | 11 | 1 | 2 | 00:00:00.01 | 13 |
| INDEX UNIQUE SCAN | DEPT_PK | 11 | 1 | 11 | 00:00:00.01 | 2 |
-
Predicate Information (identified by operation id):
---
4 - access("ORDDATE" LIKE '20110621%')
filter("ORDDATE" LIKE '20110621%')
5 - filter("Y"."TYPE1"=1)
6 - access("Y"."DEPTNO"="X"."SALDEPTNO")
{CODE}
연결 고리가 존재하지 않을 때는 어떻게 해야하는가.? ( 개인적으로 연결고리가 존재하더라도 부정형은 Hash가 월등한것으로 판단됨 ( 주관 ) )
| p. 602 FILTER |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 NOT IN ( SELECT KEY1
5 FROM TAB2 B
6 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE ) );
COUNT(*)
--
1112
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:01.14 | 16889 | |
| FILTER | 1 | 1112 | 00:00:01.15 | 16889 | ||
| 3 | TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 |
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 |
| FILTER | 1112 | 0 | 00:00:01.13 | 16680 | ||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1112 | 1 | 0 | 00:00:01.12 | 16680 |
| INDEX RANGE SCAN | TAB2_COL1 | 1112 | 2000 | 2224K | 00:00:04.46 | 8896 |
--
Predicate Information (identified by operation id):
---
2 - filter( IS NULL)
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
6 - filter(LNNVL("KEY1"<>:B1))
7 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} * 메인쿼리에서 추출한 범위가 매우 넓어서 서브쿼리가 랜덤으로 처리할 양이 매우 많아진다면 상당한 부담이 될 것이다. * 이런한 경우에는 Sort Merge 조인처럼 각각의 집합을 별도로 한 번씩만 액세스하여 정렬시킨 다음 머지를 통해서 연결하는 것이 훨씬 유리하다. * 부정형으로 연결되었지만 이런한 방식의 처리가 문제될 것은 없다. 머지 단계에서 일반적이 머지의 반대인 '머지에 실패한 것'을 추출하기만 하면 나머지는 동일한 방법이 되기 때문에이다. * 그러나 대부분의 경우 옵티마이져는 필터형 처리로 실행계획을 수립하기 때문에 필요하다면 뭔가 특별한 조치를 해야 한다. ( Hash or Merge ) |
| p.602 MERGE JOIN ANTI |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 IS NOT NULL
5 AND KEY1 NOT IN ( SELECT /*+ MERGE_AJ */ KEY1
6 FROM TAB2 B
7 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
8 AND KEY1 IS NOT NULL );
COUNT(*)
--
1112
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 224 | ||||
| 2 | MERGE JOIN ANTI | 1 | 1 | 1112 | 00:00:00.02 | 224 | ||||
| 3 | SORT JOIN | 1 | 1216 | 1112 | 00:00:00.01 | 209 | 24576 | 24576 | 22528 (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |||
| SORT UNIQUE | 1112 | 2000 | 0 | 00:00:00.01 | 15 | 83968 | 83968 | 73728 (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.02 | 15 | |||
| INDEX RANGE SCAN | TAB2_COL1 | 1 | 2000 | 2000 | 00:00:00.01 | 8 |
-
Predicate Information (identified by operation id):
---
4 - filter("KEY1" IS NOT NULL)
5 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
6 - access("KEY1"="KEY1")
filter("KEY1"="KEY1")
7 - filter("KEY1" IS NOT NULL)
8 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE:SQL} * NOT IN 을 사용한 경우만 가능하며 ( MERGE JOIN ANTI ) * 비용기준 옵티마이져로 정의 되어야만 한다. * 세미 조인이 'IN' 이나 'EXISTS' 모두 가능하듯이 부벙형 조인도 당연히 그래야 하지만 현재까지는 'NOT EXISTS'를 사용한 경우는 힌트가 적용되지 않는다 ( 현재도..?? ) |
| p.603 HASH JOIN ANTI |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 IS NOT NULL
5 AND KEY1 NOT IN ( SELECT /*+ HASH_AJ */ KEY1
6 FROM TAB2 B
7 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
8 AND KEY1 IS NOT NULL );
COUNT(*)
--
1112
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 224 | ||||
| HASH JOIN ANTI | 1 | 1 | 1112 | 00:00:00.01 | 224 | 1517K | 1517K | 1180K (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.02 | 15 | |||
| INDEX RANGE SCAN | TAB2_COL1 | 1 | 2000 | 2000 | 00:00:00.01 | 8 |
Predicate Information (identified by operation id):
---
2 - access("KEY1"="KEY1")
3 - filter("KEY1" IS NOT NULL)
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - filter("KEY1" IS NOT NULL)
6 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} * MERGE_AJ과는 다르게 SORT UNIQUE 부분이 나타나지 않는 것은 해쉬 조인이 연결을 위해 사전에 준비해 두는 작업이 필요한 것은 머지 조인과 유사하지만 실제 연결단계에서 필터형식으로 처리되므로 굳이 유일한 집합을 만들어야 할 필요가 없기 때문이다. * 항상 이런 방법이 유리한 것이 아니라는 것은 앞서 그 이유를 충분히 설명하였다. (막 쓰지말고 확인하고 ) * 특히 머지 부정형 조인이나 해쉬 부정형 조인은 전체범위 처리를 하는 경우가 많기 때문에 반드시 부분범위 처리를 하고자 할 때는 사용해서는 안 된다는 것을 분명이 기억하기 바란다. * 세미 조인이 'IN' 이나 'EXISTS' 모두 가능하듯이 부벙형 조인도 당연히 그래야 하지만 현재까지는 'NOT EXISTS'를 사용한 경우는 힌트가 적용되지 않는다 ( 현재도..?? ) |
왜 IS NOT NULL을 추가해야하는가.? ( 없었을때는 안됨 )
- 긍정형 : 어차피 내가 찾고자 하는 데이터가 아니므로 빠지더라도 문제가 될 것이 없다. 1, 2, NULL 2를 액세스할 때 집합 내에 NULL의 존재유무는 결과에 아무런 문제도 일으키지 않는다.
- 부정형 : 2가 아닌 것은 1, NULL이지만, 만약 NULL이 비교연산에서 무시된다면 '1'만 찾게 된다. 이것은 우리가 원하는 결과가 아니다. ( 부정형 서브쿼리에서도 그대로 적용 )
예을 들어 메인쿼리에서 액세스한 값이 1,2,3,NULL이라고 하고 부정형으로 확인자가 될 서브쿼리에는 1,2,NULL이 있다고 가정해 보자.
메인쿼리의 결과 중에 서브쿼리에 없는 것을 찾이면 그 결과는 '3'과 'NULL'이다. 얼핏 생각하면 '3'만 찾아야 할 것처럼 보이지만 그것은 NULL값의 개념을 잘 모르는 사람들 생각
미지수 'X'와 미지수 'Y'는 같은 미지수라는 것일 뿐 이드을 '='이라고 할 수 없는 것과 같다.
그러므로 메인쿼리에 있는 NULL값이 서브쿼리에도 있다고 해서 존재한다는 조건(Exists)을 만족했다고 해서는 안된다.
결론 ?
- 부정형 해쉬 조인은 실제로는 긍정형과 같은 방법으로 조인을 시도해서 조인의 성공여부를 결정하는 방법만 반대로 할뿐이므로
연결되는 것을 찾는 작업을 하면서 그 결과만 반대로 처리한다.
만약 서브쿼리에 NULL값이 존재한다면 결과에 영향을 미칠 수 있으므로 NOT NULL 이라는 전제가 있을 때만 이런한 방식의 조인이 가능하다.
현재도 NOT EXISTS를 사용한 경우는 힌트가 적용되지 않는가.? ㅠ
| 보너스 MERGE JOIN ANTI ( NOT EXISTS )( 현재는 됨 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 IS NOT NULL
5 AND NOT EXISTS ( SELECT /*+ MERGE_AJ */ 'X'
6 FROM TAB2 B
7 WHERE A.KEY1 = B.KEY1
8 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
9 AND KEY1 IS NOT NULL );
COUNT(*)
--
1112
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 224 | ||||
| 2 | MERGE JOIN ANTI | 1 | 1 | 1112 | 00:00:00.02 | 224 | ||||
| 3 | SORT JOIN | 1 | 1216 | 1112 | 00:00:00.01 | 209 | 24576 | 24576 | 22528 (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |||
| SORT UNIQUE | 1112 | 2000 | 0 | 00:00:00.01 | 15 | 83968 | 83968 | 73728 (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.02 | 15 | |||
| INDEX RANGE SCAN | TAB2_COL1 | 1 | 2000 | 2000 | 00:00:00.01 | 8 |
-
Predicate Information (identified by operation id):
---
4 - filter("KEY1" IS NOT NULL)
5 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
6 - access("A"."KEY1"="B"."KEY1")
filter("A"."KEY1"="B"."KEY1")
7 - filter("KEY1" IS NOT NULL)
8 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} |
| 보너스 HASH JOIN ANTI ( NOT EXISTS )( 현재는 됨 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ gather_plan_statistics INDEX( A TAB1_COL1 )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE COL1 LIKE '상품1%'
4 AND KEY1 IS NOT NULL
5 AND NOT EXISTS ( SELECT /*+ HASH_AJ */ 'X'
6 FROM TAB2 B
7 WHERE A.KEY1 = B.KEY1
8 AND COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
9 AND KEY1 IS NOT NULL );
COUNT(*)
--
1112
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 224 | ||||
| HASH JOIN ANTI | 1 | 1 | 1112 | 00:00:00.01 | 224 | 1517K | 1517K | 1189K (0) | |
| TABLE ACCESS BY INDEX ROWID | TAB1 | 1 | 1216 | 1112 | 00:00:00.01 | 209 | |||
| INDEX RANGE SCAN | TAB1_COL1 | 1 | 1216 | 1112 | 00:00:00.01 | 5 | |||
| TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 | 00:00:00.02 | 15 | |||
| INDEX RANGE SCAN | TAB2_COL1 | 1 | 2000 | 2000 | 00:00:00.01 | 8 |
Predicate Information (identified by operation id):
---
2 - access("A"."KEY1"="B"."KEY1")
3 - filter("KEY1" IS NOT NULL)
4 - access("COL1" LIKE '상품1%')
filter("COL1" LIKE '상품1%')
5 - filter("KEY1" IS NOT NULL)
6 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL1"<=TRUNC(SYSDATE@!))
| {CODE} |