2.3.6 스타조인 (by ljh1148) [2011.10.07]
2.3.6. 스타 조인
스타조인이란?
- 어떤 의미에서 볼 때는 새로운 방식의 조인이 아니라고도 할 수 있다.
- 개념적으로만 생각해 본다면 기존의 조인방식들로 수행하면서 단지 조인의 실행계획이 특정한 처리절차로 수행되는 것일 뿐이라고 할 수 있다.
- 스타라는 말이 사용된 연유는 조인된 집합들 가의 관계들이 마치 별 모양처럼 생겼기 때문에 붙여진 것이다.
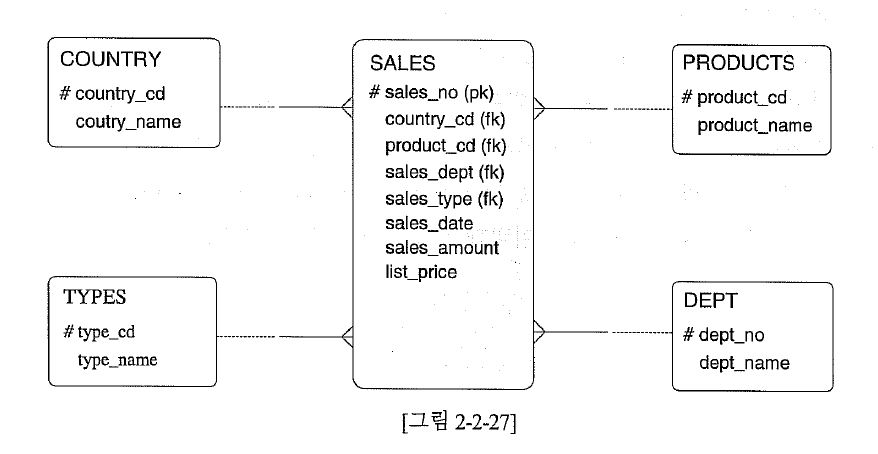
- 스타 스키마
위 그림의 문제점들...
- 1) 처리범위를 줄일 수 있는 조건들이 여러 테이블에 분산되어 있다는 점에 유의하자. ( 조인은 다이 다이 )
- 2) 각 테이블이 보유 하고 있는 조건들의 면면을 살펴보면 어느 것을 선택하더라도 처리 범위가 별로 줄어 들지 않는다는 것을 알 수 있다. ( SALES 테이블의 처림범위를 얼마나 효과적으로 줄일수 있는냐가 관건 )
- 3) SALES 테이블이 남의 도움을 받지 않고 수행할 수 있는 SALES_DATE는 3개월이나 되어 처리 범위가 만만치 않다. ( 스스로 힘들어 함 )
- 4) SALES_TYPE이나 SALES_DEPT의 도움을 받더라도 그렇게 많은 처리범위가 줄어들 것으로 보이지도 않는다.
- 5) 물론 이러한 경우를 대비해서 'SALES_TYPE + SALES_DATE' or 'SALES_DEPT + SALES_DATE, PRODUCT_CD + SALES_DATE'로 된 결합인덱스를 생성해 둔다면 얼마간 효과를 얻을 수 있다. ( 하지만 이런 인덱스 정책이라면 선택할 수 있는 해법은 아님 )
- 6) 물론 사용자 요구 사항이 적어 인덱스 개수가 그리 많지 않고, 효과 또한 크다면 적절한 인덱스 전략을 통해 해결이 가능하다.
- 7) 각 연결단계마다 조금씩 줄여 마지막 결과가 소량이 되었다면, 결과적으로 불필요한 처리가 많이 발생 했음을 의미한다.
- 8) 연결작업이 수행되고 난 결과 집합은 이미 기존의 테이블이 아니므로 이제 더 이상 인덱스를 가질 수 없다.
만약 NL 조인이라면 어쩔 수 없이 선행처리 집합이 되어서 다른 테이블을 랜덤으로 연결하게 되며, 해쉬조인이나 Sort Merge 조인이 되더라도 각 조인 단계의 결과 집합이 적지 않은 크리를 가지고 있으므로 부담이 된다.
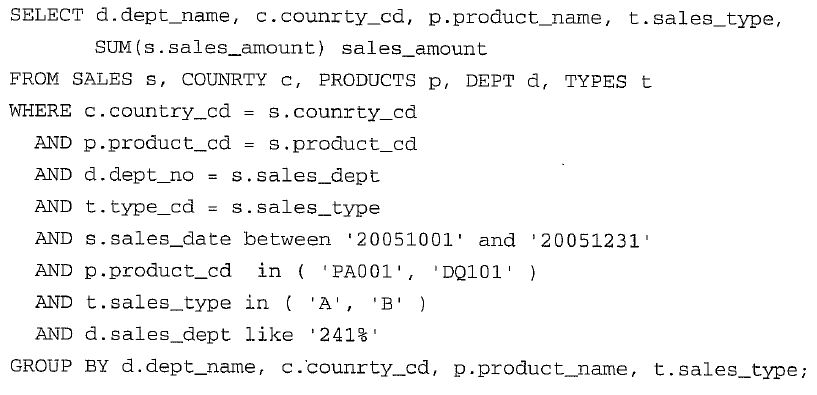
위 문제점을 해결 할 수있는 논리지적으로 가장 이상적인 처리 방법은.?
- 1) 소량의 데이터를 가지고 있는 집합들이 힘을 모아 상수 집합을 만든다.
- 2) 만든 상수집합을 일거에 SALES 테이블에 제공할 수만 있다면 대량의 데이터를 가진 SALES 테이블이 한 번만에 연결작업을 수행하게 된다.
- 3) 만약 적절한 인덱스가 존재해 이러한 상수값들로 처적의 처리범위를 줄여줄 수만 있다면 바로 소량의 결과만 추출할 수 있게 되므로 아주 이상적인처리방법이 될 것이다.
위 이상적인 방법을 실현하기 위해서는 반드시 해결해야되는 몇 가지 문제점은.?
- 1) 디멘전테이블 가에는 릴레이쉽이 없기 때문에 이들 간의 연결을 먼저 시도할 수 없다는 점 ( 디멘전테이블들 간의 카티션곱으로 해결 할수 있음 )
- 2) 상수 집합값에 해당하는 팩터테이블에 적절한 인덱스를 보유해야함 ( 어떤 디멘전 테이블이 사용될지 종잡을 수 없어서 인덱스 정책 수립이 쉽지만은 않다. 최적에 인덱스는 '=' )
- 3) D1, D2, D3, D4들의 디멘전 테이블 = 15가지 경우의 수 ( 2의 4승 ), 디멘저 테이블이 10개면 2의 10승 <= 이런 인덱스 정책문제가 가장 근본적인 문제임
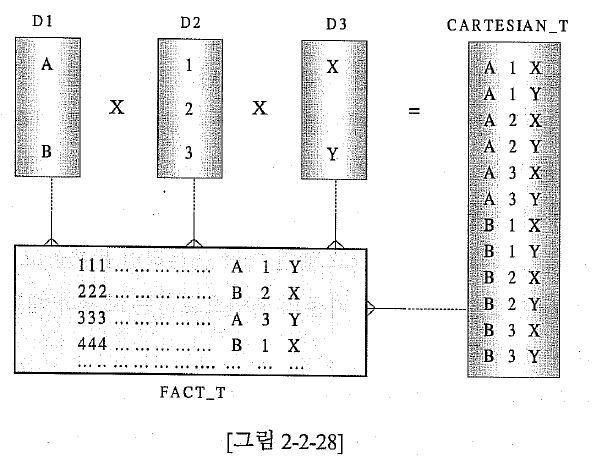
위 그림 설명...( 스타 조인 )
- 1) 디멘전 테이블 D1, D2, D3를 '무조건'( 카티션곱 ) 을 연결고리로 하여 조인하면 카티션 곱으로 만들어진 우측의 CARTESIAN_T와 같은 집합이 만들어 진다.
- 2) 쓸모없는 집합 같지만 3개의 디멘전 테이블들이 만들어 낼 수 모든 경우의 수를 가지고 있다.
- 3) 그림의 좌측 하단에 있는 FACT_T는 데이터모델 상으로는 디멘전 테이블들과 릴레이션쉽을 맺고 있다. 그러나 논리적으로 보면 우측의 CARTESIAN_T와 릴레이션쉽을 맺고 있다는 것과 동일한 의미가 된다.
- 4) 일반적으로 디멘전 테이블은 아주 소량으로 구성된다. 개수가 많지않다면 이들의 곱 또한 크게 걱정할 것이 없다. ( 2 * 3 * 2 = 12 )
- 5) 문제의 초점을 좀더 명확히 하기 위해 위 그림에 있는 FACT_T를 백만 건이라고 가정해보자. 어떤 조인 방식을 도입하건 FACT_T와 D1의 조인은 100만건과 두건의 연결이 발생하고
그 결과는 다시 백만 건이 되어 D2와 연결을 수행하여야 한다. 그 결과는 또 다시 백만건이 된다
그 결과를 또 또 다시 D3와 연결을 해야한다.
스타 조인에 주의 할점
- 1) 디멘저의 카티션 곱이 지나치게 많은 집합을 만들지 않을 때만 사용해야 한다.
- 2) 지나치게 높은 카디널리티가 가진 디멘저 테이블이 존재한다면.. 스타조인에 배제하고 경우에 따라서 먼저 조인을 수행시키든지, 아니면 최종 결과와 마지막으로 조인을 하는 것이 바람직하다.
| p. 606 준비 스크립트 |
|---|
| {CODE:SQL} |
SQL> SELECT * FROM V$VERSION WHERE ROWNUM <= 1;
BANNER
-
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
CREATE TABLE COUNTRY_JH TABLESPACE ORA03TS02 AS
SELECT TO_CHAR( LEVEL, 'FM000009' ) COUNTRY_CD
, 'NAME_'||LEVEL AS COUNTRY_NAME
FROM DUAL
CONNECT BY LEVEL <= 500
CREATE TABLE TYPES_JH TABLESPACE ORA03TS02 AS
SELECT CHR( 64 + LEVEL ) TYPE_CD
, 'NAME_'||CHR( 64 + LEVEL ) AS TYPE_NAME
FROM DUAL
CONNECT BY LEVEL <= 26
CREATE TABLE PRODUCTS_JH TABLESPACE ORA03TS02 AS
SELECT PRODCUT_CD2||PRODCUT_CD1||TO_CHAR( LV, 'FM009') AS PRODUCT_CD
, 'NAME_'||PRODCUT_CD2||PRODCUT_CD1||TO_CHAR( LV, 'FM009') AS PRODUCT_NAME
FROM (SELECT CHR( 64 + LEVEL ) PRODCUT_CD1 FROM DUAL CONNECT BY LEVEL <= 26 ) A
, (SELECT CHR( 64 + LEVEL ) PRODCUT_CD2 FROM DUAL CONNECT BY LEVEL <= 26 ) B
, (SELECT LEVEL LV FROM DUAL CONNECT BY LEVEL <= 101 ) C
--WHERE PRODCUT_CD2 = 'B'
CREATE TABLE DEPT_JH TABLESPACE ORA03TS02 AS
SELECT DISTINCT DEPT_NO, DEPT_NAME
FROM (
SELECT RPAD( LEVEL, 5, '0' ) AS DEPT_NO
, 'NAME_'|| RPAD( LEVEL, 5, '0' ) AS DEPT_NAME
FROM DUAL
CONNECT BY LEVEL <= 99999
)
CREATE TABLE SALES_JH TABLESPACE ORA03TS02 AS
SELECT LEVEL SALES_NO
, TO_CHAR( TRUNC( dbms_random.value( 1,501 ) ), 'FM000009' ) COUNTRY_CD
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || TO_CHAR( TRUNC( dbms_random.value( 1,102 ) ), 'FM009' ) PRODUCT_CD
, RPAD( TRUNC( dbms_random.value( 1,99999 + 1 ) ), 5, '0' ) SALES_DEPT
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) AS SALES_TYPE
, TO_CHAR( ( SYSDATE - 100 ) - 1 / 1440 / ( 60 / ( 2000001 - LEVEL )), 'YYYYMMDDHH24MISS' ) SALES_DATE
, TRUNC( dbms_random.value( 1,501 ) ) * 1000 AS SALES_AMOUNT
, 'list_price' AS LIST_PRICE
FROM DUAL
CONNECT BY LEVEL <= 2000000
ORA-30009: CONNECT BY 작업에 대한 메모리가 부족합니다. ㅡㅡ^
CREATE TABLE SALES_JH TABLESPACE ORA03TS02 AS
SELECT LEVEL SALES_NO
, TO_CHAR( TRUNC( dbms_random.value( 1,501 ) ), 'FM000009' ) COUNTRY_CD
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || TO_CHAR( TRUNC( dbms_random.value( 1,102 ) ), 'FM009' ) PRODUCT_CD
, RPAD( TRUNC( dbms_random.value( 1,99999 + 1 ) ), 5, '0' ) SALES_DEPT
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) AS SALES_TYPE
, TO_CHAR( ( SYSDATE - 100 ) - 1 / 1440 / ( 60 / ( 20000001 - LEVEL )), 'YYYYMMDDHH24MISS' ) SALES_DATE
, TRUNC( dbms_random.value( 1,501 ) ) * 1000 AS SALES_AMOUNT
, 'list_price' AS LIST_PRICE
FROM DUAL
CONNECT BY LEVEL <= 0
TRUNCATE TABLE SALES_JH;
BEGIN
FOR IDX IN 1 .. 50000000 LOOP
INSERT INTO SALES_JH
SELECT IDX SALES_NO
, TO_CHAR( TRUNC( dbms_random.value( 1,501 ) ), 'FM000009' ) COUNTRY_CD
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) || TO_CHAR( TRUNC( dbms_random.value( 1,102 ) ), 'FM009' ) PRODUCT_CD
, RPAD( TRUNC( dbms_random.value( 1,99999 + 1 ) ), 5, '0' ) SALES_DEPT
, CHR( TRUNC( 64+dbms_random.value( 1,27 ) ) ) AS SALES_TYPE
, TO_CHAR( ( SYSDATE - 100 ) - 1 / 1440 / ( 60 / ( 50000001 - IDX )), 'YYYYMMDDHH24MISS' ) SALES_DATE
, TRUNC( dbms_random.value( 1,501 ) ) * 1000 AS SALES_AMOUNT
, 'list_price' AS LIST_PRICE
FROM DUAL;
END LOOP;
COMMIT;
END;
CREATE UNIQUE INDEX COUNTRY_JH_PK ON COUNTRY_JH ( COUNTRY_CD ) TABLESPACE ORA03TS02
CREATE UNIQUE INDEX TYPES_JH_PK ON TYPES_JH ( TYPE_CD ) TABLESPACE ORA03TS02
CREATE UNIQUE INDEX PRODUCTS_JH_PK ON PRODUCTS_JH ( PRODUCT_CD ) TABLESPACE ORA03TS02
CREATE UNIQUE INDEX DEPT_JH_PK ON DEPT_JH ( DEPT_NO ) TABLESPACE ORA03TS02
CREATE INDEX SALES_JH_INDEX01 ON SALES_JH ( SALES_DEPT, PRODUCT_CD ) TABLESPACE ORA03TS02
-- 제약 조건 생성 후 통계정 보를 생성해야 STAR로 풀릴수 있다. ( 이거때무네.. ㅠ 4시간 삽질 )
ALTER TABLE DEPT_JH ADD (
CONSTRAINT DEPT_JH_PK
PRIMARY KEY
(DEPT_NO)
USING INDEX DEPT_JH_PK);
ALTER TABLE PRODUCTS_JH ADD (
CONSTRAINT PRODUCTS_JH_PK
PRIMARY KEY
(PRODUCT_CD)
USING INDEX PRODUCTS_JH_PK);
ALTER TABLE TYPES_JH ADD (
CONSTRAINT TYPES_JH_PK
PRIMARY KEY
(TYPE_CD)
USING INDEX TYPES_JH_PK);
ALTER TABLE COUNTRY_JH ADD (
CONSTRAINT COUNTRY_JH_PK
PRIMARY KEY
(COUNTRY_CD)
USING INDEX COUNTRY_JH_PK);
--ALTER TABLE TYPES_JH DROP CONSTRAINT SALES_JH_FK2;
ALTER TABLE SALES_JH ADD (
CONSTRAINT SALES_JH_FK4
FOREIGN KEY (SALES_DEPT) --SALES_DEPT 4 Y VARCHAR2 (20 Byte) Height Balanced 90144
REFERENCES DEPT_JH (DEPT_NO));
ALTER TABLE SALES_JH ADD (
CONSTRAINT SALES_JH_FK3
FOREIGN KEY (PRODUCT_CD) --SALES_TYPE 5 Y VARCHAR2 (4 Byte) Frequency 26
REFERENCES PRODUCTS_JH (PRODUCT_CD));
ALTER TABLE SALES_JH ADD (
CONSTRAINT SALES_JH_FK2
FOREIGN KEY (SALES_TYPE) --SALES_TYPE 5 Y VARCHAR2 (4 Byte) Frequency 26
REFERENCES TYPES_JH (TYPE_CD));
ALTER TABLE SALES_JH ADD (
CONSTRAINT SALES_JH_FK1
FOREIGN KEY (COUNTRY_CD)
REFERENCES COUNTRY_JH (COUNTRY_CD));
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'COUNTRY_JH' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TYPES_JH' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'PRODUCTS_JH' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'DEPT_JH' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'SALES_JH' );
| {CODE} |
| p.611 실행 스크립트 HASH JOIN |
|---|
| {CODE:SQL} |
SQL> SELECT * FROM V$VERSION WHERE ROWNUM <= 1;
BANNER
-
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
SQL> SELECT /*+ LEADING( D P ) STAR USE_MERGE( D P ) USE_HASH( S ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND P.PRODUCT_NAME IN ( 'NAME_AT080' , 'NAME_CP001' )
10 AND T.TYPE_NAME BETWEEN 'NAME_A' AND 'NAME_Z'
11 AND D.DEPT_NO LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_84500 000349 NAME_AT080 NAME_C 71000
NAME_85403 000259 NAME_AT080 NAME_C 306000
NAME_89292 000017 NAME_AT080 NAME_K 49000
NAME_82550 000044 NAME_AT080 NAME_L 170000
NAME_80668 000384 NAME_AT080 NAME_Z 447000
NAME_89112 000152 NAME_AT080 NAME_G 284000
NAME_86295 000424 NAME_CP001 NAME_S 490000
NAME_85235 000397 NAME_CP001 NAME_U 448000
NAME_81543 000247 NAME_AT080 NAME_M 408000
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_85080 000389 NAME_AT080 NAME_M 463000
NAME_82755 000382 NAME_AT080 NAME_P 238000
NAME_84957 000353 NAME_AT080 NAME_Z 328000
NAME_85309 000361 NAME_AT080 NAME_Y 4000
NAME_84937 000401 NAME_AT080 NAME_H 386000
NAME_85019 000457 NAME_CP001 NAME_N 461000
NAME_89567 000035 NAME_AT080 NAME_M 335000
NAME_80957 000379 NAME_AT080 NAME_T 74000
NAME_84640 000392 NAME_CP001 NAME_U 150000
NAME_81760 000354 NAME_CP001 NAME_R 28000
21 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:07.58 | 427K | 427K | |||||
| 1 | HASH GROUP BY | 1 | 1 | 21 | 00:00:07.58 | 427K | 427K | 813K | 813K | 1353K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:07.58 | 427K | 427K | |||||
| 3 | NESTED LOOPS | 1 | 1 | 21 | 00:00:07.58 | 427K | 427K | ||||
| HASH JOIN | 1 | 1 | 21 | 00:00:07.58 | 427K | 427K | 1861K | 1192K | 3041K (0) |
PLAN_TABLE_OUTPUT
| 5 | MERGE JOIN CARTESIAN | 1 | 19134 | 20000 | 00:00:00.05 | 492 | 0 | ||||
| TABLE ACCESS FULL | DEPT_JH | 1 | 9567 | 10000 | 00:00:00.02 | 279 | 0 | |||
| 7 | BUFFER SORT | 10000 | 2 | 20000 | 00:00:00.02 | 213 | 0 | 2048 | 2048 | 2048 (0) | |
| TABLE ACCESS FULL | PRODUCTS_JH | 1 | 2 | 2 | 00:00:00.01 | 213 | 0 | |||
| TABLE ACCESS FULL | SALES_JH | 1 | 261K | 288K | 00:00:07.42 | 427K | 427K | |||
| INDEX UNIQUE SCAN | TYPES_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 4 | 0 | |||
| TABLE ACCESS BY INDEX ROWID | TYPES_JH | 21 | 1 | 21 | 00:00:00.01 | 1 | 0 |
---
Predicate Information (identified by operation id):
---
4 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD" AND "D"."DEPT_NO"="S"."SALES_DEPT")
6 - filter("D"."DEPT_NO" LIKE '8%')
8 - filter(("P"."PRODUCT_NAME"='NAME_AT080' OR "P"."PRODUCT_NAME"='NAME_CP001'))
9 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."SALES_DEPT" LIKE '8%' AND "S"."COUNTRY_CD" IS NOT NULL))
10 - access("T"."TYPE_CD"="S"."SALES_TYPE")
11 - filter(("T"."TYPE_NAME">='NAME_A' AND "T"."TYPE_NAME"<='NAME_Z'))
| {CODE} * (a) 스타조인은 반드시 비용기준( Cost_based ) 옵티마이져 모드에서 수행되어야 한다. 또한 통계 정보를 생성해 주어야 작동 할 수 있다. ( 또한 PK AND FK 꼭필요하다 ( 주관 ) ) 원하는 실행계획이 생성되지 않을 때는 /*+ STAR */힌트를 적용한다. * (b) 디멘저 테이블들이 먼저 조인하여 카티션 곱을 만들어 내는 것을 확인할 수 있다. 이처럼 카티션 곱을 생성하는 대부분의 경우는 Sort Merge 조인 형식으로 나타난다. * © 카티션 곱을 좀더 효율적으로 생성하기 위해 정렬을 한 집합을 버퍼에 저장해 두는 것을 보여 주고 있다. * (d) 카티션 곱으로 생성된 집합과 팩트 테이블인 Sales 테이블이 해쉬 조이을 하고 있음을 확인할 수 있다, 그러나 이 단계가 항상 해쉬 조이이 되는 것은 아니다. 어쩌면 이 단계는이미 스타조인의 문제가 아니다. 단지 준비된 두 개의 집합이 가장 효율적인 조인형식을 선택하는 문제가 남아 있을 뿐이다. * (d)에서 제기된 문제가 바로 앞에서 우리가 해결하기 위해 남겨 두었던 바로 그 두 번재 문제이다. 카티션 곱의 집합은 이미 인덱스를 가질 수 없고, 팩트 테이블은 디멘전 테이블들의 수많은 조합을 모두 감당할 인덱스를 미리 구성하기가 어려우므로 인덱스를 사용하지 않는 해쉬 조인이나 Sort Merge 조인으로 수행하는 것이 바람직한 방법이다. |
| 그럼 머지로 해보져... ( 비슷하군요 ) |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( D P ) STAR USE_MERGE( D P ) USE_MERGE( S ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND P.PRODUCT_NAME IN ( 'NAME_AT080' , 'NAME_CP001' )
10 AND T.TYPE_NAME BETWEEN 'NAME_A' AND 'NAME_Z'
11 AND D.DEPT_NO LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_84500 000349 NAME_AT080 NAME_C 71000
NAME_85403 000259 NAME_AT080 NAME_C 306000
NAME_82550 000044 NAME_AT080 NAME_L 170000
NAME_89292 000017 NAME_AT080 NAME_K 49000
NAME_80668 000384 NAME_AT080 NAME_Z 447000
NAME_89112 000152 NAME_AT080 NAME_G 284000
NAME_85235 000397 NAME_CP001 NAME_U 448000
NAME_86295 000424 NAME_CP001 NAME_S 490000
NAME_81543 000247 NAME_AT080 NAME_M 408000
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_82755 000382 NAME_AT080 NAME_P 238000
NAME_85080 000389 NAME_AT080 NAME_M 463000
NAME_84937 000401 NAME_AT080 NAME_H 386000
NAME_84957 000353 NAME_AT080 NAME_Z 328000
NAME_85309 000361 NAME_AT080 NAME_Y 4000
NAME_80957 000379 NAME_AT080 NAME_T 74000
NAME_89567 000035 NAME_AT080 NAME_M 335000
NAME_81760 000354 NAME_CP001 NAME_R 28000
NAME_84640 000392 NAME_CP001 NAME_U 150000
NAME_85019 000457 NAME_CP001 NAME_N 461000
21 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:07.55 | 427K | 427K | |||||
| 1 | HASH GROUP BY | 1 | 1 | 21 | 00:00:07.55 | 427K | 427K | 813K | 813K | 1356K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:07.55 | 427K | 427K | |||||
| 3 | NESTED LOOPS | 1 | 1 | 21 | 00:00:07.55 | 427K | 427K | ||||
| 4 | MERGE JOIN | 1 | 1 | 21 | 00:00:07.55 | 427K | 427K | ||||
| 5 | SORT JOIN | 1 | 19134 | 20000 | 00:00:00.07 | 492 | 0 | 1328K | 587K | 1180K (0) | |
| 6 | MERGE JOIN CARTESIAN | 1 | 19134 | 20000 | 00:00:00.05 | 492 | 0 | ||||
| TABLE ACCESS FULL | DEPT_JH | 1 | 9567 | 10000 | 00:00:00.02 | 279 | 0 | |||
| 8 | BUFFER SORT | 10000 | 2 | 20000 | 00:00:00.02 | 213 | 0 | 2048 | 2048 | 2048 (0) | |
| TABLE ACCESS FULL | PRODUCTS_JH | 1 | 2 | 2 | 00:00:00.01 | 213 | 0 | |||
| SORT JOIN | 20000 | 261K | 21 | 00:00:07.48 | 427K | 427K | 15M | 1472K | 13M (0) | |
| TABLE ACCESS FULL | SALES_JH | 1 | 261K | 288K | 00:00:07.34 | 427K | 427K | |||
| INDEX UNIQUE SCAN | TYPES_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 4 | 0 | |||
| TABLE ACCESS BY INDEX ROWID | TYPES_JH | 21 | 1 | 21 | 00:00:00.01 | 1 | 0 |
---
Predicate Information (identified by operation id):
---
7 - filter("D"."DEPT_NO" LIKE '8%')
9 - filter(("P"."PRODUCT_NAME"='NAME_AT080' OR "P"."PRODUCT_NAME"='NAME_CP001'))
10 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD" AND "D"."DEPT_NO"="S"."SALES_DEPT")
filter(("D"."DEPT_NO"="S"."SALES_DEPT" AND "P"."PRODUCT_CD"="S"."PRODUCT_CD"))
11 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."SALES_DEPT" LIKE '8%' AND "S"."COUNTRY_CD" IS NOT NULL))
12 - access("T"."TYPE_CD"="S"."SALES_TYPE")
13 - filter(("T"."TYPE_NAME">='NAME_A' AND "T"."TYPE_NAME"<='NAME_Z'))
| {CODE} |
우리가 매우 주의해야 할 사항이 한 가지 있다. 우선 다음의 실행계획을 살펴보기로 하자.
| p.613 실행 스크립트 NL JOIN |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( D P T ) STAR USE_MERGE( D P T ) USE_NL( S ) FULL( D ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND P.PRODUCT_NAME IN ( 'NAME_AT080' , 'NAME_CP001' )
10 AND T.TYPE_NAME BETWEEN 'NAME_A' AND 'NAME_Z'
11 AND D.DEPT_NO LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_85403 000259 NAME_AT080 NAME_C 306000
NAME_84500 000349 NAME_AT080 NAME_C 71000
NAME_82550 000044 NAME_AT080 NAME_L 170000
NAME_89292 000017 NAME_AT080 NAME_K 49000
NAME_80668 000384 NAME_AT080 NAME_Z 447000
NAME_89112 000152 NAME_AT080 NAME_G 284000
NAME_86295 000424 NAME_CP001 NAME_S 490000
NAME_85235 000397 NAME_CP001 NAME_U 448000
NAME_85080 000389 NAME_AT080 NAME_M 463000
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_81543 000247 NAME_AT080 NAME_M 408000
NAME_82755 000382 NAME_AT080 NAME_P 238000
NAME_84937 000401 NAME_AT080 NAME_H 386000
NAME_85309 000361 NAME_AT080 NAME_Y 4000
NAME_84957 000353 NAME_AT080 NAME_Z 328000
NAME_84640 000392 NAME_CP001 NAME_U 150000
NAME_85019 000457 NAME_CP001 NAME_N 461000
NAME_81760 000354 NAME_CP001 NAME_R 28000
NAME_80957 000379 NAME_AT080 NAME_T 74000
NAME_89567 000035 NAME_AT080 NAME_M 335000
21 개의 행이 선택되었습니다.
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:01.88 | 129K | 43 | |||||
| 1 | HASH GROUP BY | 1 | 1 | 21 | 00:00:01.88 | 129K | 43 | 813K | 813K | 1353K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:01.88 | 129K | 43 | |||||
| 3 | NESTED LOOPS | 1 | 1 | 4394 | 00:00:01.87 | 128K | 43 | ||||
| 4 | MERGE JOIN CARTESIAN | 1 | 497K | 520K | 00:00:00.40 | 495 | 1 | ||||
| 5 | MERGE JOIN CARTESIAN | 1 | 19134 | 20000 | 00:00:00.08 | 492 | 1 | ||||
| TABLE ACCESS FULL | DEPT_JH | 1 | 9567 | 10000 | 00:00:00.04 | 279 | 1 | |||
| 7 | BUFFER SORT | 10000 | 2 | 20000 | 00:00:00.02 | 213 | 0 | 2048 | 2048 | 2048 (0) | |
| TABLE ACCESS FULL | PRODUCTS_JH | 1 | 2 | 2 | 00:00:00.01 | 213 | 0 | |||
| 9 | BUFFER SORT | 20000 | 26 | 520K | 00:00:00.16 | 3 | 0 | 2048 | 2048 | 2048 (0) | |
| TABLE ACCESS FULL | TYPES_JH | 1 | 26 | 26 | 00:00:00.01 | 3 | 0 | |||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 520K | 1 | 4394 | 00:00:01.25 | 128K | 42 | |||
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 4394 | 1 | 21 | 00:00:00.01 | 219 | 0 |
Predicate Information (identified by operation id):
---
6 - filter("D"."DEPT_NO" LIKE '8%')
8 - filter(("P"."PRODUCT_NAME"='NAME_AT080' OR "P"."PRODUCT_NAME"='NAME_CP001'))
10 - filter(("T"."TYPE_NAME">='NAME_A' AND "T"."TYPE_NAME"<='NAME_Z'))
11 - access("D"."DEPT_NO"="S"."SALES_DEPT" AND "P"."PRODUCT_CD"="S"."PRODUCT_CD")
filter("S"."SALES_DEPT" LIKE '8%')
12 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."COUNTRY_CD" IS NOT NULL AND "T"."TYPE_CD"="S"."SALES_TYPE"))
| {CODE} * 카티션 집합과 팩트 테이블이 NL 조인으로 풀렸다. * SALES_JH_INDEX01이 'DEPT_NO + PRODUCT_CD'( 순서는 무관 )로 구성 되어 있다면 문제가 없다. * 만약 인덱스가 'DEPT_NO + SALES_TYPE + PRODUCT_CD'로 구성되어 있다면 상황은 달라진다. 중간에 있는 SALES_TYPE이 상수값을 제공받지 못한 상태에서 인덱스가 사용된다는 것은 결합 인덱스의 원리에 의해서 비효율이 발생하게 된다. 옵티마이젼느 이러한 인덱스를 구성일 때도 NL 조인으로 실행계획을 수립하는 경향이 많이 있다. * 이처럼 전략적이지 못한 인덱스가 존재한다면 스타조인이 NL 형식으로 처리될 때 문제가 발생하는 경우가 많으므로 가장 우선적으로 해야할 일은 전략적인 인덱스를 구성하는 것이며, 그 다음은 옵티마이져가 수립한 실행계획을 확인할 필요가 있다는 점을 명심하길 바란다. |
왜 디멘저 테이블을 FS 으로 풀었냐구요? 조건절 이행으로 인한 펙터 테이블이 선두 테이블로 되기 때문에...
| 조건절 이행인지 아닌지 확인 테스트 |
|---|
| {CODE:SQL} |
CREATE UNIQUE INDEX DEPT_JH_INDEX01 ON DEPT_JH ( TRIM( DEPT_NO ) ) TABLESPACE ORA03TS02
CREATE UNIQUE INDEX PRODUCTS_JH_INDEX01 ON PRODUCTS_JH ( TRIM( PRODUCT_CD ) ) TABLESPACE ORA03TS02
CREATE UNIQUE INDEX TYPES_JH_INDEX01 ON TYPES_JH ( TRIM( TYPE_CD ) ) TABLESPACE ORA03TS02
SQL> SELECT /*+ LEADING( D P T ) STAR USE_MERGE( D P T ) USE_NL( S ) INDEX( T TYPES_JH_INDEX01 ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND TRIM( P.PRODUCT_CD ) IN ( 'AT080' , 'CP001' )
10 AND TRIM( T.TYPE_CD ) BETWEEN 'A' AND 'Z'
11 AND TRIM( D.DEPT_NO) LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_84500 000349 NAME_AT080 NAME_C 71000
NAME_85403 000259 NAME_AT080 NAME_C 306000
NAME_82550 000044 NAME_AT080 NAME_L 170000
NAME_89292 000017 NAME_AT080 NAME_K 49000
NAME_80668 000384 NAME_AT080 NAME_Z 447000
NAME_89112 000152 NAME_AT080 NAME_G 284000
NAME_85235 000397 NAME_CP001 NAME_U 448000
NAME_86295 000424 NAME_CP001 NAME_S 490000
NAME_81543 000247 NAME_AT080 NAME_M 408000
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_82755 000382 NAME_AT080 NAME_P 238000
NAME_85080 000389 NAME_AT080 NAME_M 463000
NAME_84937 000401 NAME_AT080 NAME_H 386000
NAME_84957 000353 NAME_AT080 NAME_Z 328000
NAME_85309 000361 NAME_AT080 NAME_Y 4000
NAME_80957 000379 NAME_AT080 NAME_T 74000
NAME_81760 000354 NAME_CP001 NAME_R 28000
NAME_84640 000392 NAME_CP001 NAME_U 150000
NAME_85019 000457 NAME_CP001 NAME_N 461000
NAME_89567 000035 NAME_AT080 NAME_M 335000
21 개의 행이 선택되었습니다.
SQL> @XPLAN
– TFS 더 효과적이군요 ㅎ
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:01.14 | 137K | |||||
| 1 | HASH GROUP BY | 1 | 3 | 21 | 00:00:01.14 | 137K | 813K | 813K | 1326K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:01.14 | 137K | |||||
| 3 | NESTED LOOPS | 1 | 3 | 4394 | 00:00:01.14 | 137K | ||||
| 4 | MERGE JOIN CARTESIAN | 1 | 199K | 520K | 00:00:00.28 | 9086 | ||||
| 5 | MERGE JOIN CARTESIAN | 1 | 3072K | 20000 | 00:00:00.04 | 9084 | ||||
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 1 | 4500 | 10000 | 00:00:00.02 | 9078 | |||
| INDEX RANGE SCAN | DEPT_JH_INDEX01 | 1 | 810 | 10000 | 00:00:00.01 | 24 | |||
| 8 | BUFFER SORT | 10000 | 683 | 20000 | 00:00:00.01 | 6 | 2048 | 2048 | 2048 (0) | |
| 9 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 6 | |||||
| 10 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 683 | 2 | 00:00:00.01 | 6 | |||
| INDEX UNIQUE SCAN | PRODUCTS_JH_INDEX01 | 2 | 273 | 2 | 00:00:00.01 | 4 | |||
| 12 | BUFFER SORT | 20000 | 1 | 520K | 00:00:00.12 | 2 | 2048 | 2048 | 2048 (0) | |
| 13 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 1 | 1 | 26 | 00:00:00.01 | 2 | |||
| INDEX RANGE SCAN | TYPES_JH_INDEX01 | 1 | 1 | 26 | 00:00:00.01 | 1 | |||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 520K | 1 | 4394 | 00:00:00.69 | 128K | |||
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 4394 | 1 | 21 | 00:00:00.01 | 219 |
---
Predicate Information (identified by operation id):
---
7 - access("D"."SYS_NC00003$" LIKE '8%')
filter("D"."SYS_NC00003$" LIKE '8%')
11 - access(("P"."SYS_NC00003$"='AT080' OR "P"."SYS_NC00003$"='CP001'))
14 - access("T"."SYS_NC00003$">='A' AND "T"."SYS_NC00003$"<='Z')
15 - access("D"."DEPT_NO"="S"."SALES_DEPT" AND "P"."PRODUCT_CD"="S"."PRODUCT_CD")
16 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."COUNTRY_CD" IS NOT NULL AND "T"."TYPE_CD"="S"."SALES_TYPE"))
| {CODE} |
만약 힌트가 제대로 작동하지 않는다거나 이런한 힌트를 가지고 있지 않는 DBMS를 사용하고 있다면 억지로라도 이러한 실행계획이 나타나도록 하는 방법은.?
| p. 613 실행 스크립트 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ USE_HASH( D F ) */ COUNTRY_NAME, PRODUCT_NAME, SALES_TYPE --D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( F.SALES_AMOUNT )
3 FROM (SELECT ROWNUM, PRODUCT_CD, PRODUCT_NAME, COUNTRY_CD, COUNTRY_NAME
4 FROM PRODUCTS_JH, COUNTRY_JH
5 WHERE PRODUCT_CD IN ( 'AT080' , 'CP001' ) ) D, SALES_JH F
6 WHERE F.PRODUCT_CD = D.PRODUCT_CD
7 AND F.COUNTRY_CD = D.COUNTRY_CD
8 AND F.SALES_DATE LIKE '201104%'
9 GROUP BY COUNTRY_NAME, PRODUCT_NAME, SALES_TYPE ;
COUNTRY_NAME PRODUCT_NAME SALES_TY SUM(F.SALES_AMOU
--
--
NAME_99 NAME_CP001 W 334
NAME_436 NAME_AT080 D 375
...
90 개의 행이 선택되었습니다.
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--
| 0 | SELECT STATEMENT | 1 | 90 | 00:00:07.89 | 427K | 427K | - (a) | 1 | HASH GROUP BY | 1 | 69 | 90 | 00:00:07.89 | 427K | 427K | 849K | 849K | 1326K (0) | |||||||||||||||||||
| HASH JOIN | 1 | 69 | 91 | 00:00:07.89 | 427K | 427K | 904K | 904K | 1254K (0) | - (d) | 3 | VIEW | 1 | 1000 | 1000 | 00:00:00.03 | 10 | 6 | ||||||||||||||||||
| 4 | COUNT | 1 | 1000 | 00:00:00.03 | 10 | 6 | - © | 5 | MERGE JOIN CARTESIAN | 1 | 1000 | 1000 | 00:00:00.03 | 10 | 6 | - (b) | 6 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 6 | 3 | ||||||||||||||
| 7 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 2 | 2 | 00:00:00.01 | 6 | 3 | |||||||||||||||||||||||||||||
| INDEX UNIQUE SCAN | PRODUCTS_JH_PK | 2 | 2 | 2 | 00:00:00.01 | 4 | 3 | |||||||||||||||||||||||||||||
| 9 | BUFFER SORT | 2 | 500 | 1000 | 00:00:00.01 | 4 | 3 | 27648 | 27648 | 24576 (0) | |||||||||||||||||||||||||||
| 10 | TABLE ACCESS FULL | COUNTRY_JH | 1 | 500 | 500 | 00:00:00.01 | 4 | 3 | |||||||||||||||||||||||||||||
| TABLE ACCESS FULL | SALES_JH | 1 | 2369K | 2591K | 00:00:06.99 | 427K | 427K |
--
Predicate Information (identified by operation id):
---
2 - access("F"."PRODUCT_CD"="D"."PRODUCT_CD" AND "F"."COUNTRY_CD"="D"."COUNTRY_CD")
8 - access(("PRODUCT_CD"='AT080' OR "PRODUCT_CD"='CP001'))
11 - filter("F"."SALES_DATE" LIKE '201104%')
| {CODE} * (a) SQL이 비용기준으로 정의 되어 있지 않은 것을 보여주고 있다.. ( ㅡㅡ^ ) 위 실행계획은 스타조인에 의해 만드어진 것이 아님을 의미하고 있다. * (b) 인라인뷰를 사용하여 강제로 디메전 테이블이 먼저 조인되도록 하여 카티션이 나타났다. * © 'COUNT'는 사실 없어도 무관한 단계이기는 하지만 위의 SQL에 있는 인라인뷰의 'ROWNUM' 때문에 생겨난 것이다. ( NO_MERGE 힌트와 같은 효과 ) ROWNUM이 가시는 가상속성 때문에 병합이 방지하는 효과를 가져오게 된다. 물론 힌트만 제대로 작동된다는 보장만 있다면 'NO_MERGE'힌트를 사용하여 동일한 효과를 낼 수가 있다. * (d) 해쉬조인 힌트를 사용하여 카티션곱과 팩트 테이블의 최적의 조인을 하도록 유도하였다. |
스타 조인은 단점 2가지.?
- 디멘전의 카티션 곱이 너무 클 때는 사용해서는 안된다
- 최종적으로 연결해야 할 팩트 테이블과의 조인 방식에 유의해야 한다.
해쉬 조인 : NL 조인처럼 선행집합의 처리 결과를 완벽하게 자기 집합의 처리범위를 줄일 수는 없다는데 한계가 있다.
NL 조인 : 완벽한 결합 인덱스가 없다면 무용지밀이 된다.(이를 대비하기 위한 모든 사용형태에 대한 결합 인덱스를 만들어 줄수 없다면 아직 이러한 방법은 최적이 아니다.
2.3.7 스타 변형 조인.?
- 스타변형 조인은 스타조인의 일부 단점을 개선한 조인이다. ( 스타조인을 완전히 대체하는 개념이 아니라는 것을 먼저 밝혀둔다 )
- 스타조인을 필요없게 만드는 것이 아니라 스타 조인이 갖는 단점을 개선할 수 있다는 것에 의미를 두기 바란다.
- 비트맵 인덱스의 특성을 살린 것이다. 따라서 비트맵 인덱스의 장.단점을 그대로 승계하고 있다.
- 스타조인은 카티젼 곱을 만들지만 스타변형조인은 비트맵 인덱스를 활용한다.
- 비트맵 인덱스는 액세스 형태에 따라 중간에 사용되지 않는 컬럼이 발생하지 않도록 다양한 형태의 결합인덱스를 구성해야하는 B-Tree 인덱스와는 달리
각가의 독립적인 비트맵 인덱스가 액세스 형태에 따라 그때마다 머지하는 방식으로 처리되더라도 수행속다가 나빠지지 않는다.
인덱스 머지의 장점.?
- 1) 수많은 결합 인덱스를 가지지 않도록 할 수 있다.
- 2) 팩트 테이블을 연결하기전에 먼저 처리되어 팩트 테이블의 처리범위를 공동으로 줄여 줄 수 있다는 것이다.
| p. 618 실습 스크립트 |
|---|
| {CODE:SQL} |
CREATE INDEX SALES_JH_INDEX02 ON SALES_JH ( PRODUCT_CD ) TABLESPACE ORA03TS02
SQL> SELECT /*+ INDEX_COMBINE(A A( PRODUCT_CD ) A( SALES_DEPT ) ) */ COUNT( * )
2 FROM SALES_JH A
3 WHERE PRODUCT_CD LIKE 'PA%'
4 AND SALES_DEPT LIKE '456%'
5 ;
COUNT(*)
--
70
SQL> @XPLAN
-
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--
| 0 | SELECT STATEMENT | 1 | 1 | 00:00:00.01 | 180 | 179 | ||
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.01 | 180 | 179 | |
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 1 | 1 | 70 | 00:00:00.01 | 180 | 179 |
-
Predicate Information (identified by operation id):
---
2 - access("SALES_DEPT" LIKE '456%' AND "PRODUCT_CD" LIKE 'PA%')
filter(("PRODUCT_CD" LIKE 'PA%' AND "SALES_DEPT" LIKE '456%'))
SQL> @hidden_param _b_tree_bitmap_plans
Enter value for v_par: _b_tree_bitmap_plans
old 8: AND LOWER(A.KSPPINM) LIKE '%'|| TRIM(LOWER('&v_par')) || '%'
new 8: AND LOWER(A.KSPPINM) LIKE '%'|| TRIM(LOWER('_b_tree_bitmap_plans')) || '%'
NAME
VALUE
DEF_YN
-
DESCRIPTION
_b_tree_bitmap_plans
TRUE
TRUE
enable the use of bitmap plans for tables w. only B-tree indexes
DROP INDEX SALES_JH_INDEX01
CREATE INDEX SALES_JH_INDEX01 ON SALES_JH ( SALES_DEPT ) TABLESPACE ORA03TS02
SQL> SELECT /*+ INDEX_COMBINE(A A( PRODUCT_CD ) A( SALES_DEPT ) ) */ COUNT( * )
2 FROM SALES_JH A
3 WHERE PRODUCT_CD LIKE 'PA%'
4 AND SALES_DEPT LIKE '456%'
5 ;
COUNT(*)
--
70
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--
| 0 | SELECT STATEMENT | 1 | 1 | 00:00:00.16 | 313 | 309 | |||||
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.16 | 313 | 309 | ||||
| VIEW | index$_join$_001 | 1 | 1 | 70 | 00:00:00.16 | 313 | 309 | |||
| HASH JOIN | 1 | 70 | 00:00:00.16 | 313 | 309 | 3755K | 1398K | 5578K (0) | ||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 1 | 1 | 74378 | 00:00:00.05 | 179 | 176 | |||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 1 | 1 | 55267 | 00:00:00.02 | 134 | 133 |
--
Predicate Information (identified by operation id):
---
2 - filter(("PRODUCT_CD" LIKE 'PA%' AND "SALES_DEPT" LIKE '456%'))
3 - access(ROWID=ROWID)
4 - access("PRODUCT_CD" LIKE 'PA%')
5 - access("SALES_DEPT" LIKE '456%')
SQL> SELECT /*+ INDEX_COMBINE(A ) */ COUNT( * )
2 FROM SALES_JH A
3 WHERE PRODUCT_CD LIKE 'PA%'
4 AND SALES_DEPT LIKE '456%'
5 ;
COUNT(*)
--
70
SQL> @XPLAN
--
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--
| 0 | SELECT STATEMENT | 1 | 1 | 00:00:00.21 | 313 | |||||||||||||||||
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.21 | 313 | ||||||||||||||||
| 2 | BITMAP CONVERSION COUNT | 1 | 1 | 1 | 00:00:00.21 | 313 | ||||||||||||||||
| 3 | BITMAP AND | 1 | 1 | 00:00:00.20 | 313 | <--- | 4 | BITMAP CONVERSION FROM ROWIDS | 1 | 7 | 00:00:00.11 | 179 | ||||||||||
| 5 | SORT ORDER BY | 1 | 74378 | 00:00:00.09 | 179 | 2320K | 704K | 2062K (0) | ||||||||||||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 1 | 74378 | 00:00:00.04 | 179 | ||||||||||||||||
| 7 | BITMAP CONVERSION FROM ROWIDS | 1 | 5 | 00:00:00.08 | 134 | |||||||||||||||||
| 8 | SORT ORDER BY | 1 | 55267 | 00:00:00.07 | 134 | 1824K | 650K | 1621K (0) | ||||||||||||||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 1 | 55267 | 00:00:00.03 | 134 |
--
Predicate Information (identified by operation id):
---
6 - access("PRODUCT_CD" LIKE 'PA%')
filter(("PRODUCT_CD" LIKE 'PA%' AND "PRODUCT_CD" LIKE 'PA%'))
9 - access("SALES_DEPT" LIKE '456%')
filter(("SALES_DEPT" LIKE '456%' AND "SALES_DEPT" LIKE '456%'))
| {CODE} * 각각을 서로 결합( BITMAP AND )하여 테이블을 액세스한다. 우리가 너무나 잘 알고 있는 비트맵 인덱스의 기본형이다. * 부여 받을 상수값이 다른 테이블에 존재할 경우 이를 서브쿼리를 통해서 제공할 수 있다고 생각하라는 것이다. |
| 모든 서브쿼리가 먼저 수행되어 그 결과를 메인 쿼리의 비트맵 인덱스에게 제공하여 각각 비트맵을 액세스한 후에 이들을 'BITMAP AND' 연산의 가장 이상적인 실행계획 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ INDEX_COMBINE( A ) STAR_TRANSFORMATION */ COUNT( * )
2 FROM SALES_JH A
3 WHERE PRODUCT_CD IN ( SELECT /*+ */PRODUCT_CD
4 FROM PRODUCTS_JH
5 WHERE TRIM( PRODUCT_CD ) LIKE 'PA%' )
6 AND SALES_DEPT IN ( SELECT /*+ */ DEPT_NO
7 FROM DEPT_JH
8 WHERE TRIM( DEPT_NO ) LIKE '456%' )
9 ;
COUNT(*)
--
70
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
| 0 | SELECT STATEMENT | 1 | 1 | 00:00:00.67 | 814 | 135 | ||||||||||||||||||
| 1 | SORT AGGREGATE | 1 | 1 | 1 | 00:00:00.67 | 814 | 135 | |||||||||||||||||
| 2 | BITMAP CONVERSION COUNT | 1 | 124K | 1 | 00:00:00.67 | 814 | 135 | |||||||||||||||||
| 3 | BITMAP AND | 1 | 1 | 00:00:00.67 | 814 | 135 | ||||||||||||||||||
| 4 | BITMAP MERGE | 1 | 7 | 00:00:00.35 | 386 | 72 | 1024K | 512K | ||||||||||||||||
| 5 | BITMAP KEY ITERATION | 1 | 101 | 00:00:00.12 | 386 | 72 | ||||||||||||||||||
| 6 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 1 | 3414 | 101 | 00:00:00.02 | 4 | 4 | -- (a) |
| INDEX RANGE SCAN | PRODUCTS_JH_INDEX01 | 1 | 614 | 101 | 00:00:00.01 | 3 | 3 | ||||||
| 8 | BITMAP CONVERSION FROM ROWIDS | 101 | 101 | 00:00:00.10 | 382 | 68 | ---(b) |
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 101 | 74378 | 00:00:00.08 | 382 | 68 | |||||||||
| 10 | BITMAP MERGE | 1 | 5 | 00:00:00.31 | 428 | 63 | 1024K | 512K | 254K (0) | |||||||||||||||
| 11 | BITMAP KEY ITERATION | 1 | 100 | 00:00:00.10 | 428 | 63 | ||||||||||||||||||
| 12 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 1 | 4500 | 100 | 00:00:00.06 | 93 | 12 | ||||||||||||||||
| INDEX RANGE SCAN | DEPT_JH_INDEX01 | 1 | 810 | 100 | 00:00:00.01 | 2 | 0 | ||||||||||||||||
| 14 | BITMAP CONVERSION FROM ROWIDS | 100 | 100 | 00:00:00.04 | 335 | 51 | ||||||||||||||||||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 100 | 55267 | 00:00:00.02 | 335 | 51 |
Predicate Information (identified by operation id):
---
7 - access("PRODUCTS_JH"."SYS_NC00003$" LIKE 'PA%')
filter("PRODUCTS_JH"."SYS_NC00003$" LIKE 'PA%')
9 - access("PRODUCT_CD"="PRODUCT_CD")
13 - access("DEPT_JH"."SYS_NC00003$" LIKE '456%')
filter("DEPT_JH"."SYS_NC00003$" LIKE '456%')
15 - access("SALES_DEPT"="DEPT_NO")
| {CODE} * 이전 쿠리랑 동일 하고 비트맵 머지( BITMAP MERGE )를 하는 것만 추가되어 있다. * (a) 서브쿼리 테이블을 액세서( 머전 인덱스 부터 )하여 그 결과값으로 메인쿼리의 비트리 인덱스 (b)를 엑세스( BITMAP KEY ITERATION )하여 BITMAP CONVERSION 해서 임시 비트맵으로 머지( BITMAP MERGE )해 두고 있다. * 스타변형조인의 기본 원리이다. |
| p. 621 실행 스크립트 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( S ) STAR_TRANSFORMATION INDEX_COMBINE( S ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND S.PRODUCT_CD IN ( SELECT PRODUCT_CD FROM PRODUCTS_JH WHERE TRIM( PRODUCT_CD ) IN ( 'AT080' , 'CP001' ))
10 AND ( S.SALES_TYPE ) IN (SELECT TYPE_CD FROM TYPES_JH WHERE TRIM( TYPE_CD ) BETWEEN 'A' AND 'Z' )
11 AND S.SALES_DEPT IN ( SELECT DEPT_NO FROM DEPT_JH WHERE TRIM( DEPT_NO ) LIKE '8%' )
12 -- AND ROWNUM <= 5
13 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
...
21 개의 행이 선택되었습니다.
SQL>
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
| 0 | SELECT STATEMENT | 1 | 21 | 00:01:16.81 | 134K | 102K | |||||
| 1 | HASH GROUP BY | 1 | 49 | 21 | 00:01:16.81 | 134K | 102K | 813K | 813K | 1356K (0) | |
| HASH JOIN | 1 | 49 | 21 | 00:01:16.81 | 134K | 102K | 889K | 889K | 1263K (0) | |
| HASH JOIN | 1 | 49 | 21 | 00:01:16.77 | 133K | 102K | 915K | 915K | 582K (0) | |
| HASH JOIN | 1 | 49 | 21 | 00:01:16.74 | 133K | 102K | 947K | 947K | 1181K (0) | |
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 1 | 49 | 21 | 00:01:16.72 | 133K | 102K | |||
| 6 | BITMAP CONVERSION TO ROWIDS | 1 | 169 | 00:01:16.72 | 133K | 102K | |||||
| 7 | BITMAP AND | 1 | 1 | 00:01:16.72 | 133K | 102K | |||||
| 8 | BITMAP MERGE | 1 | 1 | 00:00:00.09 | 16 | 0 | 1024K | 512K | 7168 (0) | ||
| 9 | BITMAP KEY ITERATION | 1 | 2 | 00:00:00.01 | 16 | 0 | |||||
| 10 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 6 | 0 | |||||
| 11 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 683 | 2 | 00:00:00.01 | 6 | 0 | |||
| INDEX UNIQUE SCAN | PRODUCTS_JH_INDEX01 | 2 | 273 | 2 | 00:00:00.01 | 4 | 0 | |||
| 13 | BITMAP CONVERSION FROM ROWIDS | 2 | 2 | 00:00:00.01 | 10 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 2 | 1463 | 00:00:00.01 | 10 | 0 | ||||
| 15 | BITMAP MERGE | 1 | 211 | 00:01:11.33 | 90635 | 90416 | 1024K | 512K | 86M (0) | ||
| 16 | BITMAP KEY ITERATION | 1 | 2679 | 00:00:16.68 | 90635 | 90416 | |||||
| 17 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 1 | 1 | 26 | 00:00:00.01 | 2 | 1 | |||
| INDEX RANGE SCAN | TYPES_JH_INDEX01 | 1 | 1 | 26 | 00:00:00.01 | 1 | 1 | |||
| 19 | BITMAP CONVERSION FROM ROWIDS | 26 | 2679 | 00:00:16.68 | 90633 | 90415 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX03 | 26 | 50M | 00:00:09.39 | 90633 | 90415 | ||||
| 21 | BITMAP MERGE | 1 | 173 | 00:00:05.28 | 42693 | 11929 | 1024K | 512K | 25M (0) | ||
| 22 | BITMAP KEY ITERATION | 1 | 10000 | 00:00:02.01 | 42693 | 11929 | |||||
| 23 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 1 | 4500 | 10000 | 00:00:00.05 | 9078 | 30 | |||
| INDEX RANGE SCAN | DEPT_JH_INDEX01 | 1 | 810 | 10000 | 00:00:00.02 | 24 | 24 | |||
| 25 | BITMAP CONVERSION FROM ROWIDS | 10000 | 10000 | 00:00:01.95 | 33615 | 11899 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 10000 | 5552K | 00:00:01.15 | 33615 | 11899 | ||||
| 27 | TABLE ACCESS FULL | TYPES_JH | 1 | 26 | 26 | 00:00:00.01 | 3 | 1 | |||
| 28 | TABLE ACCESS FULL | PRODUCTS_JH | 1 | 68276 | 68276 | 00:00:00.01 | 213 | 208 | |||
| 29 | TABLE ACCESS FULL | DEPT_JH | 1 | 90000 | 90000 | 00:00:00.01 | 279 | 3 |
Predicate Information (identified by operation id):
---
2 - access("D"."DEPT_NO"="S"."SALES_DEPT")
3 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD")
4 - access("T"."TYPE_CD"="S"."SALES_TYPE")
5 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."COUNTRY_CD" IS NOT NULL))
12 - access(("PRODUCTS_JH"."SYS_NC00003$"='AT080' OR "PRODUCTS_JH"."SYS_NC00003$"='CP001'))
14 - access("S"."PRODUCT_CD"="PRODUCT_CD")
18 - access("TYPES_JH"."SYS_NC00003$">='A' AND "TYPES_JH"."SYS_NC00003$"<='Z')
20 - access("S"."SALES_TYPE"="TYPE_CD")
24 - access("DEPT_JH"."SYS_NC00003$" LIKE '8%')
filter("DEPT_JH"."SYS_NC00003$" LIKE '8%')
26 - access("S"."SALES_DEPT"="DEPT_NO")
| {CODE} * 비트리로 구성된 SALES_JH_INDEX02가 BITMAP CONVERSION으로 변화하여 'BITMAP AND'를 수행한다는 것을 알 수 있다. * 이 조인 방식은 디멘전 테이블에 주어진 조건들을 최대한 이용하였을 때 팩트 테이블의 처리범위가 현격하게 줄어든다면 비로소 빛을 발한다는 것을 의미한다. * 만약 여러개의 디멘저 테이블들이 각각 서브쿼리를 통해 팩트 테이블의 비트맵을 액세스( BITMAP KEY ITERATION )하였으나 거의 감소하지 않았다고 하자 그렇다면 이들은 아무리 BITMAP AND 를 하더라도 그 결과는 매우 넓은 범위가 될 것이다. 더구나 이를 ROWID로 변환하여 일일이 팩트 테이블을 액세스 한다면 애써 많은 처리를 해 왔지만 정작 효과는 전혀 없다. 게다가 아직 조인해야 할 디멘저 테이블들이 그대로 남아 있으므로 우리가 얻은 것은 아무 것도 없다. 그 반대의 경우에는 최상의 실행 계획이라 할 수있다 ( 디멘전 처리 범위가 넓은 경우 = 스타 조인, 디멘전의 처리 범위가 작을 경우 * 그 결고 ROWID로 변환하여 팩트 테이블을 액세스 한다. * SALES_JH 검색 범위가 넓어 부하가 상당하다. |
스타 조인과 스타 변형 조인은 어떤경우에 유용한가.? ( 주관 )
- 스타 조인 : 1) 디멘전 테이블들의 처리 범위 가 넓은 경우
2) 최소의 인덱스 정책 수립만으로 대응이 가능할 경우 - 스타 변형 조인 : 1) 디멘전 테이블들의 처리 범위가 작은 경우
2) 크리티걸한 인덱스 정책 수립이 필요한 경우
그러나 아니란다.;;
- 실전에서 적용되는 경우를 보면 스타 변형 조인이 훨씬 가치가 있고, 자주 사용되고 있다. ( DW 주로 사용 )
- 팩트 테이블에는 디멘전 컬럼과 계측값을 가진 메져( Measure ) 컬럼으로 구성되고 있다.
- 디멘전 컬럼은 디멘전 테이블들의 외부키로써 존재한다.
- 외부에서 주어지는 조건들은 디멘전 컬럼에 직접 주어지거나 디멘전 테이블의 컬럼에 주어진다.
- 실전에서 발생하는 대부분의 이러한 엑세스등른 주어진 조건들을 모두 적용하면 팩트 테이블의 처리범위가 크게 감소하는 경우가 많다.
- 그러므로 현질적으로는 스타변형 조인이 DW에서 일반적으로 훨씬 유리하다.
스타 변형 조인의 필수적인 전제 조건
- 1) 하나의 팩트 테이블과 최소한 2개 이상의 디멘전 테이블이 있어야 한다.
- 2) 팩트 테이블에 있는 디멘전 - 즉, 디멘전 테이블들의 외부키 - 에는 반드시 비트맵 인덱스가
존재해야 한다. 그러나 비트리 인덱스가 있어도 비트맵 컨버전이 일어나므로 스타변형조인이
발생할 수 있다. 그러나 복합( Composite ) 비트맵 인덱스 상에서 발생할 때는 사용상의 주의가 필요하다. - 3) 팩트 테이블에 반드시 통계정보가 생성되어 있어야 한다. 그러나 ANALYZE 모드에는 영향을 받지 않는다.
- 4) STAR_TRANSFORMATION_ENABLED 파라미터가 FALSE가 아닌 TRUE 나 TEMP_DISABLE로 설정되어 있거나.
아니면 쿼리에 직접 STAR_TRANSFORMATION 힌트를 주어야 작동한다.
스타 변형 조인의 제약 조건
- 1) 비트맵을 사용할 수 없게 하는 힌트와는 서로 양립할 수 없다. 가령, FULL, ROWID, STAR와 같은 힌트는 논리적으로 서로 공존할 수 없기 때문이다.
- 2) 쿼리 내에 바인드 변수를 사용하지 않아야 한다. 어떤 경우의 바인드 변수의 사용도 스타 변형 조인을 발생시키지 않는다.
스타 변형 조인을 위한 WHERE절의 바인드 변수 뿐만 아니라, 이와 상관없는 WHERE 절에 바인드 변수가 있어도 스타 변형 조인은 일어 나지 않는다.
이러한 현상이 발생하는 이유에 대해서는 뒤에서 별도로 설명하기로 하겠다. - 3) 원격( Remote ) 팩터 테이블인 경우에는 스타 변형 조인이 일어나지 않는다. 그 이유는 각 서브쿼리마다 원격에 있는 팩트 테이블을 비트맵 탐침( BITMAP KEY ITERATION )하고
최종적으로 합성 ( BITMAP AND) 된 결과로 다시 원격 테이블을 액세스 해야 하므로 오히려 부하가 크게 증가하기 때문이다. - 4) 그러나 디멘저 테이블이 원격에 있으면 이 조인은 일어날 수 없다.
디멘전 테이블은 일반적으로 소량이며, 서브쿼리에서 먼저 수행하거나 마지막으로 해쉬조인 드응로 조인할 때 사용되므로 그리 큰 부담이 되지 않기 때문이다. - 5) 부정형 조인으로 수행되는 경우에는 이 조인이 발생하지 않는다.
우리가 앞서 부정형 조인에서 그 특성을 알아보았듯이 부정형 조인은 제공자 역할이 아닌 확인자의 역할만을 담당하므로 스타변형 조인으로 수행되더라도 전혀 얻을 것이 없기 때문이다. - 6) 인라인뷰나 뷰 쿼리 중에는 독립적으로 먼저 수행될 수 있는 경우와 액세스 쿼리와 머지 한 후에 수행될 수 있는 두 가지 종류가 있다.
후자의 경우는 이 조인이 일어날 수 없다.
그 이유는 논리적으로 보더라도 아직 머지가 일어나지 않은 쿼리르 대상으로 스타변형 조인을 위한 질의 재생성을 할수는 없기 때문이다. - 7) 서브쿼리에서 이미 디멘전 테이블로 사용한 테이블에 대해서는 이런 방식의 조인을 위한 변형이 일어나지 않는다.
물론 여기서 말하는 서브쿼리는 변형에 의해 생성된 서브쿼리가 아니라 사용자 쿼리에 직접 기술한 것ㅇ르 말한다.
만약 변형이 일어난다면 이중으로 생기게 되므로 이러한 제약이 있는 것은 당연하다.
옵티마이져의 판단에 의해 스타변형 조인이 일어 나지 않는 경우.? ;;
- 1) 팩트 테이블이 가진 조건들 만으로도 충분히 처리범위가 주어든다고 판단하였거나 특정 디멘전 테이블이 선행해서 제공자 역하을 한 것만으로도 충분한 경우에는 스타변형조인은 일어나지않는다.
- 2) 팩트 테이블의 크기가 너무 작아서 굳이 스타변형 조인을 수행시킬 가치가 없다고 판단한 경우에도 이 조인은 일어나지 않는다.
- 3) 인덱스 머지에서도 나타났듯이 '머지'
바인드 변수는 상수값 아니므로 옵티마이져가 정확한 판단을 할 수 없어 효과를 보장 할 수 없기 때문에 아예 포기하는 것이다. ( 필자님 고찰 )
- 1) 실전에서 일어나는 대부분의 경우는 평균적ㅇ니 분포도를 기준으로 결정했을 때도 크나큰 문제가 없으며,
실전에서 사용되는 대다수의 쿼리에는 바인드 변수가 포함되어 있기 때문에 이러한 경우를 모두 제외해 보리면 이 조인을 활용할 기회가 너무 적어지기 때문에 바람직하지 않다. - 2) 정 부담되면 변수를 사용한 조건이 포함된 부분만 변형에 포함시키지 않는다거나 퀄의 사용자가 힌트를 통해 반드시 적용하겠다고 의지를 보였다면
그 책임은 옵티마져에게 있는 것이 아니므로 이를 허용하는 것이 바람직하다고 믿는다. 이점은 점차 개선될 것이다 ( ㅡㅡ^ ) - 3) 비트맵 합성에서도 어느 한쪽이 지나치게 넓은 범위를 가지고 있다면 이를 합성 대상에서 제외 시킨다.
물론 항상 제외되는 것은 아니다 좁은 범위를 가지고 있는 다른디멘저들이 충분히 그 역할을 담당한다는 판단이 서면 제외시키지만 그렇지 않을 때는 대상에 포함시킨다.
실제로 테스트를 해보면 등장한 디멘전 테이블들의 수에 따라 선택된 디멘전이나 개수에 미묘한 차이를 보이고 있다.
그러나 여기에는 굳이 테이스트 결과를 공개하지 않겠다.
이것은 어차피 옵티마이져가 판단할 문제이므로 여러분이 너무 깊순한 부분까지 알면 오리혀 혼란만 가중될 수도 있을 거이라는 생각이기 때문이다 ( ㅡㅡ^ )
| 변칙적이지만 이런 생각 하시는 분이 있을것입니다. 굳이 서브쿼리들이 필요한가.? 네 필요합니다. 책에서는 디멘전 테이블이 중앙 테이블을 제어하기 때문입니다. 하지만 TEST ㄱㄱ |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( S ) STAR_TRANSFORMATION INDEX_COMBINE( S ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND S.PRODUCT_CD IN ( SELECT PRODUCT_CD FROM PRODUCTS_JH WHERE ( PRODUCT_CD ) IN ( 'AT080' , 'CP001' ))
10 AND ( S.SALES_TYPE ) IN (SELECT TYPE_CD FROM TYPES_JH WHERE ( TYPE_CD ) BETWEEN 'A' AND 'Z' )
11 AND S.SALES_DEPT IN ( SELECT DEPT_NO FROM DEPT_JH WHERE ( DEPT_NO ) LIKE '8%' )
12 -- AND ROWNUM <= 5
13 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_80030 000490 NAME_AT080 NAME_F 476000
...
21 개의 행이 선택되었습니다.
SQL> @XPLAN
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp |
| 0 | SELECT STATEMENT | 1 | 21 | 00:01:14.92 | 104K | 309K | 218K | ||||||
| 1 | HASH GROUP BY | 1 | 2 | 21 | 00:01:14.92 | 104K | 309K | 218K | 813K | 813K | 1355K (0) | ||
| 2 | NESTED LOOPS | 1 | 21 | 00:01:14.92 | 104K | 309K | 218K | ||||||
| 3 | NESTED LOOPS | 1 | 2 | 21 | 00:01:14.92 | 104K | 309K | 218K | |||||
| 4 | NESTED LOOPS | 1 | 2 | 21 | 00:01:14.92 | 103K | 309K | 218K | |||||
| HASH JOIN | 1 | 2 | 21 | 00:01:14.92 | 103K | 309K | 218K | 947K | 947K | 539K (0) | ||
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 1 | 9 | 21 | 00:01:14.92 | 103K | 309K | 218K | ||||
| 7 | BITMAP CONVERSION TO ROWIDS | 1 | 169 | 00:01:14.92 | 103K | 309K | 218K | ||||||
| 8 | BITMAP AND | 1 | 1 | 00:01:14.92 | 103K | 309K | 218K | ||||||
| 9 | BITMAP OR | 1 | 1 | 00:00:00.01 | 10 | 0 | 0 | ||||||
| 10 | BITMAP CONVERSION FROM ROWIDS | 1 | 1 | 00:00:00.01 | 5 | 0 | 0 | ||||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 1 | 714 | 00:00:00.01 | 5 | 0 | 0 | |||||
| 12 | BITMAP CONVERSION FROM ROWIDS | 1 | 1 | 00:00:00.01 | 5 | 0 | 0 | ||||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 1 | 749 | 00:00:00.01 | 5 | 0 | 0 | |||||
| 14 | BITMAP CONVERSION FROM ROWIDS | 1 | 173 | 00:00:07.99 | 13167 | 21862 | 21862 | ||||||
| 15 | SORT ORDER BY | 1 | 5552K | 00:00:07.30 | 13167 | 21862 | 21862 | 96M | 3353K | 112M (1) | 89088 | ||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 1 | 5552K | 00:00:02.32 | 13162 | 0 | 0 | |||||
| 17 | BITMAP CONVERSION FROM ROWIDS | 1 | 204 | 00:01:06.91 | 90602 | 287K | 196K | ||||||
| 18 | SORT ORDER BY | 1 | 50M | 00:01:01.46 | 90602 | 287K | 196K | 865M | 9615K | 112M (1) | 774K | ||
| INDEX RANGE SCAN | SALES_JH_INDEX03 | 1 | 50M | 00:00:11.82 | 90582 | 90390 | 0 | |||||
| 20 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 6 | 1 | 0 | ||||||
| 21 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 2 | 2 | 00:00:00.01 | 6 | 1 | 0 | ||||
| INDEX UNIQUE SCAN | PRODUCTS_JH_PK | 2 | 2 | 2 | 00:00:00.01 | 4 | 1 | 0 | ||||
| 23 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 21 | 1 | 21 | 00:00:00.01 | 25 | 0 | 0 | ||||
| INDEX UNIQUE SCAN | TYPES_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 4 | 0 | 0 | ||||
| INDEX UNIQUE SCAN | DEPT_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 23 | 8 | 0 | ||||
| 26 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 21 | 1 | 21 | 00:00:00.01 | 21 | 0 | 0 |
Predicate Information (identified by operation id):
---
5 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD")
6 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."COUNTRY_CD" IS NOT NULL))
11 - access("S"."PRODUCT_CD"='AT080')
13 - access("S"."PRODUCT_CD"='CP001')
16 - access("S"."SALES_DEPT" LIKE '8%')
filter(("S"."SALES_DEPT" IS NOT NULL AND "S"."SALES_DEPT" LIKE '8%' AND "S"."SALES_DEPT" LIKE '8%'))
19 - access("S"."SALES_TYPE">='A' AND "S"."SALES_TYPE"<='Z')
22 - access(("P"."PRODUCT_CD"='AT080' OR "P"."PRODUCT_CD"='CP001'))
24 - access("T"."TYPE_CD"="S"."SALES_TYPE")
filter(("T"."TYPE_CD">='A' AND "T"."TYPE_CD"<='Z'))
25 - access("D"."DEPT_NO"="S"."SALES_DEPT")
filter("D"."DEPT_NO" LIKE '8%')
| {CODE} * 옵티마이져들이 불필요하다고 생각하고 쿼리 변형이 일어나서 서브쿼리들을 배제해버렸음. * ( 'AT080' , 'CP001' ) 조건때문에 BITMAP OR 수립됩 |
| 처리범위가 작다면 스타 변형 조인이 답인데.. 위에 처럼 처리 범위가 넓다면 정말 스타 변형 조인이 답인가.? |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( P ) INDEX_JOIN( S ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND S.PRODUCT_CD IN ( SELECT /*+ UNNEST */ PRODUCT_CD FROM PRODUCTS_JH WHERE ( PRODUCT_CD ) IN ( 'AT080' , 'CP001' ))
10 AND ( S.SALES_TYPE ) IN (SELECT /*+ UNNEST */ TYPE_CD FROM TYPES_JH WHERE ( TYPE_CD ) BETWEEN 'A' AND 'Z' )
11 AND S.SALES_DEPT IN ( SELECT /*+ UNNEST */ DEPT_NO FROM DEPT_JH WHERE ( DEPT_NO ) LIKE '8%' )
12 -- AND ROWNUM <= 5
13 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
...
21 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:00.01 | 1547 | |||||
| 1 | HASH GROUP BY | 1 | 2 | 21 | 00:00:00.01 | 1547 | 813K | 813K | 1355K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:00.01 | 1547 | |||||
| 3 | NESTED LOOPS | 1 | 2 | 21 | 00:00:00.01 | 1526 | ||||
| 4 | NESTED LOOPS | 1 | 2 | 21 | 00:00:00.01 | 1522 | ||||
| 5 | NESTED LOOPS | 1 | 2 | 21 | 00:00:00.01 | 1478 | ||||
| 6 | INLIST ITERATOR | 1 | 2 | 00:00:00.01 | 6 | |||||
| 7 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 2 | 2 | 00:00:00.01 | 6 | |||
| INDEX UNIQUE SCAN | PRODUCTS_JH_PK | 2 | 2 | 2 | 00:00:00.01 | 4 | |||
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 2 | 1 | 21 | 00:00:00.01 | 1472 | |||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 2 | 1 | 1463 | 00:00:00.01 | 10 | |||
| 11 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 21 | 1 | 21 | 00:00:00.01 | 44 | |||
| INDEX UNIQUE SCAN | DEPT_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 23 | |||
| INDEX UNIQUE SCAN | TYPES_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 4 | |||
| 14 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 21 | 1 | 21 | 00:00:00.01 | 21 |
---
Predicate Information (identified by operation id):
---
8 - access(("P"."PRODUCT_CD"='AT080' OR "P"."PRODUCT_CD"='CP001'))
9 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."SALES_DEPT" LIKE '8%' AND "S"."COUNTRY_CD" IS NOT NULL AND
"S"."SALES_TYPE">='A' AND "S"."SALES_TYPE"<='Z' AND "S"."SALES_DEPT" IS NOT NULL))
10 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD")
filter(("S"."PRODUCT_CD"='AT080' OR "S"."PRODUCT_CD"='CP001'))
12 - access("D"."DEPT_NO"="S"."SALES_DEPT")
filter("D"."DEPT_NO" LIKE '8%')
13 - access("T"."TYPE_CD"="S"."SALES_TYPE")
filter(("T"."TYPE_CD">='A' AND "T"."TYPE_CD"<='Z'))
| {CODE} |
한번 액세스한 디멘전의 결과를 재사용하기 위해서 생성하는 임시( TEMP ) 테이블에 대해 소개하겠다.
- 임시 테이블을 생성하는 이유 : 설사 내부적으로 테이블을 새롭게 만드는 부담이 있더라도 이를 재사용 하도록 하기 위한 것이다.
- 임시 테이블을 사용하는 기준 : 가령, '고객' 데이블과 같이 대량의 데이터를 가진 디멘전 테이블이 자신의 범위를 크게 줄여주는 조건을 가지고 있을 때
먼저 액세스하여 소량의 임시 테이블을 생성하고, 이를 활용하는 것은 분명히 효과가 있다.
그러나 소량의 데이터를 가진 디멘전 테이블이거나 조건이 처리범위를 별로 줄여주지 못한다면 거의 효과가 없다. - BYPASS_RECURSIVE_CHECK : 인서트 문에서 사용하는 WITH 구분과 같음 ( TEMP )
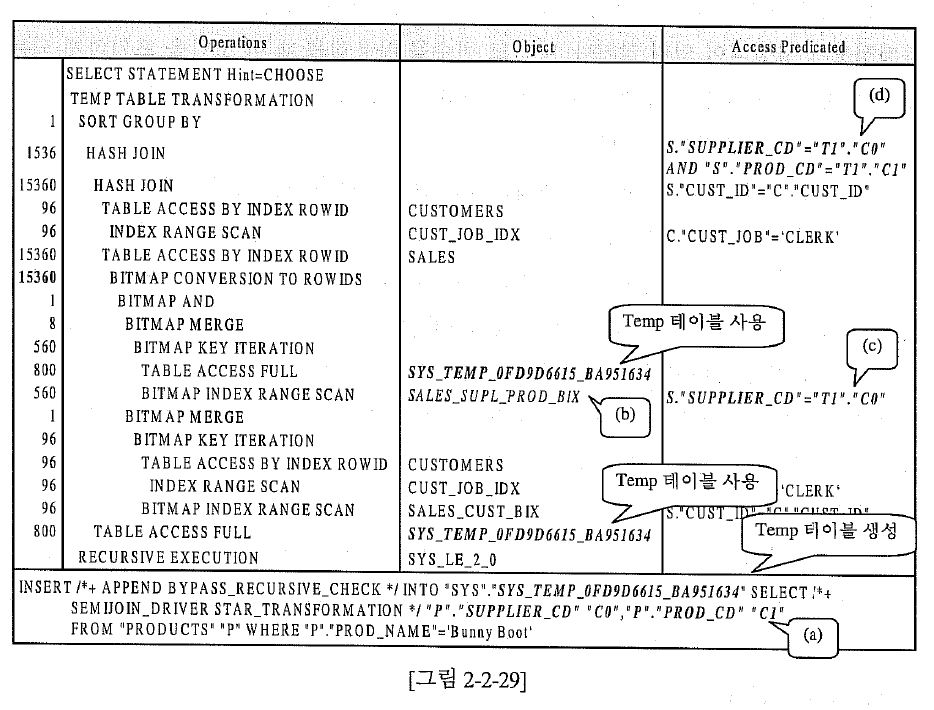
- 변형에 사용할 디멘전 테이블을 주어진 조건에 대한 추출하고 ( SYS_TEMP_OFD9D6615_BA951634 )
- 이것을 임시 테이블에 저장했다가 ( TEMP TABLE TRANSFORMATION )
- 비트맵 탐침에도 사용하고( BITMAP KEY ITERATION )
- 연결을 위한 해쉬조인에서도 사용 하였음을 알수 있다. ( 아래에서 두번째 TABLE ACCESS FULL )
- 스타변형 조인에서 디멘전 테이블이 항상 두번씩 액세스되는 것을 알고 있다 ( SELECT 절에 디멘전 테이블 컬럼을 사용 할 경우 ( 주관 ) )
- 옵티마이져가 대형( Big dimension )이라고 판단한 것에 대해서만 생성하며, 또한 대형이라고 해서 모두 생성되는 것이 아니라
조인에 참여하는 디멘전의 수에 따라 옵티마이져가 판단한다. - 디멘전이 4개 이상 있을 때는 가장 큰 디멘전은 아예 제외되기 때문에 어차피 임시 테이블은 영향을 주지 못한다.
그러므로 사실 실전에서는 임시 테이블로 인한 수행속도 향상은 크게 기대할 만큼 나타나지 않는다. - 만약 여러분드이 보유하고 있는 데이터 웨어하우스의 데이터 모델에서 대부분의 디멘전들이 소형이라면 'TEMP_DISABLE'을 적용해도 무리가 없다.
그러나 대형 디멘전들이 자주 사용되는 환경이라면 TRUE로 관리하는 것이 보다 좋은 결정이 될 것이다.
그럼 테스트 해봐야죠.?( 조건 범위가 큰 디멘저를 먼서 드라이빙해서 TEMP TABLE로 유도 하겠음 )
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( D P T ) STAR_TRANSFORMATION USE_MERGE( D P T ) USE_NL( S ) INDEX( T TYPES_JH_INDEX01 ) */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND TRIM( P.PRODUCT_CD ) IN ( 'AT080' , 'CP001' )
10 AND TRIM( T.TYPE_CD ) BETWEEN 'A' AND 'Z'
11 AND TRIM( D.DEPT_NO) LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
NAME_84500 000349 NAME_AT080 NAME_C 71000
...
21 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:01:22.37 | 133K | 104K | 32 | |||||
| 1 | TEMP TABLE TRANSFORMATION | 1 | 21 | 00:01:22.37 | 133K | 104K | 32 | |||||
| 2 | LOAD AS SELECT | 1 | 0 | 00:00:00.03 | 10 | 5 | 1 | 269K | 269K | 269K (0) | ||
| 3 | INLIST ITERATOR | 1 | 2 | 00:00:00.03 | 6 | 5 | 0 | |||||
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS_JH | 2 | 683 | 2 | 00:00:00.03 | 6 | 5 | 0 | |||
| INDEX UNIQUE SCAN | PRODUCTS_JH_INDEX01 | 2 | 273 | 2 | 00:00:00.01 | 4 | 3 | 0 | |||
| 6 | LOAD AS SELECT | 1 | 0 | 00:00:00.20 | 9112 | 81 | 31 | 269K | 269K | 269K (0) | ||
| 7 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 1 | 4500 | 10000 | 00:00:00.19 | 9078 | 81 | 0 | |||
| INDEX RANGE SCAN | DEPT_JH_INDEX01 | 1 | 810 | 10000 | 00:00:00.03 | 24 | 24 | 0 | |||
| 9 | HASH GROUP BY | 1 | 3 | 21 | 00:01:22.14 | 124K | 104K | 0 | 813K | 813K | 1337K (0) | |
| HASH JOIN | 1 | 3 | 21 | 00:01:22.14 | 124K | 104K | 0 | 766K | 766K | 1317K (0) | |
| HASH JOIN | 1 | 3 | 21 | 00:01:22.13 | 124K | 104K | 0 | 785K | 785K | 580K (0) | |
| 12 | MERGE JOIN | 1 | 3 | 21 | 00:01:22.13 | 124K | 104K | 0 | ||||
| 13 | SORT JOIN | 1 | 49 | 21 | 00:01:22.13 | 124K | 104K | 0 | 4096 | 4096 | 4096 (0) | |
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 1 | 49 | 21 | 00:01:22.13 | 124K | 104K | 0 | |||
| 15 | BITMAP CONVERSION TO ROWIDS | 1 | 169 | 00:01:21.03 | 124K | 103K | 0 | |||||
| 16 | BITMAP AND | 1 | 1 | 00:01:21.03 | 124K | 103K | 0 | |||||
| 17 | BITMAP MERGE | 1 | 1 | 00:00:00.09 | 16 | 10 | 0 | 1024K | 512K | 7168 (0) | ||
| 18 | BITMAP KEY ITERATION | 1 | 2 | 00:00:00.04 | 16 | 10 | 0 | |||||
| 19 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6678_9F556819 | 1 | 683 | 2 | 00:00:00.01 | 6 | 1 | 0 | |||
| 20 | BITMAP CONVERSION FROM ROWIDS | 2 | 2 | 00:00:00.04 | 10 | 9 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 2 | 1463 | 00:00:00.04 | 10 | 9 | 0 | ||||
| 22 | BITMAP MERGE | 1 | 213 | 00:01:14.11 | 90635 | 90609 | 0 | 1024K | 512K | 86M (0) | ||
| 23 | BITMAP KEY ITERATION | 1 | 2679 | 00:00:17.84 | 90635 | 90609 | 0 | |||||
| 24 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 1 | 1 | 26 | 00:00:00.01 | 2 | 2 | 0 | |||
| INDEX RANGE SCAN | TYPES_JH_INDEX01 | 1 | 1 | 26 | 00:00:00.01 | 1 | 1 | 0 | |||
| 26 | BITMAP CONVERSION FROM ROWIDS | 26 | 2679 | 00:00:17.83 | 90633 | 90607 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX03 | 26 | 50M | 00:00:10.49 | 90633 | 90607 | 0 | ||||
| 28 | BITMAP MERGE | 1 | 175 | 00:00:06.81 | 33621 | 13221 | 0 | 1024K | 512K | 25M (0) | ||
| 29 | BITMAP KEY ITERATION | 1 | 10000 | 00:00:03.14 | 33621 | 13221 | 0 | |||||
| 30 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6679_9F556819 | 1 | 4500 | 10000 | 00:00:00.02 | 36 | 32 | 0 | |||
| 31 | BITMAP CONVERSION FROM ROWIDS | 10000 | 10000 | 00:00:03.10 | 33585 | 13189 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX01 | 10000 | 5552K | 00:00:01.95 | 33585 | 13189 | 0 | ||||
| SORT JOIN | 21 | 1 | 21 | 00:00:00.01 | 2 | 0 | 0 | 2048 | 2048 | 2048 (0) | |
| 34 | TABLE ACCESS BY INDEX ROWID | TYPES_JH | 1 | 1 | 26 | 00:00:00.01 | 2 | 0 | 0 | |||
| INDEX RANGE SCAN | TYPES_JH_INDEX01 | 1 | 1 | 26 | 00:00:00.01 | 1 | 0 | 0 | |||
| 36 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6678_9F556819 | 1 | 683 | 2 | 00:00:00.01 | 3 | 2 | 0 | |||
| 37 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6679_9F556819 | 1 | 4500 | 10000 | 00:00:00.01 | 33 | 0 | 0 |
---
Predicate Information (identified by operation id):
---
5 - access(("P"."SYS_NC00003$"='AT080' OR "P"."SYS_NC00003$"='CP001'))
8 - access("D"."SYS_NC00003$" LIKE '8%')
filter("D"."SYS_NC00003$" LIKE '8%')
10 - access("C0"="S"."SALES_DEPT")
11 - access("C0"="S"."PRODUCT_CD")
14 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."COUNTRY_CD" IS NOT NULL))
21 - access("S"."PRODUCT_CD"="C0")
25 - access("T"."SYS_NC00003$">='A' AND "T"."SYS_NC00003$"<='Z')
27 - access("S"."SALES_TYPE"="T"."TYPE_CD")
32 - access("S"."SALES_DEPT"="C0")
33 - access("T"."TYPE_CD"="S"."SALES_TYPE")
filter("T"."TYPE_CD"="S"."SALES_TYPE")
35 - access("T"."SYS_NC00003$">='A' AND "T"."SYS_NC00003$"<='Z')
| {CODE} * 설명위 위와 같음 |
복합 인덱스 사용시 주의할 사항.
| 준비 스크립 |
|---|
| {CODE:SQL} |
SQL> SELECT COUNT(*) / ( 101 * 13 )
2 FROM PRODUCTS_JH;
COUNT(*)/(101*13)
-
52
ALTER TABLE PRODUCTS_JH ADD SUPPLIER_CD NUMBER;
UPDATE PRODUCTS_JH
SET SUPPLIER_CD = TRUNC(dbms_random.value( 1, 101 * 13 + 1 ) )
COMMIT;
SQL> SELECT *
2 FROM (SELECT SUPPLIER_CD, COUNT(*)
3 FROM PRODUCTS_JH
4 GROUP BY SUPPLIER_CD
5 )
6 WHERE ROWNUM <= 5;
SUPPLIER_CD COUNT(*)
---
--
1 46
2 51
3 54
4 64
5 60
CREATE TABLE SUPPLIER_JH AS
SELECT LEVEL SUPPLIER_CD
, 'NAME_' || LEVEL SUPPLIER_NAME
FROM DUAL
CONNECT BY LEVEL <= 101 * 13
CREATE UNIQUE INDEX SUPPLIER_JH_PK ON SUPPLIER_JH ( SUPPLIER_CD ) TABLESPACE ORA03TS02
ALTER TABLE SUPPLIER_JH ADD (
CONSTRAINT SUPPLIER_JH_PK
PRIMARY KEY
(SUPPLIER_CD)
USING INDEX SUPPLIER_JH_PK);
ALTER TABLE PRODUCTS_JH ADD (
CONSTRAINT PRODUCTS_JH_FK1
FOREIGN KEY (SUPPLIER_CD) --SALES_DEPT 4 Y VARCHAR2 (20 Byte) Height Balanced 90144
REFERENCES SUPPLIER_JH (SUPPLIER_CD));
--CREATE UNIQUE INDEX PRODUCTS_JH_INDEX02 ON PRODUCTS_JH ( SUPPLIER_CD, PRODUCT_CD ) TABLESPACE ORA03TS02
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'PRODUCTS_JH' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'SUPPLIER_JH' );
SQL> SELECT *
2 FROM COUNTRY_JH
3 WHERE ROWNUM <= 5
4 ;
COUNTRY_CD COUNTRY_NAME
--
000001 NAME_1
000002 NAME_2
000003 NAME_3
000004 NAME_4
000005 NAME_5
| {CODE} |
| 실행 스크립트 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ LEADING( U ) STAR_TRANSFORMATION FULL( P ) FULL( U ) INDEX_COMBINE( S ) */ C.COUNTRY_CD, P.PRODUCT_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM SALES_JH S, COUNTRY_JH C, PRODUCTS_JH P, SUPPLIER_JH U
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND P.SUPPLIER_CD = U.SUPPLIER_CD
7 AND C.COUNTRY_NAME = 'NAME_5'
8 AND U.SUPPLIER_NAME = 'NAME_3'
9 GROUP BY C.COUNTRY_CD, P.PRODUCT_NAME
10 ;
COUNTRY_CD PRODUCT_NAME SUM(S.SALES_AMOUNT)
--
--
---
000005 NAME_CP047 899000
000005 NAME_CV073 385000
...
38 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem |
| 0 | SELECT STATEMENT | 1 | 38 | 00:00:00.54 | 907 | 1 | 1 | |||||
| 1 | TEMP TABLE TRANSFORMATION | 1 | 38 | 00:00:00.54 | 907 | 1 | 1 | |||||
| 2 | LOAD AS SELECT | 1 | 0 | 00:00:00.05 | 338 | 0 | 1 | 269K | 269K | 269K (0) | ||
| HASH JOIN | 1 | 52 | 54 | 00:00:00.05 | 334 | 0 | 0 | 1180K | 1180K | 381K (0) | |
| TABLE ACCESS FULL | SUPPLIER_JH | 1 | 1 | 1 | 00:00:00.01 | 6 | 0 | 0 | |||
| 5 | TABLE ACCESS FULL | PRODUCTS_JH | 1 | 68276 | 68276 | 00:00:00.01 | 328 | 0 | 0 | |||
| 6 | HASH GROUP BY | 1 | 37 | 38 | 00:00:00.49 | 566 | 1 | 0 | 865K | 865K | 1357K (0) | |
| HASH JOIN | 1 | 76 | 92 | 00:00:00.49 | 566 | 1 | 0 | 858K | 858K | 1264K (0) | |
| 8 | NESTED LOOPS | 1 | 52 | 54 | 00:00:00.01 | 9 | 1 | 0 | ||||
| 9 | TABLE ACCESS BY INDEX ROWID | COUNTRY_JH | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | 0 | |||
| INDEX UNIQUE SCAN | COUNTRY_JH_INDEX | 1 | 1 | 1 | 00:00:00.01 | 2 | 0 | 0 | |||
| 11 | TABLE ACCESS FULL | SYS_TEMP_0FD9D66A7_9F556819 | 1 | 52 | 54 | 00:00:00.01 | 6 | 1 | 0 | |||
| 12 | TABLE ACCESS BY INDEX ROWID | SALES_JH | 1 | 76 | 92 | 00:00:00.49 | 557 | 0 | 0 | |||
| 13 | BITMAP CONVERSION TO ROWIDS | 1 | 92 | 00:00:00.49 | 465 | 0 | 0 | |||||
| 14 | BITMAP AND | 1 | 1 | 00:00:00.49 | 465 | 0 | 0 | |||||
| 15 | BITMAP MERGE | 1 | 4 | 00:00:00.22 | 206 | 0 | 0 | 1024K | 512K | 173K (0) | ||
| 16 | BITMAP KEY ITERATION | 1 | 54 | 00:00:00.02 | 206 | 0 | 0 | |||||
| 17 | TABLE ACCESS FULL | SYS_TEMP_0FD9D66A7_9F556819 | 1 | 52 | 54 | 00:00:00.01 | 3 | 0 | 0 | |||
| 18 | BITMAP CONVERSION FROM ROWIDS | 54 | 54 | 00:00:00.02 | 203 | 0 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX02 | 54 | 39329 | 00:00:00.01 | 203 | 0 | 0 | ||||
| 20 | BITMAP MERGE | 1 | 9 | 00:00:00.27 | 259 | 0 | 0 | 1024K | 512K | 291K (0) | ||
| 21 | BITMAP KEY ITERATION | 1 | 9 | 00:00:00.05 | 259 | 0 | 0 | |||||
| 22 | TABLE ACCESS BY INDEX ROWID | COUNTRY_JH | 1 | 1 | 1 | 00:00:00.01 | 3 | 0 | 0 | |||
| INDEX UNIQUE SCAN | COUNTRY_JH_INDEX | 1 | 1 | 1 | 00:00:00.01 | 2 | 0 | 0 | |||
| 24 | BITMAP CONVERSION FROM ROWIDS | 1 | 9 | 00:00:00.05 | 256 | 0 | 0 | |||||
| INDEX RANGE SCAN | SALES_JH_INDEX04 | 1 | 100K | 00:00:00.03 | 256 | 0 | 0 |
Predicate Information (identified by operation id):
3 - access("P"."SUPPLIER_CD"="U"."SUPPLIER_CD")
4 - filter("U"."SUPPLIER_NAME"='NAME_3')
7 - access("C"."COUNTRY_CD"="S"."COUNTRY_CD" AND "C0"="S"."PRODUCT_CD")
10 - access("C"."COUNTRY_NAME"='NAME_5')
19 - access("S"."PRODUCT_CD"="C0")
23 - access("C"."COUNTRY_NAME"='NAME_5')
25 - access("S"."COUNTRY_CD"="C"."COUNTRY_CD")
| {CODE} * PRODUCTS_JH.SUPPLIER_CD 범위가 넓어 옵티마이져가 템프를 선택함. |
비트맵 조인 인덱스 ( Bitmap Joint Index )
| 비트맵 조인 인덱스 |
|---|
| {CODE:SQL} |
SQL> SELECT /*+ STAR_TRANSFORMATION */ D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME
2 , SUM( S.SALES_AMOUNT )
3 FROM COUNTRY_JH C, PRODUCTS_JH P, DEPT_JH D, TYPES_JH T, SALES_JH S
4 WHERE C.COUNTRY_CD = S.COUNTRY_CD
5 AND P.PRODUCT_CD = S.PRODUCT_CD
6 AND D.DEPT_NO = S.SALES_DEPT
7 AND T.TYPE_CD = S.SALES_TYPE
8 AND S.SALES_DATE LIKE '201104%'
9 AND P.PRODUCT_NAME IN ( 'NAME_AT080' , 'NAME_CP001' )
10 AND T.TYPE_NAME BETWEEN 'NAME_A' AND 'NAME_Z'
11 AND D.DEPT_NO LIKE '8%'
12 GROUP BY D.DEPT_NAME, C.COUNTRY_CD, P.PRODUCT_NAME, T.TYPE_NAME;
DEPT_NAME COUNTRY_CD PRODUCT_NAME TYPE_NAME SUM(S.SALES_AMOUNT)
--
--
--
--
---
NAME_80030 000490 NAME_AT080 NAME_F 476000
NAME_88348 000046 NAME_AT080 NAME_B 303000
...
21 개의 행이 선택되었습니다.
SQL> @XPLAN
---
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---
| 0 | SELECT STATEMENT | 1 | 21 | 00:00:00.02 | 1846 | |||||
| 1 | HASH GROUP BY | 1 | 1 | 21 | 00:00:00.02 | 1846 | 813K | 813K | 1342K (0) | |
| 2 | NESTED LOOPS | 1 | 21 | 00:00:00.02 | 1846 | |||||
| 3 | NESTED LOOPS | 1 | 1 | 21 | 00:00:00.02 | 1825 | ||||
| 4 | NESTED LOOPS | 1 | 1 | 21 | 00:00:00.02 | 1802 | ||||
| HASH JOIN | 1 | 1 | 21 | 00:00:00.01 | 1797 | 1049K | 1049K | 504K (0) | |
| TABLE ACCESS FULL | PRODUCTS_JH | 1 | 2 | 2 | 00:00:00.01 | 328 | |||
| 7 | INLIST ITERATOR | 1 | 21 | 00:00:00.01 | 1469 | |||||
| TABLE ACCESS BY INDEX ROWID | SALES_JH | 2 | 1465 | 21 | 00:00:00.01 | 1469 | |||
| 9 | BITMAP CONVERSION TO ROWIDS | 2 | 1463 | 00:00:00.01 | 7 | |||||
| BITMAP INDEX SINGLE VALUE | SALES_PROD_NAME_BIX | 2 | 2 | 00:00:00.01 | 7 | ||||
| TABLE ACCESS BY INDEX ROWID | TYPES_JH | 21 | 1 | 21 | 00:00:00.01 | 5 | |||
| INDEX UNIQUE SCAN | TYPES_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 4 | |||
| INDEX UNIQUE SCAN | DEPT_JH_PK | 21 | 1 | 21 | 00:00:00.01 | 23 | |||
| 14 | TABLE ACCESS BY INDEX ROWID | DEPT_JH | 21 | 1 | 21 | 00:00:00.01 | 21 |
---
Predicate Information (identified by operation id):
---
5 - access("P"."PRODUCT_CD"="S"."PRODUCT_CD")
6 - filter(("P"."PRODUCT_NAME"='NAME_AT080' OR "P"."PRODUCT_NAME"='NAME_CP001'))
8 - filter(("S"."SALES_DATE" LIKE '201104%' AND "S"."SALES_DEPT" LIKE '8%' AND "S"."COUNTRY_CD" IS NOT NULL))
10 - access(("S"."SYS_NC00009$"='NAME_AT080' OR "S"."SYS_NC00009$"='NAME_CP001'))
11 - filter(("T"."TYPE_NAME">='NAME_A' AND "T"."TYPE_NAME"<='NAME_Z'))
12 - access("T"."TYPE_CD"="S"."SALES_TYPE")
13 - access("D"."DEPT_NO"="S"."SALES_DEPT")
| {CODE} * 마치 팩트 테이블 컬럼처럼 인식하여 서브쿼를 만들어 비트랩 탐침도, 비트맵 머지도 하지 않고 바로 'BITMAP AND'에 참여하는 것을 확인하기 바란다. * 아주 빈번하게 사용되는 디멘전 테이블의 컬럼들의 일부를 같은 방법으로 관리한다면 보다 향상된 수행속도를 얻을 수 있다. |
비트맵 조인 인덱스의 개념에 대해 좀더 자세하게 알아보기로 하자.
- 개념을 가장 쉽게 이해하는 방법은 조인된 결과의 집합을 하나의 테이블이라고 생각하는 것이다.
바로 이 논리적 테이블에 있는 컬럼을 비트맵 인덱스로 생성하였다고 생각하면 아주 쉽다. - 비트맨 조인 인덱스를 생성하는 문장을 살펴보자. 마치 SELECT 문의 조인처럼 FROM저로가 WHERE절을 가지고 있다.
서로 조인되는 테이블들은 동등한 관계를 가지고 있기 때문에 조인된 결과는 어느 특정 테이브의 소유로 볼 수는 없다.
이를 분명히 하기 위해 위의 생성문장에는 'ON SALES_JH'을 지정한 것이다.
조인을 하더라도 인덱스를 생성하는 집합이 그대로 보존되기 위해서는 다음의 사항을 준수해야한다. p. 633
- 인덱스를 생성하는 테이블에 조인( 참조 )되는 테이블은 반드시 기본키 컬럼이거나 유일성 제약 조건( Unique Constraints )을 가진 컬럼이 조인조건이 되어야 한다.
그것은 조인되는 집합의 유일성이 보장되지 않으면 그 결과는 보존될 수 없기 때문이다. - 참조되는테이블의 조인컬럼은그 테이블의 기본키로 지정되어 있거나, 인텍스를 생성하는 테이블에서 외부키 제약조건이 선언되어야 한다.
- 조인 조건은 반드시 이퀄( = )이어야 하며,아우터 조인을 사용할 수 없다.
- 인덱스를 생성하는 조인 문에 집합을 처리하는 연산( Union, Minus 등 ), DISTINCT, SUM, AVG, COUNT 등의 집계 함수, 분석 함수, GROUP BY, ORDER BY, CONNECT BY,
START WITH절의 상요해서는 안 된다. - 인덱스 컬럼은 반드시 조인되는 테이블에 소속된 컬럼이어야 한다.
- 비트맵 조인인덱스는 비트맵 인덱스의 일종으므로 당연히 일반적인 비트맵 인덱스의 각종 규칙을 그대로 준수해야 한다.
가령, 유일성을 가진 컬럼은 비트맵 인덱스를 생성할 수 없다.
비트맵 조인인덱스 사용상제약 사항
- 병렬DML 처리는 비트맵조인 인덱스르 가지고 있는 테이블에서만 지원된다.
만약 관련된 참조 테이블에서 병렬 DML을 수행시키면 비트맵 조인인덱스는 'UNUSABLE'상태가 된다. - 비트맵조인인덱스르 사용하게 되면, 언떤 트랜잭션에서 동시에 오직 하나의 테이블만처리해야 한다. 조인된 테이블이 COMMIT되지 않은상태에서 동시에 변경되면일관성을 보장할 수가 없기 때문이다.
- 조인 문장에서 동일한 테이블이 두 번 등장 할 수 없다.
| 동시에 여러 테이블을 참조하여 결합된 구조를 생성할 수도 있다. |
|---|
| {CODE:SQL} |
CREATE BITMAP INDEX SALES_PROD_CTRY_NAME_BIX
ON SALES_JH( PRODUCTS_JH.PRODUCT_NAME, COUNTRY_JH.COUNTRY_NAME )
FROM SALES_JH
, PRODUCTS_JH
, COUNTRY_JH
WHERE SALES_JH.PRODUCT_CD = PRODUCTS_JH.PRODUCT_CD
AND SALES_JH.COUNTRY_CD = COUNTRY_JH.COUNTRY_CD
| {CODE} * 방법상 전혀 문제가 없지만, 바람직 하지 않다. ( 비트맵 인덱스의 특성상 임의의 비트맵이 독립적으로 사용되어 그때마다 비트맵 연사을 수행하여 해결하는 것이 여러 가지로 유리 하기 때문이다.) |
결론 ( 이거 왜 필요한데.? )
- 결합 인덱스는 어떤 조건절에서 특정 컬럼이 사용되지 않거나 =로 사용되지 않을 때 결합된 인덱스 컬럼의 순서에 영향을 받는다.
그러므로 상황에 따라 적절한 인덱스 구조를 제공하려면 너무 많은 인덱스가 필요하게 되었다.
이러한 단점을 개선하기 위해 도입한 비트맵 인덱스르 굳이 결합된 컬럼으로 할 필요는 없다.
특히 비트맵인덱스는 보다 제한 사항이 많기 때문에 함부로 결합하지 않는 것이 좋다.
물론 아주 업무적으로 친밀도가 강력하여 언제나 같이 사용하는 경우라면 검토해볼 수도 있을 것이다.
그러나 역시 우리가 관심을 가져야 할 것은 여러 디멘전 테이븡레서 다양한 형태의 검색 조건을 받았을 때의 조인 최적화를 위한 스타변형 조이을 위해 이 개념을 활용하는 것이 바람직하다.
2000