1.4. 부분범위처리로의 유도 (by sunshiny) [2011.08.14]
1.4. 부분범위처리로의 유도
- 부분범위 처리로의 유도 방법
- 1.4.1. 액세스 경로를 이용한 SORT 의 대체
- 1.4.2. 인덱스만 처리하는 부분범위 처리
- 1.4.3. MIN, MAX 의 처리
- 1.4.4. FILTER 형 부분범위 처리
- 1.4.5. ROWNUM 을 이용한 부분범위 처리
- 1.4.6. 인라인뷰를 이용한 부분범위 처리
- 1.4.7. 저장형 함수를 이용한 부분범위 처리
- 1.4.8. 쿼리의 분리를 이용한 부분범위 처리
- 1.4.9. 웹 게시판에서의 부분범위 처리
1.4.1. 액세스 경로를 이용한 SORT 의 대체
- 대부분의 'ORDER BY'는 전체범위 처리가 된다.
- 인덱스를 이용하여 역순으로 정렬되기를 원하는 예
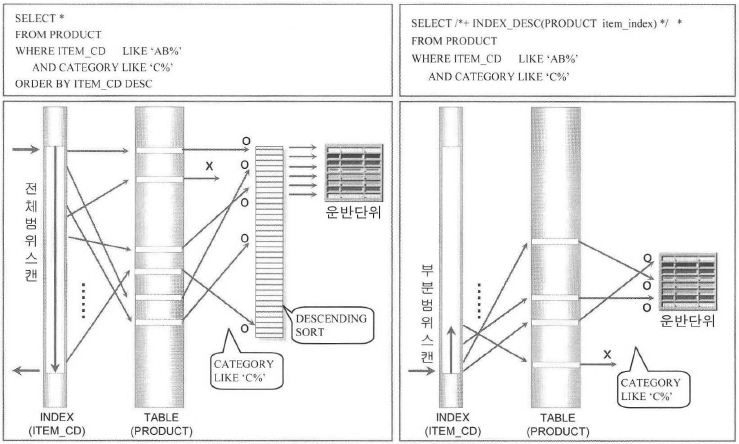
<그림2-1-7>
- 양쪽 모두 ITEM_CD 인덱스르르 사용하는 실행계획이 수립되었더라도 좌측 그림은 주어진 ITEM 조건에 해당하는 전체범위를 액세스하여 역순으로 정렬(Descending sort)하여 운반단위만큼 추출.
그러나 우측의 그림은 ITEM_CD 인덱스를 역순으로 처리하여 테이블을 액세스한 후 다른 조건과 비교하여 만족하는 로우들만 운반단위로 보내며 운반단위가 채워지면 추출시킴. - 규칙기준 옵티마이저인 경우는 좌측의 경우도 인덱스를 역순으로 액세스하는 부분범위 처리로 실행계획이 수립되지만 비용기준일 때는 반드시 그렇게 된다는 보장이 없기 때문에 우측과 같이 힌트를 사용하여 ORDER BY 대신에 인덱스를 이용한 부분범위 처리로 유도하는 것이 바람직함.
- 원하는 정렬이 'ITEM_CD_DESC'가 아니라 'ITEM_CD DESC, CATEGORY DESC' 일경우 인덱스가 'ITEM_CD + CATEGORY'로 결합되어 있다면 가능함.
- 액세스의 조건으로 사용되지 않더라도 'ORDER BY'를 없애기 위한 목적만으로 인덱스에 필요한 컬럼을 추가시키는 것도 하나의 좋은 방법이 될수 있음.
- SQL 의 액세스를 주관하는 컬럼과 'ORDER BY'의 컬럼이 다른경우.
- ord_date like '2005%' 인 범위가 아주 넓다고 가정.
SELECT ord_dept, ordqty * 1000
FROM order
WHERE ord_date like '2005%'
ORDER BY ord_dept desc
;
-- ORD_DATE 의 처리범위가 넓지 않다면 가장 양호한 액세스 경로가 되겠지만, 처리범위가 넓다면 부담이됨.
# 예측 실행계획
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)|
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 5774K| | 2120 (1)|
| 1 | SORT ORDER BY | | 96929 | 5774K| 13M| 2120 (1)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 96929 | 5774K| | 675 (1)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE | 96929 | | | 272 (2)|
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
SELECT /*+ INDEX_DESC(a ord_dept_index) */
ord_dept, ordqty * 1000
FROM order a
WHERE ord_date like '2005%'
AND ord_dept > ' '
;
-- AND ord_dept > ' ' 을 추가함으로써 이 SQL 은 액세스를 주관하는 컬럼과 'ORDER BY'할 컬럼이 같아짐.
-- 속도향상 원리 '액세스 주관 컬럼의 처리범위가 넓어도 다른 조건의 처리범위도 같이 넓으면 빠르다'는
원리에 의해 아주 빠른 수행속도를 얻을수 있음.
-- 힌트를 통해 액세스 주관 컬럼을 ord_dept_index 로 지정, 원래의 조건은 검증 조건으로 바꾸어 부분범위 처리로 유도함.
# 예측 실행계획
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 5774K| 213K (1)|
|* 1 | TABLE ACCESS BY INDEX ROWID | ORDER_T | 96929 | 5774K| 213K (1)|
|* 2 | INDEX RANGE SCAN DESCENDING| IDX_ORDER_T_ORD_DEPT | 1034K| | 2005 (2)|
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ORD_DATE" LIKE '2005%')
2 - access("ORD_DEPT">' ')
filter("ORD_DEPT">' ')
- 만약 ord_date like '2005%'로 사용하지 않고 ord_date like :date 와 같이 변수값을 사용했다면 좀더 많은 고려 사항이 필요.
- 실행 시 변수에 주어진 상수값은 경우에 따라 넓은 처리범위를 가질 수도, 그렇지 않을 수도 있기 때문.
- 만약 주어진 상수값이 좁은 범위를 가진다면 위의 예에서처럼 부분범위로 유도한 방법은 오히려 수행속도를 매우 나쁘게 만듬.
- 만약 1개월 분량의 데이터가 이러한 방법에 대한 손익분기점이라고 한다면, 동적(Dynamic) SQL 을 사용하거나 SQL 을 별도로 적용시켜야 함.
1.4.2 인덱스만 액세스하는 부분범위처리
- 옵티마이저는 사용자의 의도와는 상관없이 인덱스만으로 처리할 수 잇다고 판단되면 테이블을 액세스하지 않고 인덱스만 액세스하는 실행계획을 수립함.
- 인덱스는 첫 번재 로우를 찾을 때만 랜덤 액세스를 하고 그 다음부터는 스캔을 하지만 테이블을 액세스하는 행위는 항상 랜덤 액세스를 해야 함.
수행속도에 가장 많은 영향을 주는 테이블 랜덤 액세스를 하지 않고, 인덱스로만 처리할 수 있다면 비록 처리범위가 넓더라도 매우 효율적인 처리를 할 수 있음.
이러한 방식으로 유도하기 위한 최대의 관건은 인덱스가 어떻게 구성되어 있느냐에 달려있음.
- 인덱스만을 사용하는 실행계획이 수립되기 위해서는 다음과 같은 경우에 해당 되어야 함.
- 쿼리에 사용된 모든 컬럼들이 하나의 인덱스에 결합되어 있거나,
- 인덱스 머지가 되는 실행계획이 수립되려면 머지되는 두 개의 인덱스 내에 모든 컬럼들이 모두 사용되어야 함.
- 쿼리에 사용된 전체 컬럼들이 몇 개의 인덱스에 모두 포함될 수 있다면 인덱스 조인이 성립하게 된다.
이런 경우는 인덱스들만 이용해서 조인을 하는 실행계획이 수립됨. (인덱스 조인:235~238 참조)
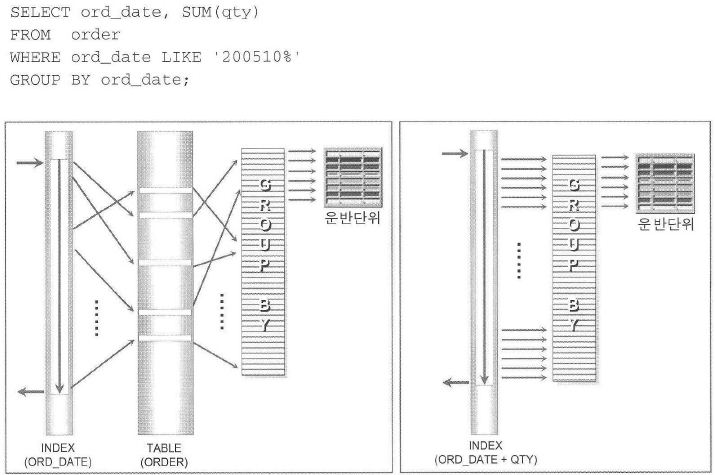
<그림2-1-8>
- 그림에서와 같이 ORD_DATE 인덱스에 QTY를 합친 결합 인덱스를 생성하면 옵티마이저는 인덱스만 사용하는 실행계획을 수립.
처리범위 및 클러스터링 팩터에 따라 차이가 있겠지만 좌측에 비해 거의 200~500% 정도의 수행속도를 향상시킴. - 두 가지 경우의 차이가 손익분기점만큼 차이가 나지 않는 것은 'GROUP BY' 처리가 양쪽에 모두 같이 있기 때문.
이와 같이 WHERE 절의 조건으로 사용하지 않은 컬럼도 인덱스만 사용하도록 유도할 목적으로 결합 인덱스에 추가할 수 있음.
SELECT ord_date, SUM(ordqty)
FROM order
WHERE ord_date LIKE '2005%'
GROUP BY ord_date
;
# 예측 실행계획
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 3691K| 675 (1)|
| 1 | SORT GROUP BY NOSORT | | 96929 | 3691K| 675 (1)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 96929 | 3691K| 675 (1)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE | 96929 | | 272 (2)|
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
# 예측 실행계획 : 결합인덱스 생성후 (ORD_DATE + QTY)
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 3691K| 326 (1)|
| 1 | SORT GROUP BY NOSORT| | 96929 | 3691K| 326 (1)|
|* 2 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE_QTY | 96929 | 3691K| 326 (1)|
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
- ORDER 테이블에 'ORD_DATE + AGENT_CD'로 결합된 인덱스가 있다고 가정하고 다음 SQL을 수행.
SELECT ord_dept, COUNT(*)
FROM order
WHERE ord_date LIKE '200510%'
GROUP BY ord_dept
;
# 예측 실행계획
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 48 | 2304 | 17 (6)|
| 1 | HASH GROUP BY | | 48 | 2304 | 17 (6)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 48 | 2304 | 16 (0)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE_AGENT_CD | 48 | | 3 (0)|
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '200510%')
filter("ORD_DATE" LIKE '200510%')
-- 'ORD_DATE + AGENT_CD' 인덱스로 전체범위를 스캔하여 랜덤으로 테이블을 액세스하고, GROUP BY 를 한 후 결과를 추출.
- AGENT_CD 로 변경후 SQL 실행
SELECT agent_cd, COUNT(*)
FROM order
WHERE ord_date LIKE '200510%'
GROUP BY agent_cd
;
# 예측 실행계획
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 48 | 1536 | 4 (25)|
| 1 | HASH GROUP BY | | 48 | 1536 | 4 (25)|
|* 2 | INDEX RANGE SCAN| IDX_ORDER_ORD_DATE_AGENT_CD | 48 | 1536 | 3 (0)|
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ORD_DATE" LIKE '200510%')
filter("ORD_DATE" LIKE '200510%')
-- 이 SQL 은 'ORD_DATE + AGENT_CD' 인덱스만 사용하는 실행계획을 수립하므로 훨씬 빠른 수행속도를 얻을 수 있음.
1.4.3. MIN, MAX의 처리
- 대량의 데이터를 가지고 있는 테이블에서 최대값(Max)이나 최소값(Min)을 찾거나, 기본키(Primary key)에 있는 일련번호를 생성하기 위해 최대값을 찾는 형태 해결방안
- 각 분류단위마다 하나의 로우를 가진 별도의 테이블을 생성해 두고, 트랜잭션마다 읽어서 사용하고 +1을 하여 저장하는 방법.
현재 사용자들이 가장 애용하고 있는 이 방법은 결코 권장할 방법이 못된다.
대개의 경우 트랜잭션의 병목현상 및 잠금(Lock)을 발생시키는 원인이 되기 때문. - 시퀀스 생성기(Sequence Generator)을 사용하는 방법.
시퀀스는 테이블이나 뷰처럼 일종의 데이터베이스 객체(Object)이며, 사용권한만 있으면 어떤 SQL 내에서도 마음대로 사용할 수가 있음.
- 각 분류단위마다 하나의 로우를 가진 별도의 테이블을 생성해 두고, 트랜잭션마다 읽어서 사용하고 +1을 하여 저장하는 방법.
CREATE SEQUENCE empno_seq ------------------- 시퀀스 명
INCREMENT BY 1 ------------------- 증가 단위
START WITH 1 ------------------- 시작 숫자
MAXVALUE 100000000 ------------------- 최대값 제한
NOCYCLE ------------------- 순환 여부
CACHE 20 ------------------- 메모리 확보 단위
- 생성된 시퀀스는 SQL 내에서 CURRVAL(현재값), NEXTVAL(다음값)을 이용하여 원하는 값을 제공받음
- 시퀀스는 사용자가 생성한 테이블과는 근본적으로 다름.
- 메모리 내에서 DBMS가 자동으로 관리해 주며, LOCK을 발생하지 않기 때문에 양호한 수행속도를 보장.
- 다음과 같은 경우에서 사용될 수 있음.
- INSERT 문의 VALUE 절
- SELECT 문의 SELECT-List
- UPDATE 문의 SET 절
- 사용 예
SELECT empno_seq.CURRVAL FROM DUAL ;
INSERT INTO EMP (empno, ename, job, hiredate, sal)
VALUES (empno_seq.NEXTVAL, 'James Dean', 'MANAGER', '2011-08-14', 30000000) ;
UPDATE EMP
SET empno = empno_seq.NEXTVAL
WHERE empno = 10001 ;
- 시퀀스의 특징
- 시퀀스는 세션(session)단위로 관리된다.
- 서로 다른 세션에서 NEXTVAL 을 요구하든, 자신의 세션에서 계속해서 요구를 하든 무조건 하나씩 증가된 값이 나타남.
- A 세션에서 NEXTVAL 을 실행하여 CURRVAL 의 값이 10이 나오고, B 세션에서 NEXTVAL 을 실행하여 CURRVAL의 값이 11이 나왔을 경우.
- A 세션에서 CURRVAL 을 다시 실행해도 값은 10 으로 나옴.
- A 세션에서 NEXTVAL 을 다시 실행하면 CURRVAL 의 값은 12가 나옴.
(결과적으로 해당 세션에서 NEXTVAL 을 실행하고 난후 다른 세션의 영향없이 해당 세션의 CURRVAL 값은 동일)
- 어떤 세션에서 NEXTVAL 을 하지 않은 채 CURRVAL 을 요구하게 되면 에러가 발생.
CURRVAL 은 바로 그 세션이 지그 현재 가지고 있는 최종 시퀀스 값을 의미하므로 한번도 NEXTVAL 을 요구한적이 없다면 보유하고 있는 CURRVAL 값이 없기 때문. - 데이터베이스의 데이터 딕셔너리에 관련정보가 저장(시퀀스의 최종값).
- 사용자가 NEXTVAL 을 했을 때마다 디스크에 저장하지 않고, 'CACHE'에 있는 값만큼 선행 증가를 시킴.
최초에 생성되었을때 0을 저장하는 것이 아니라 20(cache 값을 20 으로 지정했다고 가정)을 저장
이후 사용자의 요구에 의해 증가하는 것은 메모리 내에서 관리되다가 20(START WITH 20)이 되는 순간 다시 40(START WITH 40)을 저장.
만약 36 인 상태에서 시스템에 이상이 발생하여 비정상 종료(Abnormal shutdown)가 되었다면 시스템이 다시 가동(startup)되었을 때 41 부터 제공하게 됨.
이로 인해 일부의 값에 누락이 발생(이것을 방지하려면 CACHE 값을 2로 주면되지만 시퀀스를 사용하는 장점이 없어지게 되므로 바람직하지 않음)
CACHE 값은 괜히 불필요한 저장이 빈번하게 발생하지 않도록 충분히 크게 주는 것이 좋음. - 특정 분류단위로 일련번호가 증가하는 경우에는 처리할 수 없음.('DEPTNO + SEQ'로 식별자가 구성되어 있다면 부서별로 일련번호가 발생해야 하므로 시퀀스 적용이 곤란)
1.4.4. FILTER 형 부분범위 처리
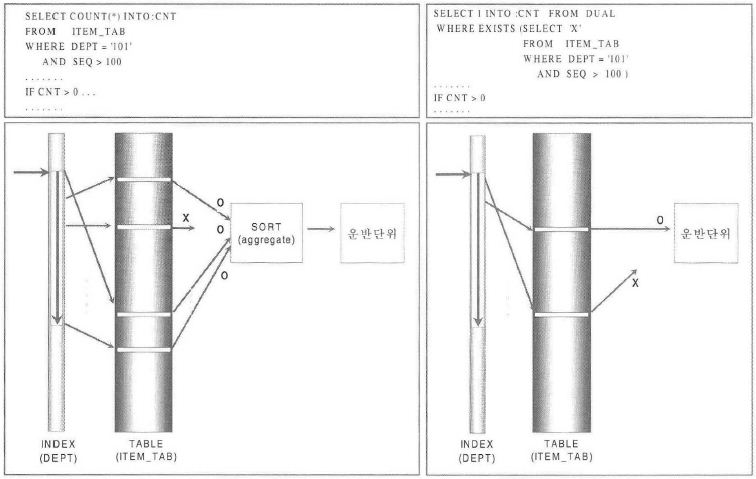
<그림2-1-9>
- 이 SQL 은 그룹함수를 사용하였기 때문에 논리적으로 이미 일부분만 액세스하여 처리하는 것이 불가능함.
- 먼저 드라이빙 조건인 DEPT 를 액세스하여 검증조건인 SEQ 를 체크.
- 통과한 결과에 대해 COUNT 를 하기 위한 정렬작업을 하여 그 결과를 변수에 저장한 후, 'IF CNT > 0'의 조건으로 다음 처리를 진행
- 그림에서도 확인할 수 있듯이 이 SQL 은 그 결과가 몇 건이건 간에 전체범위를 모두 처리하여 그룹함수로 가공하여 하나의 결과를 추출.
이와 같이 단지 존재 여부를 확인하기 위해 전체범위를 모두 처리했다는 것은 엄청나게 비효율적인 처리를 한 것임. - 우측의 그림과 같이 EXISTS 를 사용하여 수행결과의 존재여부를 체크하여 성공과 실패만을 확인하는 불린(Boolean) 함수를 이용하여
단 하나라도 성공한 결과가 나타나면 즉시 수행을 멈추고 결과를 리턴.- 서브쿼리를 부분범위 처리로 수행하다가 조건을 만족하는 첫 번째 로우를 만나는 순간 서브쿼리의 수행을 멈추고 메인쿼리를 통해 결과를 리턴.
SELECT ord_dept, ord_date, custno
FROM order
WHERE ord_date like '2005%'
MINUS
SELECT ord_dept, ord_date, '12541'
FROM sales
WHERE custno = '12541';
- 위 SQL 은 대량의 처리범위를 각각의 로우마다 랜덤 액세스로 대응되는 로우를 찾아 확인하는 것을 피하기 위해 '전체처리가 최적화(ALL ROWS)'되도록 머지 방법으로 유도한 경우.
배치처리 애플리케이션인 경우에는 좋은 방법이 될 수도 있겠지만 전체 범위로 처리되므로 온라인에서는 첫 번째 운반단위가 추출되는 시간이 많이 소요된다.
SELECT ord_dept, ord_date, custno
FROM order x
WHERE ord_date like '2005%'
AND NOT EXISTS (SELECT * FROM sales y
WHERE y.ord_dept = x.ord_dept
AND y.ord_date = x.ord_date
AND y.custno = '12541'
) ;
- 위 SQL 은 부분범위로 처리하도록 실행계획이 변경되었음.
- 여기에서 사용된 서브쿼리는 'NOT EXISTS'를 요구했으므로 서브쿼리의 집합이 적을수록 조건을 만족하는 범위는 오히려 넓어지게 된다.
그러므로 CUSTNO = '12541'을 만족하는 로우가 적다면 체크 조건은 넓어져 아주 빠른 수행속도를 보장받을수가 있으며, 그렇지 않다면 앞서 제시한 'MINUS'를 사용한 SQL 이 더 유리해질 것이다.
1.4.5. ROWNUM의 활용
- ROWNUM 은 모든 SQL 에 그냥 삽입해서 사용할 수 있는 일종의 가상(Pseudo)의 컬럼.
- 이 값은 SQL 이 실행되는 과정에서 발생하는 일련번호이므로 각 SQL 수행 시마다 같은 로우라 하더라도 서로 다른 ROWNUM 을 가질 수 있다.
- 이 또한 컬럼이 분명하기 때문에 조건절에 사용하여 원하는 만큼만 처리가 수행되도록 할 수 있다.
이 방법 역시 전체를 처리하지 않고 일부만 처리하도록 유도하는 방법이므로 일종의 부분범위 처리라고 말할 수 있다.
그러나 SQL 이 실행하는 어떤 과정의 어느 특정 부분에서 ROWNUM 이 결정되는지를 정확히 알지 못하고 사용한다면 원하지 않는 결과가 추출될 수도 있음.
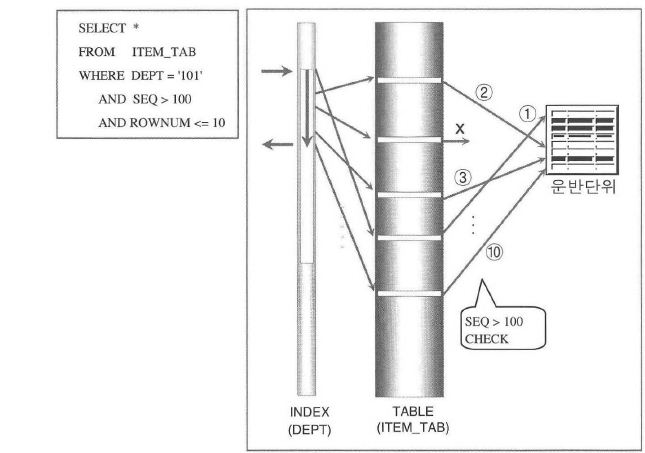
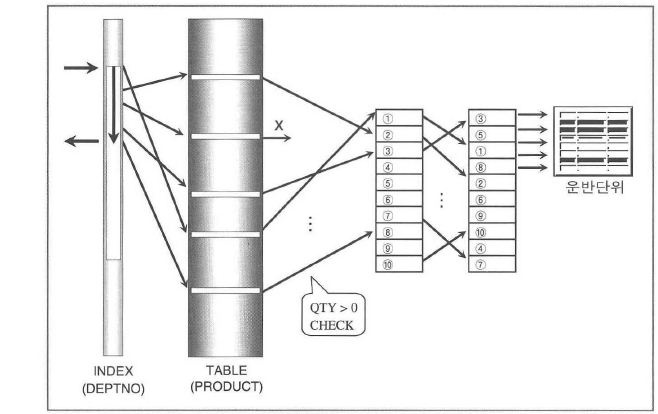
<그림2-1-10>
- 위의 그림에서 인덱스를 통해 액세스한 테이블의 로우들 중에 체크 조건을 확인하여 만족하는 로우들만 ROWNUM 이 부여되어 운반단위로 보내진다는 것을 알수 있다.
- 운반단위가 채워지거나 ROWNUM 이 10보다 커지는 순간 수행을 멈춤.
- 만약 액세스는 했으나 조건을 만족하는 로우가 없다면 끝까지 ROWNUM <= 10 을 만족하지 못했으므로 부분범위 처리 방식임에도 불구하고 전체범위가 끝날 때까지 계속 처리.
- ROWNUM 은 액세스되는 로우의 번호가 아니라 조건을 만족한 '결과에 대한 일련번호'이므로 우리가 단지 10건만 요구하였더라도 내부적으로는 그것보다 훨씬 많은 로우가 액세스될 수도 있다.
- 추출되는 로우중에 10번째 로우를 찾기 위해 WHERE 절에서 'ROWNUM = 10' 을 요구했다면 이 조건을 만족하는 로우는 결코 추출될 수가 없음.
Execution Plan
------------------------------------------------------------
SELECT STATEMENT
COUNT (STOPKEY)
TABLE ACCESS (FULL) OF 'PRODUCT'
- 이 실행계획은 테이블을 부분범위 처리로 액세스하여 ROWNUM 을 COUNT 하다가 주어진 ROWNUM 조건에 도달하면 멈춤(Stopkey)을 하겠다는 것을 나타내고 있다.
이로써 확실히 일정 범위만 스캔했다는 것을 확인할 수 있다.
SELECT ROWNUM, item_cd, category_cd, ......
FROM product
WHERE deptno like '120%'
AND qty > 0
AND ROWNUM <= 10
ORDER BY item_cd
;
- 이 결과는 조건을 만족하는 10개의 로우를 액세스한 다음 정렬하여 결과를 추출한다.
비록 ROWNUM 이 SQL 단위로 생성되는 값이기는 하지만 'ORDER BY'가 수행되기 전에 이미 WHERE 절에 있는 조건을 만족한느 로우마다 부여되어 임시공간에 저장됨.
그러므로 'ORDER BY'를 수행하기 전에 이미 'ROWNUM <= 10'이 적용되어 단 10건만 정렬하여 운반단위로 보냄.
<그림2-1-11>
- 위 그림은 추출된 로우들에 있는 ROWNUM 은 순차적 정렬이 되어 있지 않는다는 것을 확인할 수 있다.
- 이 SQL 은 전체범위 처리를 하여야 하므로 일단 조건에 맞는 데이터를 액세스하여 내부적으로 저장한 다음 이를 정렬하게 된다.
- 내부적인 저장이 일어날 때 ROWNUM 이 생성되어 같이 저장된다는 것을 알수 있음.
- 전체범위 처리를 하는 경우는 중간에 한번 더 가공 단계를 거치게 되므로 최종적으로 추출되는 로우의 순서와 ROWNUM 이 일치하지 않으며, 잘못된 결과를 추출할 수도 있다.
- ORDER BY 를 인라인뷰에 넣은 다음 ROWNUM 을 체크하는 방법
SELECT ROWNUM, item_cd, category_cd, ......
FROM (SELECT *
FROM product
WHERE deptno like '120%'
AND qty > 0
ORDER BY item_cd
)
WHERE ROWNUM <= 10
;
-- 이 방법은 인라인뷰 내에 있는 처리는 전체범위로 수행되므로
-- 불필요한 액세스가 많이 발생할 수 있으므로 주의하여야 함.
- GROUP BY 한 결과를 원하는 로우만큼 추출하고자 할때.
CREATE VIEW PROD_VIEW (deptno, totqty)
AS SELECT deptno, sum(qty)
FROM product
GROUP BY deptno
;
-- 뷰는 자료사전(Data Dictionary)에 SQL 문장이 저장되어 있다가 SQL 을 수행하는 순간,
-- 뷰의 SQL(뷰 쿼리)과 수행시킨 SQL(액세스 쿼리)을 합성(Merge)하여 실행계획을 수립.
-- 아래 SQL 에서는 뷰를 이용해 ROWNUM 을 요구
SELECT ROWNUM, deptno, totqty
FROM PROD_VIEW
WHERE deptno like '120%'
AND ROWNUM <= 10
;
-- 뷰를 생성한 SQL 에는 조건절이 전혀 없었지만 SQL 을 실행하면
-- 액세스 쿼리가 뷰 쿼리로 합성되어 다음과 같은 SQL 이 내부적으로 만들어져서 수행됨.
SELECT ROWNUM, dept, totqty
FROM (SELECT deptno, sum(qty) totqty
FROM product
WHERE deptno like '120%'
GROUP BY deptno
)
WHERE ROWNUM <= 10
;
-- GROUP BY 를 수행한 결과는 내부적으로 저장이 되며 이때 ROWNUM 도 같이 생성됨.
- 위와 같은 처리는 마치 두 개의 SQL 이 수행된 것과 유사하며 내부적으로 저장을 하는 단계 또한 두번에 걸쳐 일어난다.
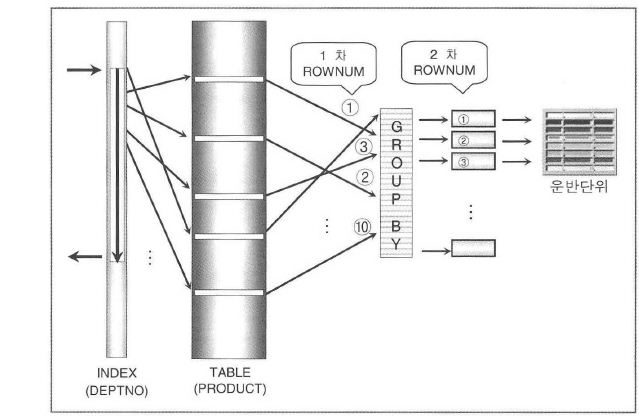
<그림2-1-12>
- 위 그림에서 보는 바와 같이 조건에 맞는 데이터를 액세스할 때 발생되는 ROWNUM(1차)과 GROUP BY 된 결과에 대한 ROWNUM(2차)은 분명한 차이가 있다.
- 논리적으로 보면 단위 SELECT 마다 하나씩의 ROWNUM 을 가질 수 있다고 생각하면 보다 이해가 쉬울 수도 있다.
논리적으로 구성되는 단위 집합마다 ROWNUM 이 존재한다.
만약 선행 집합에서 생성된 ROWNUM 을 활용하고 싶다면 다른 이름으로 치환을 해두면 계속 유효하다.
1.4.6. 인라인뷰를 이용한 부분범위처리
- 인라인뷰를 활용하여 부분범위 처리를 유도하는 원리는 전체범위 처리가 되는 부분을 인라인뷰로 묶어서 다른 부분들은 부분범위 처리가 되도록 하겠다는 것이다.
그대로 두면 전체 쿼리를 전체범위 처리로 만들어 버리는 요인을 인라인뷰로 묶어내어 격리함으로써 다른 처리들을 부분범위 처리가 되도록 하겠다는 것.
SELECT a.dept_name, b.empno, b.emp_name, c.sal_ym, c.sal_tot
FROM department a, employee b, salary c
WHERE b.deptno = a.deptno
AND c.empno = b.empno
AND a.location = 'SEOUL'
AND b.job = 'MANAGER'
AND c.sal_ym = '200512'
ORDER BY a.dept_name, b.hire_date, c.sal_ym
;
- 위 SQL 은 서울에 근무하는 매니저들의 입사일 순으로 급여액을 조회하고자 한다.
이러한 결과를 얻기 위해서 작성한 이 SQL 은 일견 너무나 당연해 보인다.
부분범위 처리를 방해하는 정렬처리 컬럼은 세 테이블에 각각 분산되어 있으며, 추출하려는 로우의 단위는 최하위 집합인 'SALARY' 테이블이므로 어쩔 수 없이 모든 집합을 조인한 후에 정렬을 해야만 한다. - 그러나 가만히 따져보면 분명히 무엇인가 불필요한 작업이 들어가 있다.
서울에 근무하는 매니저들은 크지 않은 집합이 분명하다.
그렇지만 'SALARY' 테이블과 조인하는 순간 로우는 크게 증가한다.
이렇게 증가된 집합을 정렬하여 결과를 추출한다면 좋은 수행속도를 얻을 수 없다. - 적은 집합인 'DEPT' 와 'EMPLOYEE' 테이블만 먼저 조인시키고 그 결과만 먼저 정렬시킨 다음,
대량의 집합인 'SALARY' 테이블은 기본키인 'empno + sal_ym' 인덱스를 경유하게 하는 벙법으로 동일한 결과를 얻을 수 있다면 가장 이상적인 실행방법이 될 것이다.
SELECT /*+ ORDERD, USE_NL(x y) */
a.dept_name, b.empno, b.emp_name, c.sal_ym, c.sal_tot
FROM (SELECT a.dept_name, b.hire_date, b.empno, b.emp_name
FROM DEPT a, EMPLOYEE b
WHERE b.deptno = a.deptno
AND a.location = 'SEOUL'
AND b.job = 'MANAGER'
ORDER BY a.dept_name, b.hire_date ) x, SALARY y
WHERE y.empno = x.empno
AND y.sal_ym = '200512'
;
- 위에서 힌트를 사용한 것은 반드시 인라인뷰를 먼저 수행한 다음, 그 결과와 'SALARY' 테이블이 Nasted Loop 조인이 되도록 하기 위해서 이다.
- 이 SQL 에서 알 수 있듯이 처리 대상이 적은 테이블을 먼저 처리하여 전체범위 처리가 되도록 함으로써 대량의 데이터를 가진 집합은 부분범위로 처리되도록 했다는 것을 알수 있다.
- 다음은 GROUP BY 를 통해 가공된 중간 집합을 생성하고 나머지 참조되는 일종의 디멘전 테이블들을 부분범위 처리로 유도하는 경우.
SELECT a.product_cd, product_name, avg_stock
FROM PRODUCT a,
(SELECT product_cd, SUM(stock_gty) / (:b2 - :b1) avg_stock
FROM PROD_STOCK
WHERE stock_date between :b1 and :b2
GROUP BY product_cd ) b
WHERE b.product_cd = a.product_cd
AND a.category_cd = '20'
;
- 최적의 처리가 될 수 있는 수행절차의 시나리오
- 대량의 처리 대상 범위를 가진 CATEGORY_CD 가 20인 PRODUCT_CD 를 부분범위 처리 방식으로 첫 번째 로우를 읽는다.
- 읽혀서 상수값을 가지게 된 PRODUCT_CD 와 이미 상수값을 가진 STOCK_DATE 로 인덱스 (product_cd + stock_date 로 구성되었다고 가정)를 이용해 PROD_STOCK 테이블을 액세스하여 평균 재고수량을 구한다.
- 두 번째 PRODUCT_CD 에 대해 위의 작업을 반복하다가 운반단위가 채워지면 일단 멈춘다.
1.4.7. 저장형 함수를 이용한 부분범위처리
- 저장형 함수가 가지고 있는 가장 큰 특징은 SQL 내로 절차형 처리를 끌어들였다는 점이다.
- 저장형 함수는 데이터베이스가 제공하는 절차형 SQL 을 이용해 생성한다.
- 저장형 함수 내에는 하나 이상의 SQL 이 존재할 수 있음은 물론이고 다양한 연산이나 조건처리, 반복(Loop) 처리도 할 수 있음.
- 외부에서 받은 값이나 고정된 상수값을 이용하여 필요한 처리를 하여 단 하나의 결과값만을 리턴.
- 저장형 함수는 처리할 각 집합의 각각의 대상 로우에 대해 한 번씩 수행.
- 저장형 함수는 장점뿐만 아니라 많은 단점을 가지고 있으므로 정확한 개념을 알지 못한 채 함부로 사용해서는 안된다.
- 단일값만 리턴하기 때문에 만약 여러 개의 결과를 얻고자 한다면 반복해서 사용해야 하므로 매우 주의해서 사용해야함.
- 해당 집합의 로우마다 실행된다는 것은 처리 속도에 문제가 될 소지가 많기 때문에 주의를 할 필요가 있음.
- 배치 처리 형태의 애플리케이션이라면 더욱 더 저장형 함수를 사용하지 않는 것이 좋다.
배치 처리는 일반적으로 처리할 데이터가 훨씬 더 많으므로 부하에 대한 부담은 더욱 늘어날 수 있기 때문.
CREATE or REPLACE FUNCTION GET_AVG_STOCK
( v_start_date in date,
v_end_date in date,
v_product_cd in varchar2
)
RETURN number IS
RET_VAL number(14) ;
BEGIN
SELECT SUM(stock_qty) / (v_start_date - v_end_date) ) into RET_VAL
FROM PROD_STOCK
WHERE product_cd = v_product_cd
AND stock_date between v_start_date and v_end_date ;
RETURN RET_VAL ;
END GET_AVG_STOCK ;
SELECT product_cd, product_name,
GET_AVG_STICJ (product_cd, :b1, :b2) avg_stock
FROM PRODUCT
WHERE category_cd = '20'
;
- 위의 SQL 을 보면 어디에도 전체범위 처리를 해야 할 요인들을 찾을 수 없기 때문에 부분범위 처리가 되는 것이 확실하다.
설사 저장형 함수에 훨씬 더 복잡한 처리가 들어있더라도 부분범위 처리에는 아무런 영향을 미치지 못한다.
가) 확인자 역할의 M 집합 처리를 위한 부분범위처리
SELECT y.cust_no, y.cust_name, x.bill_tot, ............
FROM ( SELECT a.cust_no, sum(bill_amt) bill_tot
FROM account a, charge b
WHERE a.acct_no = b.acct_no
AND b.bill_cd = 'FEE'
AND b.bill_ym = between :b1 and :b2
GROUP BY a.cust_no
HAVING sum(b.bill_amt) >= 1000000 ) x, customer y
WHERE y.cust_no = x.cust_no
AND y.cust_status = 'ARR'
AND ROWNUM <= 30
;
- 위 SQL 은 고객의 상태가 '체납(ARR)'인 사람이 보유하고 있는 계정(Account)들의 청구(Charge) 정보에서 주어진 기간 내에 요금(Fee)으로 청구한 총금액이 백만 원이 넘는 30명만 선별하고자 하는 SQL 이다.
- 추출하고자 하는 데이터는 CUSTOMER 레벨이지만 이를 위해 액세스해야 할 데이터는 그 보다 하위인 ACCOUNT 와 CHARGE 테이블이다.
- 만약 체납 고객이 5% 미만이고 그 중에서 30명은 1/100 이라면 우리가 불필요하게 처리한 일량은 실로 막대하다.
- 이러한 비효율을 제거하기 위해서 우선 생각해볼것은 EXISTS 서브쿼리를 활요하는 방법일 것이다.
- 그러나 이 서브쿼리는 불린 값만을 리턴할 수 있기 때문에 위의 예에서처럼 고객의 요금청구총액(bill_amt)을 얻을 수 없어 적용이 불가능하다.
- 결과를 리턴 받으면서 부분범위를 가능하게 하려면 저장형 함수를 사용함으로써 간단하게 해결할 수 있다.
CREATE or REPLACE FUNCTION CUST_ARR_FEE_FUNC
( v_costno in varchar2,
v_start_ym in varchar2,
v_end_ym in varchar2
)
RETURN number IS
RET_VAL number(14) ;
BEGIN
SELECT sum(bill_amt) into RET_VAL
FROM account a, charge b
WHERE a.acct_no = b.acct_no
AND a.cust_no = v_cust_no
AND b.bill_cd = 'FEE'
AND b.bill_ym between v_start_ym and v_end_ym ;
RETURN RET_VAL ;
END CUST_ARR_FEE_FUNC ;
SELECT CUST_NO, CUST_NAME, CUST_ARR_FEE_FUNC(cust_no, :b1, :b2), ................
FROM CUSTOMER
WHERE CUST_STATUS = 'ARR'
AND CUST_ARR_FEE_FUNC(cust_no, :b1, :b2) >= 1000000
AND ROWNUM <= 30
;
- 인라인뷰를 활용하는 방법
SELECT cust_no, cust_name, bill_tot, .........
FROM ( SELECT ROWNUM, cust_no, cust_name,
CUST_ARR_FEE_FUNC(cust_no, :b1, :b2) bill_tot, ...............
FROM customer
WHERE cust_status = 'ARR' )
WHERE bill_tot >= 1000000
AND ROWNUM <= 30
;
-- 이 SQL 의 실행계획을 보면 몇 가지 특이한 점을 발견할 수 있다.
Execution Plan
----------------------------------------------------------------------
SELECT STATEMENT
COUNT (STOPKEY)
VIEW --------------------------------------- (b)
COUNT --------------------------------------- (a)
TABLE ACCESS (BY ROWID) OF 'CUSTOMER'
INDEX (RANGE SCAN) OF 'CUST_STATUS_IDX'
- (a) 에 있는 COUNT 는 서브쿼리에 추가한 ROWNUM 때문에 나타난 것.
- (b) 의 'VIEW' 는 내부적으로 이 집합이 저장되었음을 의미함.