2.3.조인 종류별 특징 및 활용방안 (by bshman) [2011.08.09]
h1.조인 종류별 특징 및 활용 방안
조인이라는 데이터와 데이터를 연결하는 작업이다.
우리가 원하는 데이터를 위하여 정규화 되어 있는 정보들을 필요에 의해서 다양한 형태로 결합하여 정보를 얻는다.
조인이란, 여러가지 형태의 조인이 존재하지만 종류마다 가지고 독특한 장ㆍ단점이 존재한다.
이러하여 조인의 특성을 정확히 알고 상황에 맞도록 적절한 방법을 선택해야한다.
물론, 옵티마이져의 성능이 나날이 좋아지고 있지만, 결국 옵티마이져가 처리 할수 있는 한계는 분명 존재하기 때문이다.
이러한 문제로 인하여 우리가 정확한 조인방법을 이해하여 옵티마이져가 최적의 성능을 발휘 할수 있도록 조정해줄수 있어야한다.
h3.<명확하지않은경우>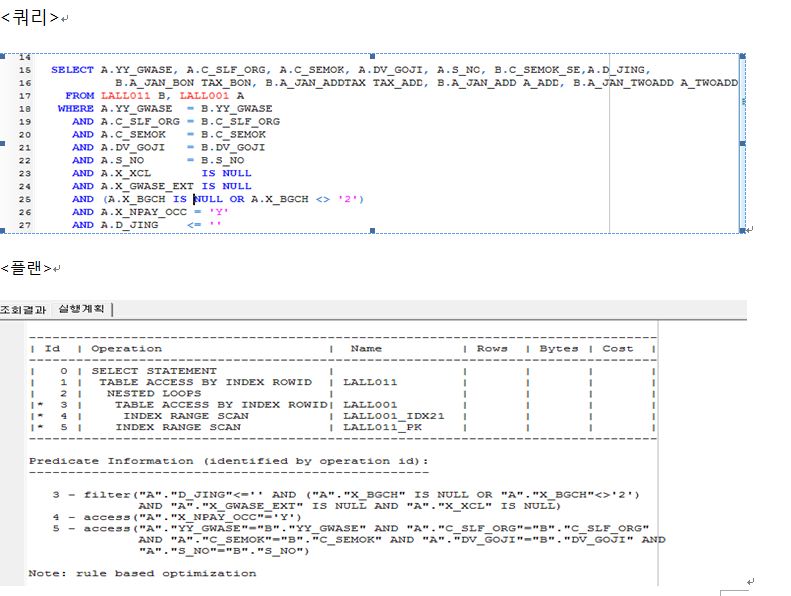
h3.<명확한경우>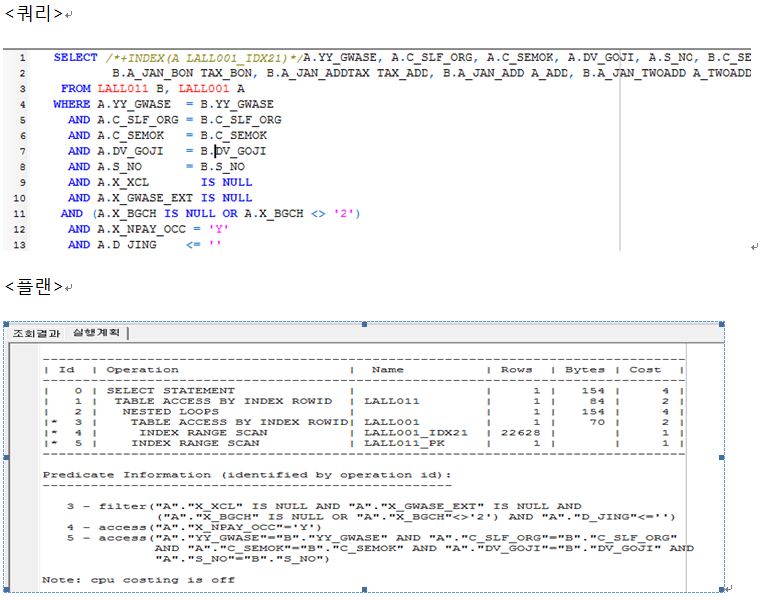
위 두개의 차이는 A.X_PANY_OCC='Y' 부분 인덱스를 강제로 태우도록 힌트를 주었다. 
위의 차이에서 유추 해서 볼수있는 것은 통계정보를 수집하지 않은 상태에서
옵티마이져의 선택은 불불명할수있다 라는걸 알수있다. 인덱스가 존재존재하는경우
이런식으로 강제적으로 인덱스를 태울수 있도록 처리하는것도 하나의 방법일수도 있다.
조인의 형태로 크게 두 가지로 존재하는데, NESTED LOOP JOIN과 SORT MERGE JOIN 이존재한다.
두가지 조인에 대해서 알아보도록 하겠다.
h2.조인 종류별 특징 및 활용 방안
Nested Loop 조인은 가장 전통적인 방법이면서, 보편적인 조인방식이다.
이 조인 방식이 그러한 역할을 하게 되는 가장 근복적인 이유는 먼저 엑서스한 결과를
다음의 엑세스에 상수값으로 제공해 줄 수 있다는데 있다.
하지만, 선행처리결과에서 범위를 적게 줄여 주었는데, 다음 처리할 집합에서
이것을 전혀 활용하지못한다면 이것은 전혀 효율적이지 않는다.
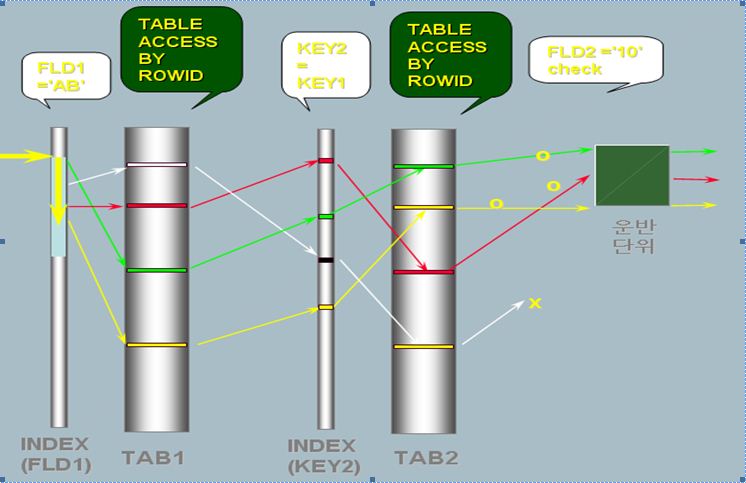
Nested Loop 조인은 그림과 같이 절차로 수행하게 된다.
SELECT *
FROM TAB 1 A, TAB B
WHERE A.KEY1 = B.KEY2
AND A.FLD1 ='AB'
AND B.FLD2 ='10'
h2.Nested Loops 조인의 특징
- 순차적, 선행적, 종속적, 랜덤 액세스, 선택적, 연결고리상태, 방향성, 부분범위처리가능, 체크조건의 영향력
h2.Nested Loops 조인의 특징 및 적용기준
- 부분범위처리를 하는 경우에 유리해진다.(부분범위처리가능)
- 조인되는 어느 한족이 상대방 테이블에서 제공한 결과를 받아야만 처리범위를 줄일수 있는 상황이라면 Nested Loop 조인방식을 선택해야한다.(순차적, 선행적, 종속적)
- 주로 처리량이 적은 경우 라면 대개 Nested Loop 방식이 가장 무난하다.(랜덤 액세스)
- Nested Loop 방식은 연결고리의 인덱스를 이용하기 때문에 연결고리의 상태에 따라 매우 큰 차이가 발생한다(선택적, 연결고리 상태, 방향성)
- 먼저 수행한 집합의 처리범위의 크기와 얼마나 많은 처리 범위를 미리 줄여 줄 수 있느냐가 수행속도에 많은 영향을 미친다.(순차적,선행적)
- 부분범위처리를 하는 경우에는 운반단위의 크기가 수행속도에 상당항 영향을 미칠 수 있다.(부분범위처리)
- 선행 테이블의 처리 범위가 많거나 연결 테이블의 랜덤 엑세스의 양이 아주 많다면 Sort Merge 조인이나 해쉬조인을 검토해야 한다.(체크조건의 영향력)
h2.Nested Loops 조인의 조인의 순서결정
Nested Loop 은 먼저 수행되는 결과가 연결할 범위에 절대적인 영향을 미치기 때문에 어떤 순서로 선행조건이 수행되었는가가 중요하다.
SELECT ........
FROM TAB1 X, TAB2 Y, TAB3 Z
WHERE X.A1 = Y.B1
AND Z.C1 = Y.B2
AND Z.A2 = '10'
AND Y.B2 LIKE 'AB%';
| no | 순서 | ACCESS PATH | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | TAB1 TAB2 TAB3 | A2 ='10' B1 = A1 AND B2 LIKE 'AB%' C1 = B2 | 2 | TAB2 TAB3 TAB1 | B2 LIKE 'AB%' C1 = B2 A1 = B1 AND A2 ='10' | 3 | TAB3 TAB2 TAB1 | FULL TABLE SCAN B2 = C1 AND B2 LIE 'AB%' A1 = B1 AND A2 ='10' |
데이터 모델의 릴레이션쉽에 따라 조인의 성공률은 달라진다.
여기서 성공률이란 조인되는 집합이 자식 쪽이어서 1'쪽의 집합을 'M' 집합으로 증가시킨 다는 것을 표현한 말이다.
집합이 증가할수록 다음에 조인할 대상이 증가하는 것은 당연하므로 조인의 순서를
결정할 때 가능하다면 'M' 집합은 나중에 처리될수록 좋다. 물론 항상 그렇다는 것은아니다.
여기서 '가능하다면'이라는 말의 진정한 의미는 '자신의 처리범위를 줄여줄 수 있는 다른 집합이 먼저 엑세스 된후'
라는 의미와 자신이 먼저 처리범위를 줄여줄 수 있다면 그들보다 먼저 라는 의미가 함께 포함된것이다.
{CODE:SQL}
SELECT .....
FROM ITEM_MST M , ITEM_MOV V , VENDOR A, DEPT D
WHERE M.ITEM_CD = V.ITEM_CD
AND A.VENTOR = V.MANUFACTURE
AND D.DEPTNO = V.ACT_DEPT
AND M.CATEGORY = :B1
AND M.PMA LIKE :B2
AND V.PATERN = :B3
AND V.MOV_DATE BETWEEN :B4 AND :B5
AND D.LOCATION = :B6
위의 SQL은 ITEM_MST 와 ITEM_MOV가 1:M의 관계를 가지며 , ITEM_MOV에 VENDOR 와 DEPT가 '1'쪽 집합으로 연결된걸 알수있다.
{CODE}
이 조인은 ITEM_MST -> ITEM_MOV -> VENDOR -> DEPT 순으로 수행되고있다.
(1) 인덱스를 스캔한 로우 수가 9621 인데 테이블을 액세스한 숫자는 4253이다.
인덱스를 스캔한 개수보다 테이블을 액세스한 숫자가 적다는 것은 인덱스 내부에서 체크하여 걸러졌다는걸 의미한다.
ITEM_M_IDX1 인덱스에는 주어진 조건인 CATEGORY와 PMA 사이에 또 다른 컬럼이 존재하고 있었기 때문에 CATEGORY의
처리 범위인 9620개를 스캔하여 PMA 조건을 체크하니 4253개가 되었다는 것이다.
(2) 선행처리되는 ITEM_MST의 4253 개에 대해 M쪽 집합인 ITEM_MOV가 기본키를 이용해 연결을 하고있다.
약 1:57 비율로 연결이 되어 인덱스를 스캔한 숫자는 243209가 되었다.
그러나 테이블을 액세스 한 것이 그 보다 적은 83212이었다는 것은 조건을 받은
PATTERN이나 MOV_DATE중 하나의 기본키에 포함되어 있기는 하지만 그 사이에 다른 컬럼이
존재하고 있어 인덱스 내에 체크 되었음을 알 수 있다.
이렇게 조인한 결과는 (A)에 나타나는데 4218로 크게 감소한 것을 발견할 수 있다.
(3) 이제 상수값이 된 ITEM_MOV의 MANUFACTURE를 이용해 VENDOR 테이블을 연결하고 있다.
물론 기본키로 연결하기 때문에 나타난 숫자는 인덱스, 테이블 스캔 모두 4218이다.
이것은 곧 이 연결을 통해서 아무것도 줄여 주지 못했음을 의미한다.
(4) 마찬가지 방법으로 DEPT를 연결하였다. 그러나 (B)를 보면 조인에 최종적으로 성공한 것은
124개에 불과하다는 것을 알 수 있다. 이것은 바로 DEPT에 부여한 조건인 LOCATION으로 인한 것임을 쉽게 알 수 있다.
대부분 처리가 완료된 후에 버리게 되었다는것은 비효율을 발생한 것은 틀림없다.
위 실행계획을 분석한 결과 문제점이 발견된걸 확인할수있다.
ITEM_MOV의 MOV_DATE와 DEPT의 LOCATION 이었다. VENDOR는 전혀 범위를 줄여주지 못한것도 알수있다.
그렇다면 제일많은 데이터를 가진 ITEM_MOV 테이블을 가장 먼저 최소 범위를 만드는게 중요하다.
MOV_DATE와 LOCATION이 :B6이 가진 DEPTNO 가 협력해서 처리할 범위를 최소화 시켜주는것이다.
VENDOR는 처리범위를 줄여주지못하기 때문에 제일 나중에 조인되어야한다.
가장유리한 처리순서는 DEPT->ITEM_MOV->ITEM_MST->VENDOR 순이다.
많은범위 처리를 줄여주었던 DEPT 의 LOCATION이 젤먼저 범위를 줄여줘야지만 가장 먼저 엑세스 하여
해당 DEPTNO만 ITEM_MOV만 제공하여야 한다.
이때 가장 이상적인 인덱스 구조는 'ACT_DEPT+PATTERN+MOV_DATE' 이다.
ITEM_MST가 세번째로 연결되어야 하는 이유는 여기서도 일부분 범위가 줄어들기 때문이다.
이 조인은 OTEM_CD 로만 생성된 기본키로 'UNIQUE_SCAN'을 하게 되므로
연결이 된 후에 나머지 조건인 CATEGORY와 PMA를 체크할수 밖에없다.
만약에 ITEM_MST의 조건인 CATEGORY, PMA 조인인덱스로 구성되어있다면 최적의 조인이 수행될것이다.
가령, 'ACT_DEPT+PATTERN+MOV_DATE'로 인덱스를 구성하지못하고 PATTERN+MOV_DATE로 된 인덱스를 사용할 수 밖에없다면,
ITEM_MOV->DEPT->ITEM_MST->VENDOR 순으로 조인되는게 가장 유리하다.
조인의 순서를 결정하기 위한 구체적인 방법에 대해서 알아보도록 하겠다.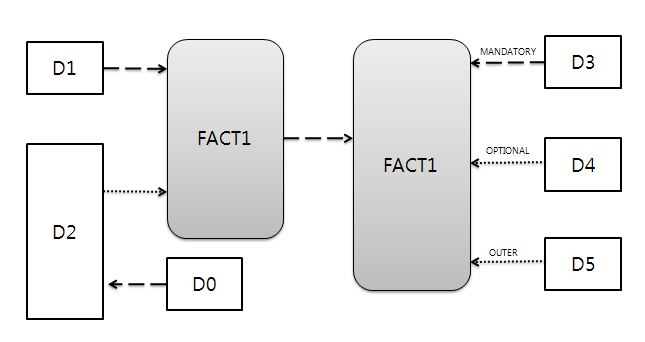
대부분의 조인쿼리는 몇 개의 트랜잭션 데이터가 들어가 있는 일종의 팩트 테이블이 존재한다,.
개념적으로는 하나의 집합이지만 정규화로 인해 이러한 모양이 될 수 있다.
그들의 주변에는 여러 개의 참조 모델들이 관계를 맺게 된다.
이러한 참조 모델들은 필수적(MANDATORY)관게를 가지거나, 선택적(OPTIONAL) 관계를 가지게 되며,
그 중에서는 아우터 조인으로 연결되기도 한다.
경우에 따라 D0 처럼 몇단계 걸친 관계의 조인도 발생한다.
조인을 하는경우 가장먼저 해야 할일은 조인하는 집합중에서 제일 하위 집합을 찾아내는일이다.
그림에서는 FACT2 테이블인걸 확인할수있다.
이테이블 기준으로 또다른 팩트 테이블이 FACT1을 찾을수가 있다.
FACT1 테이블의 자기부여 상수조건은 D1, D2, D0
FACT2 테이블의 자기부여 상수조건은 D3, D4, D5 인데 D5는 OUTER 조인이므로 제외한다.
이유는 아우터 조인은 제공자 역할을 할 수 없기 때문이다.
이런식으로 확보된 조건을 확인하여 처리범위를 많이 줄일수 있는지 비교해본뒤
애매한 경우 SROT MERGE 조인이나 해쉬조인으로 수행하는 경우가 많다.
우열을 가려졌으면 각 테이블이 보유한 인덱스 구조를 참조하여 다시한번 평가한다.
아무리 많은 조건이 걸려있어도 인덱스에 결합 되지 않았다면 인덱스 머지를 하지 않고서는
그중 하나만 선택되고 나머지는 체크 조건만 역할 한다.
WHERE 절에 사용된 조건들은 어떤 수단으로 액세스를 했든지 소량의 집합이 된다면
선행되어야 할 이유는 충분히 존재한다.
그것은 다음 선행되는 처리범위를 줄여주기 때문이다.
또한, 자신은 비록 처리범위를 줄이지 못했지만 그 결과가 다른 조인에 좋은 영향을 미칠 수 있다면
선행처리 될수 있도록 한다.
집합을 증가 시키는 'M'쪽 집합과 조인이 남아 있다면 일단 그 집합을 조인하기 전에
남아 있는 연결 가능한 디멘전 테이블과 조인을 우선적으로 검토 하는 것이 좋다.
그 중 자신의 범위를 줄여줄수 있는 조건이 있다면 보다 많은 양을 줄일수 있는 것부터
조인을 하고, 아우터 조인은 마지막으로 보낸다.
여기까지 순서가 결정되었다면 'M'쪽 집합과 조인을 한다.
가능한 체크조건을 활용하여 조금이라도 줄여 줄 수 있는 것들부터 조인을 실시한다.
지금까지 처리된 집합의 결과를 조인하고자 하는 집합에 결과를 제공했을 때 그것을 받는것이
훨씬 유리하다면 NESTED LOOP 아니면, SORT MERGE나 해쉬 조인으로 유도해야한다.
최적의 처리경로를 알고 있어도 실행계획을 그렇게 나타나지 않는 경우가 존재한다.
그런경우에는 적절한 힌트나 인라인류를 잘활용 하는 방법이있다.
그래도 안되면 특정 컬럼의 인덱스 사용 억제를 활용하라!
그것도 또 안되면 ROWNUM을 삽입하여 특정 인라인뷰가 먼저 수행되도록 하는 등 갖가지 수단과 방법을 동원하라.
h2.Sort Merge 조인
Nested Loop 조인처럼 각각의 연결할 대상에 대해 일일이 랜덤 액세스를 하지 않으려면 어떻게 하는 방법이있을까?
조인할 집합의 대응되는 대상은 서로 알 수 없는 임의의 장소에 위차한다. 이것을 연결 가능하게 하는 방법은
서로 사전 작업을 통해 연결할 수 있는 모습으로 다시 배치를 하게 해야 한다. 여기서 연결을 할 수 있도록
사전에 하는 재배치를 정렬(Sort) 방식으로 하여, 이들을 서로 연결(Merge)하는 방식을 Sort Merge 조인이다
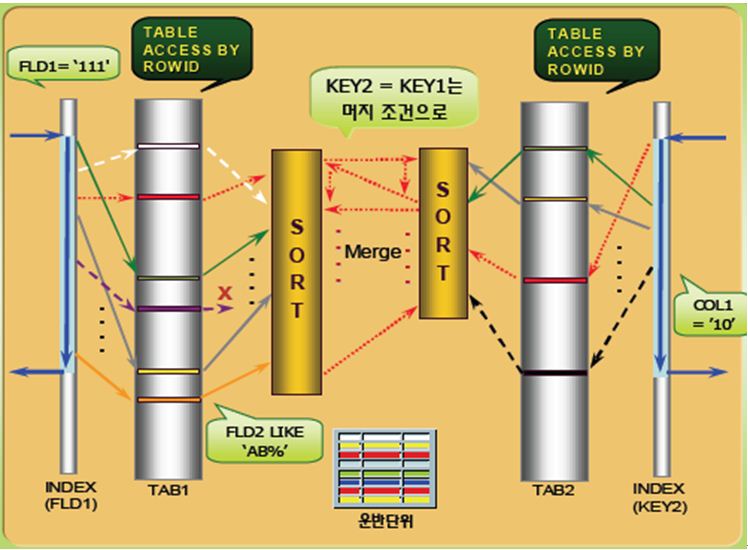
Sort Merge 조인은 그림과 같이 절차로 수행하게 된다.
h2.Sort Merge 조인의 특징 및 적용기준
- 전체범위 처리를 할 수 밖에 없는 프로세싱에서 검토된다(전체범위처리)
- 상대방 테이블에서 어떤 상수값을 받지 않고서도 충분히 처리범위를 줄일 수 있다면 상당한 효과를 기대할 수 있다.(독립적)
- 주로 처리량이 많으면서 항상 전체범위 처리를 해야 하는 경우에 유리해진다.(전체범위처리)
- 연결고리 이상 상태에 영향을 받지 않으므로 연결고리르 ㄹ위한 인덱스를 생성할 필요가 없을때 매우 유용하게 사용할수 있다.(스캔방식)
- 스스로 자신의 처리범위를 어떻게 줄일 수 있느냐가 수행속도에 많은 영향을 미치므로 보다 효율적으로 액세스할 수 있는 인덱스 구성이 중요하다.(선택적)
- 전체범위처리를 하므로 운반단위의 크기가 수행속도에 영향을 미치지 않는다.(무방향성)
- 처리할 데이터 량이 적은 온라인 애플리케이션에서는 Nested Loops 조인이 유리한 경우가많다.(Nested Loop조인비교)
- 옵티마이져 목표(Goal)가 'ALL_ROWS'인 경우는 자주 Sort Merge 조인이나 해쉬조인으로 실행계획이 수립되므로 부분범위 처리를 하고자 한다면 이 옵티마이져 목표가 어떻게 지정되어있는지에 주의하여야한다.(Nested Loop조인비교)
- 충분한 메모리 활용이 가능하고, 병렬처리를 통해 빠르게 정렬작업을 할 수 있다면 대량의 데이터 조인에 매우 유용하게 적용할 수 있다.(Nested Loop조인비교)
h2.Nested Loops 조인& Sort Merge 조인 비교
해당SQL를 실행하였을때 두조인에 대해서 비교해보자.
SELECT *
FROM TAB1 A, TAB2 B
WHERE A.KEY1 = B.KEY2
AND A.FLD1 = '111'
AND A.FLD2 LIKE 'AB%'
<== 삭제
Nested Loops 조인으로 수행했을경우 처리철차를 확인해보자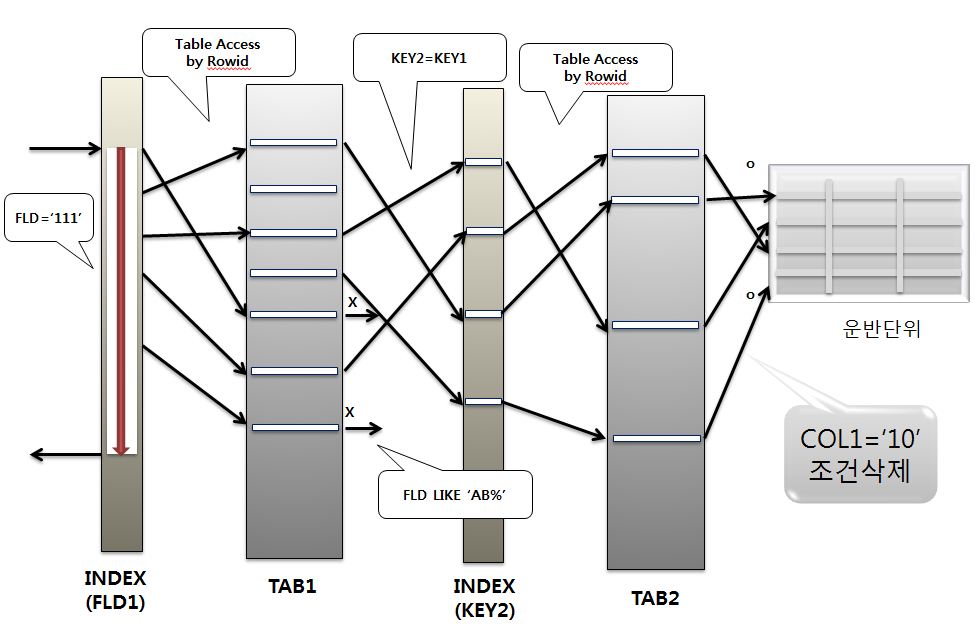
이 조건은 수행했던 일의 모든조인이 완료된 다음 단지 최종적으로 체크하는 역할을 했다.
이 체크 기능이 없어짐으로써 달라진 일은 성공 결과값이 늘어난것이다.
이와 같이 Nested Loops 조인에서는 어느 한쪽의 조건이 없어지더라도 영향을 크게 받지 않을 수도 있으며,
경우에 따라서 오히려 유리해질 수도 있다.
Sort Merge 조인으로 수행을 하였을경우 처리절차를 확인해보자.
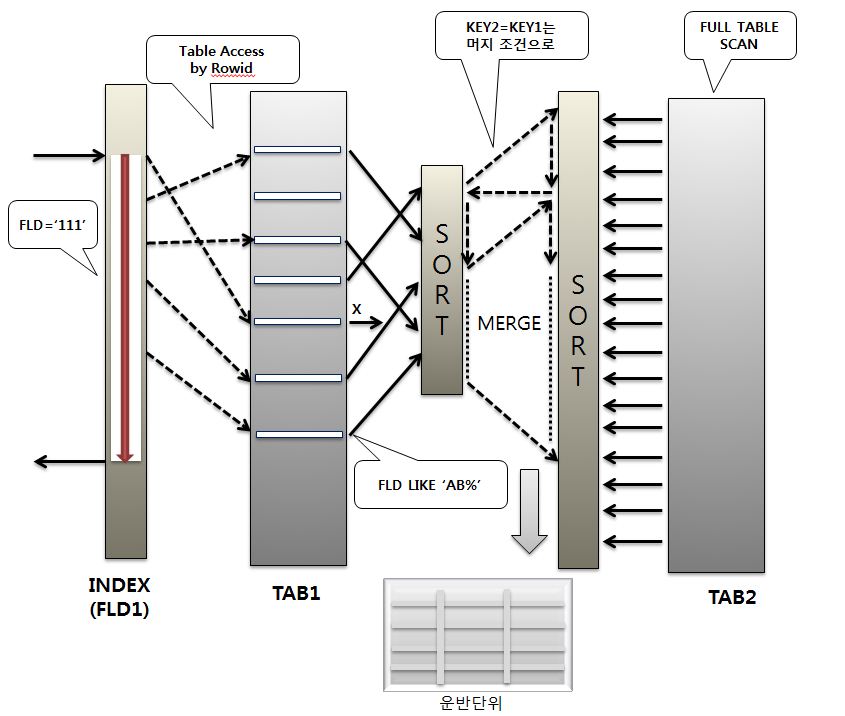
위와같이 TAB2의 COL1 ='10'인 조건이 빠짐으로써 발생하는 차이를 살펴보자면,
Nested Loops 는 TAB2의 처리범위를 줄여 주는 중요한 역할을 했지만,
이 조건이 없어짐으로써 이제 TAB2는 전체 테이블을 모두 스캔하여 부담되는 정렬의 범위가 크게늘어나고,
머지할 양도 크게증가하였다.
이와 같이 한쪽에 조건을 삭제해 보았더니 nested Loops 조인은 거의 영향은 받지않았으나
Sort Merge 조인은 엄청난 일의 증가를 가져왔다. 이것으로 두개의 조인의 차이점은 확인할수있다.
아래 SQL은 ORDER BY 를 하였으므로 전체범위를 처리하게 될것이다.
SELECT *
FROM TAB1 A, TAB2 B
WHERE A.KEY1 = B.KEY2
ORDER BY A.FLD5, B.COL5
SQL이 전체범위처리를 Nested Loops 조인으로 수행하였을 때 처리되는 절차를 확인해보자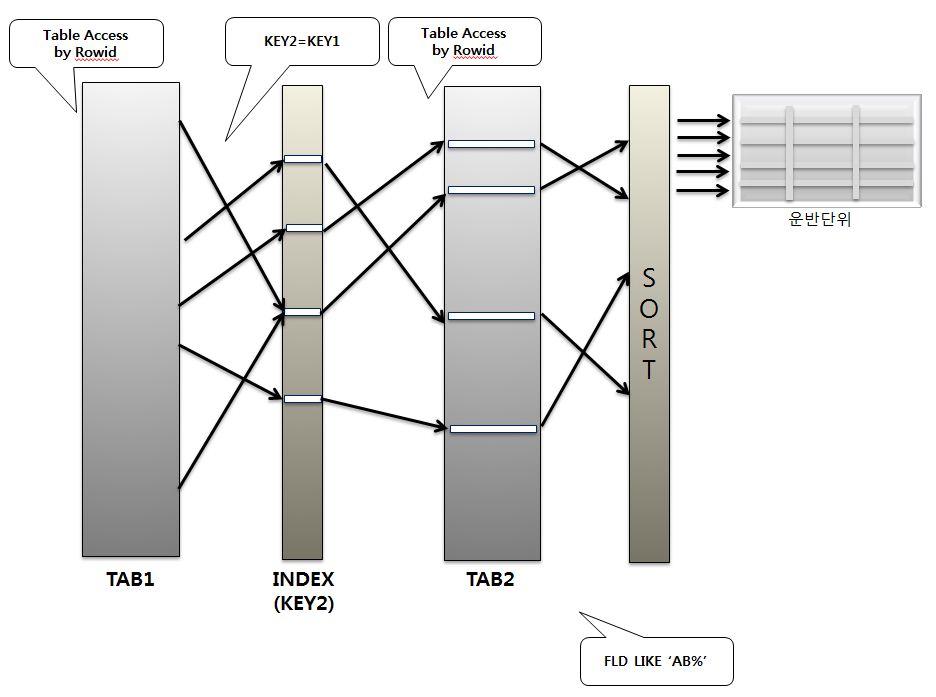
조인되는 양쪽에 모주 조건이 없으므로 어느 한쪽이 먼저 전체 테이블을 스캔한다. 여기서는 TAB1
읽혀진 KEY1의 상수값에 대응되는 로우를 KEY2 인덱스에서 찾아 ROWID로 TAB2의
해당 로우를 액서스한다. 이 처리방식은 선행테이블이 전체 테이블을 스캔하므로 전체 테이블을 대상으로 랜덤 액세스가 발생한다.
이번에는 동일한 SQL로 Sort Merge 조인으로 수행시켰을 때의 어떤 차이를 내는지 확인해보자.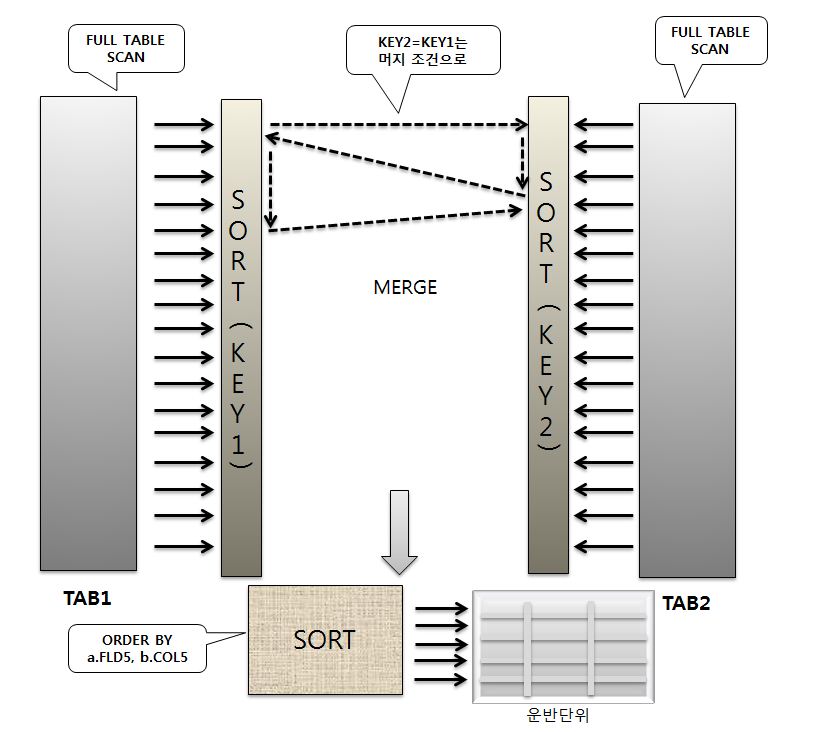
조인되는 양쪽에 모두 조건이 없으므로 각각의 테이블마다 전체 테이블을 스캔하여 연결고리가 되는 컬럼으로
정렬한 후 머지한다. 어차피 전체 테이블을 조인해야 한다면 랜덤으로 전체 테이블을 액세스하는 것보다
스캔방식으로 전체 테이블을 액세스하는 것이 당연 유리하다.
이와 같이 전체 테이블에 대한 Sort Merge 조인에서는 대량의 랜덤 액세스를 피할 수 있으므로
Nested Loops 조인에 비해 훨씬 더 유리해진다.
h2.해쉬(Hash)조인
전통적인 조인방식인 Nested Loops 방식과 Sort Merge 방식은 장-단점이 매우 대조적이어서 서로의 단점을
보완해 주는 대체 수단으로서 활용되어 왔다.
데이터 처리범위가 날이 갈수록 초대형으로 증가하면서 이제 많은 부분에서 Sort Merge 가 더 이상의 대안이 될 수 없는 지경에 이르었다.
이에 대한 해결책이 필연적으로 요구되었고ㅡ 거기에 부응해서 나타난 솔류션이 바로 해쉬조인이라고 할 수 있다.
해쉬 조인은 대용량 처리의 선결조건이 랜덤과 정렬에 대한 부담을 해결할 수 있는 대안으로서 등장하게 되었다.
물론, 이런 문제는 초대용량 데이터가 아니라면 클러스터링 팩터를 향상시킨다든지, 정렬영역을 늘여 주는 방법으로
상당한 효과를 얻을 수도 있다.
그러나 초대량 데이터라면 이미 그러한 방법으로서는 도저히 버틸 수 없게 된다는 데 문제의 심각성이 있다.
해쉬 조인이 이러한 면에서 강점을 가지는 이유는 연결행위마다 인덱스를 경유하여 랜덤을 하지 않고 해쉬함수를
이용한 연결을 한다는 점과 파티션단위로 처리하기 때문에 대량의 처리에도 수행속도가 급격히 상승하지 않는다는 것에 있다.
해쉬 조인은 가장 기본적인 원리는 해쉬함수를 활용하는데 있다, 원래 수학에서 말하는 함수란 어떤 값을 대입하면
어떤 연산을 처리하여 결과값을 리턴하는 것이다.
이와 마찬가지로 데이터의 컬럼에 있는 상수값을 입력으로 받아 '위치값'을 리턴하는 것을 해쉬함수라고 이해하면된다.
h4.해쉬영역(Hash Area)
해쉬 영역이란 해쉬 조인을 수행하기 위해 메모리 내에 만들어진 영역을 말한다. 이 영역은 비트맵 벡터와 해쉬 테이블, 그
리고 파티션 테이블 영역으로 구성되어 있다.
해쉬 테이블에는 파티션들의 위치정보를 가지고 있으며 조인의 연결 작업을 수행할 때나 디스크에 내려가 있는
파티션 짝들을 찾는데 사용된다. 파티션 테이블에는 여러 개의 파티션이 존재하며, 조인할 집합의 실제 로우들을 가지고 있는 영역이다.
해쉬영역이 부족하면 디스크를 사용할 수 밖에 없어 수행속도에 지대한 영향을 미치게 되므로
해쉬영역크기를 적절하게 지정하는 것은 매우 중요하다.
h4.파티션(Partition)
파티션이란 파티션을 결정하기 위해 수행하는 첫 번째 해쉬함수가 리턴한 동일한 해쉬값을 갖는 묶음을 말한다.
즉, 동일한 해쉬값을 가진 로우들의 버켓을 말한다. 특히 빌드입력이 인_메모리에 작업이 불가능하면 반드시 파티션으로 나뉘어져야 한다.
이렇게 만들어진 파티션 수를 팬아웃이라고 부른다.
하나의 파티션은 여러 개의 클러스트로 분리된다, 2차 해슁을 하면 저장할 클러스터의 위치가 결정되며,
이 단위는 I/O의 단위가 될 뿐만 아니라 검색의 단위로도 활용된다. 파티션 수를 많게 하면 - 즉,
팬아웃을 크게하면 적는 크기의 많은 파티션이 생성되기 때문에 비효율적인 I/O가 발생할 수 있다.
반대로 너무 적게하면, 지나치게 큰 파티션이 생성되어 해쉬영역과 맞지 않을 수도 있으므로
이에 대한 결정은 해쉬 조인의 효율에 큰영향을 미친다.
h4.클러스터(Cluster)
파티션은 작지 않은 크기로 되어 있기 때문에 이를 다시 클러스터 단위로 분할한다.
이 클러스터는 연속된 블록으로 되어 있으며 디스크와 I/O를 하는 단위가 된다.
물론 주어진 파라메터에 의해 동시에 I/O 하는 양이 결정된다.
특히 해쉬 ㅋ클러스터링을 했을 때와 매우 유사한 형태로 이해하는 것이 좋다.
해쉬 클러스터링을 했을 ?는 해쉬함수에서 생성된 값이 같으면 동일한 클러스터에 저장되고,
이를 검색할 때는 해쉬값으로 해당 클러스터를 찾아 클러스터를 스캔하면서 원하는 로우를 찾는다.
캐비닛을 파티션이라고 한다면 슬롯은 서랍이라고 생각하면 이해가 빠를 것이다.
우리가 물건을 찾을 때도 먼저 캐비닛을 결정한 다음 해당 서랍을 열어서 물건을 꺼내는 것과 매우 유사하다고 하겠다.
h4.빌드입력(Build Input)과 검색입력(Probe Input)
조인을 위해 먼저 액세스하여 필요한 준비를 해두는 처리를 빌드입력이라 하며,
나중에 액세스하면서 조인을 수행하는 처리를 검증 혹은 검색입력이라고 한다.
h4.인_메모리(In-memory)해쉬조인과 유예 해쉬조인
해쉬 조인에는 전체 빌드입력이 해쉬영역보다 적은 경우와 그렇지 않은 경우에 따라 처리 방식에 큰 차이가 있다.
그러므로 무조건 적은 집합을 가진 것이 빌드입력이 되도록 해야 함은 당연하다.
빌드입력이 해쉬영역에 모두 위치할 수 있는 경우는 인_메모리 해쉬조인을 수행하게 되고,
그렇지 못한 경우에는 유예 해쉬조인을 수행하게 된다.
유예 해쉬 조인은 먼저 전체를 빌드입력과 검색입력을 수행하여 여러 개의 파티션에 분할하고,
해쉬영역을 초과할 때마다 임시 세그먼트에 파티션을 저장한다.
h4.비트맵 벡터(Bitmap Vector)
빌드입력에 대해서 파티션을 구하는 작업 중에 생성되며, 빌드입력값들에 대한 유일 값을 메모리 내의 해쉬영역에 정의하는 것을 말한다.
해쉬영역에 만들어지는 비트맵 벡터는 빌드입력의 전체 집합에 대해서 생성된다.
즉, 처리대상이 커서 해쉬영역을 초과하여 임시 세그먼트에 저장하게 되더라도 처리할 빌드 입력의
모든 집합에 대해 조인종료 시 까지 유지된다.
검색입력에 액세스한 것이 어차피 빌드입력에 존재하지 않는다면 굳이 파티션에 위치시킬 필요조차 없기 때문에
이를 필터링 하는 중요한 역할을 하게 된다. 이 작업은 파티션을 결정하기 위해 해쉬함수를 적용하기 전에 수행하여 불필요한
대상들을 걸러내므로 실제 조인에 참여할 대상을 경우에 따라 크게 감소시킬 수 있다,
일반적으로 이 영역은 메모리에 정의하는 해쉬영역의 5%로 생성된다.
h4.해쉬 테이블(Hash Table)
최종적으로 조인의 연결작업에 대응되는 로우를 찾기 위한 해쉬 인덱스로 사용된다.
마치 Nested Loops 조인에서 나중에 대응되는 로우를 인덱스에서 찾는 것과 유사하지만
물리적인 인덱스가 미리 생성되는 것이 아니라 조인을 수행할 때 임시적으로 생성된다는 것이 다른 점이다.
물론 그 인덱스 구조는 해슁을 활용하는 방법이다.
일반 인덱스에서 인덱스 컬럼값과 ROWID를 가지고 있는 것과 유사하게 해쉬 테이블은 해쉬키값과 해쉬 클러스터의 주소를 가지고 있다.
일반적인 인덱스는 테이블의 로우만큼의인덱스 로우를 가지고 있지만 해쉬 테이블에는
실제 테이블의 로우 별로 인덱스를 가지고 있지는 않는다.
이는 마치 해쉬 클러스터링 테이블에서 해쉬 클러스터로 액세스 하는 것과 유사한 개념이다.
일반적인 인덱스 연결은 최악의 경우 하나의 연결을 위해 한 블록이 액세스 될 수 있다.
그러나 해쉬 조인의 연결에서는 파티션 짝(Pair)들간에는 연결에 필요한 데이터가 100%존재하는 것이 보장되기
때문에 메모리 내에 해쉬를 적용하여 수행하는 연결은 일반적인 랜덤과 비교할 수 없이 빠르다.
h4.파티션 테이블(Partition Table)
만약 빌드입력이 메모리 크기를 초과하여 파티션을 생성하게 되면 '파티션 테이블'에 관련정보가 저장된다.
또한 디스크의 임시 세그먼트로 이동하면 그 위치정보를 갖는다. 이 위치 정보는 나중에 다시 메모리로 올려서
처리할 대상을 선정할 때 활용된다. 또한 빌드입력과 검색입력에서 생성된 파티션 간에 서로 짝을 찾는데도 활용된다.
처리되는 단위마다 동적으로 역할이 변할 수 있으며, 이것을 일컬어 동적 역할 반전이라고 부른다.
이러한 개념을 적용하는 이유는 인_메모리 해쉬 조인의 가능성을 높이기 위한 전략 때문이다.
해쉬 테이블은 해당 처리 단위의 연결작업을 위한 인덱스 개념으로 사용되지만
다른 구 가지는 전체 작업에 필요한 정보를 가지고 있기 때문이다.
이들의 합이 전체 해쉬영역의 15%~20% 넘으면 오버헤드가 발생하므로 이런 경우에는 해쉬영역을 증가시키는 것이 바람직하다.
통계정보에 있는 히스토그램을 이용하여 파티션의 크기나 파티션 내의 데이터 분포를 동적으로 관리하여,
이 결과를 다음 번 수행 시에 활용하여 파티션의 크기를 결정하기도 한다. 물론 이러한 기능은 DBMS나 버전에 따라 차이가 있다.
h3.인_메모리 해쉬조인
빌드입력을 모두 메모리에 저장하고 해쉬 테이블을 만들어 검색입력을 스캔하면서 조인을 수행한다.
비록 모양상으로 랜덤이지만 거의 부담이 없는 랜덤을 수행하기 때문에 Sort Merge 조인처럼 연결을 위해서
정렬을 해야 하거나 Nested Loops 조인처럼 수많은 블록을 액세스하지 않아도 되므로 대용량 데이터의 조인에 매우 효과적이다.
또한, Nested Loops 조인만 가질 수 있는 부분범위 처리도 가능하게 되므로
만약 어느 한쪽의 처리범위가 크지 않는 경우라면 매우 효율적인 조인방법이다.
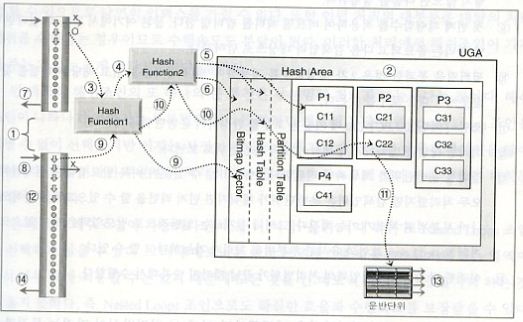
1) 통계정보를 참조하여 보다 효과적인 카디널러티를 갖는 집합을 빌드입력으로 선택한다.
일반적으로 조인은 1:1이나 1:M 관계에서 발생하므로 대부분의 경우 '1' 족 집합이 빌드입력이된다.
2) 팬아웃, 즉 파티션 수를 결정한다. 파ㅣ션의 수와 크기는 성능에 큰 영향을 미치게 되므로 히스토그램 정보를 입각하여
이를 동적으로 최적화하여 결정하게 된다.
3) 빌드입력의 조인키에 1차 해슁함수를 적용하여 저장할 파티션을 결정한다.
4) 2차 해슁함수를 적용하여 해쉬값을 생성한다.
5) 이 값을 이용하여 해쉬 테이블을 만들고, 해당파티션의 슬롯에 저장한다.
이때 저장되는 컬럼은 SQL의 SELECT-List 에 있는 컬럼들도 같이 저장된다.
6) 검색입력의 필터링을 위해 사용할 비트맨 백터를 생성한다. 이 값은 유일한 값으로 만들어지므로
처리할 값을 찾아본 후 없으면 생성하고 있으면 그대로 통과하는 방식으로 생성된다.
7) 이러한 방식으로 빌드입력의 처리범위를 모두 처리할 때까지 반복해서 수행한다.
8) 이번에는 검색입력의 처리범위를 액세스하기 시작하여 조건을 만족하지 않으면 버리고 그렇지 않으면 다음을 실행한다.
9) 첫 번째 해슁함수를 적용하여 비트맨 백터를 필터링 한다. 물론 여기에서 찾을 수 없다면
해당 처리는 종료되고 다음 검색입력 대상으로 넘어간다.
10) 필터링을 통과한 것은 2차 해슁함수를 적용하여 해쉬 테이블을 읽고 해당 파티션을 찾아 슬롯에서 대응 로우를 찾는다.
11) 조인이 되면 SELECT-List 에 기술된 로우를 완성하여 운반단위에 태운다.
12) 이러한 작업을 반복해서 수행하여 계속 운반단위로 보낸다.
13) 정해진 운반단위가 채워지면 리턴한다. 빌드입력은 전체범위를 모두 처리했지만
검색입력은 운반단위가 채워지면 먼저 리턴을 할 수 있으므로 부분적으로 나마 부분범위 처리가 가능해진다.
그러나 실제로는 일반적으로 빌드입력은 크지 않으므로 거의 Nested Loops 조인과 유사한 부분범위 처리가 가능하다고 할 수 있다.
14) 이러한 방식으로 검색입력의 처리범위가 끝날 때까지 반복해서 수행한다.
h3.유예 해쉬조인
빌드입력이 해쉬영역을 초과하면 해쉬조인은 좀더 복잡한 과정을 거치게 된다. 그 이유는 빌드입력이
해쉬영역을 초과하게 되면 어쩔 수 없이 디스크에 저장을 할 수 밖에 없기 때문이다.
빌드입력의 일부라도 디스크에 저장을 할 수 밖에 없게 된다면 마치 정렬을 통해 연결을 하는
Sort Merge 조인처럼 무엇인가 정렬을 유사한 효과를 얻을 수 있는 방법이 있어야 한다.
정렬을 하지 않고서도 연결이 가능하도록 데이터를 위치시키는 방법은 따로 해슁함수를 적용하는 것이다.
Sort Merge 조인은 각각의 집합을 먼저 정렬을 한 후 그것은 머지하는 방식으로 연결을 수행하고,
해쉬조인은 각각의 집합에 대해서 먼저 해슁함수를 적용하여 같은 해쉬값을 갖는
파티션에 저장을 한 후 그들을 짝을 찾아 연결을 수행한다.
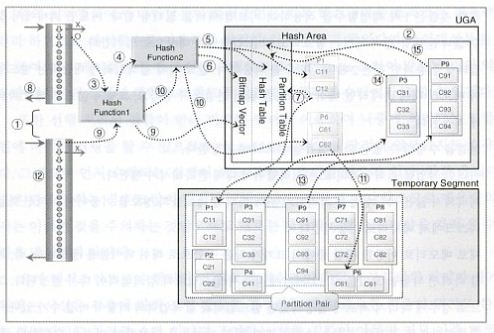
1) 통계정보를 참조하여 보다 효과적인 카디널러티를 갖는 집합을 빌드입력으로 선택한다.
2) 파티션 수를 결정한다.
3) 빌드입력의 조인키에 대하여 1차 해슁함수를 적용하여 저장할 파티션을 결정한다.
4) 2차 해슁함수를 적용하여 해쉬값을 생성한다.
5) 이 값을 이용하여 해쉬 테이블을 만들고, 해당 파티션의 슬롯에 저장한다.
이때 저장되는 컬럼은 SQL 의 SELECT-List 에 있는 컬럼들도 같이 저장된다.
6) 검색입력의 필터링을 위해 사용할 비트맵 백터를 생성한다. 여기서 생성된 값을 이용해
다음에 수행될 검색입력의 필터링을 하게 되므로 유예 해쉬조인에서도 크기가 작은 집합이
빌드입력이 대상을 크게 줄이는 효과를 볼수있다. 여기까지는 인_메모리 해쉬조인과 동일하다.
7) 이러한 방식으로 빌드입력의 처리범위를 처리하다가 해쉬영역을 초과하면 파티션 테이블에
위치정보를 남기고 디스크로 이동하게 된다. 파티션 테이블에 있는 정보는
나중에 파티션 짝을 찾아 연결작업을 수행할 때 사용된다.
8) 빌드입력의 모든 처리범위를 위의 방법으로 끝까지 수행한다.
9) 이번에는 검색입력의 처리범위를 액세스하기 시작하여 조건을 만족하지 않으면 버리고,
만족한 것들은 1차 해슁함수를 저?하여 비트맵 백터를 필터링 한다
비트맵 백터에서 찾을수 없다면 해당 건의 처리는 종료되고 다음 검색입력 대상으로 넘어간다.
10) 필터링을 통과한 것은 2차 해슁함수를 적용한다. 만약 이때 검색입력에 대응되는
빌드입력이 메모리 내에 존재하면 해쉬 테이블을 읽어 연결을 수행하고, 그렇지 않으면 해당 파티션에 저장한다.
11) 연결을 수행할 수 없는 파티션들을 디스크에 저장한다.
12) 이러한 작업을 검색입력의 모든 처리범위에 대해 반복해서 수행한다.
13) 처리되지 않은 파티션들을 처리하기 위해 파티션 테이블의 정보를 이용하여
파티션 짝들을 디스크에서 메모리로 이동시킨다.
14) 새로 메모리로 이동한 집합 중에서 크기가 작은 집합으로 해쉬 테이블을 생성한다.
즉, 처리할 파티션 짝들을 모았을 때, 그 크기에 따라서 빌드입력과 검색입력이 다시 결정된다.
그러므로 경우에 따라서 최초에 결정되었던 빌드입력과 검색입력의 역할이 바뀔 수가 있다.
15) 검색입력으로 결정된 집합을 스캔하면서 해쉬 테이블을 이용하여 연결을 수행한다.
물론 운반단위에 모았다가 채워지면 리턴하는 것은 당연하다. 이러한 작업을 남아 있는 모든 대상에 대해서 실시한다.
h3.유예 해쉬조인의 특징과 적용기준
-조인의 연결을 위해서는 기존에 미리 생성되어 있는 인덱스를 전혀 사용하지 않음
(조인 연결고리에 인덱스가 없어도 영향을 받지 않는다는 것과 그러면서도 오히려 기존의 B-Tree 인덱스 보다 더 유리한 해쉬를 이용한 조인을 할수 있기 때문이다. 이러한 집합의 연산과정은 이미 가공된 집합일 수 있기 때문에 인덱스가 존재하지 않을 수도 있음은 물론이고, 대개의 경우 대용량의 처리이기 때문에 데이터 량의 증가에 따른 부담이 최소화 될 필요가있다.)
-부분범위 처리가 불가능하다.(해쉬조인은 비록 해쉬영역을 초과하는 대용량의 데이터라 하더라도 해쉬함수를 이용하여 적절한 위치에 옮겨 두었다가 조인대상들을 다시 불러 들여 해쉬 테이블을 통해 조인을 수행하므로 Sort Merge 조인이 갖는 최대의 약점인 대용량 데이터의 정렬에 대한 오버헤드를 해결하는 최적의 수단이다. 사실 이 경우 따라 조인 방식을 결정하는 매우 중요한 기준이 된다.)