4.2. 클러스터링 형태의 결정 기준 (by dreamlhs) [2011.08.06]
클러스터링 형태의 결정 기준
- 넓은 범위의 처리를 스캔방식으로 유도하기 위해서 단일테이블 클러스터링을 사용.
- 여러테이블의 조인을 향상시키기 위해서 다중테이블 클러스터링 사용.
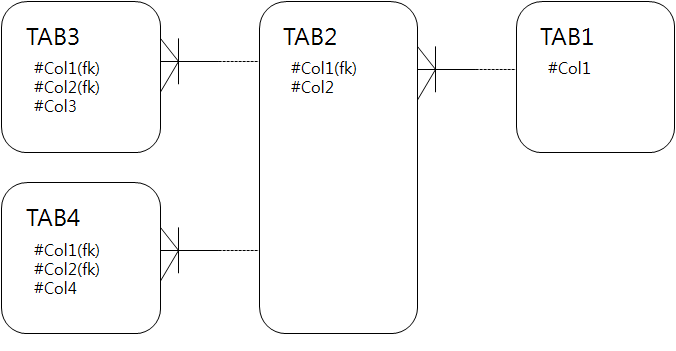
<그림1-4-13>
- TAB3+TAB2+TAB1 으로 광범위 클러스터링
- TAB1+TAB2 만으로 클러스터링
- TAB3나 TAB4를 COL3나 COL4로 단일 테이블 클러스터링
4.2.1 포괄적인 클러스터링
TAB1+TAB2+TAB3를 같은 클러스터로 결합했다고 가정한 모습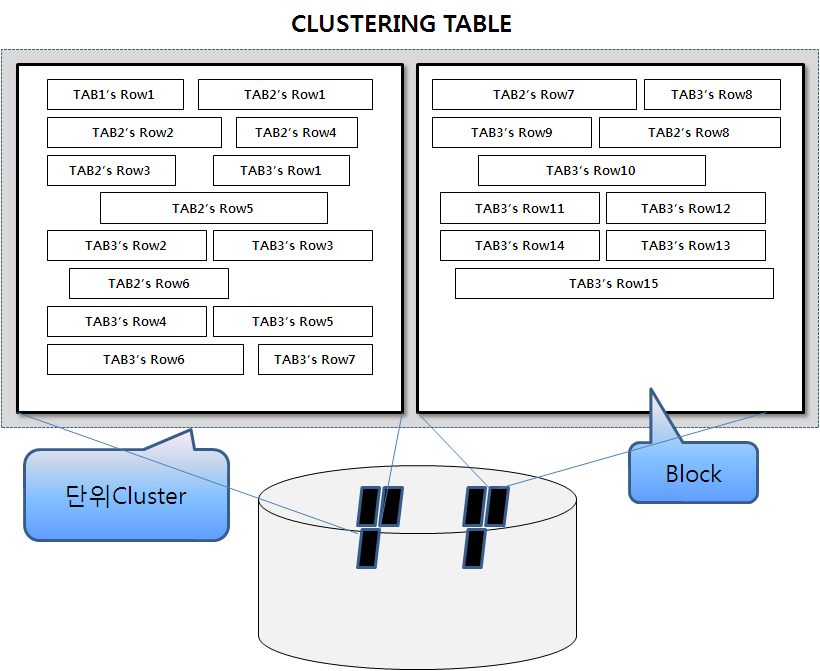
<그림1-4-14>
- 수직계열에 있는 TAB1,TAB2,TAB3는 하위로 내려갈수록 데이터량이 증가한다.
- 이들을 클러스터키로 결합하면, 하나의 TAB1의 로우에 여러개의 TAB2의 로우, 그리고 더 많은 TAB3의 로우가 같이 저장된다.
- 이렇게 증가하다 보면 한블럭을 넘을 것이고, 데이터가 입력되는 시점이 다르다면 클러스터 체인이 발생한다.(클러스터링 팩터를 나쁘게 한다)
- 따라서 다수의 테이블을 클러스터링 하는 것은 현재의 사용형태 뿐만 아니라 향후에 예상되는 액세스 형태를 감안해야 한다.
4.2.2 부분적인 클러스터링
- 업무적인 결합도가 양호한 TAB1과 TAB2만 다중텡블 클러스트링을 하고, 넓은 범위를 자주 스캔하는 TAB3는 COL3로 단일 테이블 클러스터링을 한다고 가정하면....
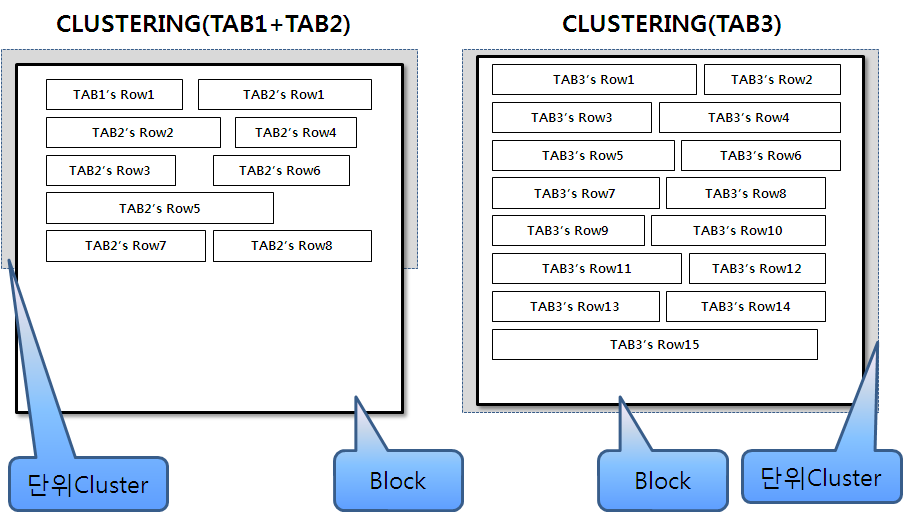
<그림1-4-15>
- TAB1은 여전히 밀도가 낮지만 다른 테이블에 비해서 크기가 작다.
- 상대적으로(TAB1대비) 많은 데이터를 가지고 있는 TAB2는 클러스터링 팩터가 향상되었다.
4.2.3 단일테이블 클러스터링
- 조인의 효율성 향상을 위한 다중 클러스터링은 특정한 경우를 제외하고는 가능한한 피하는 것이 좋다.
- 일반적으로 여러개 테이블을 조인하는 경우는 조인의 수는 많으나 그 처리범위는 그리 넓지 않은 경우가 많다. 여러 테이블을 조인할 경우 그 처리 범위가 넓다면 클러시터링을 했더라도 수행속도를 보장받기 어렵다.(부분범위처리 제외)
- 단일테이블 클러스터링은 넓은 범위를 스캔방식으로 유도하여 수행속도를 향상시킨다.
- 대량의 범위를 자주 처리하는 테이블만 클러스터링하고, 다른 테이블들은 별도로 생성시키는 것이 일반적으로 가장 좋은 방법인 경우가 많다.
4.2.4 단위클러스터의 크기결정
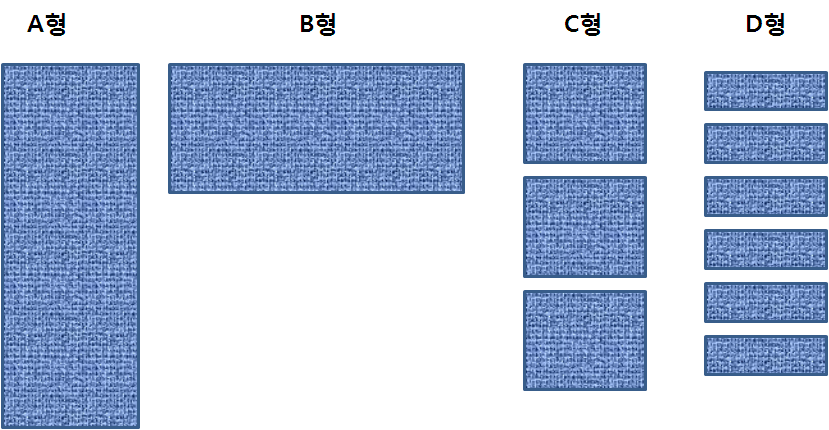
<그림1-4-16>
-A형: 로우 길이가 짧고 단위 클러스터에 많은 로우들이 존재.
-B형: 로우 길이가 길고 단위 클러스터에 적은 수의 로우가 존재.
-C형: A형에 비해 적당한 크기로 단위 클러스터가 분할.
-D형: 매우 작은 크기로 클러스터 생성.
단일테이블 클러스터링 할 경우
- A형 vs. B형: 면적은 동일하지만, 같은 량의 블럭을 액세스 했을 경우 추출되는 로우수는 큰 차이가 난다.A형이 효율적.
- A형 vs. C형: A형이 C형보다 적은 랜덤 발생.A형은 일부 요구에도 불구하고 클러 스터를 전부 액세스 해야 하지만, C형은 특정한 단위 클러스터만 액세스 할 수 있음. C형이 효율적.
- C형 vs. D형: 적은 부분만 액세스 한다면 D형이 유리. 넓은 범위의 처리에서는 D형이 불리하다.
- 단일클러스터크기 계산법
- 블록당 유효 저장공간 크기 = (블록크기 - 블록헤더크기)*(100-PCTFREE)/100
- 로우의 평균길이산정
- 클러스터 키별 로우수 구함
- 단위클러스터 크기를 계산하고 결정
4.2.5 클러스터 사용을 위한 조치
클러스터키컬럼을 첫번째로 하는 인덱스를 생성시키지 말것
클러스터가 반드시 사용되어지기를 원한다면 액세스 경로를 고정시킨다
( /*+ CLUSTER(테이블) */ 힌트 사용)