전통적인 조인방식인 Nested Loops 방식과 Sort Merge 방식은 장-단점이 매우 대조적이어서 서로의 단점을 보완해 주는 대체 수단으로서 활용되어 왔다.
데이터 처리범위가 날이 갈수록 초대형으로 증가하면서 이제 많은 부분에서 Sort Merge 가 더 이상의 대안이 될 수 없는 지경에 이르었다.
이에 대한 해결책이 필연적으로 요구되었고ㅡ 거기에 부응해서 나타난 솔류션이 바로 해쉬조인이라고 할 수 있다.
해쉬 조인은 대용량 처리의 선결조건이 랜덤과 정렬에 대한 부담을 해결할 수 있는 대안으로서 등장하게 되었다.
물론, 이런 문제는 초대용량 데이터가 아니라면 클러스터링 팩터를 향상시킨다든지, 정렬영역을 늘여 주는 방법으로상당한 효과를 얻을 수도 있다.
그러나 초대량 데이터라면 이미 그러한 방법으로서는 도저히 버틸 수 없게 된다는 데 문제의 심각성이 있다.
해쉬 조인이 이러한 면에서 강점을 가지는 이유는 연결행위마다 인덱스를 경유하여 랜덤을 하지 않고 해쉬함수를 이용한 연결을 한다는 점과 파티션단위로 처리하기 때문에 대량의 처리에도 수행속도가 급격히 상승하지 않는다는 것에 있다.
해쉬 조인은 가장 기본적인 원리는 해쉬함수를 활용하는데 있다, 원래 수학에서 말하는 함수란 어떤 값을 대입하면 어떤 연산을 처리하여 결과값을 리턴하는 것이다.
이와 마찬가지로 데이터의 컬럼에 있는 상수값을 입력으로 받아 '위치값'을 리턴하는 것을 해쉬함수라고 이해하면된다.
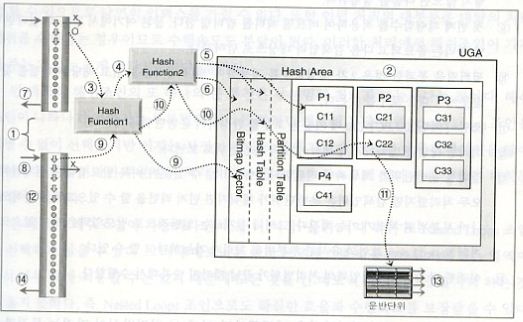
해쉬영역(Hash Area)
해쉬 영역이란 해쉬 조인을 수행하기 위해 메모리 내에 만들어진 영역을 말한다. 이 영역은 비트맵 벡터와 해쉬 테이블, 그리고 파티션 테이블 영역으로 구성되어 있다.
해쉬 테이블에는 파티션들의 위치정보를 가지고 있으며 조인의 연결 작업을 수행할 때나 디스크에 내려가 있는 파티션 짝들을 찾는데 사용된다.
파티션 테이블에는 여러 개의 파티션이 존재하며, 조인할 집합의 실제 로우들을 가지고 있는 영역이다.
해쉬영역이 부족하면 디스크를 사용할 수 밖에 없어 수행속도에 지대한 영향을 미치게 되므로 해쉬영역크기를 적절하게 지정하는 것은 매우 중요하다.
파티션(Partition)
파티션이란 파티션을 결정하기 위해 수행하는 첫 번째 해쉬함수가 리턴한 동일한 해쉬값을 갖는 묶음을 말한다.
즉, 동일한 해쉬값을 가진 로우들의 버켓을 말한다. 특히 빌드입력이 인_메모리에 작업이 불가능하면 반드시 파티션으로 나뉘어져야 한다.
이렇게 만들어진 파티션 수를 팬아웃이라고 부른다.
하나의 파티션은 여러 개의 클러스트로 분리된다, 2차 해슁을 하면 저장할 클러스터의 위치가 결정되며, 이 단위는 I/O의 단위가 될 뿐만 아니라 검색의 단위로도 활용된다.
파티션 수를 많게 하면 - 즉, 팬아웃을 크게하면 적는 크기의 많은 파티션이 생성되기 때문에 비효율적인 I/O가 발생할 수 있다.
반대로 너무 적게하면, 지나치게 큰 파티션이 생성되어 해쉬영역과 맞지 않을 수도 있으므로 이에 대한 결정은 해쉬 조인의 효율에 큰영향을 미친다.
클러스터(Cluster)
파티션은 작지 않은 크기로 되어 있기 때문에 이를 다시 클러스터 단위로 분할한다.
이 클러스터는 연속된 블록으로 되어 있으며 디스크와 I/O를 하는 단위가 된다.
물론 주어진 파라메터에 의해 동시에 I/O 하는 양이 결정된다.
특히 해쉬 ㅋ클러스터링을 했을 때와 매우 유사한 형태로 이해하는 것이 좋다.
해쉬 클러스터링을 했을 ?는 해쉬함수에서 생성된 값이 같으면 동일한 클러스터에 저장되고, 이를 검색할 때는 해쉬값으로 해당 클러스터를 찾아 클러스터를 스캔하면서 원하는 로우를 찾는다.
캐비닛을 파티션이라고 한다면 슬롯은 서랍이라고 생각하면 이해가 빠를 것이다.
우리가 물건을 찾을 때도 먼저 캐비닛을 결정한 다음 해당 서랍을 열어서 물건을 꺼내는 것과 매우 유사하다고 하겠다.
빌드입력(Build Input)과 검색입력(Probe Input)
조인을 위해 먼저 액세스하여 필요한 준비를 해두는 처리를 빌드입력이라 하며, 나중에 액세스하면서 조인을 수행하는 처리를 검증 혹은 검색입력이라고 한다.
인_메모리(In-memory)해쉬조인과 유예 해쉬조인
해쉬 조인에는 전체 빌드입력이 해쉬영역보다 적은 경우와 그렇지 않은 경우에 따라 처리 방식에 큰 차이가 있다.
그러므로 무조건 적은 집합을 가진 것이 빌드입력이 되도록 해야 함은 당연하다.
빌드입력이 해쉬영역에 모두 위치할 수 있는 경우는 인_메모리 해쉬조인을 수행하게 되고, 그렇지 못한 경우에는 유예 해쉬조인을 수행하게 된다.
유예 해쉬 조인은 먼저 전체를 빌드입력과 검색입력을 수행하여 여러 개의 파티션에 분할하고, 해쉬영역을 초과할 때마다 임시 세그먼트에 파티션을 저장한다.
비트맵 벡터(Bitmap Vector)
빌드입력에 대해서 파티션을 구하는 작업 중에 생성되며, 빌드입력값들에 대한 유일 값을 메모리 내의 해쉬영역에 정의하는 것을 말한다.
해쉬영역에 만들어지는 비트맵 벡터는 빌드입력의 전체 집합에 대해서 생성된다.
즉, 처리대상이 커서 해쉬영역을 초과하여 임시 세그먼트에 저장하게 되더라도 처리할 빌드 입력의 모든 집합에 대해 조인종료 시 까지 유지된다.
검색입력에 액세스한 것이 어차피 빌드입력에 존재하지 않는다면 굳이 파티션에 위치시킬 필요조차 없기 때문에 이를 필터링 하는 중요한 역할을 하게 된다.
이 작업은 파티션을 결정하기 위해 해쉬함수를 적용하기 전에 수행하여 불필요한 대상들을 걸러내므로 실제 조인에 참여할 대상을 경우에 따라 크게 감소시킬 수 있다,
일반적으로 이 영역은 메모리에 정의하는 해쉬영역의 5%로 생성된다.
해쉬 테이블(Hash Table)
최종적으로 조인의 연결작업에 대응되는 로우를 찾기 위한 해쉬 인덱스로 사용된다.
마치 Nested Loops 조인에서 나중에 대응되는 로우를 인덱스에서 찾는 것과 유사하지만
물리적인 인덱스가 미리 생성되는 것이 아니라 조인을 수행할 때 임시적으로 생성된다는 것이 다른 점이다.
물론 그 인덱스 구조는 해슁을 활용하는 방법이다.
일반 인덱스에서 인덱스 컬럼값과 ROWID를 가지고 있는 것과 유사하게 해쉬 테이블은 해쉬키값과 해쉬 클러스터의 주소를 가지고 있다.
일반적인 인덱스는 테이블의 로우만큼의인덱스 로우를 가지고 있지만 해쉬 테이블에는 실제 테이블의 로우 별로 인덱스를 가지고 있지는 않는다.
이는 마치 해쉬 클러스터링 테이블에서 해쉬 클러스터로 액세스 하는 것과 유사한 개념이다.
일반적인 인덱스 연결은 최악의 경우 하나의 연결을 위해 한 블록이 액세스 될 수 있다.
그러나 해쉬 조인의 연결에서는 파티션 짝(Pair)들간에는 연결에 필요한 데이터가 100%존재하는 것이 보장되기
때문에 메모리 내에 해쉬를 적용하여 수행하는 연결은 일반적인 랜덤과 비교할 수 없이 빠르다.
파티션 테이블(Partition Table)
만약 빌드입력이 메모리 크기를 초과하여 파티션을 생성하게 되면 '파티션 테이블'에 관련정보가 저장된다.
또한 디스크의 임시 세그먼트로 이동하면 그 위치정보를 갖는다. 이 위치 정보는 나중에 다시 메모리로 올려서 처리할 대상을 선정할 때 활용된다.
또한 빌드입력과 검색입력에서 생성된 파티션 간에 서로 짝을 찾는데도 활용된다.
처리되는 단위마다 동적으로 역할이 변할 수 있으며, 이것을 일컬어 동적 역할 반전이라고 부른다.
이러한 개념을 적용하는 이유는 인_메모리 해쉬 조인의 가능성을 높이기 위한 전략 때문이다.
해쉬 테이블은 해당 처리 단위의 연결작업을 위한 인덱스 개념으로 사용되지만 다른 구 가지는 전체 작업에 필요한 정보를 가지고 있기 때문이다.
이들의 합이 전체 해쉬영역의 15%~20% 넘으면 오버헤드가 발생하므로 이런 경우에는 해쉬영역을 증가시키는 것이 바람직하다.
통계정보에 있는 히스토그램을 이용하여 파티션의 크기나 파티션 내의 데이터 분포를 동적으로 관리하여,
이 결과를 다음 번 수행 시에 활용하여 파티션의 크기를 결정하기도 한다. 물론 이러한 기능은 DBMS나 버전에 따라 차이가 있다.
인_메모리 해쉬조인
빌드입력을 모두 메모리에 저장하고 해쉬 테이블을 만들어 검색입력을 스캔하면서 조인을 수행한다.
비록 모양상으로 랜덤이지만 거의 부담이 없는 랜덤을 수행하기 때문에 Sort Merge 조인처럼 연결을 위해서 정렬을 해야 하거나 Nested Loops 조인처럼 수많은 블록을 액세스하지 않아도 되므로 대용량 데이터의 조인에 매우 효과적이다.
또한, Nested Loops 조인만 가질 수 있는 부분범위 처리도 가능하게 되므로 만약 어느 한쪽의 처리범위가 크지 않는 경우라면 매우 효율적인 조인방법이다.
1) 통계정보를 참조하여 보다 효과적인 카디널러티를 갖는 집합을 빌드입력으로 선택한다.
일반적으로 조인은 1:1이나 1:M 관계에서 발생하므로 대부분의 경우 '1' 족 집합이 빌드입력이된다.
2) 팬아웃, 즉 파티션 수를 결정한다. 파ㅣ션의 수와 크기는 성능에 큰 영향을 미치게 되므로 히스토그램 정보를 입각하여
이를 동적으로 최적화하여 결정하게 된다.
3) 빌드입력의 조인키에 1차 해슁함수를 적용하여 저장할 파티션을 결정한다.
4) 2차 해슁함수를 적용하여 해쉬값을 생성한다.
5) 이 값을 이용하여 해쉬 테이블을 만들고, 해당파티션의 슬롯에 저장한다.
이때 저장되는 컬럼은 SQL의 SELECT-List 에 있는 컬럼들도 같이 저장된다.
6) 검색입력의 필터링을 위해 사용할 비트맨 백터를 생성한다. 이 값은 유일한 값으로 만들어지므로
처리할 값을 찾아본 후 없으면 생성하고 있으면 그대로 통과하는 방식으로 생성된다.
7) 이러한 방식으로 빌드입력의 처리범위를 모두 처리할 때까지 반복해서 수행한다.
8) 이번에는 검색입력의 처리범위를 액세스하기 시작하여 조건을 만족하지 않으면 버리고 그렇지 않으면 다음을 실행한다.
9) 첫 번째 해슁함수를 적용하여 비트맨 백터를 필터링 한다. 물론 여기에서 찾을 수 없다면
해당 처리는 종료되고 다음 검색입력 대상으로 넘어간다.
10) 필터링을 통과한 것은 2차 해슁함수를 적용하여 해쉬 테이블을 읽고 해당 파티션을 찾아 슬롯에서 대응 로우를 찾는다.
11) 조인이 되면 SELECT-List 에 기술된 로우를 완성하여 운반단위에 태운다.
12) 이러한 작업을 반복해서 수행하여 계속 운반단위로 보낸다.
13) 정해진 운반단위가 채워지면 리턴한다. 빌드입력은 전체범위를 모두 처리했지만
검색입력은 운반단위가 채워지면 먼저 리턴을 할 수 있으므로 부분적으로 나마 부분범위 처리가 가능해진다.
그러나 실제로는 일반적으로 빌드입력은 크지 않으므로 거의 Nested Loops 조인과 유사한 부분범위 처리가 가능하다고 할 수 있다.
14) 이러한 방식으로 검색입력의 처리범위가 끝날 때까지 반복해서 수행한다.
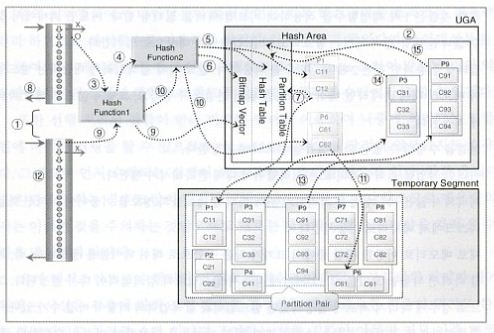
유예 해쉬조인
빌드입력이 해쉬영역을 초과하면 해쉬조인은 좀더 복잡한 과정을 거치게 된다. 그 이유는 빌드입력이 해쉬영역을 초과하게 되면 어쩔 수 없이 디스크에 저장을 할 수 밖에 없기 때문이다.
빌드입력의 일부라도 디스크에 저장을 할 수 밖에 없게 된다면 마치 정렬을 통해 연결을 하는 Sort Merge 조인처럼 무엇인가 정렬을 유사한 효과를 얻을 수 있는 방법이 있어야 한다.
정렬을 하지 않고서도 연결이 가능하도록 데이터를 위치시키는 방법은 따로 해슁함수를 적용하는 것이다.
Sort Merge 조인은 각각의 집합을 먼저 정렬을 한 후 그것은 머지하는 방식으로 연결을 수행하고, 해쉬조인은 각각의 집합에 대해서 먼저 해슁함수를 적용하여 같은 해쉬값을 갖는 파티션에 저장을 한 후 그들을 짝을 찾아 연결을 수행한다.
1) 통계정보를 참조하여 보다 효과적인 카디널러티를 갖는 집합을 빌드입력으로 선택한다.
2) 파티션 수를 결정한다.
3) 빌드입력의 조인키에 대하여 1차 해슁함수를 적용하여 저장할 파티션을 결정한다.
4) 2차 해슁함수를 적용하여 해쉬값을 생성한다.
5) 이 값을 이용하여 해쉬 테이블을 만들고, 해당 파티션의 슬롯에 저장한다.
이때 저장되는 컬럼은 SQL 의 SELECT-List 에 있는 컬럼들도 같이 저장된다.
6) 검색입력의 필터링을 위해 사용할 비트맵 백터를 생성한다. 여기서 생성된 값을 이용해 다음에 수행될 검색입력의 필터링을 하게 되므로 유예 해쉬조인에서도 크기가 작은 집합이
빌드입력이 대상을 크게 줄이는 효과를 볼수있다. 여기까지는 인_메모리 해쉬조인과 동일하다.
7) 이러한 방식으로 빌드입력의 처리범위를 처리하다가 해쉬영역을 초과하면 파티션 테이블에 위치정보를 남기고 디스크로 이동하게 된다. 파티션 테이블에 있는 정보는 나중에 파티션 짝을 찾아 연결작업을 수행할 때 사용된다.
8) 빌드입력의 모든 처리범위를 위의 방법으로 끝까지 수행한다.
9) 이번에는 검색입력의 처리범위를 액세스하기 시작하여 조건을 만족하지 않으면 버리고, 만족한 것들은 1차 해슁함수를 저?하여 비트맵 백터를 필터링 한다
비트맵 백터에서 찾을수 없다면 해당 건의 처리는 종료되고 다음 검색입력 대상으로 넘어간다.
10) 필터링을 통과한 것은 2차 해슁함수를 적용한다. 만약 이때 검색입력에 대응되는 빌드입력이 메모리 내에 존재하면 해쉬 테이블을 읽어 연결을 수행하고, 그렇지 않으면 해당 파티션에 저장한다.
11) 연결을 수행할 수 없는 파티션들을 디스크에 저장한다.
12) 이러한 작업을 검색입력의 모든 처리범위에 대해 반복해서 수행한다.
13) 처리되지 않은 파티션들을 처리하기 위해 파티션 테이블의 정보를 이용하여 파티션 짝들을 디스크에서 메모리로 이동시킨다.
14) 새로 메모리로 이동한 집합 중에서 크기가 작은 집합으로 해쉬 테이블을 생성한다.
즉, 처리할 파티션 짝들을 모았을 때, 그 크기에 따라서 빌드입력과 검색입력이 다시 결정된다.
그러므로 경우에 따라서 최초에 결정되었던 빌드입력과 검색입력의 역할이 바뀔 수가 있다.
15) 검색입력으로 결정된 집합을 스캔하면서 해쉬 테이블을 이용하여 연결을 수행한다.
물론 운반단위에 모았다가 채워지면 리턴하는 것은 당연하다. 이러한 작업을 남아 있는 모든 대상에 대해서 실시한다.
유예 해쉬조인의 특징과 적용기준
조인의 연결을 위해서는 기존에 미리 생성되어 있는 인덱스를 전혀 사용하지 않음
(조인 연결고리에 인덱스가 없어도 영향을 받지 않는다는 것과 그러면서도 오히려 기존의 B-Tree 인덱스 보다 더 유리한 해쉬를 이용한 조인을 할수 있기 때문이다. 이러한 집합의 연산과정은 이미 가공된 집합일 수 있기 때문에 인덱스가 존재하지 않을 수도 있음은 물론이고, 대개의 경우 대용량의 처리이기 때문에 데이터 량의 증가에 따른 부담이 최소화 될 필요가있다.)
부분범위 처리가 불가능하다.(해쉬조인은 비록 해쉬영역을 초과하는 대용량의 데이터라 하더라도 해쉬함수를 이용하여 적절한 위치에 옮겨 두었다가 조인대상들을 다시 불러 들여 해쉬 테이블을 통해 조인을 수행하므로 Sort Merge 조인이 갖는 최대의 약점인 대용량 데이터의 정렬에 대한 오버헤드를 해결하는 최적의 수단이다. 사실 이 경우 따라 조인 방식을 결정하는 매우 중요한 기준이 된다.)