press x to close
 |
11:45:32 SQL> SELECT * FROM V$VERSION WHERE ROWNUM <= 1;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bi
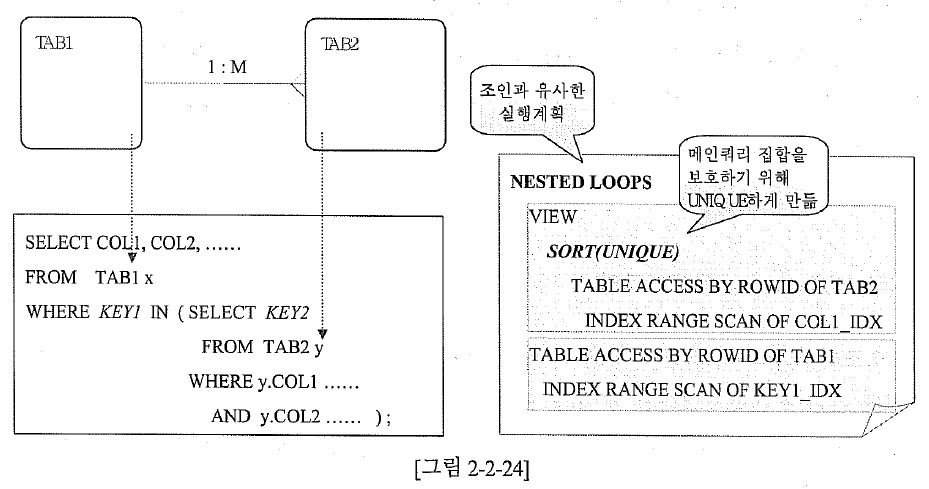
DROP TABLE TAB1 PURGE;
DROP TABLE TAB2 PURGE;
CREATE TABLE TAB1 AS
SELECT LEVEL KEY1
, '상품'||LEVEL COL1
, TRUNC( dbms_random.value( 1,7 ) ) * 500 + TRUNC( dbms_random.value( 1,3 ) ) * 750 COL2
FROM DUAL
CONNECT BY LEVEL <= 10000;
CREATE TABLE TAB2 AS
SELECT LEVEL KEY1
, TRUNC(dbms_random.value( 1, 10000 ) ) KEY2
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 1000 ) COL1
, 'A' COL2
FROM DUAL
CONNECT BY LEVEL <= 100000;
CREATE INDEX KEY1_IDX ON TAB1( KEY1 );
CREATE INDEX COL1_IDX01 ON TAB2( COL1, COL2 );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB1' );
EXEC DBMS_STATS.GATHER_TABLE_STATS( USER, 'TAB2' );
SQL> DESC TAB2;
이름 널? 유형
----------------------------------------------------------------------------------------------------------------- -------- -
KEY1 NUMBER
KEY2 NUMBER
COL1 DATE
COL2 CHAR(1)
SQL> SELECT /*+ gather_plan_statistics */ COUNT( DISTINCT KEY2 )
2 FROM TAB2 A
3 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
4 AND COL2 = 'A';
COUNT(DISTINCTKEY2)
-------------------
1810
경 과: 00:00:00.02
SQL> @xplan
---------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT GROUP BY | | 1 | 1 | 1 |00:00:00.01 | 15 | 83968 | 83968 |73728 (0)|
|* 2 | FILTER | | 1 | | 2000 |00:00:00.01 | 15 | | | |
| 3 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 4 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
---------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
4 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT KEY2
4 FROM TAB2 B
5 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND COL2 = 'A' ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.02
SQL> @xplan
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 41 | | | |
|* 2 | FILTER | | 1 | | 1810 |00:00:00.01 | 41 | | | |
|* 3 | HASH JOIN RIGHT SEMI | | 1 | 1830 | 1810 |00:00:00.01 | 41 | 1517K| 1517K| 1277K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 5 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 |00:00:00.01 | 26 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ HASH_SJ */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.01
SQL> @XPLAN
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 40 | | | |
|* 2 | FILTER | | 1 | | 1810 |00:00:00.01 | 40 | | | |
|* 3 | HASH JOIN RIGHT SEMI | | 1 | 1830 | 1810 |00:00:00.01 | 40 | 1517K| 1517K| 1274K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 5 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 |00:00:00.01 | 25 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ UNNEST */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.01
SQL> @XPLAN
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 41 | | | |
|* 2 | FILTER | | 1 | | 1810 |00:00:00.01 | 41 | | | |
|* 3 | HASH JOIN RIGHT SEMI | | 1 | 1830 | 1810 |00:00:00.01 | 41 | 1517K| 1517K| 1552K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 5 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
| 6 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 |00:00:00.01 | 26 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
5 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
SQL> SELECT /*+ gather_plan_statistics UNNEST( @SUB ) */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB )*/ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.01
SQL> @XPLAN
-- KEY1_IDX 인덱스가 유니크인덱스가 아니라서 패스트 풀스켄으로 옵티마이져 선택해서 해쉬로 풀리는 듯.
-----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 41 | | | |
|* 2 | FILTER | | 1 | | 1810 |00:00:00.01 | 41 | | | |
|* 3 | HASH JOIN | | 1 | 2000 | 1810 |00:00:00.01 | 41 | 1517K| 1517K| 1292K (0)|
| 4 | SORT UNIQUE | | 1 | 2000 | 1810 |00:00:00.01 | 15 | 83968 | 83968 |73728 (0)|
| 5 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 6 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
| 7 | INDEX FAST FULL SCAN | KEY1_IDX | 1 | 10000 | 10000 |00:00:00.01 | 26 | | | |
-----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
3 - access("KEY1"="KEY2")
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
DROP INDEX KEY1_IDX
CREATE UNIQUE INDEX KEY1_IDX ON TAB1( KEY1 )
SQL> SELECT /*+ gather_plan_statistics UNNEST( @SUB )*/ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB ) */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.01
SQL> @XPLAN
-----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 1827 | | | |
|* 2 | FILTER | | 1 | | 1810 |00:00:00.01 | 1827 | | | |
| 3 | NESTED LOOPS | | 1 | 2000 | 1810 |00:00:00.01 | 1827 | | | |
| 4 | SORT UNIQUE | | 1 | 2000 | 1810 |00:00:00.01 | 15 | 83968 | 83968 |73728 (0)|
| 5 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 6 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
|* 7 | INDEX UNIQUE SCAN | KEY1_IDX | 1810 | 1 | 1810 |00:00:00.01 | 1812 | | | |
-----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
7 - access("KEY1"="KEY2")
SQL> SELECT /*+ gather_plan_statistics LEADING( B A ) USE_NL( A B ) */ COUNT(*)
2 FROM TAB1 A
3 , (SELECT DISTINCT KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A' ) B
7 WHERE A.KEY1 = B.KEY2;
COUNT(*)
----------
1810
경 과: 00:00:00.01
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 1827 |
| 2 | NESTED LOOPS | | 1 | 1829 | 1810 |00:00:00.01 | 1827 |
| 3 | VIEW | | 1 | 1829 | 1810 |00:00:00.01 | 15 |
| 4 | HASH UNIQUE | | 1 | 1829 | 1810 |00:00:00.01 | 15 |
|* 5 | FILTER | | 1 | | 2000 |00:00:00.01 | 15 |
| 6 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 |
|* 7 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 |
|* 8 | INDEX UNIQUE SCAN | KEY1_IDX | 1810 | 1 | 1810 |00:00:00.01 | 1812 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
7 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND "B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
8 - access("A"."KEY1"="B"."KEY2")
SQL> SELECT /*+ gather_plan_statistics */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
4 FROM TAB2 B
5 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND B.COL2 = 'A'
7 ) ;
COUNT(*)
----------
1801
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:12.22 | 138K|
|* 2 | FILTER | | 1 | | 1801 |00:00:13.86 | 138K|
| 3 | TABLE ACCESS FULL | TAB1 | 1 | 10000 | 10000 |00:00:00.01 | 33 |
|* 4 | FILTER | | 10000 | | 1801 |00:00:12.21 | 138K|
|* 5 | TABLE ACCESS BY INDEX ROWID| TAB2 | 10000 | 1 | 1801 |00:00:12.18 | 138K|
|* 6 | INDEX SKIP SCAN | COL1_IDX01 | 10000 | 46 | 18M|00:00:00.09 | 74061 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter( IS NOT NULL)
4 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
5 - filter("KEY2"=:B1)
6 - access("B"."COL1">=TRUNC(SYSDATE@!-1) AND "B"."COL2"='A' AND
"B"."COL1"<=TRUNC(SYSDATE@!))
filter("B"."COL2"='A')
바로 위 쿼리 플렌 보충 쿼리 1
SQL> SELECT /*+ gather_plan_statistics */ KEY1
2 FROM TAB1 A
3 WHERE KEY1 = 1
4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
5 FROM TAB2 B
6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
7 AND B.COL2 = 'A'
8 ) ;
KEY1
----------
1
SQL> @XPLAN
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
|* 1 | INDEX UNIQUE SCAN | KEY1_IDX | 1 | 1 | 1 |00:00:00.01 | 15 |
|* 2 | FILTER | | 1 | | 1 |00:00:00.01 | 13 |
|* 3 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 1 | 1 |00:00:00.01 | 13 |
|* 4 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 46 | 1685 |00:00:00.01 | 7 |
------------------------------------------------------------------------------------------------------
--바로 위 쿼리 플렌 보충 쿼리 2
SQL> SELECT /*+ gather_plan_statistics */ KEY1
2 FROM TAB1 A
3 WHERE KEY1 = 2
4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
5 FROM TAB2 B
6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
7 AND B.COL2 = 'A'
8 ) ;
KEY1
----------
2
SQL> @XPLAN
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
|* 1 | INDEX UNIQUE SCAN | KEY1_IDX | 1 | 1 | 1 |00:00:00.01 | 15 |
|* 2 | FILTER | | 1 | | 1 |00:00:00.01 | 13 |
|* 3 | TABLE ACCESS BY INDEX ROWID| TAB2 | 1 | 1 | 1 |00:00:00.01 | 13 |
|* 4 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 46 | 1745 |00:00:00.01 | 7 |
------------------------------------------------------------------------------------------------------
--바로 위 쿼리 플렌 보충 쿼리 3
SQL> SELECT /*+ gather_plan_statistics */ KEY1
2 FROM TAB1 A
3 WHERE KEY1 IN ( 1, 2 )
4 AND KEY1 IN ( SELECT /*+ NO_UNNEST */ KEY2
5 FROM TAB2 B
6 WHERE B.COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
7 AND B.COL2 = 'A'
8 ) ;
KEY1
----------
1
2
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------
| 1 | INLIST ITERATOR | | 1 | | 2 |00:00:00.01 | 31 |
|* 2 | INDEX RANGE SCAN | KEY1_IDX | 2 | 1 | 2 |00:00:00.01 | 31 |
|* 3 | FILTER | | 2 | | 2 |00:00:00.01 | 26 |
|* 4 | TABLE ACCESS BY INDEX ROWID| TAB2 | 2 | 1 | 2 |00:00:00.01 | 26 |
|* 5 | INDEX SKIP SCAN | COL1_IDX01 | 2 | 46 | 3430 |00:00:00.01 | 14 |
-------------------------------------------------------------------------------------------------------
SQL> SELECT /*+ gather_plan_statistics SEMIJOIN_DRIVER(@SUB) */ COUNT( * )
2 FROM TAB1 A
3 WHERE KEY1 IN ( SELECT /*+ QB_NAME( SUB )* */ KEY2
4 FROM TAB2 B
5 WHERE COL1 BETWEEN TRUNC( SYSDATE - 1 ) AND TRUNC( SYSDATE )
6 AND COL2 = 'A' ) ;
COUNT(*)
----------
1810
경 과: 00:00:00.02
SQL> @xplan
-------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-------------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.02 | 2020 | | | |
| 2 | BITMAP CONVERSION COUNT | | 1 | 2000 | 1 |00:00:00.02 | 2020 | | | |
| 3 | BITMAP MERGE | | 1 | | 1 |00:00:00.02 | 2020 | 1024K| 512K| 416K (0)|
| 4 | BITMAP KEY ITERATION | | 1 | | 2000 |00:00:00.02 | 2020 | | | |
|* 5 | FILTER | | 1 | | 2000 |00:00:00.01 | 15 | | | |
| 6 | TABLE ACCESS BY INDEX ROWID | TAB2 | 1 | 2000 | 2000 |00:00:00.01 | 15 | | | |
|* 7 | INDEX SKIP SCAN | COL1_IDX01 | 1 | 40 | 2000 |00:00:00.01 | 8 | | | |
| 8 | BITMAP CONVERSION FROM ROWIDS| | 2000 | | 2000 |00:00:00.01 | 2005 | | | |
|* 9 | INDEX RANGE SCAN | KEY1_IDX | 2000 | | 2000 |00:00:00.01 | 2005 | | | |
-------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(TRUNC(SYSDATE@!-1)<=TRUNC(SYSDATE@!))
7 - access("COL1">=TRUNC(SYSDATE@!-1) AND "COL2"='A' AND "COL1"<=TRUNC(SYSDATE@!))
filter("COL2"='A')
9 - access("KEY1"="KEY2")
 |
DROP TABLE 사원 PURGE;
DROP TABLE 가족 PURGE;
CREATE TABLE 사원 AS
SELECT LEVEL AS 사번
, '아무개'||LEVEL AS 성명
, TRUNC( dbms_random.value( 1,7 ) ) 직급
, TRUNC( SYSDATE ) - 100 + CEIL( LEVEL/ 10000 ) 입사일
, DECODE( TRUNC( dbms_random.value( 1,32 ) ), 1, 'DB1팀', 2, 'DB2팀', 3, 'DB3팀'
, 4, '시스템1팀', 5, '시스템2팀', 6, '시스템3팀'
, 7, '경리1과', 8, '경리2과', 9, '경리3과', 10, '경리과', 11, '경리4과'
, 12, '개발1팀', 13, '개발2팀', 14, '개발3팀', 15, '개발4팀', 16, '개발5팀', 17, '개발6팀'
, 18, 'MD1팀', 19, 'MD2팀', 20, 'MD3팀', 21, 'MD4팀'
, 22, '디자인1팀', 23, '디자인2팀', 24, '디자인3팀', 25, '디자인4팀'
, 26, '멀티미디어1팀', 27, '멀티미디어2팀', 28, '멀티미디어3팀'
, 29, '모바일1팀'
, 30, '웹모바일팀'
, 31, '마케팅팀'
, 32, '기획팀' ) 부서
FROM DUAL
CONNECT BY LEVEL <= 1000000
CREATE TABLE 가족 AS
SELECT 사번, LV 가족번호, '아무개'||LV 성명
, '19'|| TRUNC( dbms_random.value( 50,110 ) )|| TO_CHAR( TRUNC( dbms_random.value( 1,12 ) ), 'FM09' )|| TO_CHAR( TRUNC( dbms_random.value( 1,28 ) ), 'FM09' ) 생년월일
FROM 사원 A
, (SELECT LEVEL LV FROM DUAL CONNECT BY LEVEL <= 10 ) B
WHERE A.직급 >= B.LV
CREATE INDEX 부서_INDEX ON 사원 ( 부서, 사번 )
CREATE UNIQUE INDEX PK_INDEX ON 가족 ( 사번, 가족번호 )
SQL> SELECT 부서, COUNT(*)
2 FROM 사원
3 GROUP BY 부서
4 ;
부서 COUNT(*)
------------- ----------
멀티미디어1팀 31437
시스템2팀 31200
개발4팀 31232
시스템3팀 31172
DB3팀 30931
MD3팀 30972
경리1과 31134
개발1팀 31243
웹모바일팀 31341
개발2팀 31302
모바일1팀 31425
부서 COUNT(*)
------------- ----------
경리3과 31263
개발3팀 31554
기획팀 31291
경리2과 31012
MD1팀 31160
DB2팀 31518
디자인2팀 31272
멀티미디어2팀 31276
경리4과 31075
개발5팀 31409
개발6팀 31425
부서 COUNT(*)
------------- ----------
DB1팀 31310
디자인1팀 31094
멀티미디어3팀 31227
시스템1팀 31249
디자인3팀 31237
마케팅팀 31364
경리과 31346
MD2팀 31126
MD4팀 31113
디자인4팀 31290
32 개의 행이 선택되었습니다.
경 과: 00:00:00.38
SQL>
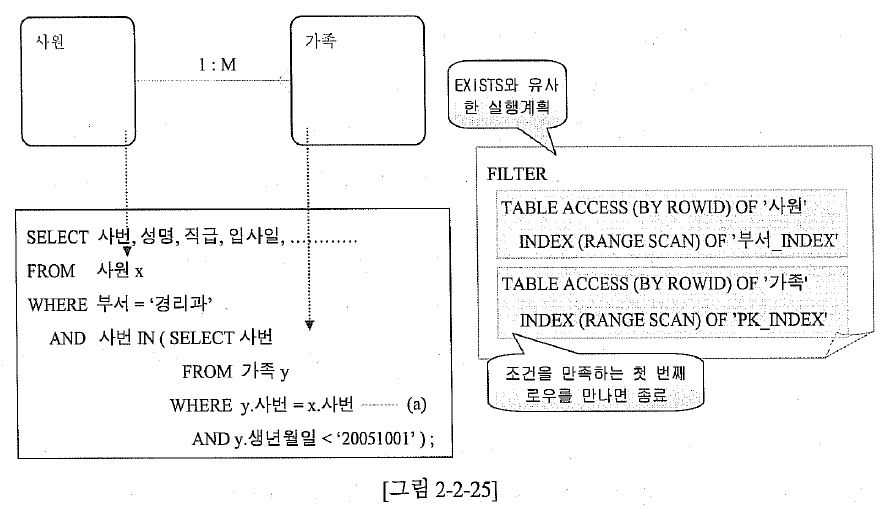
SQL> SELECT /*+ gather_plan_statistics */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
SQL> @xplan
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.69 | 14633 | 9632 | | | |
|* 2 | HASH JOIN SEMI | | 1 | 26199 | 30828 |00:00:00.40 | 14633 | 9632 | 1935K| 1935K| 2195K (0)|
|* 3 | INDEX RANGE SCAN | 부서_INDE| 1 | 26199 | 31346 |00:00:00.01 | 103 | 0 | | | |
|* 4 | TABLE ACCESS FULL| 가족 | 1 | 2901K| 3175K|00:00:00.02 | 14530 | 9632 | | | |
------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("사번"="사번")
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
SQL> SELECT /*+ gather_plan_statistics */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ INDEX( Y PK_INDEX ) */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.35 | 96727 | 17 |
| 2 | NESTED LOOPS SEMI | | 1 | 26199 | 30828 |00:00:00.34 | 96727 | 17 |
|* 3 | INDEX RANGE SCAN | 부서_INDE| 1 | 26199 | 31346 |00:00:00.01 | 103 | 0 |
|* 4 | TABLE ACCESS BY INDEX ROWID| 가족 | 31346 | 2901K| 30828 |00:00:00.31 | 96624 | 17 |
|* 5 | INDEX RANGE SCAN | PK_INDEX | 31346 | 1 | 33915 |00:00:00.15 | 62709 | 15 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
5 - access("사번"="사번")
SQL> SELECT /*+ gather_plan_statistics LEADING( @SUB ) */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ QB_NAME( SUB ) */ 사번
5 FROM 가족 Y
6 WHERE 1 = 1 --Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.61 | 14633 | | | |
|* 2 | HASH JOIN SEMI | | 1 | 26199 | 30828 |00:00:00.35 | 14633 | 1935K| 1935K| 2187K (0)|
|* 3 | INDEX RANGE SCAN | 부서_INDE| 1 | 26199 | 31346 |00:00:00.01 | 103 | | | |
|* 4 | TABLE ACCESS FULL| 가족 | 1 | 2901K| 3175K|00:00:00.01 | 14530 | | | |
---------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("사번"="사번")
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
SQL> SELECT /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ QB_NAME( SUB ) */ 사번
5 FROM 가족 Y
6 WHERE 1 = 1 --Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
SQL> @xplan
---------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp|
---------------------------------------------------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:01:38.58 | 14633 | 12586 | 4371 | | | | |
|* 2 | HASH JOIN RIGHT SEMI| | 1 | 26199 | 30828 |00:01:38.20 | 14633 | 12586 | 4371 | 84M| 7739K| 111M (1)| 39936 |
|* 3 | TABLE ACCESS FULL | 가족 | 1 | 2901K| 3175K|00:01:22.56 | 14530 | 8215 | 0 | | | | |
|* 4 | INDEX RANGE SCAN | 부서_INDE| 1 | 26199 | 31346 |00:00:00.01 | 103 | 0 | 0 | | | | |
---------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("사번"="사번")
3 - filter("Y"."생년월일"<'20051001')
4 - access("부서"='경리과')
SQL> SELECT /*+ gather_plan_statistics */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ NO_UNNEST PUSH_SUBQ */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
경 과: 00:00:00.37
SQL> @XPLAN
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.35 | 128K|
|* 2 | INDEX RANGE SCAN | 부서_INDE| 1 | 1310 | 30828 |00:00:00.34 | 128K|
|* 3 | TABLE ACCESS BY INDEX ROWID| 가족 | 31346 | 29019 | 30828 |00:00:00.30 | 127K|
|* 4 | INDEX RANGE SCAN | PK_INDEX | 31346 | 12806 | 33915 |00:00:00.14 | 94053 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("부서"='경리과')
filter( IS NOT NULL)
3 - filter("Y"."생년월일"<'20051001')
4 - access("사번"=:B1)
SQL> SELECT /*+ gather_plan_statistics */ COUNT(*)
2 FROM 사원 X
3 WHERE 부서 = '경리과'
4 AND 사번 IN (SELECT /*+ NO_UNNEST NO_PUSH_SUBQ */ 사번
5 FROM 가족 Y
6 WHERE Y.사번 = X.사번 --(a)
7 AND Y.생년월일 < '20051001' );
COUNT(*)
----------
30828
경 과: 00:00:00.37
SQL> @XPLAN
Plan hash value: 2622244588
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.36 | 128K|
|* 2 | FILTER | | 1 | | 30828 |00:00:00.37 | 128K|
|* 3 | INDEX RANGE SCAN | 부서_INDE| 1 | 26199 | 31346 |00:00:00.01 | 103 |
|* 4 | TABLE ACCESS BY INDEX ROWID| 가족 | 31346 | 29019 | 30828 |00:00:00.30 | 127K|
|* 5 | INDEX RANGE SCAN | PK_INDEX | 31346 | 12806 | 33915 |00:00:00.14 | 94053 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter( IS NOT NULL)
3 - access("부서"='경리과')
4 - filter("Y"."생년월일"<'20051001')
5 - access("사번"=:B1)
CREATE TABLE 고객 AS
SELECT LEVEL 고객번호
, LEVEL 납입자
FROM DUAL
CONNECT BY LEVEL <= 1000000; --100만건
CREATE TABLE 청구 AS
SELECT B.고객번호
, A.청구년월
, 0 입금액
FROM (SELECT '2005'||TO_CHAR( LEVEL , 'FM09' ) 청구년월
FROM DUAL
CONNECT BY LEVEL <= 12 ) A
, ( SELECT * FROM 고객 ) B --1200만건
CREATE INDEX 고객_INDEX01 ON 고객( 납입자 );
CREATE INDEX 청구_INDEX01 ON 청구( 고객번호, 청구년월 );
CREATE INDEX 청구_INDEX02 ON 청구( 청구년월, 고객번호 );
SQL> SELECT *
2 FROM 고객
3 WHERE 납입자 = 1000;
고객번호 납입자
---------- ----------
1000 1000
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
-------------------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.04 | 10 | 3 | | | |
| 2 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.02 | 7 | 2 | | | |
| 3 | SORT UNIQUE | | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | 9216 | 9216 | 8192 (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | | | |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | 0 | | | |
|* 6 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1 | 1 |00:00:00.02 | 3 | 2 | | | |
-------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NO_UNNEST */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @xplan
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:13.77 | 4003K| 3196 |
|* 2 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 67149 | 1 |00:00:13.77 | 4003K| 3196 |
|* 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:06.59 | 4000K| 0 |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:04.15 | 3000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("청구년월"='200503')
filter( IS NOT NULL)
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NO_UNNEST */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000
7 AND Y.고객번호 = X.고객번호 );
1 행이 갱신되었습니다.
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:17.11 | 4031K| 31441 |
|* 2 | FILTER | | 1 | | 1 |00:00:17.11 | 4031K| 31441 |
|* 3 | TABLE ACCESS FULL | 청구 | 1 | 575K| 1000K|00:00:01.30 | 31508 | 31441 |
|* 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:07.22 | 4000K| 0 |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:04.46 | 3000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter( IS NOT NULL)
3 - filter("청구년월"='200503')
4 - filter("고객번호"=:B1)
5 - access("납입자"=1000)
SQL> UPDATE /*+ gather_plan_statistics */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.01 | 10 | | | |
| 2 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 7 | | | |
| 3 | SORT UNIQUE | | 1 | 1 | 1 |00:00:00.01 | 4 | 9216 | 9216 | 8192 (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
|* 6 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX01 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NL_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:24.92 | 3031K| 31246 |
| 2 | NESTED LOOPS SEMI | | 1 | 1 | 1 |00:00:24.92 | 3031K| 31246 |
|* 3 | TABLE ACCESS FULL | 청구 | 1 | 1342K| 1000K|00:00:09.04 | 31508 | 31246 |
|* 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:08.62 | 3000K| 0 |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:03.62 | 2000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("청구년월"='200503')
4 - filter("고객번호"="고객번호")
5 - access("납입자"=1000)
-- 청구_INDEX02
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ NL_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL>
SQL> @XPLAN
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:09.18 | 3003K|
| 2 | NESTED LOOPS SEMI | | 1 | 1 | 1 |00:00:09.18 | 3003K|
|* 3 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1000K|00:00:00.01 | 3207 |
|* 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:08.27 | 3000K|
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:03.38 | 2000K|
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("청구년월"='200503')
4 - filter("고객번호"="고객번호")
5 - access("납입자"=1000)
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ HASH_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.26 | 3214 | | | |
|* 2 | HASH JOIN RIGHT SEMI | | 1 | 1 | 1 |00:00:00.26 | 3211 | 1035K| 1035K| 324K (0)| <--
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
|* 5 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1000K|00:00:00.01 | 3207 | | | |
---------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 ) LEADING( X) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ HASH_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp|
-------------------------------------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:05.95 | 3212 | 3503 | 3503 | | | | |
|* 2 | HASH JOIN SEMI | | 1 | 1 | 1 |00:00:05.95 | 3211 | 3503 | 3503 | 50M| 5133K| 69M (0)| 36864 | <--
|* 3 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1000K|00:00:00.01 | 3207 | 0 | 0 | | | | |
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | 0 | | | | |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | 0 | 0 | | | | |
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("고객번호"="고객번호")
3 - access("청구년월"='200503')
5 - access("납입자"=1000)
SQL> UPDATE /*+ gather_plan_statistics INDEX( X 청구_INDEX02 )*/ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ MERGE_SJ*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
Plan hash value: 2507689243
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.01 | 11 | | | |
| 2 | MERGE JOIN SEMI | | 1 | 1 | 1 |00:00:00.01 | 10 | | | |
|* 3 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1001 |00:00:00.01 | 6 | | | |
|* 4 | SORT UNIQUE | | 1001 | 1 | 1 |00:00:00.01 | 4 | 73728 | 73728 | |
| 5 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
|* 6 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("청구년월"='200503')
4 - access("고객번호"="고객번호")
filter("고객번호"="고객번호")
6 - access("납입자"=1000)
-- 1
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) INDEX( X@MAIN 청구_INDEX02 ) MERGE_SJ( @SUB ) QB_NAME( MAIN ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB )*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000 );
1 행이 갱신되었습니다.
SQL> @XPLAN
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.01 | 11 | | | |
| 2 | MERGE JOIN SEMI | | 1 | 1 | 1 |00:00:00.01 | 10 | | | |
|* 3 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1001 |00:00:00.01 | 6 | | | |
|* 4 | SORT UNIQUE | | 1001 | 1 | 1 |00:00:00.01 | 4 | 73728 | 73728 | |
| 5 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
|* 6 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("청구년월"='200503')
4 - access("고객번호"="고객번호")
filter("고객번호"="고객번호")
6 - access("납입자"=1000)
-- 2
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) INDEX( X@MAIN 청구_INDEX02 ) HASH_SJ( @SUB ) QB_NAME( MAIN ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB )*/ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000 );
1 행이 갱신되었습니다.
SQL> @XPLAN
------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:01.43 | 3212 | 5 | | | |
|* 2 | HASH JOIN RIGHT SEMI | | 1 | 1 | 1 |00:00:01.43 | 3211 | 5 | 1035K| 1035K| 310K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | | | |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | 0 | | | |
|* 5 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1342K| 1000K|00:00:00.01 | 3207 | 5 | | | |
------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics SEMIJOIN_DRIVER(@SUB ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.91 | 10 | | | |
| 2 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.90 | 7 | | | |
| 3 | SORT UNIQUE | | 1 | 1 | 1 |00:00:00.86 | 4 | 9216 | 9216 | 8192 (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.86 | 4 | | | |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
|* 6 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1 | 1 |00:00:00.04 | 3 | | | |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS(@SUB Y) QB_NAME( MAIN ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
-------------------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:00.14 | 10 | 3 | | | |
| 2 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.12 | 7 | 2 | | | |
| 3 | SORT UNIQUE | | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | 9216 | 9216 | 8192 (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | | | |
|* 5 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | 0 | | | |
|* 6 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 1 | 1 |00:00:00.12 | 3 | 2 | | | |
-------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("납입자"=1000)
6 - access("고객번호"="고객번호" AND "청구년월"='200503')
--음.. 좀더 공격적인 힌트
SQL> UPDATE /*+ gather_plan_statistics SWAP_JOIN_INPUTS( @SUB Y ) LEADING( @SUB Y ) HASH_SJ( @SUB ) INDEX( X 청구_INDEX02 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:01.24 | 36800 | | | |
|* 2 | HASH JOIN RIGHT SEMI | | 1 | 1 | 1 |00:00:01.24 | 36799 | 1035K| 1035K| 340K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1 | 1 | 1 |00:00:00.01 | 3 | | | |
|* 5 | INDEX FULL SCAN | 청구_INDEX0| 1 | 575K| 1000K|00:00:01.00 | 36795 | | | |
---------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("고객번호"="고객번호")
4 - access("납입자"=1000)
5 - access("청구년월"='200503')
filter("청구년월"='200503')
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX01 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ 고객번호
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:24.74 | 4038K| 38444 |
|* 2 | INDEX FULL SCAN | 청구_INDEX0| 1 | 28751 | 1 |00:00:24.74 | 4038K| 38444 |
|* 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:07.15 | 4000K| 0 |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:04.40 | 3000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("청구년월"='200503')
filter(("청구년월"='200503' AND IS NOT NULL))
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
DROP INDEX 청구_INDEX01
CREATE UNIQUE INDEX 청구_INDEX02 ON 청구( 고객번호, 청구년월 );
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX02 ) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
-- 아니군요 ㅠ
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:09.54 | 4036K| 47 |
|* 2 | INDEX FULL SCAN | 청구_INDEX0| 1 | 28751 | 1 |00:00:09.54 | 4036K| 47 |
|* 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:06.99 | 4000K| 0 |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:04.28 | 3000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("청구년월"='200503')
filter(("청구년월"='200503' AND IS NOT NULL))
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
CREATE INDEX 청구_INDEX03 ON 청구( 청구년월, 고객번호 );
SQL> UPDATE /*+ gather_plan_statistics LEADING( @SUB Y ) NO_UNNEST( @SUB ) INDEX( X 청구_INDEX03) */ 청구 X
2 SET 입금액 = NVL( 입금액, 0 ) + 50000
3 WHERE 청구년월 = '200503'
4 AND 고객번호 IN (SELECT /*+ QB_NAME( SUB ) */ ( 고객번호 )
5 FROM 고객 Y
6 WHERE 납입자 = 1000);
1 행이 갱신되었습니다.
SQL> @XPLAN
Plan hash value: 483576752
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------
| 1 | UPDATE | 청구 | 1 | | 0 |00:00:17.10 | 4003K| 3059 |
|* 2 | INDEX RANGE SCAN | 청구_INDEX0| 1 | 28751 | 1 |00:00:17.10 | 4003K| 3059 |
|* 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 1000K| 1 | 1 |00:00:06.98 | 4000K| 0 |
|* 4 | INDEX RANGE SCAN | 고객_INDEX0| 1000K| 1 | 1000K|00:00:04.27 | 3000K| 0 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("청구년월"='200503')
filter( IS NOT NULL)
3 - filter("고객번호"=:B1)
4 - access("납입자"=1000)
- 강좌 URL : http://www.gurubee.net/lecture/4452
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.