press x to close
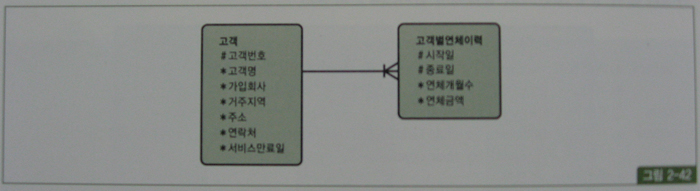 |
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일
create table 고객
as
select empno 고객번호, ename 고객명, 'C70' 가입회사
, '서울' 거주지역, '...' 주소, '123-' || empno 연락처
, to_char(to_date('20050101','yyyymmdd')+rownum*20000,'yyyymmdd') 서비스만료일
from emp
where rownum <= 10;
create index 고객_idx01 on 고객(가입회사);
create table 고객별연체이력
as
select a.고객번호, b.시작일, b.종료일, b.연체개월수, b.연체금액
from 고객 a
,(select to_char(to_date('20050101', 'yyyymmdd')+rownum*2, 'yyyymmdd') 시작일
, to_char(to_date('20050102', 'yyyymmdd')+rownum*2, 'yyyymmdd') 종료일
, round(dbms_random.value(1, 12)) 연체개월수
, round(dbms_random.value(100, 1000)) * 100 연체금액
from dual
connect by level <= 100000) b;
select min(시작일) MN_시작일, max(시작일) MX_시작일 from 고객별연체이력;
MN_시작일 MX_시작일
---------------- ----------------
20050103 25520801
create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 종료일, 시작일);
-- Oracle Release 10g
SQL> select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
2 from 고객 a, 고객별연체이력 b
3 where a.가입회사 = 'C70'
4 and b.고객번호 = a.고객번호
5 and '20050131' between b.시작일 and b.종료일;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.41 0.40 4619 4636 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.42 0.40 4619 4636 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=4636 pr=4619 pw=0 time=273 us)
21 NESTED LOOPS (cr=4634 pr=4619 pw=0 time=4334 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=223 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=116 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=4630 pr=4619 pw=0 time=706 us)(object id 117505)
SQL> drop index 고객별연체이력_idx01;
인덱스가 삭제되었습니다.
SQL> create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 시작일, 종료일);
인덱스가 생성되었습니다.
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 30 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 30 0 10
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=30 pr=0 pw=0 time=172 us)
21 NESTED LOOPS (cr=28 pr=0 pw=0 time=1836 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=242 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=173 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=24 pr=0 pw=0 time=259 us)(object id 117506)
select /*+ ordered use_hash(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where b.고객번호 = a.고객번호
and '20050131' between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 2 32 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.00 2 32 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=32 pr=2 pw=0 time=2657 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=91 us)
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=29 pr=2 pw=0 time=166 us)
10 INDEX SKIP SCAN 고객별연체이력_IDX01 (cr=27 pr=2 pw=0 time=662 us)(object id 117506)
select /*+ ordered use_nl(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and a.서비스만료일 between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.16 0.15 0 2571 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.16 0.15 0 2571 0 10
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=2571 pr=0 pw=0 time=3026 us)
21 NESTED LOOPS (cr=2561 pr=0 pw=0 time=58935 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=145 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=75 us)(object id 117502)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=2557 pr=0 pw=0 time=152588 us)(object id 117506)
SQL> select min(서비스만료일) 최소만료일, max(서비스만료일) 최대만료일 from 고객;
최소만료일 최대만료일
---------------- ----------------
20591005 25520801
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 1 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 1 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=40 pr=1 pw=0 time=722 us)
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=40 pr=1 pw=0 time=636 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=1 pw=0 time=548 us)(object id 117506)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=46 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=208 us)(object id 117502)
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.00 0 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=247 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=171 us)(object id 117506)
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=115 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=190 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=126 us)(object id 117502)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=375 us)
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=247 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=171 us)(object id 117506)
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 A, 고객별연체이력 B
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index_desc(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and a.서비스만료일 between 시작일 and 종료일
and rownum <= 1)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 44 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 44 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=115 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=199 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=126 us)(object id 117502)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=376 us)
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=245 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=169 us)(object id 117506)
select /*+ ordered use_hash(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where b.고객번호 = a.고객번호
and a.서비스만료일 between b.시작일 and b.종료일
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 1.06 1.03 4702 4725 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 1.06 1.03 4702 4725 0 10
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=4725 pr=4702 pw=0 time=115957 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=117 us)
1000000 TABLE ACCESS FULL 고객별연체이력 (cr=4722 pr=4702 pw=0 time=1000046 us)
 |
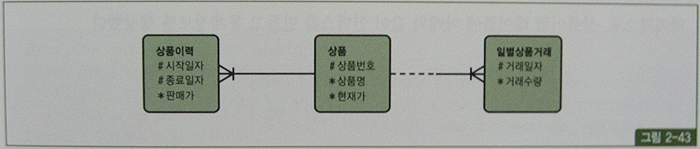 |
SQL> create table 일별상품거래
2 as
3 select 'A' || lpad(b.no, 4, '0') 상품번호, a.거래일자, round(dbms_random.value(1, 100)) 거래수
량
4 from (select to_char(sysdate - rownum, 'yyyymmdd') 거래일자
5 from dual
6 connect by level <= 3653) a
7 ,(select rownum no from dual connect by level <= 100) b
8 ;
테이블이 생성되었습니다.
SQL> create table 상품이력
2 as
3 select 상품번호
4 ,(case when 거래일자 = min(거래일자) over (partition by 상품번호) then 최소일자 else 거래
일자 end) 시작일자
5 ,(case when 거래일자 = max(거래일자) over (partition by 상품번호) then '99991231' else to_
char(to_date(거래일자, 'yyyymmdd') + 3, 'yyyymmdd') end) 종료일자
6 , round(dbms_random.value(100, 10000), -2) 판매가
7 from (
8 select 상품번호, 거래일자, mod(rownum, 4) no
9 from (
10 select 상품번호, 거래일자
11 from 일별상품거래
12 order by 상품번호, 거래일자
13 )
14 ), (select min(거래일자) 최소일자 from 일별상품거래)
15 where no = 1
16 ;
테이블이 생성되었습니다.
SQL> select count(distinct 상품번호) 상품수, count(*)
2 from 일별상품거래;
상품수 COUNT(*)
---------- ----------
100 365300
-- 상품번호별 거래 데이터가 평균 3,653건
SQL> select avg(cnt)
2 from (select 상품번호, count(*) cnt
3 from 일별상품거래
4 group by 상품번호);
AVG(CNT)
----------
3653
-- 상품이력 테이블에는 상품별로 평균 913건의 이력이 존재
-- 평균적으로 4일에 한 번(=3,653/913)씩 이력 데이터가 생성된 셈
SQL> select avg(cnt)
2 from (
3 select 상품번호, count(*) cnt
4 from 상품이력
5 group by 상품번호
6 )
7 ;
AVG(CNT)
----------
913.25
-- 상품이력 테이블에 인덱스를 만들고 통계정보 생성
SQL> create index 상품이력_idx on 상품이력(상품번호, 시작일자, 종료일자);
인덱스가 생성되었습니다.
SQL> exec dbms_stats.gather_table_stats(user, '일별상품거래');
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL> exec dbms_stats.gather_table_stats(user, '상품이력');
PL/SQL 처리가 정상적으로 완료되었습니다.
select /*+ leading(b) use_nl(a) index(a 상품이력_idx)*/
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 56.92 55.60 1 1900386 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 56.93 55.61 1 1900386 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1900386 pr=1 pw=0 time=55609298 us)
365300 TABLE ACCESS BY INDEX ROWID 상품이력 (cr=1900386 pr=1 pw=0 time=58082932 us)
730601 NESTED LOOPS (cr=1535086 pr=1 pw=0 time=2210032 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365356 us)
365300 INDEX RANGE SCAN 상품이력_IDX (cr=1533917 pr=1 pw=0 time=52300282 us)(object id 117596)
-- 튜닝한 선분이력 조회 (NL 조인 및 rowid 이용)
-- (참고로, 아래 쿼리는 SQL 트레이스 걸면 매우 오래 걸리지만 그냥 수행하면 굉장히 빠르게 조회됩니다.
-- 9i, 10g, 11g에서 공통적으로 나타나는 현상이며, 버그라고 생각됩니다.)
select /*+ ordered use_nl(b) rowid(b) */
sum(a.거래수량) 총거래수량
, sum(a.거래수량 * b.판매가) 총판매금액
, round(avg(a.거래수량 * b.판매가)) 평균판매금액
from 일별상품거래 a, 상품이력 b
where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
from 상품이력 c
where 상품번호 = a.상품번호
and a.거래일자 between c.시작일자 and c.종료일자
and rownum <= 1)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 12.53 12.23 0 1462640 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 12.53 12.23 0 1462640 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1462640 pr=0 pw=0 time=12235960 us)
365300 NESTED LOOPS (cr=1462640 pr=0 pw=0 time=12785586 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365350 us)
365300 TABLE ACCESS BY USER ROWID 상품이력 (cr=1461471 pr=0 pw=0 time=10969772 us)
365300 COUNT STOPKEY (cr=1096171 pr=0 pw=0 time=7270114 us)
365300 INDEX RANGE SCAN DESCENDING 상품이력_IDX (cr=1096171 pr=0 pw=0 time=4678008 us)(object id 117596)
SQL> ALTER SESSION SET SQL_TRACE=FALSE;
세션이 변경되었습니다.
SQL> set timing on
SQL> set autotrace traceonly
SQL> select /*+ ordered use_nl(b) rowid(b) */
2 sum(a.거래수량) 총거래수량
3 , sum(a.거래수량 * b.판매가) 총판매금액
4 , round(avg(a.거래수량 * b.판매가)) 평균판매금액
5 from 일별상품거래 a, 상품이력 b
6 where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
7 from 상품이력 c
8 where 상품번호 = a.상품번호
9 and a.거래일자 between c.시작일자 and c.종료일자
10 and rownum <= 1)
11 ;
경 과: 00:00:12.57
Execution Plan
----------------------------------------------------------
Plan hash value: 3446302624
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 101G (1)|999:59:59 |
| 1 | SORT AGGREGATE | | 1 | 33 | | |
| 2 | NESTED LOOPS | | 34G| 1047G| 370K (1)| 01:14:05 |
| 3 | TABLE ACCESS FULL | 일별상품 | 369K| 6503K| 268 (3)| 00:00:04 |
| 4 | TABLE ACCESS BY USER ROWID | 상품이력 | 92162 | 1350K| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN DESCENDING| 상품이력_| 2 | 54 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(ROWNUM<=1)
6 - access("상품번호"=:B1 AND "C"."종료일자">=:B2 AND "C"."시작일자"<=:B3)
filter("C"."종료일자">=:B1)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1462640 consistent gets
0 physical reads
0 redo size
482 bytes sent via SQL*Net to client
392 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
SQL> set autotrace off;
SQL> select /*+ ordered use_nl(b) rowid(b) */
2 sum(a.거래수량) 총거래수량
3 , sum(a.거래수량 * b.판매가) 총판매금액
4 , round(avg(a.거래수량 * b.판매가)) 평균판매금액
5 from 일별상품거래 a, 상품이력 b
6 where b.rowid = (select /*+ index_desc(c 상품이력_idx)*/ rowid
7 from 상품이력 c
8 where 상품번호 = a.상품번호
9 and a.거래일자 between c.시작일자 and c.종료일자
10 and rownum <= 1)
11 ;
총거래수량 총판매금액 평균판매금액
---------- ---------- ------------
18429240 9.3271E+10 255327
경 과: 00:00:12.57
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 137.28 134.13 0 1578 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 137.29 134.13 0 1578 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1578 pr=0 pw=0 time=134135617 us)
365300 HASH JOIN (cr=1578 pr=0 pw=0 time=135619021 us)
91325 TABLE ACCESS FULL 상품이력 (cr=409 pr=0 pw=0 time=91375 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365358 us)
SQL> create table 상품이력2
2 as
3 select 상품번호
4 ,(case when 거래일자 = min(거래일자) over (partition by 상품번호) then 최소일자 else to_ch
ar(거래일자, 'yyyymmdd') end) 시작일자
5 ,(case when 거래일자 = max(거래일자) over (partition by 상품번호) then '99991231' else to_
char(lead(거래일자) over (partition by 상품번호 order by 거래일자)-1, 'yyyymmdd') end) 종료일자
6 , round(dbms_random.value(100, 10000), -2) 판매가
7 from (
8 select 상품번호, to_date(거래일자, 'yyyymmdd') 거래일자, mod(rownum, 4) no
9 from (
10 select 상품번호, 거래일자
11 from 일별상품거래
12 order by 상품번호, 거래일자
13 )
14 ), (select min(거래일자) 최소일자 from 일별상품거래)
15 where no = 1 or to_char(거래일자, 'dd') = '01'
16 ;
테이블이 생성되었습니다.
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력2 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
and trunc(to_date(b.거래일자, 'yyyymmdd'), 'mm') = trunc(to_date(a.시작일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 1 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 3.15 3.06 187 1617 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 3.15 3.07 187 1618 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1617 pr=187 pw=0 time=3068575 us)
365300 HASH JOIN (cr=1617 pr=187 pw=0 time=4638547 us)
100325 TABLE ACCESS FULL 상품이력2 (cr=448 pr=187 pw=0 time=100489 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365370 us)
SQL> select * from 월도 order by 1;
기준월 시작일자 종료일자
------------ ---------------- ----------------
199211 19921101 19921130
199212 19921201 19921231
199301 19930101 19930131
199302 19930201 19930228
199303 19930301 19930331
199304 19930401 19930430
199305 19930501 19930531
199306 19930601 19930630
199307 19930701 19930731
199308 19930801 19930831
199309 19930901 19930930
...
...
241 개의 행이 선택되었습니다.
select a.기준월, b.시작일자, b.종료일자
from 월도 a, 상품이력 b
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
 |
select /*+ ordered use_merge(b) use_hash(c) */
sum(c.거래수량) 총거래수량
, sum(c.거래수량 * b.판매가) 총판매금액
, round(avg(c.거래수량 * b.판매가)) 평균판매금액
from 월도 a, 상품이력 b, 일별상품거래 c
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
and c.상품번호 = b.상품번호
and c.거래일자 between b.시작일자 and b.종료일자
and a.기준월 || '01'
= trunc(to_date(c.거래일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 1 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 4 19.58 19.10 0 3162 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 8 19.58 19.11 0 3163 0 2
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 54
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1581 pr=0 pw=0 time=9534623 us)
365300 HASH JOIN (cr=1581 pr=0 pw=0 time=11090507 us)
100325 MERGE JOIN (cr=412 pr=0 pw=0 time=6135538 us)
241 SORT JOIN (cr=3 pr=0 pw=0 time=1093 us)
241 TABLE ACCESS FULL 월도 (cr=3 pr=0 pw=0 time=290 us)
100325 FILTER (cr=409 pr=0 pw=0 time=405580 us)
5590350 SORT JOIN (cr=409 pr=0 pw=0 time=11341081 us)
91325 TABLE ACCESS FULL 상품이력 (cr=409 pr=0 pw=0 time=91346 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=365367 us)
- 강좌 URL : http://www.gurubee.net/lecture/4439
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.