press x to close
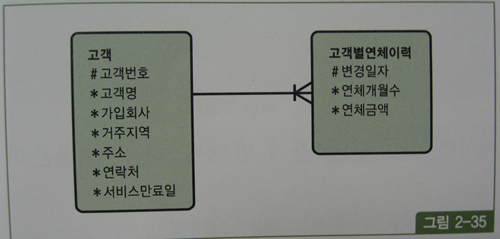 |
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ max(변경일자)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 13 | | |
| 7 | FIRST ROW | | 5039 | 65507 | 3 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN (MIN/MAX)| 고객별연체이력_IDX01 5039 | 65507 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ index_desc(b 고객별연체이력_IDX01 */ 변경일자
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1);
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
|* 6 | COUNT STOPKEY | | | | | |
|* 7 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | 26 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ substr(max(변경일자 || 연체개월수), 9)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 3836 (1)| 00:00:47 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 16 | | |
| 7 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 5039 | 80624 | 38 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 907 | | 6 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
select .....
,(selct substr(max(변경일자 || 연체금액), 9) from ...)
from 고객 a where .....
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70';
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 430 | 2 (0)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN DESCENDING| 고객별연체이력_IDX01| 907 | | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
select 고객명, 거주지역, 주소, 연락처
, to_number(substr(연체, 3)) 연체금액
, to_number(substr(연체, 1, 2)) 연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */
lpad(연체개월수, 2) || 연체금액
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일
and rownum <= 1) 연체
from 고객 a
where 가입회사 = 'C70'
);
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 700 | 2 (0)| 00:00:01 |
| 1 | VIEW | | 10 | 700 | 2 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid;
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 7381K| 12 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 100K| 7381K| 12 (0)| 00:00:01 |
| 2 | VIEW | | 10 | 560 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY USER ROWID | 고객별연체별이력 | 10079 | 187K| 1 (0)| 00:00:01 | --
------------------------------------------------------------------------------------------
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <= 1);
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 957 | 59334 | 312 (0)| 00:00:04 |
| 1 | NESTED LOOPS | | 9574K| 566M| 12 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY USER ROWID | 고객별연체이력| 1007K| 18M| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN | 고객별연체이력| 2 | 38 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
select /*+ full(a) full(b) full(c) use_hash(a b c) no_merge(b) */
a.고객명, a.거주지역, a.주소, a.연락처, c.연체금액, c.연체개월수
from 고객 a
,(select 고객번호, max(변경일자) 변경일자
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b, 고객별연체이력 c
where b.고객번호 = a.고객번호
and c.고객번호 = b.고객번호
and c.변경일자 = b.변경일자;
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 1 | HASH JOIN | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 2 | HASH JOIN | | 10 | 490 | 809 (5)| 00:00:10 |
| 3 | TABLE ACCESS FULL | 고객 | 10 | 300 | 3 (0)| 00:00:01 |
| 4 | VIEW | | 10 | 190 | 805 (4)| 00:00:10 |
| 5 | HASH GROUP BY | | 10 | 130 | 805 (4)| 00:00:10 |
|* 6 | TABLE ACCESS FULL| 고객별연| 9881 | 125K| 804 (4)| 00:00:10 |
| 7 | TABLE ACCESS FULL | 고객별연| 1007K| 18M| 788 (2)| 00:00:10 |
---------------------------------------------------------------------------------
select a.고객명, a.거주지역, a.주소, a.연락처
, to_number(substr(연체, 11)) 연체금액
, to_number(substr(연체, 9, 2)) 연체개월수
from 고객 a
,(select 고객번호, max(변경일자 || lpad(연체개월수, 2) || 연체금액 ) 연체
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b
where b.고객번호 = a.고객번호;
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 251 | 15311 | 395 (1)| 00:00:05 |
| 1 | HASH GROUP BY | | 251 | 15311 | 395 (1)| 00:00:05 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 988 | 18772 | 39 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 9881 | 588K| 393 (0)| 00:00:05 |
| 4 | TABLE ACCESS FULL | 고객 | 10 | 420 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력| 988 | | 5 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, row_number() over (partition by 고객번호 order by 변경일자 desc) no
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.no = 1;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 810K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 810K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 521K| | 865 (4)| 00:00:11 |
|* 4 | WINDOW SORT PUSHED RANK| | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL | 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
---------------------------------------------------------------------------------------------
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, max(변경일자) over (partition by 고객번호) max_dt
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.변경일자 = b.max_dt;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 781K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 781K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 492K| | 865 (4)| 00:00:11 |
| 4 | WINDOW SORT | | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL| 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
----------------------------------------------------------------------------------------
- 강좌 URL : http://www.gurubee.net/lecture/4437
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.