(6) 징검다리 테이블 조인을 이용한 튜닝
from절에 조인되는 테이블 개수를 늘려 성능을 향상시키는 사례( 교재 page. 319~ )
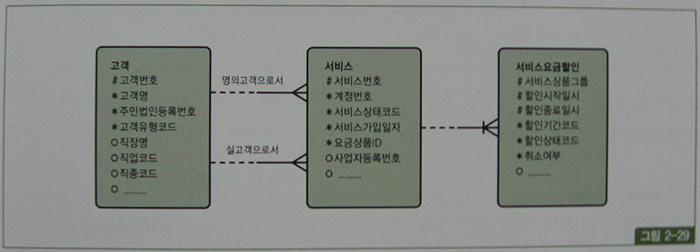
- 위의 데이터 모델에서 고객의 할인혜택을 조회하는 쿼리
SELECT /*+ ordered use_nl(s r)*/
c.고객번호, s.서비스번호, s.서비스구분
, s.서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s.명의고객번호 = c.고객번호
and r.서비스번호 = s.서비스번호
and r.서비스상품그룹 = '3001'
and r.할인기간코드 = '15'
order by r.할인종료일자 desc, s.서비스번호
고객_N1 : 주민법인등록번호
서비스_N2 : 명의고객번호 + 서비스번호
서비스요금할인_PK : 서비스요금할인_PK + 서비스상품그룹
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드
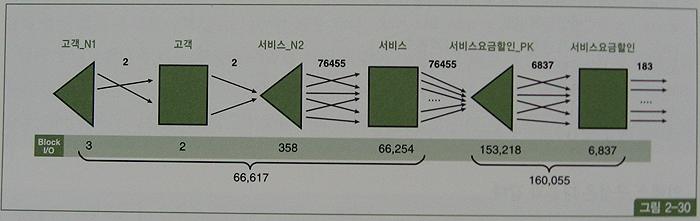
- 위의 쿼리 수행시 : 서버 구간에서만 28초가 걸리고, 블록 I/O는 226,672나 발생.
- 아래 그림은 Row Source Operation(p.320 실행계획)의 처리과정을 표현한 것이고, 각 오퍼레이션 단계에서의 출력 건수와 블록 I/O 발생량을 함께 표시하였다.
- 최종 건수는 183건에 불과 하지만, 고객 테이블을 먼저 드라이빙해 서비스 테이블과 NL 조인하는 과정에서 66,617개의 블록 I/O가 발생했고, 이어서 서비스요금할인 테이블과 NL 조인하는 과정에서 160,055개의 블록 I/O가 추가로 발생.
- 총 블록 I/O 개수는 226,672
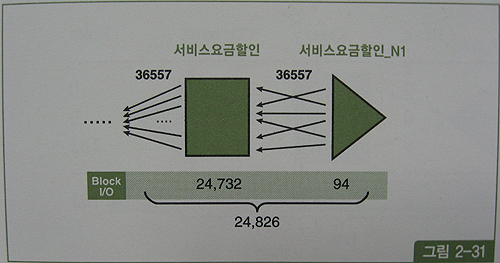
- 아래는 조인 순서를 바꿔 서비스요금할인 테이블이 먼저 드라이빙
- 그림과 같이 할인기간코드 = '15' AND 서비스상품그룹코드 = '3001' 조건에 부합하는 레코드는 36,557건
- 테이블 액세스 하는 단계에서 24,826개의 블록I/O 발생, 조인순서를 바꾸더라도 조인액세스량 줄이기는 어렵다.
- 해시조인유도시 91,443(= 66,617 + 24,826)개의 블록I/O 발생 짐작.
- I/O가 절반이상 줄기 때문에 조금은 빨라지겠지만, 속도는 만족스럽지 못함.
- 최종결과 건수는 얼마되지 않으면서, 필터 조건만으로 각 부분을 따로 읽으면 결과 건수가 아주 많을 때 튜닝하기가 가장 어려움.
- 이유는 NL 조인 과정에서 Random I/O 부하가 심하게 발생하기 때문이며, 어느 쪽으로 드라이빙하더라도 결과는 마찬가지.
- 튜닝을 위해 서비스요금할인_N1 인덱스에 아래와 같이 '서비스번호' 컬럼을 추가
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드 + 서비스번호
- 서비스와 서비스요금할인을 한 번씩 더 조인하도록 쿼리를 아래처럼 변경
SELECT /*+ ordered use_hash(r_brdg) rowid(s) rowid(r) */ ------------------- 1
c.고객번호, s.서비스번호, s.서비스구분
, s.서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c
, 서비스 s_brdg, 서비스요금할인 r_brdg ------------------------------ 2
, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s_brdg.명의고객번호 = c.고객번호
and r_brdg.서비스번호 = s_brdg.서비스번호
and r_brdg.서비스상품그룹 = '3001'
and r_brdg.할인기간코드 = '15'
and s.rowid = s_brdg.rowid --------------------------------- 3
and r.rowid = r_brdg.rowid -------------------------------- 4
order by r.할인종료일자 desc, s.서비스번호
실행결과(p.322)
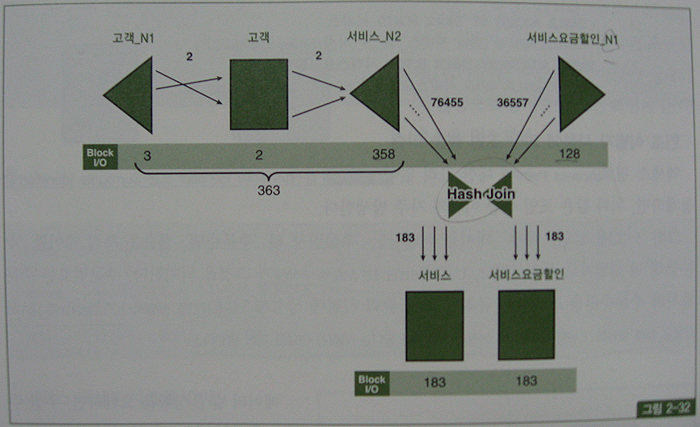
- 튜닝 전에 226,672개 블록을 읽으면서 27.8초 걸리던 쿼리가 857개 블록을 읽으면서 0.12초만에 수행.
- '서비스'와 '서비스요금할인' 테이블을 한 번씩 더 조인(from절 2번)함으로써 I/O가 줄면서 성공적으로 튜닝.
- 양쪽 테이블에서 인덱스만 읽은 결과끼리 먼저 조인하고 최종 결과집합 183건에 대해서만 테이블을 액세스하도록 한 것이 핵심 아이디어(서비스요금할인_N1 인덱스에 '서비스번호' 추가).
- 고객 테이블과 서비스_N2 인덱스를 조인할 때는 블록 I/O가 총 363번 발생.
- 서비스요금할인_N1 인덱스만 읽을 때도 블록 I/O는 128개(94개에서 128개로 늘어난 이유는 서비스번호 컬럼을 추가했기 때문)
- 인덱스에서 얻어진 집합끼리 조인할 때는 대량 데이터 조인이므로 해시 조인 방식을 사용(쿼리에서 1번)
- 인덱스에 없는 컬럼 값들을 읽으려고 테이블을 액세스할 때는 추가적인 인덱스 탐색 없이 인덱스에서 읽은 rowid 값을 가지고 직접 액세스(쿼리에서 3번과 4번, Table Access By User ROWID)
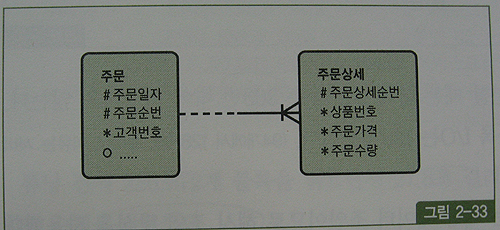
인조 식별자 사용에 의한 조인 성능 이슈
- 위 그림은 '주문' 테이블 식별자인 '주문일자'와 '주문순번' 컬럼을 자식 테이블 '주문상세'의 식별자로 상속시킴(UID Bar)
- 아래는 특정주문일자에 발생한 특정상품 주문금액 집계 쿼리(주문일자평균 100,000건, 상품번호 1000건, 상품번호별 하루평균 600건의 데이터)
- 주문상세 쪽 인덱스를 상품번호 + 주문일자 또는 주문일자 + 상품번호 순으로 구성. -- 자세한 설명은 4장 5절 '조건절 이행' 참조
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문일자 = 주문상세.주문일자
and 주문.주문순번 = 주문상세.주문순번
and 주문.주문일자 = '20090315'
and 주문상세.상품번호 = 'AC001'
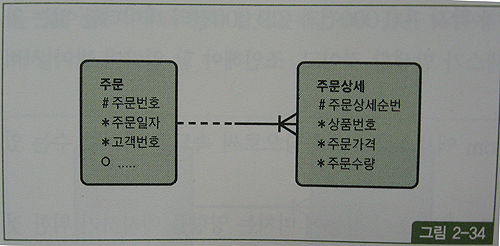
- 반면, 아래 그림처럼 '주문번호'라는 인조 식별자 컬럼을 따로 둔다면 주문상세 테이블에 '주문일자' 속성이 상속되지 않음으로 조인 과정에 큰 비효율 발생
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문, 주문상세
where 주문.주문번호 = 주문상세.주문번호
and 주문.주문일자 = '20090315'
AND 주문상세.상품번호 = 'AC001'
주문_PK : 주문번호
주문_X01 : 주문일자
주문상세_PK : 주문번호 + 주문일자
주문상세_X01 : 상품번호
- 주문 테이블에서 읽은 100,000건에 대해 주문상세 쪽으로 100,000번의 조인 액세스가 일어남.
- 주문상세_PK 인덱스를 거쳐 주문상세 테이블을 100,000번 액세스하고서 상품번호 = 'AC001' 조건을 필터링 하고 나면 최종적으로 600건 정도만 남고 모두 버려짐.
- 주문상세_X01 또는 주문_X01 인덱스에 주문번호를 추가하고 이 인덱스를 이용하면 테이블 Random 액세스를 줄일 수 있지만 조인 시도 횟수는 줄지 않음.
- 해시 조인으로 유도하더라도 인덱스를 거쳐 각각 100,000건과 219,000건의 데이터를 읽는 과정에서 이미 상당량의 테이블 Random 액세스 발생할 것이고, 조인해야 할 일량이 많아 서버 리소스(CPU, 메모리)를 많이 사용하게 됨.
- 위 상황에서는 '주문일자' 컬럼을 주문상세 테이블로 반정규화하는 것이 가장 효과적인 해법일 것이다.
인조 식별자를 둘 때 주의 사항
- 장점
- 단일 컬럼으로 구성되므로 테이블 간 연결 구조가 단순해지고, 인덱스 저장공간이 최소화된다.
- 다중 컬럼으로 조인할 때보다 조인 연산을 위한 CPU사용량이 조금 줄 수 있다.
- 단점
- 조인 연산 횟수와 블록 I/O 증가로 시스템 리소스를 낭비한다.
- 실질 식별자를 찾기 어려워 데이터 모델이 이해하기 어려워진다.
- TIP
- 1. 논리적인 데이터 모델링 단계에서는 가급적 인조 식별자를 두지 않는 것이 좋다.
- 2. 의미상 주어에 해당하는 속성들을 식별자로 사용했다가 물리 설계 단계에서 저장 효율과 액세스 효율 등을 고려해서 결정한다.