press x to close
SELECT *
FROM (
SELECT ROWNUM NO, 등록일자, 번호, 제목
, 회원명, 게시판유형명, 질문유형명, COUNT(*) OVER() CNT
FROM(
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
FROM 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
)
WHERE ROWNUM <= 31
)
WHERE NO BETWEEN 21 AND 30
Execution Plan
--------------------------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 VIEW
2 1 WINDOW (BUFFER)
3 2 COUNT (STOPKEY)
4 3 VIEW
5 4 SORT (ORDER BY STOPKEY)
6 5 NESTED LOOPS
7 6 NESTED LOOPS
8 7 NESTED LOOPS
9 8 TABLE ACCESS (BY LOCAL INDEX ROWID) OF '게시판' (TABLE)
10 9 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
11 10 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 7 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 6 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) ROWID(A) */
A.등록일자, B.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, X.CNT
FROM (
SELECT RID, ROWNUM NO, COUNT(*) OVER() CNT
FROM (
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
)
WHERE ROWNUM <= 31
) X, 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
Execution Plan
---------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 NESTED LOOPS
2 1 NESTED LOOPS
3 2 NESTED LOOPS
4 3 NESTED LOOPS
5 4 VIEW
6 5 COUNT (STOPKEY)
7 6 VIEW
8 7 SORT (ORDER BY STOPKEY)
9 8 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
10 4 TABLE ACCESS (BY USER ROWID) OF '게시판' (TABLE) -- BY USER ROWID
11 3 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 2 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 1 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호(+) = A.작성자번호
AND C.게시판유형(+) = A.게시판유형
AND D.질문유형(+) = A.질문유형
 |
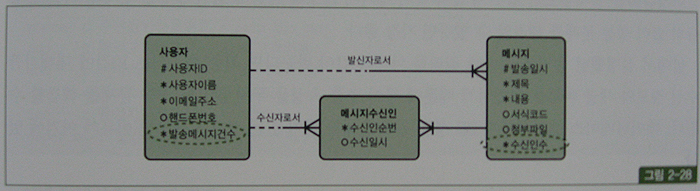 |
SELECT ..
FROM (
SELECT ..
FROM (
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) FROM 메시지수신인 ..) 수신확인자수
, ( SELECT COUNT(*) FROM 메시지수신인 ..) 수신대상자수
, ( CASE WHEN EXISTS ( SELECT 'x' FROM 메시지수신인
WHERE 발신자ID = a.발신자ID
AND 발송일시 = a.발송일시
AND 수신자ID = :로그인사용자ID
AND 수신일시 IS NULL ) THEN 'Y' END ) 새글여부
FROM 메시지 a, 사용자 b
ORDER BY a.발송일시 DESC
) a
WHERE rownum <= 10
)
WHERE no between 1 and 10;
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) || '/' || COUNT(*) FROM 메시지수신인 ..) 수신확인
, ( CASE WHEN EXISTS ( .. ) THEN 'Y' END ) 새글여부
FROM (
SELECT ROWNUM NO, ...
FROM ( SELECT 발신인ID, a,발송일시, a.제목 FROM 메시지 ORDER BY a.발송일시 DESC )
WHERE ROWNUM <= 30
) a, 사용자 b
WHERE NO BETWEEN 21 AND 30;
AND .........
- 강좌 URL : http://www.gurubee.net/lecture/4435
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.