press x to close
SYS> drop table t1 purge ;
Table dropped.
SYS> create table t1 ( c1 int, c2 int );
Table created.
SYS> create index t1_n1 on t1 ( c1 ) ;
Index created.
SYS> insert into t1 select level, level from dual connect by level <= 10000 ;
10000 rows created.
SYS>@gather t1
PL/SQL procedure successfully completed.
SYS> select /*+ gather_plan_statistics index(t1) */ count(c1) from t1 where c1 >= 5 ;
COUNT(C1)
----------
9996
SYS>@stat
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 20 |
|* 2 | INDEX RANGE SCAN| T1_N1 | 1 | 9997 | 20 (0)| 9996 |00:00:00.01 | 20 |
SYS>delete from t1 where c1 >= 1 ;
10000 rows deleted.
SYS>select /*+ gather_plan_statistics index(t1) */ count(c1) from t1 where c1 >= 5 ;
SYS>@stat
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 20 |
|* 2 | INDEX RANGE SCAN| T1_N1 | 1 | 9997 | 20 (0)| 0 |00:00:00.01 | 20 |
SYS> exec tree_dump2(v_owner =>'sys',v_name=>'t1_n1');
----- begin tree dump
branch: 0x40ef32 4255538 (0: nrow: 19, level: 1)
leaf: 0x40ef33 4255539 (-1: nrow: 540 rrow: 540)
leaf: 0x40ef34 4255540 (0: nrow: 533 rrow: 533)
leaf: 0x40ef35 4255541 (1: nrow: 533 rrow: 533)
leaf: 0x40ef36 4255542 (2: nrow: 533 rrow: 533)
leaf: 0x40ef37 4255543 (3: nrow: 533 rrow: 533)
leaf: 0x40ef38 4255544 (4: nrow: 533 rrow: 533)
leaf: 0x40f491 4256913 (5: nrow: 533 rrow: 533)
leaf: 0x40f492 4256914 (6: nrow: 533 rrow: 533)
leaf: 0x40f493 4256915 (7: nrow: 533 rrow: 533)
leaf: 0x40f494 4256916 (8: nrow: 533 rrow: 533)
leaf: 0x40f495 4256917 (9: nrow: 533 rrow: 533)
leaf: 0x40f496 4256918 (10: nrow: 533 rrow: 533)
leaf: 0x40f497 4256919 (11: nrow: 533 rrow: 533)
leaf: 0x40f498 4256920 (12: nrow: 533 rrow: 533)
leaf: 0x40f4a1 4256929 (13: nrow: 533 rrow: 533)
leaf: 0x40f4a2 4256930 (14: nrow: 533 rrow: 533)
leaf: 0x40f4a3 4256931 (15: nrow: 533 rrow: 533)
leaf: 0x40f4a4 4256932 (16: nrow: 533 rrow: 533)
leaf: 0x40f4a5 4256933 (17: nrow: 399 rrow: 399)
----- end tree dump
SYS>@dic t1_n1
OWNER : SYS
INDEX_NAME : T1_N1
INDEX_TYPE : NORMAL
TABLE_OWNER : SYS
TABLE_NAME : T1
TABLE_TYPE : TABLE
UNIQUENESS : NONUNIQUE
COMPRESSION : DISABLED
PREFIX_LENGTH :
TABLESPACE_NAME : SYSTEM
INI_TRANS : 2
MAX_TRANS : 255
INITIAL_EXTENT : 65536
NEXT_EXTENT :
MIN_EXTENTS : 1
MAX_EXTENTS : 2147483645
PCT_INCREASE :
PCT_THRESHOLD :
INCLUDE_COLUMN :
FREELISTS : 1
FREELIST_GROUPS : 1
PCT_FREE : 10
LOGGING : YES
BLEVEL : 1
LEAF_BLOCKS : 19 <======== Leaf Blocks 수
DISTINCT_KEYS : 10000
AVG_LEAF_BLOCKS_PER_KEY : 1
AVG_DATA_BLOCKS_PER_KEY : 1
CLUSTERING_FACTOR : 18
SYS> select /*+ gather_plan_statistics index(t1) */ c1 from t1 where c1 >= 5 ;
SYS>@stat
before delete
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
|* 1 | INDEX RANGE SCAN| T1_N1 | 1 | 9997 | 20 (0)| 9996 |00:00:00.01 | 686 |
-------------------------------------------------------------------------------------------------
SYS> delete from t1 where c1 >= 1 ; -- 이미 테스트 가.1.C1 에서 삭제함 - Remind 차원
10000 rows deleted.
SYS> select /*+ gather_plan_statistics index(t1) */ c1 from t1 where c1 >= 5 ;
SYS> @stat
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
|* 1 | INDEX RANGE SCAN| T1_N1 | 1 | 9997 | 20 (0)| 0 |00:00:00.01 | 20 |
-------------------------------------------------------------------------------------------------
SYS>drop table t1 purge ;
Table dropped.
SYS>create table t1 ( c1 int, c2 int );
Table created.
SYS>create index t1_n1 on t1 ( c1 ) ;
Index created.
SYS>insert into t1 select level, level from dual connect by level <= 10000 ;
10000 rows created.
SYS>@gather t1
PL/SQL procedure successfully completed.
SYS>select /*+ gather_plan_statistics index(t1) */ c1 from t1 where c1 >= 5 ;
SYS>exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SYS> @mysid
SYS> @mon_on &v_sid
SYS> select /*+ gather_plan_statistics index(t1) */ c1 from t1 where c1 >= 5 ;
SYS> @mon_off
SYS> select t1.name as name, sum(t1.value) as value1 from t_mon_temp t1
where t1.name in ('buffer is pinned count','session logical reads','user calls')
group by t1.name ;
NAME VALUE1
---------------------------------------------------------------- ----------
user calls 709
session logical reads 781
buffer is pinned count 0
SYS>delete from t1 where c1 >= 1 ;
10000 rows deleted.
SYS>exit
SYS>@mysid
SYS>@mon_on &v_sid
SYS> select /*+ gather_plan_statistics index(t1) */ c1 from t1 where c1 >= 5 ;
SYS> @mon_off
SYS> select t1.name as name, sum(t1.value) as value1 from t_mon_temp t1
where t1.name in ('buffer is pinned count','session logical reads','user calls')
group by t1.name ;
NAME VALUE1
---------------------------------------------------------------- ----------
user calls 42
session logical reads 98
buffer is pinned count 0
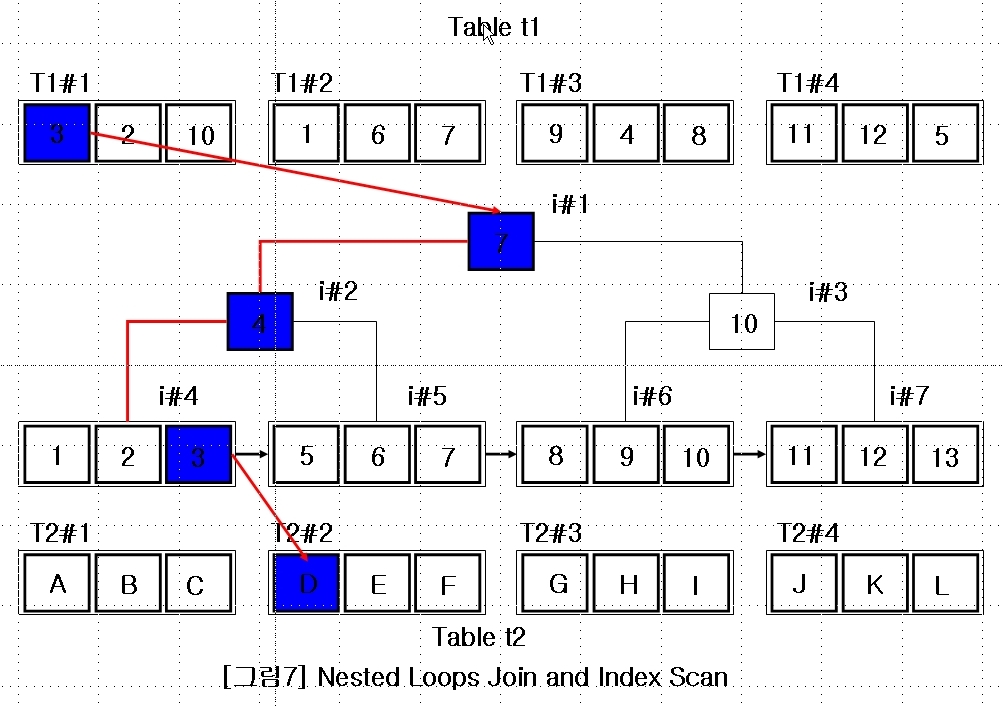
select /*+ leading(t1) use_nl(t1 t2) index(t2) */ *
from t1, t2
where t1.c1 = t2.c1 ;
TABLE ACCES BY INDEX ROWID T2
NESTED LOOPS
TABLE ACCESS FULL T1
INDEX RANGE SCAN T2_NI
 |
SYS>drop table t1 purge ;
Table dropped.
SYS>drop table t2 purge ;
Table dropped.
SYS>create table t1 (c1 int, c2 int ) ;
Table created.
SYS>create table t2 ( c1 int , c2 int );
Table created.
SYS>create index t2_n1 on t2 ( c1) ;
Index created.
SYS>insert into t1 select level, level from dual connect by level <= 10000 ;
10000 rows created.
SYS>insert into t2 select level, level from dual connect by level <= 10000 ;
10000 rows created.
SQL> begin for i in 1..10000 loop
2 insert into t1 values ( i, i) ;
3 end loop;
4 commit ;
5 end ;
6 /
PL/SQL procedure successfully completed.
SQL> begin for i in 1..10000 loop
2 insert into t2 values ( i, i) ;
3 end loop;
4 commit ;
5 end ;
6 /
PL/SQL procedure successfully completed
SQL> alter session set sql_trace = true ;
SQL> select /*+ leading(t1) use_nl(t1 t2) index(t2) */ * from t1, t2 where t1.c1 = t2.c1 ;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1001 0.08 0.16 2 23036 4 10000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1003 0.08 0.16 2 23036 4 10000
Misses in library cache during parse: 1
Optimizer goal: CHOOSE
Parsing user id: SYS
Rows Row Source Operation
------- ---------------------------------------------------
10000 NESTED LOOPS
10001 TABLE ACCESS FULL T1
10000 TABLE ACCESS BY INDEX ROWID T2
20000 INDEX RANGE SCAN (object id 415897)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.01 0 49 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 668 0.14 0.13 0 12728 0 10000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 670 0.15 0.14 0 12777 0 10000
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: SYS
Rows Row Source Operation
------- ---------------------------------------------------
10000 TABLE ACCESS BY INDEX ROWID T2 (cr=12728 pr=0 pw=0 time=190220 us)
20001 NESTED LOOPS (cr=12043 pr=0 pw=0 time=100056 us)
10000 TABLE ACCESS FULL T1 (cr=690 pr=0 pw=0 time=20023 us)
10000 INDEX RANGE SCAN T2_N1 (cr=11353 pr=0 pw=0 time=78354 us)(object id 53549)
- 강좌 URL : http://www.gurubee.net/lecture/4429
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.