트러블슈팅 오라클 퍼포먼스 2판 (2017년)
적절한 파라미터 설정하기
- 쿼리 옵티마이저를 성공적으로 구성하려면 옵티마이저의 작동 방식 및 각각의 초기화 파타미터가 옵티마이저에 미치는 영향을 반드시 이해해야 한다.
- 이러한 지식을 바탕으로 임의로 구겅을 조정하거나 최근 인터넷에서 발견한 좋은 값을 붙여넣기 하는 대신에 다음과 같은 것들을 수행해야 한다.
- 현재 상황을 이해한다.
- 달성해야 할 목표를 설정한다.
- 설정한 목료를 달성하기 위해 수정되어야 할 초기화 파라미터나 통계를 찾아본다.
쿼리 옵티마이저와 관련된 파라미터
OPTIMIZER_MODE
- 이 파라미터는 더 빠른 처리 보다 보다 적은 리소스 사용 또는 다른 무언가를 의미할 수 있다.
- OPTIMIZER_MODE 초기화 파라미터의 값을 선택하기 위해서는 쿼리 옵티마이저가 첫 로우의 빠른 전송과 마지막 로우의 빠른 전송 중에 어떠한 실행 계획을 생성하는 것이 더 중요한지 자문해봐야 한다.
- 기본값은 ALL_ROWS이다 INSERT, DELETE, MERGE, UPDATE 구문은 항상 ALL_ROWS로 최적화된다.
OPTIMIZER_FEATURES_ENABLE
- 데이터베이스 버전이 올라갈 때마다 오라클은 쿼리 옵티마이저에 대해 새로운 기능을 도입하거나 이전 버전에서 비활성화되었던 기능을 활성화한다.
- 이전 버전을 사용하기를 원하면 OPTIMIZER_FEATURES_ENABLE을 이전 버전으로 설정하면 된다.
- OPTIMIZER_FEATURES_ENABLE 초기화 파라미터는 인스턴스 및 세션 레벨에서 변경 가능한 동적 파라미터이다.
SQL> SELECT value
2 FROM v$parameter_valid_values
3 WHERE name = 'optimizer_features_enable';
VALUE
--------------------------------------------------------------------------------
8.0.0
8.0.3
8.0.4
8.0.5
...
9.0.0
9.0.1
9.2.0
...
10.1.0.4
10.1.0.5
...
11.2.0.1
11.2.0.2
11.2.0.3
...
12.2.0.1
12.2.0.1.1
35 행이 선택되었습니다.
DB_FILE_MULTIBLOCK_READ_COUNT
- 멀티블록 읽기를 하는 동안 데이터베이스 엔진이 사용하는 최대 디스크 I/O의 크기는 DB_BLOCK_SIZE와 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터의 값을 곱해서 결정된다. 따라서 멀티블락 읽기를 하는 동안 읽게 될 블록의 최대 개수는 최대 디스크 I/O 크기를 테이블스페이스의 블록 크기로 나누면 된다.
- 다시 말해 기본 블록 크기일 경우 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터가 읽어 들일 블록의 최대 개수를 지정한다. 이 파라미터는 단순히 최댓값 을 의미할 뿐인데, 왜냐하면 일반적으로 다음과 같은 세 가지 경우에는 초기화 파라미터에서 지정된 값보다 더 작은 값으로 멀티블록 읽기가 일어날 수 있기 때문이다.
- 세크먼트 헤더나 익스텐트 맵 같은 세그먼트 메타데이터가 포함된 다른 블록에 대해서는 싱글블록 읽기로 읽어 들인다.
- 물리적 읽기는 결코 여러 개의 익스텐트에 걸쳐서 일어나지 않는다.
- 직접 경로 읽기를 제외하고 이미 버퍼 캐시에 캐싱된 블록은 디스크 I/O 시스템에서 다시 읽어 들이지 않는다.
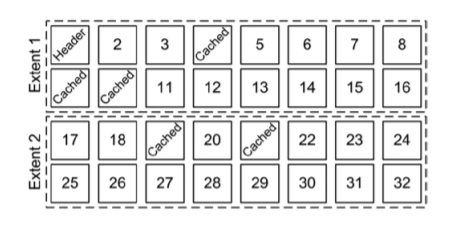 |
- 위에 그림은 수동 세그먼트 공간 관리를 사용하는 테이블스페이스에 저장된 세그먼트의 구조를 보여준다.
- 첫 번째 익스텐트의 첫 번째 블록은 세그먼트 헤더이다. 일부 블록(4,9,10,19,20)은 버퍼 캐시에 캐싱되어 있다.
- 이 세그먼트를 버퍼 캐시로 읽어들이는 데이터베이스 엔진의 프로세스는 DB_FILE_MULTIBOLCK_READ_COUNT 파라미터가 32보다 크거나 같은 값으로 설정되어 있더라도 한 번의 물리적 멀티블록 읽기로 읽어 들일 수 없다.
DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터가 8로 설정되어 있다면, 버퍼 캐시 읽기가 다음과 같이 수행된다.
- 세그먼트 헤더(1번)에 대한 싱글블록 읽기 1회
- 2개의 블록(2번 3번)에 대한 한 번의 멀티블록 읽기를 수행한다. 블록 4가 캐싱되어 있기 때문에 더 이상의 블록들은 읽어 들일 수 없다.
- 4개의 블록(5번~8번)을 한 번의 멀티블록 읽기로 읽어 들인다. 블록 9가 캐싱되어 있기 때문에 더 이상의 블록들은 읽어 들일 수 없다.
- 6개의 블록(11번~16번)을 한 번의 멀티블록 읽기로 읽어 들인다. 블록 16이 익스텐트의 마지막이기 때문에 더 이상의 블록은 읽어 들일 수 없다.
- 두 개의 블록(17/18번)을 한 번의 멀티블록 읽기로 읽어 들인다. 블록 19가 캐싱되어 있기 때문에 더 이상의 블록은 읽어 들일 수 없다.
- 20번 블록에 대해 한 번의 싱글블록 읽기가 수행된다. 블록 21이 캐싱되어 있기 때문에 더 이상의 블록은 읽어 들일 수 없다.
- 8개의 블록(22번~29번)을 한 번의 멀티블록 읽기로 읽어 들인다. db_file_multiblock_read_count 초기화 파라미터가 8로 설정되어 있기 때문에 더 이상의 블록은 읽어 들일 수 없다,
- 3개의 블록(30~32번)에 대해 한 번의 멀티블록 읽기가 수행된다.
- 요약하자면 오라클 프로세스는 2번의 싱글블록 읽기와 6번의 멀티블록 읽기를 수행한다.
- 멀티블록 읽기로 읽어 들인 블록의 평균 개수는 대략 4이다. 평균 크기가 8보다 작다는 사실은 오라클이 시스템 통계에서 mbrc 값을 도입한 이유를 설명해준다.
- workload 시스템 통계를 사용할 수 있는 경우에는 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터의 값을 사용하지 않고 I/O 비용을 계산한다.
- 멀티블록 I/O 비용은 공식 9-1에 따라 계산된다.
Formula 9-1. I/O cost of multiblock read operations with workload statistics blocks mreadtim io_cost mbrc sreadtim
nowworkload 통계의 경우 공식 9-1에서 변수가 다음과 같이 대체된다.
- DB_FILE_MULTIBOLCK_READ_COUNT 초기화 파라미터를 명시적으로 설정할 경우에는 mbrc가 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터의 값으로 대체되고 그렇지 않으면 8이 사용된다.
- 비용 계산 공식을 살펴봤으니 이제 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라미터의 설정값을 찾는 방법을 살펴볼 차례이다.
- 이때 가장 중요한 것은 멀티블록 읽기가 성능에 큰 영향을 미칠 수 있다는 사실이다. 따라서 DB_FILE_MULTIBLOCK_READ_COUNT 초기화 파라티머는 최적의 성능을 얻을 수 있도록 신중하게 설치해야 한다.
- 일반적으로 디스트 I/O 크기가 1MB일 때 최적에 가까운 성능을 제공하긴 하지만, 가끔은 그보다 높거나 낮은 값이 더 나은 결과를 보여줄 때도 있다.
- 게다가 이 파라미터의 값이 높을 경우 일반적으로 디스트 I/O 오퍼레이션을 수행하는데 더 적은 CPU를 사용한다.
- 서로 다른 값을 사용하여 간단한 full table scan을 수행해본다면 이 초기화 파라미터가 미치는 영향에 대해 유용한 정보를 얻을 수 있으며, 최적의 값을 찾는데 도움을 받을 수 있다.
- assess_dbmbrc.sql 스크립트를 발췌한 다음 PL/SQL 코드는 이러한 목적에 사용할 수 있다.
BEGIN dbms_output.put_line('dbfmbrc blocks seconds cpu');
FOR i IN 0..10
LOOP
l_dbfmbrc := power(2,i);
EXECUTE IMMEDIATE 'ALTER SESSION SET db_file_multiblock_read_count = '||l_dbfmbrc;
EXECUTE IMMEDIATE 'ALTER SYSTEM FLUSH BUFFER_CACHE';
SELECT sum(decode(name, 'physical reads', value)),
sum(decode(name, 'CPU used by this session', value))
INTO l_starting_blocks, l_starting_cpu
FROM v$mystat ms JOIN v$statname USING (statistic#)
WHERE name IN ('physical reads','CPU used by this session');
l_starting_time := dbms_utility.get_time();
SELECT count(*) INTO l_count FROM t;
l_ending_time := dbms_utility.get_time();
SELECT sum(decode(name, 'physical reads', value)),
sum(decode(name, 'CPU used by this session', value))
INTO l_ending_blocks, l_ending_cpu
FROM v$mystat ms JOIN v$statname USING (statistic#)
WHERE name IN ('physical reads','CPU used by this session');
l_time := round((l_ending_time-l_starting_time)/100,1);
l_blocks := l_ending_blocks-l_starting_blocks;
l_cpu := l_ending_cpu-l_starting_cpu;
dbms_output.put_line(l_dbfmbrc||' '||l_blocks||' '||to_char(l_time)||' '||to_char(l_cpu)); END LOOP; END;
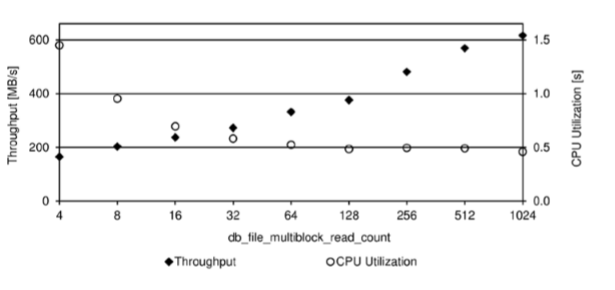 |
- 모든 초기화 파라미터를 기본값으로 설정한 11.2 데이터베이스에서 위의 PL/SQL 블록을 실행하여 측정한 나의 테스트 시스템에 대한 특성을 보여주고 있다.
- 여기에서 주목할 점은 다음과 같다.
- 처리량은 db_file_multiblock_read_count 초기화 파라미터가 작은 값을 때 약 200MB/s에서 매우 큰 값일 때 600MB/s 이상으로 증가한다.
- CPU 사용률은 db_file_multiblock_read_count 초기화 파라미터가 작은 값일 때 약 1.5초에서 매우 큰 값일 때 0.5초 이하로 떨어진다.
OPTIMIZER_DYNAMIC_SAMPLING
12.1 버전부터는 동적 샘플링이라는 용어 대신에 동적 통계라는 용어가 사용되지만 이 책에서는 옛날 이름인 동적 샘플링을 사용한다.
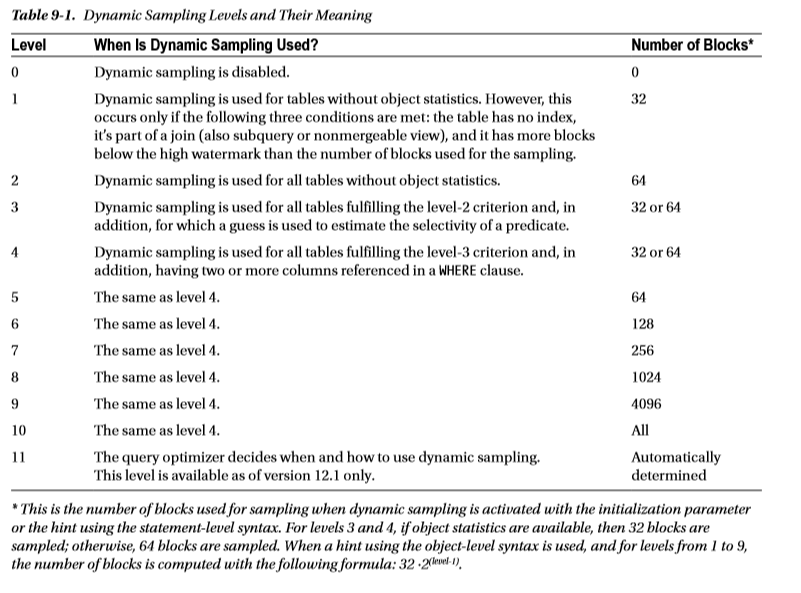 |
- OPTIMIZER_DYNAMIC_SAMPLING 초기화 파라미터는 동적 파라미터이며 인스턴스 레벨 및 세션 레벨에서 변경할 수 있다.
- 12.1 멀터터넨트 환경에서는 PDB 레벨에서 설정할 수도 있다.
- 또한 dynamic_sampling 힌트를 사용하여 구분 레벨에서 값을 지정할 수도 있다. 힌트에서 다음과 같은 두 가지 문법을 사용할 수 있다.
- dynamic_sampling(레벨) : 구문 레벨의 힌트는 optimizer_dynamic_sampling 초기화 파라미터에서 설정한 값보다 우선한다.
- dynamic_sampling(table_alias 레벨) : 오브젝트 레벨 힌트는 지정한 테이블에 대해서만 동적 샘플링을 활성화한다.
- 쿼리 옵티마이저는 두 가지 유형의 통계를 수집하기 위하여 동적 샘플링을 사용할 수 있다.
첫 번째는 다음과 같다.
- 세그먼트의 하이 워터마크 아래에 있는 블록의 개수
- 테이블에 있는 로우의 개수
- 컬럼의 distinct 값의 개수
- 컬럼의 NULL 값의 개수
두 번째 유형은 다음과 같다.
- 조건절의 선택도
- 조인의 카디널리티(12.1 버전 이후만)
- 집계의 카디널리티(12.1 버전 이후만)
SQL> CREATE TABLE t_noidx (id, n1, n2, pad) AS
SELECT rownum, rownum,
cast(round(dbms_random.value(1,100)) AS VARCHAR2(100)),
cast(dbms_random.string('p',1000) AS VARCHAR2(1000))
FROM dual CONNECT BY level <= 1000 ;
테이블이 생성되었습니다.
SQL> CREATE TABLE t_idx (id CONSTRAINT t_idx_pk PRIMARY KEY, n1, n2, pad) AS SELECT * FROM t_noidx;
테이블이 생성되었습니다.
SELECT * FROM t_noidx t1, t_noidx t2 WHERE t1.id = t2.id AND t1.id < 19
SELECT * FROM t_idx t1, t_idx t2 WHERE t1.id = t2.id AND t1.id < 19
- 레벨이 1로 설정되어 있는 경우, 두 번째 쿼리가 참조하는 테이블에 인덱스가 있기 때문에 첫 번째 쿼리만 동적 샘플링이 수행된다.
SELECT NVL(SUM(C1),0),
NVL(SUM(C2),0),
COUNT(DISTINCT C3),
NVL(SUM(CASE WHEN C3 IS NULL THEN 1 ELSE 0 END),0)
FROM (
SELECT 1 AS C1,
CASE WHEN "T1"."ID"<19 THEN 1 ELSE 0 END AS C2,
"T1"."ID" AS C3
FROM "CHRIS"."T_NOIDX" SAMPLE BLOCK (20 , 1) SEED (1) "T1"
) SAMPLESUB
여기서는 다음과 같은 것들을 주목해야 한다.
- 쿼리 옵티마이저는 로우의 총 개수, WHERE 절(id < 19)에서 지정한 범위에 있는 로우의 개수, distinct 값의 개수, ID 칼럼에서 NULL 값의 개수를 카운트한다.
- 쿼리에서 사용된 값을 알고 있어야 한다. 바인드 변수가 사용되었다면, 쿼리 옵티마이저가 동적 샘플링을 수행할 수 있도록 미리 값을 엿볼 수 있어야 한다.(BIND PEEKING).
- 샘플링을 수행하기 위해 SAMPLE 절이 사용되었다. 테스트 데이터베이스에서 t_noidx 테이블은 155 블록으로 이루어졌기 때문에 샘플링 비율은 20%이다.
SELECT NVL(SUM(C1),0),
NVL(SUM(C2),0),
NVL(SUM(C3),0)
FROM ( SELECT 1 AS C1,
1 AS C2,
1 AS C3
FROM "CHRIS"."T_IDX" "T1"
WHERE "T1"."ID"<19
AND ROWNUM <= 2500
) SAMPLESUB
- 레벨 2로 설정되어 있는 경우에는 오브젝트 통계가 없을 때 언제나 동적 샘플링이 사용되기 때문에 양쪽 테스트 쿼리에 대해 동적 샘플링을 제공한다.
BEGIN dbms_stats.gather_table_stats( ownname => user,
tabname => 't_noidx',
method_opt => 'for all columns size 1');
dbms_stats.gather_table_stats( ownname => user,
tabname => 't_idx',
method_opt => 'for all columns size 1',
cascade => true);
END;
- 레벨 3 이상으로 설정되면 쿼리 옵티마이저는 조건절의 선택도를 추정하기 위해 데이터 딕셔너리 통계나 하드 코딩된 값을 사용하는 대신 테이블의 로우 샘플링을 통해 선택도를 측정하는 동적 샘플링을 수행한다.
SELECT * FROM t_idx WHERE id = 19
SELECT * FROM t_idx WHERE round(id) = 19
첫 번째의 경우 쿼리 옵티마이저는 컬럼 통계와 히스토그램을 기반으로 id=19 조건절의 선택도를 추정할 수 있다. 따라서 어떤 동적 샘플링도 필요로 하지 않는다. 그 대신 두 번째 쿼리에 대해 쿼리 옵티마이저는 round(id)=19 조건절의 선택도를 추론할 수 없다.
SELECT NVL(SUM(C1),0),
NVL(SUM(C2),0),
COUNT(DISTINCT C3)
FROM ( SELECT 1 AS C1,
CASE WHEN ROUND("T_IDX"."ID")=19 THEN 1 ELSE 0 END AS C2,
ROUND("T_IDX"."ID") AS C3
FROM "CHRIS"."T_IDX" SAMPLE BLOCK (20 , 1) SEED (1) "T_IDX"
) SAMPLESUB
- 레벨 4 이상으로 설정한 경우 동일 테이블에서 WHERE 절이 두 개 이상의 칼럼을 참조할 때도 쿼리 옵티마이저는 동적 샘플링을 수행한다.
SELECT * FROM t_idx WHERE id < 19 AND n1 < 19
- 또한 이 경우에 쿼리 옵티마이저는 앞서와 동일한 구조를 가진 쿼리를 사용하여 동적 샘플링을 수행한다.
SELECT NVL(SUM(C1),0),
NVL(SUM(C2),0)
FROM ( SELECT 1 AS C1,
CASE WHEN "T_IDX"."ID"<19 AND "T_IDX"."N1"<19 THEN 1 ELSE 0 END AS C2
FROM "CHRIS"."T_IDX" SAMPLE BLOCK (20 , 1) SEED (1) "T_IDX"
) SAMPLESUB
요약하면 일반적으로 레벌1과 2는 그다지 유용하지 않다는 사실을 알 수 있다.
OPTIMIZER_INDEX_COST_ADJ
- OPTIMIZER_INDEX_COST_ADJ 초기화 파라미터는 index scan을 통해서 테이블을 액세스할 때의 비용을 변경하기 위한 목적으로 사용된다.
- 이 초기화 파라미터가 비용 계산 공식에 미치는 영향을 이해하려면 쿼리 옵티마이저가 index range scan에 기초하는 테이블 엑세스와 관련된 비용을 어떻게 계산하는지 알고 있어야 한다.
- index range scan은 여러 개의 키에 대한 인덱스 검색이다.
다음과 같은 오퍼레이션이 수행된다.
1. 인덱스의 루트 블록을 엑세스 한다.
2. 브랜치 블록을 거쳐서 첫 번째 키가 포함된 리프 블록을 찾아간다.
3. 검색 기준을 충족하는 각각의 키에 대해 다음을 수행한다.
- 데이터 블록을 참조하는 rowid를 추출한다.
- rowid가 참조하는 데이터 블록을 엑세스 한다.
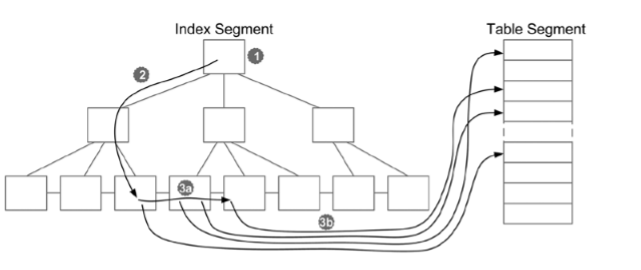 |
- index range scan에 의해 수행되는 물리적 읽기의 수는 첫 번째 키를 포함하는 리프 블록을 찾기 위해 액세스 하는 브랜치 블록의 수, 스캔되는 리프 블록의 수를 모두 더한 것과 동일하다.
- 이에 대해 optimizer_index_cost_adj 초기화 파라미터가 적용된 보정값까지 고려한 다음의 공식이 제공된다.
 |
SQL> ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ = 100;
SQL> SELECT * FROM t WHERE val1 = 11 AND val2 = 11;
-----------------------------------------------
| Id | Operation | Name | -----------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS BY INDEX ROWID| T |
|* 2 | INDEX RANGE SCAN | T_VAL2_I |
-----------------------------------------------
1 - filter("VAL1"=11)
2 - access("VAL2"=11)
SQL> ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ = 10;
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS BY INDEX ROWID| T |
|* 2 | INDEX RANGE SCAN | T_VAL1_I |
-----------------------------------------------
1 - filter("VAL2"=11) 2 - access("VAL1"=11)
SQL> ALTER INDEX t_val1_i RENAME TO t_val3_i;
SQL> SELECT * FROM t WHERE val1 = 11 AND val2 = 11;
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS BY INDEX ROWID| T |
|* 2 | INDEX RANGE SCAN | T_VAL2_I |
-----------------------------------------------
1 - filter("VAL1"=11) 2 - access("VAL2"=11)
OPTIMIZER_SECURE_VIEW_MERGING
- OPTIMIZER_SECURE_VIEW_MERGING 초기화 파라미터는 뷰 병합 및 조건 이돈 같은 쿼리 변환을 제어할 수 있다. 파라미터 기본값은 TRUE이다.
- FALSE로 설정할 경우 쿼리 옵티마이저는 쿼리 변환으로 인한 보안 문제의 발생 여부를 확인하지 않고 적용한다.
- TRUE로 설정하면 쿼리 변환으로 인해 보안 문제가 발생하지 않는 경우에 한해 쿼리변환을 적용한다.
CREATE TABLE t ( id NUMBER(10) PRIMARY KEY, class NUMBER(10), pad VARCHAR2(10) )
CREATE OR REPLACE VIEW v AS SELECT * FROM t WHERE f(class) = 1
CREATE OR REPLACE FUNCTION spy (id IN NUMBER, pad IN VARCHAR2) RETURN NUMBER AS
BEGIN dbms_output.put_line('id='||id||' pad='||pad);
RETURN 1;
END;
SQL> SELECT id, pad
2 FROM v
3 WHERE id BETWEEN 1 AND 5;
ID PAD
---------- ---------
1 DrMLTDXxxq 4 AszBGEUGEL
SQL> SELECT id, pad
2 FROM v
3 WHERE id BETWEEN 1 AND 5
4 AND spy(id, pad) = 1;
ID PAD
---------- ---------
1 DrMLTDXxxq
4 AszBGEUGEL
id=1 pad=DrMLTDXxxq
id=2 pad=XOZnqYRJwI
id=3 pad=nlGfGBTxNk
id=4 pad=AszBGEUGEL
id=5 pad=qTSRnFjRGb
SQL> SELECT id, pad
2 FROM v
3 WHERE id BETWEEN 1 AND 5
4 AND spy(id, pad) = 1;
ID PAD
---------- ---------
1 DrMLTDXxxq
4 AszBGEUGEL
id=1 pad=DrMLTDXxxq
id=4 pad=AszBGEUGEL
"데이터베이스 스터디모임" 에서 2017년에 "전문가를 위한 트러블슈팅 오라클 퍼포먼스(Second Edition)
" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/4388
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.