8.10 CHAR형식에서 개발 오류 제거를 통한 성능 향상
- 인덱스 대상 컬럼이 CHAR형식인 경우 SQL WHERE절에서 인덱스를 이용하지 못하는 형식으로, 컬럼이 비교되는 경우가 많아 성능이 저하된다.
8.10.1 CHAR로 지정된 인덱스 컬럼 변형으로 인한 성능저하
- 그림 8-32는 사용자 테이블에 사용자ID 가 CHAR1)으로 지정되어 있는 경우다. 만약 사용자ID가 'perfDB'라고 하는 ID를 가지고 정보를 조회하려고 하면 길이가 6바이트 이므로 그냥 'SELECT 사용자명 FROM 사용자 WHERE 사용자ID = 'perfDB'로 SQL문장을 작성하면 결과가 출력되지 않을 것이다.
- 사용자ID는 CHAR(10)이므로 테이블에는 'perfDB '로 되어 있고, 비교하는 값은 'perfDB'므로 결국 WHERE 'perfDB ' = 'perfDB'가 되어 다른 결과가 된다.
- 이런현상을 피하기 위해 개발자는 CHAR형식으로 지정된 컬럼에 공란을 없애는 함수를 사용한다.
- 그러면 '인덱스가 걸려 있는 컬럼에 변형이 발생되면 인덱스를 이용할 수 없다'는 전제에 의해 인덱스를 사용할수 없게 되고, 결과적으로 풀 테이블 스캔이 발생하여 선으이 저하된다.
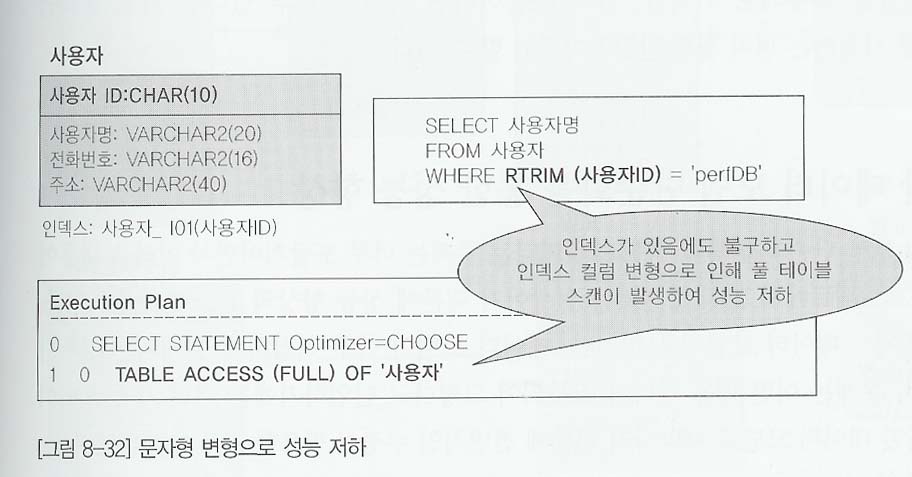
- 그림 8-23는 사용자ID에 인덱스가 걸려 있음에도 불구하고 인덱스 컬럼에 RTRIM(사용자ID)와 같이 변형되었기 때문에 인덱스를 이용하지 못하고, 풀테이블 스캔이 발생되었다.
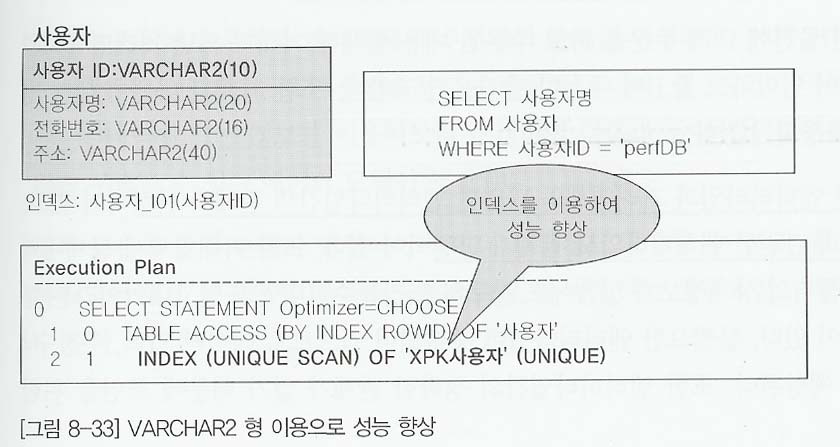
- 이를 가변적인 데이터 타입인 VARCHAR2 형식으로 데이터 타입을 수정하면 비록 VARCHAR2(10)으로 설정되어 있어도 6바이트의 데이터가 들어오면 6바이트만 점유한다.
- (CHAR처럼 공란을 차지하지 않으므로). 그로므로 SQL WHERE절에서 WHERE 사용자ID = 'perfDB'로 비교해도 원하는 결과를 얻을 수 있고 인덱스 변형이 일어나지 않아 정상적으로 인덱스를 이용할 수 있어 성능이 저하되지 않는다.
8.11 복잡한 데이터 모델 단순화를 통한 성능 향상
- 특히 업무구성 과 업무흐름에 따라 엔티티타입, 관계, 속성이 선정되어야 하는데, 업무흐름과는 별개로 화면 구성에 따라 데이터 모델을 화면 구성에 짜 맞추기 식으로 설계한 경우가 많아 데이터 모델이 복잡하게 생성된 경우가 많다.
- 이러한 복잡한 데이터모델의 특징은 통합되어야 할 엔티티타입이 여러군데 산재해 있고, 업무 흐름에 따라 표현되어야할 관계가 표현되지 않고 단절되어 있다.
- 관계가 단절됨에 따라 PK구성도 데이터 모델링에 의해 자연스럽게 생성되지 않고, 인위적으로 추가하거나 제거하게 되어 다른 테이블과의 관계속에서 데이터 무결성도 보장할수 없는 경우가 종종 발견된다.
8.11.1 엔티티타입이 통합되지 않고 관계가 단절된 복잡한 데이터 모델
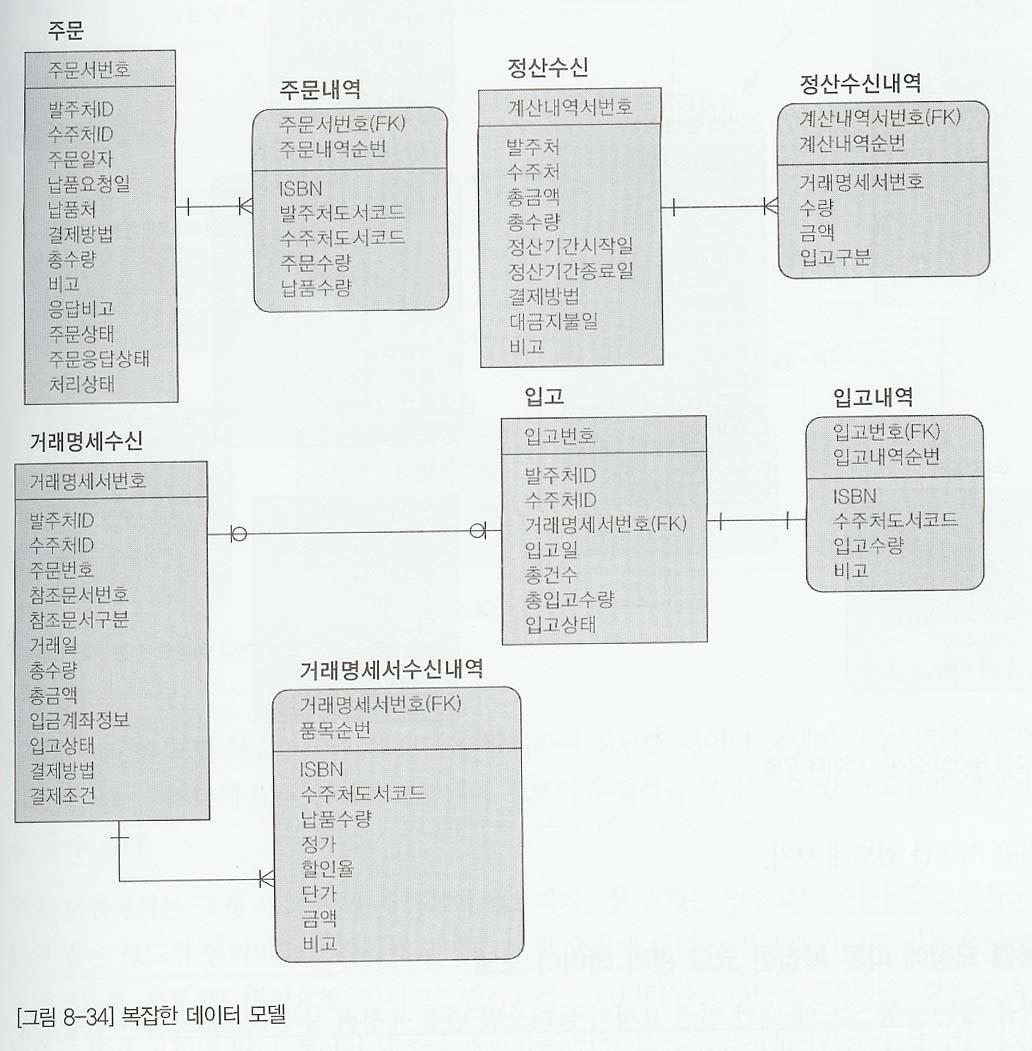
- 그림 8-34는 어떤 물건에 주문을 하고 주문된 내용에 대해 거래가 되면 거래명세서와 상세내용을 보내주어 입력하고 창고에 주문한 물건을 입고한다. 또한 거래된 내용에 대해 정산을 하는 업무로 구성되어 있다.
- 먼저 주문과 관련된 엔티티 타입과 거래명세서와 관련된 엔티티타입간의 관계가 단절 되어 있고, 거래명세서와 정산과 관련한 엔티티타입도 관계가 단절되어 있다. 또한 거래명세서 상세내역에 이미 거래가 된 물건의 상세정보가 있음에도 불구하고 정산수신내역과 입고내역이라는 불필요한 엔티티타입이 있다. 불필요한 엔티티타입이 중복되어 있으므로 데이터 입력, 수정, 삭제 시 성능 저하가 예상된다. 또한 엔티티타입간의 정확한 관계가 없기 때문에 조인을 위한 불필요한 반정규화를 하거나 다른 속성이 테이블 사이에 조인할 수 있는 지 분석하여 이용해야 할것이다.
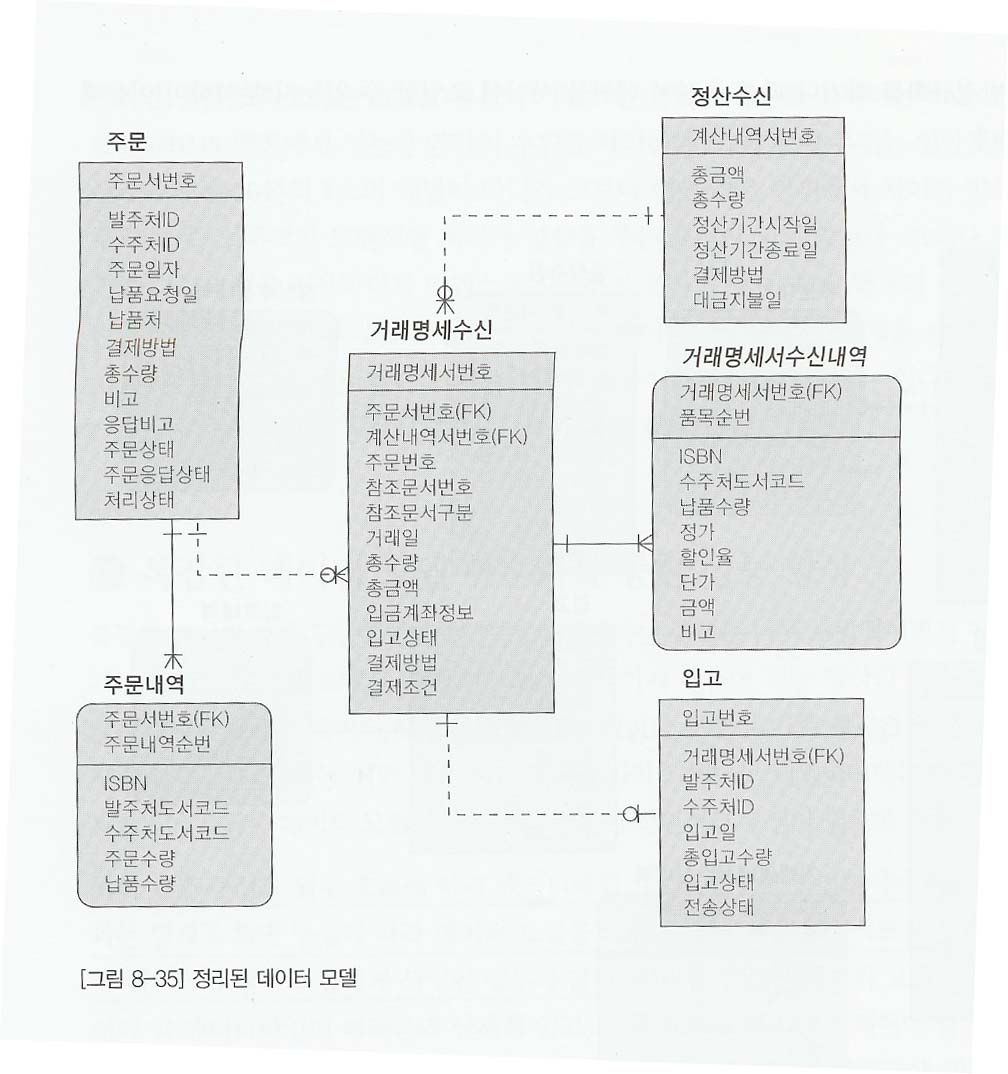
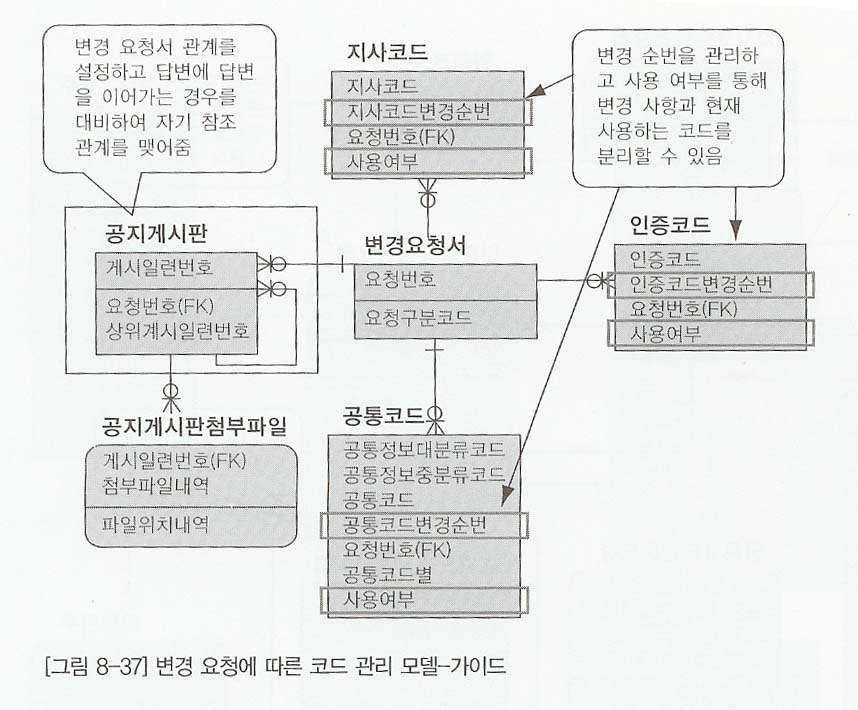
- 그림 8-34에서 주문과 거래명세서 쉰과의관계를 연결하고, 다시 거래명세서수신과 정산수신관계를 연결한다. 또한 불필요하게 중복된 입고내역,정산수신내역을 제거하거 거래명세서수신내역에 있는 정보를 이용하도록 수정하면 다음과 같이 간단하지만, 업무흐름에 명확하게 구별할수 있는 데이터 모델이 생성된다.
8.11.2 변경요청에 따른 복잡한 코드 관리 데이터 모델
- 공통 코드에 대한 변경요청이 들어오면 변경 요청된 상세코드를 포함한 변경요청서를 접수하고, 변경 작업이 수행되면 작업결과를 등록하고 공지게시판에 게시하는 업무 흐름을 가지고있다.
- 데이터 모델을 보면 변경 요청에 따라 공지게시판에 데이터가 발생하에도 불구하고 관계가 단절되어 있어 데이터 추적을 할 수 없는 모습이다. 또한 각각의 코드들에 대해 변경 요청이 왔을 때 변경된 코드 엔티티타입이 있고 또한 현재 값만 존재하는 코드 엔티티타입이 별도로 있으면서 관계는 단절된 모습이다. 이미 변경요청에 이력의 의미가 없음에도 불구하고 별도의 변경요청서 처리 이력을 생성하였으나 그다지 활용가치가 없으며, 속성의 내용이 변경요청서에 있어도 무방한 속성들이다.
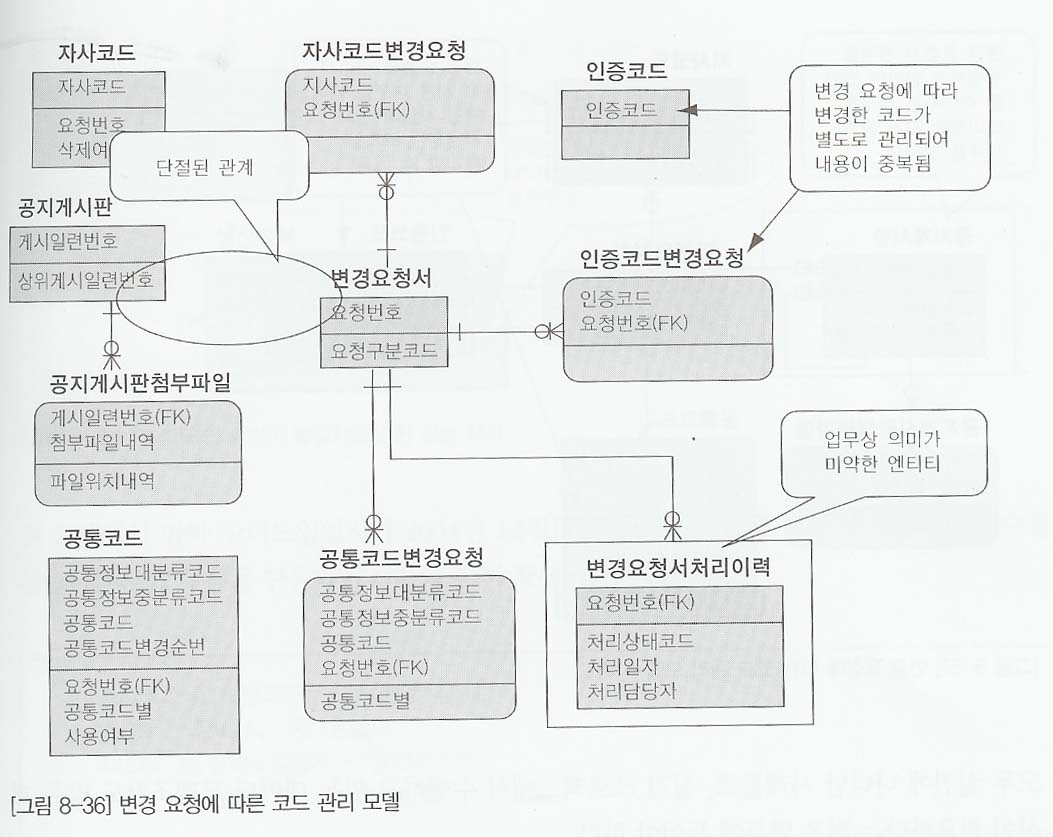
- 그림 8-36을 보면 복잡한 데이터 모델을 간단한 데이터 모델이 생성되었을 뿐만 아니라 모든 엔티티에 대해 관계가 연결되어 정보의 추적성을 보장할 수 있느 모델이 생성됨을 알수 있다.
- 위의 모델에서는 크게 세가지의 개선점이 필요하다. 첫번째 인증코드, 지사코드, 공통코드와 같은 코드성 엔티티타입 각각에 발생한 변경요청 엔티티타입을 하나로 통합하는 경우고 두번째는 변경요처에 따라 게시한 내용을 관리하는 변경 요청과 공지게시판의 관계를 표현하는 것이다.
- 마지막으로는 변경요청서는 보통 한 사람이 최종적으로 처리하는데 의미가 있으므로 변경요청서처리이력을 삭제해야 한다.
- 만약 변경요청서처리를 2~3단계에 걸쳐 결제하는 경우가 있다고 하더라도 각 단계에 대한 처리일자를 변경요청서에 위치시킴으로써 이와같은 사항을 관리할 수 있으므로 변경요청서처리이력이라는 엔티티타입은 별도로 관리할 필요가 없다.
- 그럼 이렇게 복잡한 데이터 모델을 단순하게 수정할수 있는가?
- 핵심적인 키워드는 '업무 흐름에 맞는 엔티티타입과 관계의 표현'이다.
8.12 일관성있는 데이터타입과 길이를 통한 성능향상
- 동일 컬럼에 데이터타입의 길이가 맞이 않을 경우 컬럼의 형변환이 발생하여 인덱스를 사용하지 못하는 경우가 발생하ㅡ로 반드시 일관서 있는 데이터타입과 길이를 유지하도록 한다.
8.12.1 데이터타입과 길이가 달라짐으로 인한 성능저하
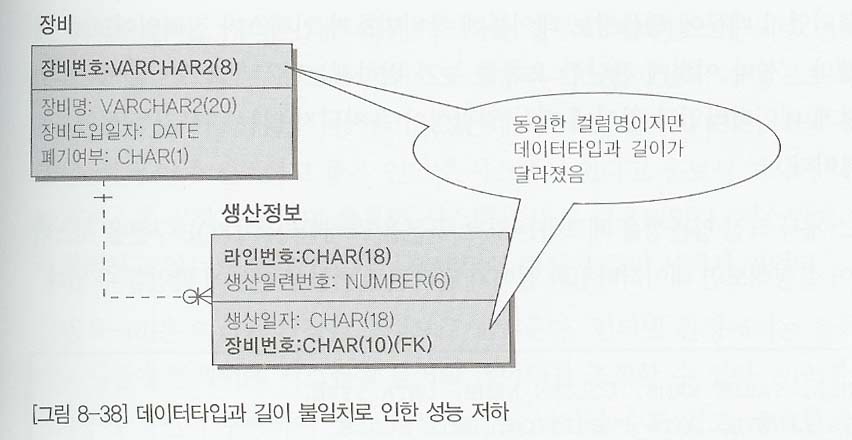
- 위 모델에서 만약장비도입일자가 2004년 12월 1일인 장비에 대해 라인 번호당 생산건수를 산출하는 SQL구문을 만든다면 다음과 같이 작성된다.
SELECT a.모델코드, a.모델명
FROM 장비 a, 생산정보 b
WHERE a.장비도입일자 = '20041201' AND a.장비번호 = b.장비번호
- 두 속성의 데이터 타입과 길이가 달라 원하는 결과가 나오지 않는다.
- 생산정보의 장비정보 컬럼에 인덱스가 걸려 있다고 해도 인덱스를 이용하지 못하는 현상이 발생되어 풀테이블 스캔이 된다.

- 오라클 데이터베이스에서 직접 일관성을 체크하는 SQL구문 소개
SELECT owner, table_name, column_name, data_type, data_length,
data_precision, data_scale
FROM dba_tab_columns
WHERE owner LIKE 'SC%' <== 테이블을 OWNER 지정
AND column_name IN (
SELECT column_name
FROM (SELECT DISTINCT column_name, data_type, data_length,
data_precision, data_scale
FROM dba_tab_columns
WHERE owner LIKE 'SC%')
-- WHERE owner LIKE 'SC%') <== 테이블을 OWNER 지정
GROUP BY column_name
HAVING COUNT (*) > 1)
- 데이터 모델링을 할 때 각 속성에 데이터타입과 길이를 직접 지정하면 앞에서와 같이 컬럼의 일관성이 결여되는 경우가 많으므로 가급적이면 도메인을 정의하여 각 속성에는 도메인을 할당하는 형식으로 데이터 모델링을 진행하는 것이 데이터 모델에 대한 일관성뿐만 아니라 데이터베이스의 성능 저하를 예방하는 좋은 방법이된다.
8.13 분산환경 구성을 통한 성능향상
- 중요 데이터 처리에 부하를 주는 배치처리/통계성 업무/인터넷 서비스등은 데이터베이스 분산환경 구성(데이터베이스 서버)을 통해 주요 업무 데이터베이스 서버에 걸리는 부하를 최소화하도록 배치한다.
8.13.1 인터넷 환경에서 분산환경을 통한 성능향상
- 인터넷 환경에서는 불특정 다수의 사람이 어느 시점에 한꺼번에 시스템에 들어와 데이터를 조회할 수 있다. 이러한 이유로 인해 업무 처리중에 자원이 부족하여 성능 저하 현상이 나타날 수도 있고, 중요한 업무 처리데이터와 외부에서 처리해야 하는 데이터가 공존하다 보면 데이터베이스 서버가 다운될 수있는 위험이 잠재되어 있다.
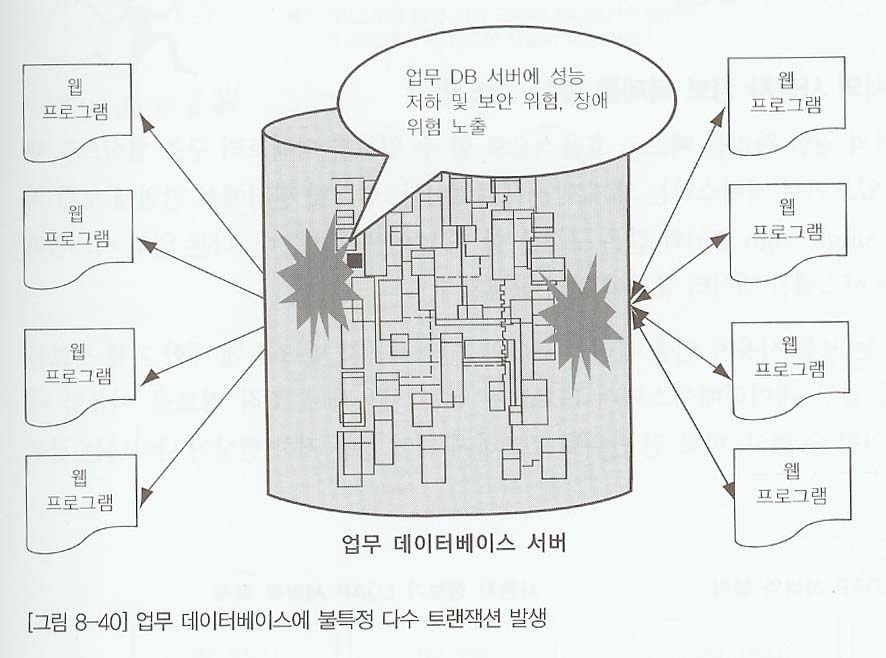
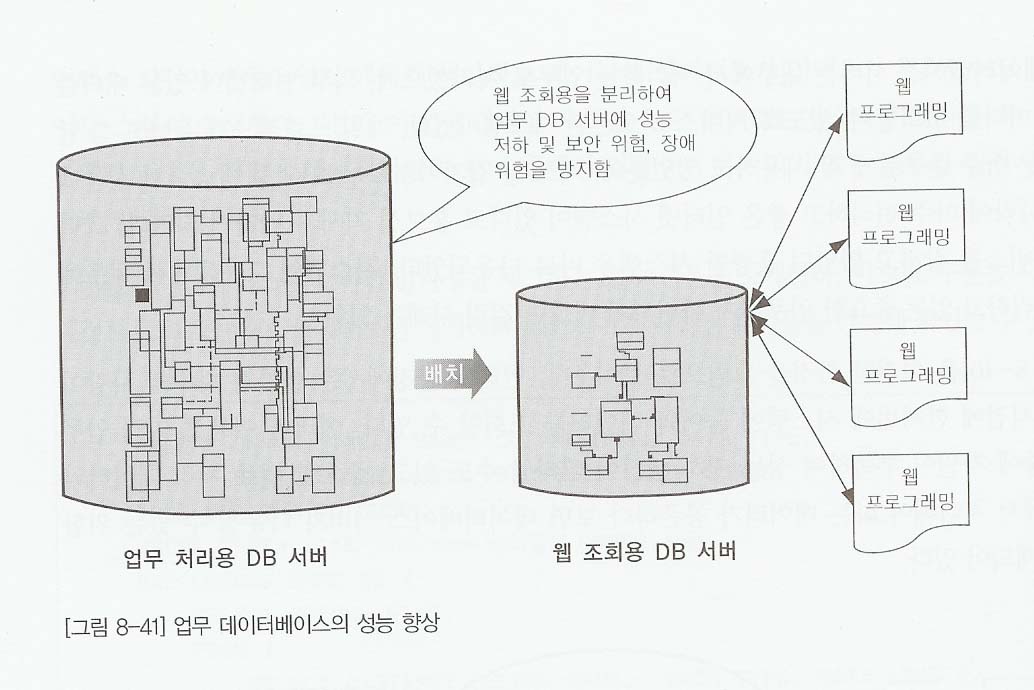
- 인터넷에서 불특정 다수의 이용자가 서버에 접근할 때 처리 가능한 데이터의수를 줄여주고 인터넷 사용자에 의해 데이터베이스 서버가 다운되더라도 업무서비스는 정상적으로 처리할수 있도록하기 위해 그림 8-14과 같이 서버를 분리하여 데이터베이스를 구성한다.
8.13.2 LDAP서버에서의 사용자 정보 복제를 통한 성능 향상
- LDAP서버에서는 보통 사용자인증 관리인 SSO와 기타 사용자 및 조직에 대한 기본정보를 관리하고, 다른 업무 데이터베이스에서 LDAP에 있는 사용자 조직 정보를 이용할때 FROM절에 조인될 수 없고, 바로 건 단위로 조회하게 되어 성능저하 현상이 나타나는 경유가 많다.
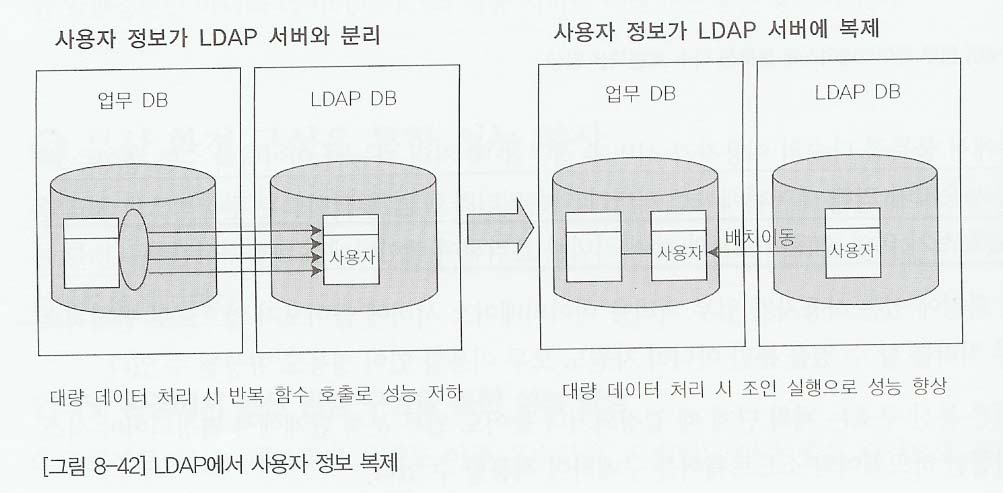
- 가급적 서용자 정보는 업무데이터베이스 영역에 데이터를 복제하도록 하고, 그에 따라 데이터를 동기화하여 사용해야 한다.