논리적인 데이터 모델에서 설계한 슈퍼타입/서브타입 모델을 물리적인 데이터 모델로 전환할때 주로 어떤 유형의 트랜잭션이 발생하는지 검증해야 한다.
물론 데이터량이 아주 적은 경우를 예로 들어 10만건도 되지 않는다면 그리고 시스템을 운영하는 중에도 증가하지 않는다면 트랜잭션의 성격을 고려하지 않고 전체를 하나의 테이블로 묶어도 좋다.
그러나 데이터양이 많고 지속적으로 많은 양이 증가한다면, 슈퍼타입/서브타입에 대해 물리적 데이터 모델을 변환하는 세가지 유형에 대해 세심하게 적용해야 한다.
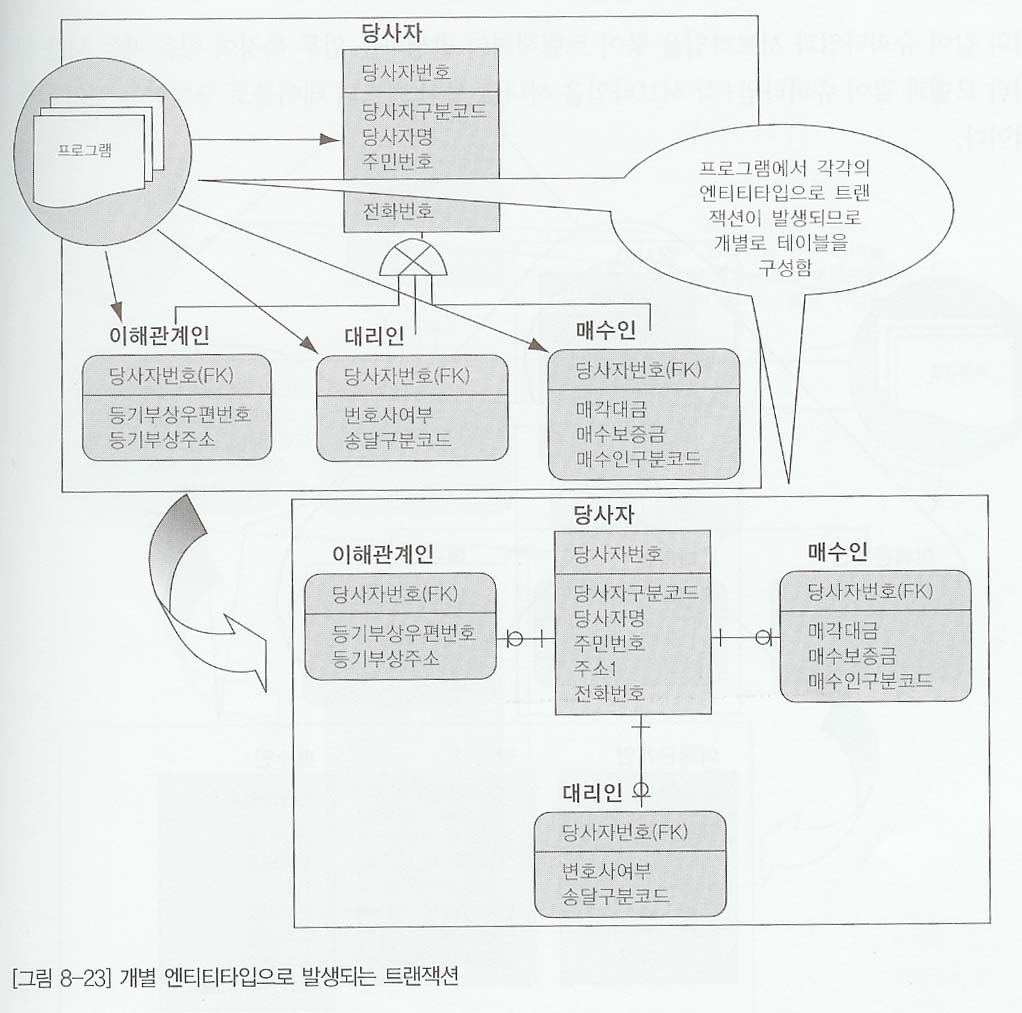
8.6.1 개별적으로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성
업무적으로 발생되는 트랜잭션으은 수퍼타입과 서브타입 각각에 대해 발생한다. 다음 업무화면을 보면 공통으로 처리하는 슈퍼타입인 당사자 정보를 미리 조회하고, 원하는 내용을 클릭하면 그에 따라 서브타입인 세부적인 정보, 즉 이해관계인 매수인, 대리인에 대한 내용을 조회하는 형식이다. 즉 슈퍼타입을 각 서브타입에 대한 기준역활을 하는 형식으로 사용할때 이러한 유형의 트랜잭션이 발생한다.
그림 8-22와 같이 슈퍼타입과 서브타입 각각에 대해 독립적으로 트랜잭션이 발생되면 슈퍼타입에도 꼭 필요한 속성만 주고, 서브타입에도 꼭 필요한 속성 및 자신의 타입에 맞는 데이터 만 갖도록 분리하여 1:1 관계로 만든다.
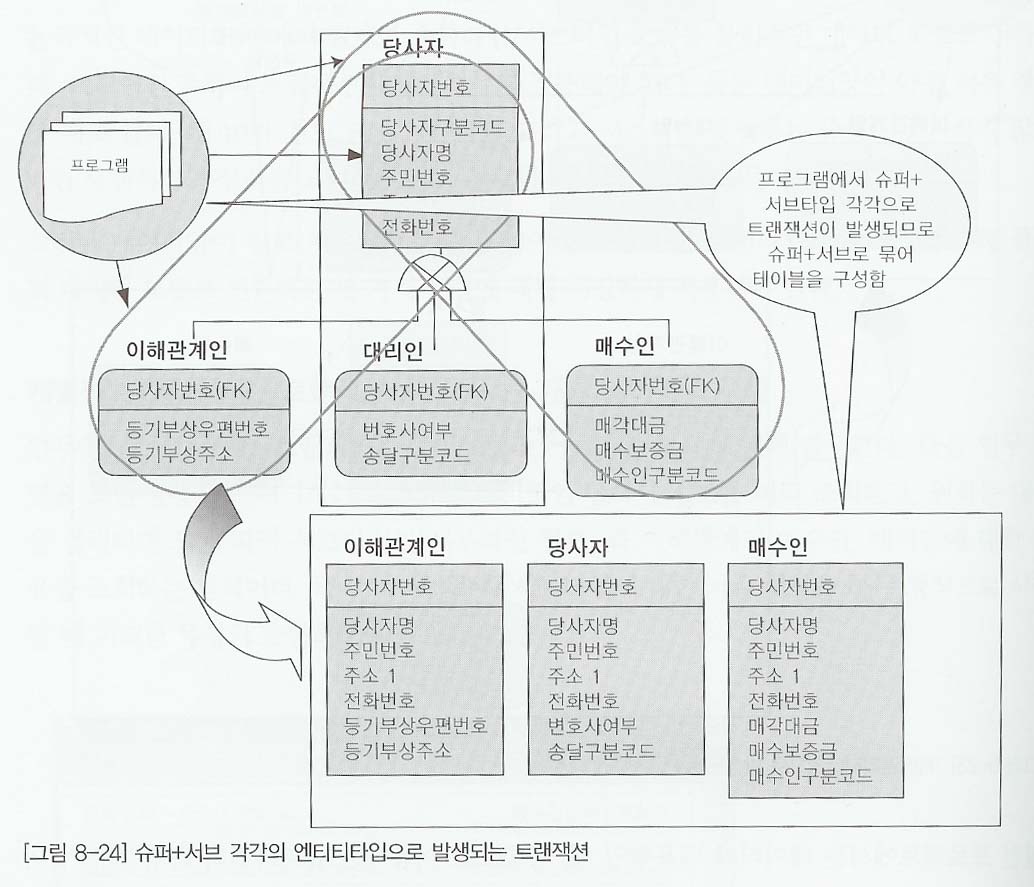
8.6.2 슈퍼타입+서브타입 대해 발생되는 트랜잭션에 대해서는 슈퍼타입+서브타입 테이블로 구성
만약 대리인 10만건, 매수인 500만건, 이해관계인 500만건의 데이터가 있다고 가정하고 슈퍼타입과 서브타입이 모두 하나의 테이블로 통합되어 있다고 가정하자. 매수인, 이해관계인에 대한 정보는 배제하고, 10만 건뿐인 대리인에 대한 데이터만 처리할 경우 다른 테이블과 같이 데이터가 1,010만 건이 저장되어 이쓴 곳에서 처리해야 하므로 불필요한 성능 저하 현상이 발생한다. 즉 대리인에 대한 처리가 개별적으로 많이 발생하는데, 매수인과 이해관계인의 데이터까지 포함되므로 최대 10만건을 읽어서 처리하는 업무가 1,010만 건을 처리해야 하는 경우가 발생할 수 있다.
이와 같이 슈퍼타입과 서브타입을 묶어 발생하는 업무 특징이 있을때는 다음 데이터 모델과 같이 슈퍼타입+각 서브타입을 하나로 묶어 테이블로 구성하는 것이 효율적이다.
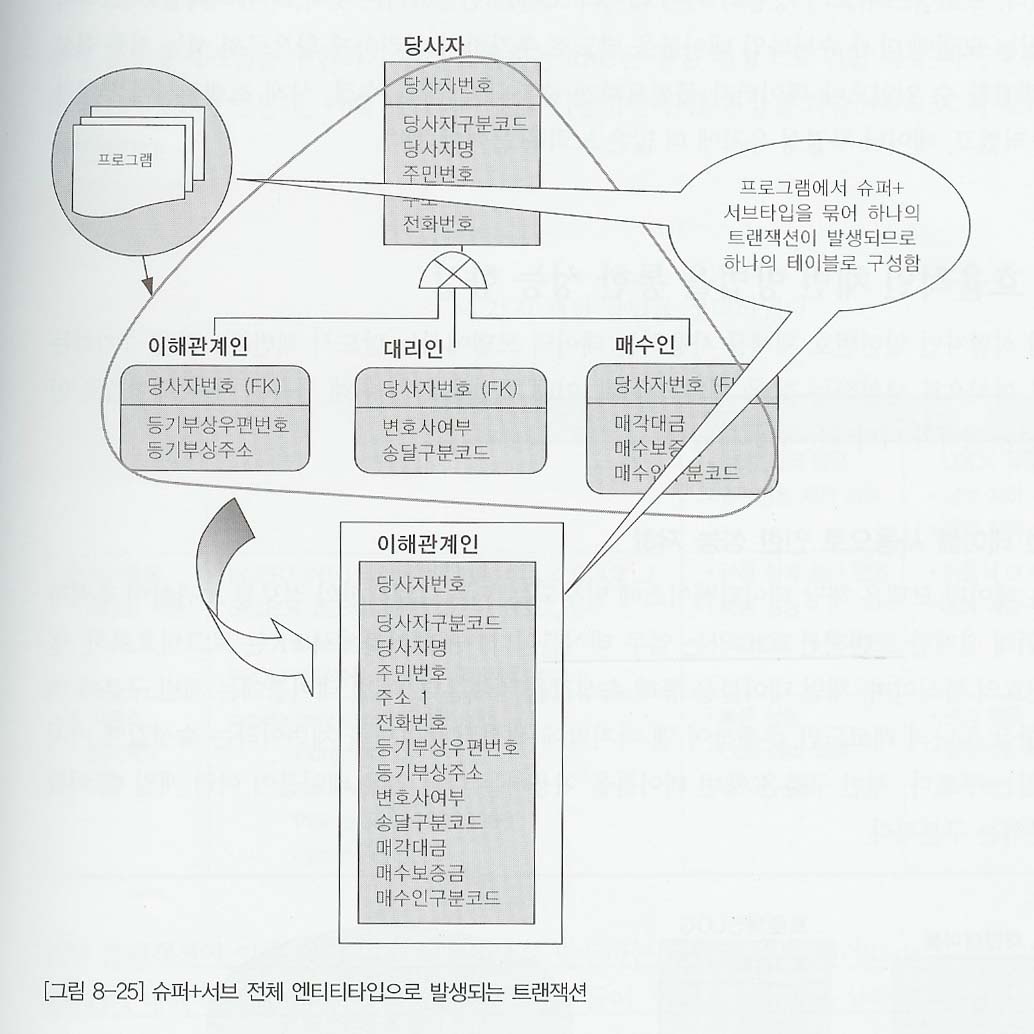
8.6.3 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성
대리인 10만건, 매수인 500만건, 이해관계인 500만건의 데이터가 있다고 하더라도 데이터를 처리할때 대리인, 매수인, 이해관계인을 항상 통합하여 처리한다고 하면 테이블을 개별로 분리해야 불필요한 조인을 유발하거나 또는 불필요한 Union All과 같은 SQL구문이 작성도어 성능이 저하된다. 비록 슈퍼타입과 서브타이브이 테이블을 하나로 묶었을때 각각의 속성별로 제약사항 (Null/Not Null, 기본값, 체크값)을 정확하게 지정하지 못할지라도 대용량이고 성능향상이 필요하다면 하나의 테이블로 묶어서 만들어 준다.