6.3 InnoDB 스토리지 엔진
6.3.1 MySQL 5.6 InnoDB
- XtraDB는 기본적으로 MySQL의 InnoDb 스토리지 엔진의 모든 기능을 그대로 유지하면서 추가적으로 성능이나 확장성이 개선된 스토리지 엔진이다.
6.3.1.1 영구적인 통계 정보
- MySQL 5.6의 InnoDB에서는 각 테이블의 통계 정보를 테이블로 관리하도록 보완되었다.
- 이전 버전에서는 메모리상에서만 관리 되었고, 이는 매우 자주변경되고 Master와 Slave에서 각각 다른 실행 계획을 만들 확률도 높았다.
- MySQL 5.6의 InnoDB에서는 테이블의 전체 레코드 수나 인덱스별로 Cardinality 정보를 mysql 데이터베이스의 innodb_index_stats와 innodb_table_stats 테이블로 관리하도록 개성되었다.
- innodb_stats_auto_recalc를 이용하여 자동 여부 결정 가능.
- MariaDB 10.0에서는 스토리지 엔진 레벨이 아닌 MariaDB 서버 차원에서 스토리지 엔진의 종류에 관계 없이 통계 정보를 mysql 데이터베이스에 있는 table_stats와 index_stats, column_stats테이블로 관리하고 있다.
- MariaDB 10.0에서는 인덱스되지 않은 컬럼에 대해서 통계정보, 히스토그램까지 관리 가능 하도록 개선되었다.
6.3.1.2 데이터 읽기 최적화
- MySQL 5.6의Index Condition Pushdown과 Multi Range Read가 지원된다.(TokuDB, Mroonga 스토리지 엔진은 지원가능 여부를 확인해야 함)
6.3.1.3 커널 뮤텍스(Kernel Mutex)
- InnoDB는 내부적으로 많은 공유 메모리 객체들을 가지고 있고, 이런 공유된 메모리 객체들은 수많은 클라이언트 커넥션들이 서로 경쟁하면서 점유했다가 다시 점유를 해제하면서 쿼리를 처리한다.
- 수많은 메모리 객체들이 각 클라이언트 커넥션들이 서로 동시에 점유하지 못하도록 동기화 처리를 하는데, 이런 목적으로 뮤텍스 또는 세마포어를 사용한다.
- kernel_mutex는 MySQL 소스코드에서 딱 용도가 들어맞는 뮤텍스나 세마포어가 없을 때 사용되는 공통 뮤텍스 같은 존재이다. 이런 형식으로 kernel_mutex가 사용되다 보니 InnoDB의 성능에서 웬만하면 kernel_mutex가 병목이 되고 확장성을 저해하는 요소 였다.
- MySQL 5.6의 InnoDb에서는 이렇게 범용으로 사용되던 kernel_mutex를 각 용도별로 더 세분화해서 별도의 Lock을 도입했다.
- 대표적으로 트랜잭션의 동시성 제어와 MVCC등의 메모리 구조체들은 모두 개별적인 읽고 쓰기 잠금으로 제어되도록 개선되었다.
6.3.1.4 멀티 스레드 기반의 언두 퍼지(Multi threaded purge)
- InnoDB는 MVCC(Multi Version Concurrency Control)와 롤백을 위해서 언두 영역(UNDO Space, Rollback Segment)를 별도로 관리하고 있다.
-- 데이터 INSERT
INSERT INTO member(m_id, m_name, m_area) VALUES (12, '홍길동', '서울');
COMMIT;
-- 데이터 UPDATE
UPDATE member SET m_area='경기' WHERE m_id=12;
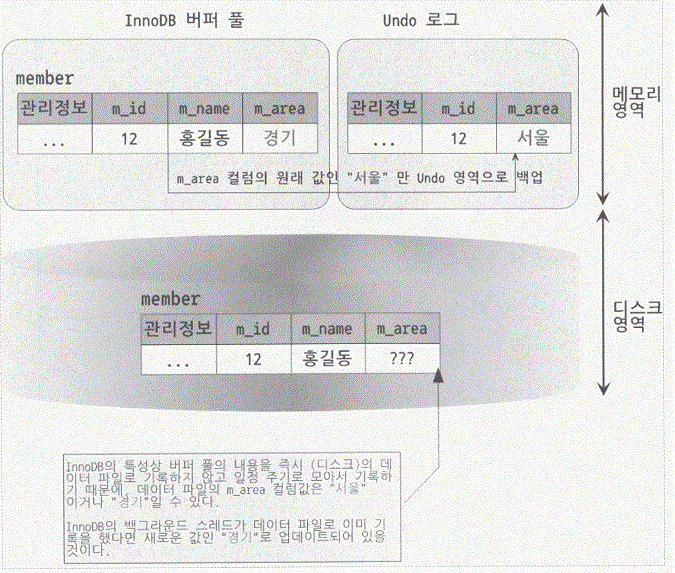
- UPDATE 문장이 실행된 후 COMMIT이나 ROLLBACK이 실행되기 전의 InnoDB 버퍼 풀과 디스크의 상태를 보여 주고 있다.
- COMMIT을 수행하면 버퍼 풀의 변경된 내용이 영구적으로 적용되며, ROLLBACK 을 수행하면 언두 로그에 있던 "서울"이라는 정보를 가져와서 InnoDB의 버퍼 풀에 있는 레코드 정보를 원래대로 되돌리는 것이다.
- 많은 클라이언트 커넥션에서 데이터를 변경하면, 언두로그 영역에 수많은 변경 전 정보들이 쌓이게 되는데, 이렇게 쌓인 언두 로그를 언젠가는 삭제를 하고 빈 공간을 마련해야 이후의 변경 이력들을 계속 저장 할 수 있다. 이때 언두 로그를 삭제하는 작업을 언두 퍼지(Undo Purge)라고 한다.
- MySQL 5.1 버전까지는 언두 퍼지 작업이 마스터 스레드라고 불리는 InnoDB의 메인 스레드에서 처리되었다. 그러나 InnoDB 마스터 스레드는 언두 퍼지 이외에도 많은 작업들을 수행하는 스레드여서 언두 퍼지가 제대로 이루어지지 못하거나 마스터 스레드의 다른 작업들이 지연되는 현상이 발생했었다.
- MySQL 5.5 버전의 InnoDB에서는 언두퍼지를 전담하는 별도의 스레드를 도입하였는데, 이때까지 언두 퍼지를 위해서 단 하나의 스레드만 사용할 수 있다.
- MySQL 5.5 버전까지는 innodb_purge_threads = 1 또는 0으로만 설정 가능 했다. "0"으로 설정하면 전용의 언두 퍼지 스레드를 사용하지 않고, InnoDB 마스터 스레드에서 언두를 퍼지하게 되고, "1"로 설정하면 하나의 언두 퍼지 전용 스레드가 활성화 되는 것이다.
- MySQL 5.6 버전의 InnoDB에서는 innodb_purge_threads 시스템 변수에 1 이상의 값을 설정하여 여러 개의 언두 퍼지 스레드를 동시에 사용할 수 있도록 개선되었다.
6.3.1.5 독립된 플러시 스레드
- 사용자가 DML 문장을 실행하면 변경된 데이터는 먼저 리두로그에 기록되면서 디스크에 영구적으로 남게 된다.
- InnoDB 스토리지 엔진은 실제 테이블의 데이터를 메모리(InnoDB 버퍼 풀) 상에서만 변경하게 된다.
- 여기까지 완료되면 MySQL 서버는 클라이언트의 사용자에게 쿼리가 실행 완료되었다고 리턴 한다.
- InnoDB 버퍼 풀에 변경된 데이터를 우리는 "Dirty"라고 하고, 이런 Dirty 데이터를 디스크로 영구히 기록하는 작업을 "Flush"라고 한다.
- 위의 그림에서 m_area 컬럼의 값이 "서울"에서 "경기"로 변경되었는데, 이 "경기"로 변경된 레코드를 담고 있는 페이지(InnoDB 버퍼풀의 관리 단위로서 일반적으로 16KB)가 더티 페이지가 되는 것이다.
- MySQL 5.5 버전의 InnoDB에서는 마스터 스레드가 다른 작업들을 수행하면서 더티 페이지를 디스크로 플러시 하도록 되어 있었다.
- MySQL 5.6에서는 InnoDB 버퍼 풀의 더테 페이지를 디스크로 Flush 하는 전용의 스레드를 도입하였다.
6.3.1.6 가변 페이지 사이즈
- MySQL 5.5 버전까지는 InnoDB의 페이지 사이즈는 16KB로 고정되었으며, 이를 조정하기 위해서는 MySQL 서버를 다시 컴파일 해야 한다.
- 사이즈가 작은 레코드를 2~3건씩 읽어가는 쿼리가 아주 빈번하게 실행되는 시스템에서는 16KB 페이지는 사실 많이 큰 편이다. 실제 레코드 3~40바이트를 읽기 위해서 16KB 페이지 단위로 디스크에서 읽고 그 데이터가 변경되면 16KB를 통째로 디스크에 플러시하는 것은 상당히 불합리할 수도 있다.
- MySQL 5.6의 InnoDB 스토리지 엔진에서는 데이터나 인덱스 페이지의 크기를 기존 16KB에서 4KB나 8KB로 조정할 수 있게 되었다.
- PK나 Index를 통해서 1~2건의 레코드를 읽는 단순한 형태의 쿼리들이 아주 빈번하게 실행되는 MySQL 서버라면 4KB를 쓰는것이 유리\!\!
6.3.1.7 테이블 스페이스 복사(Transportable tablespace)
- MySQL 5.5의 InnoDB에서도 테이블 스페이스를 복사할 수 있는 기능은 제공되었으나, 자신의 MySQL 서버로부터 백업된 테이블 스페이스 파일(*.ibd)만 복사할 수 있었다.
- InnoDB 스토리지 엔진은 내부적으로 모든 InnoDB 테이블의 메타 정보를 가진 딕셔너리 정보가 있는데 이 딕셔너리 정보에는 모든 InnoDB 테이블마다 고유의 ID가 할당되어서, MySQL 5.5의 InnoDB에서는 ID가 일치하지 않으면 다른 서버에서 ibd 파일을 복사해서 Import 하는것이 불가능 했다.
CREATE TABLE tb_trans (
fd1 INT NOT NULL,
fd2 VARCHAR(20),
PRIMARY KEY(fd1)
) ENGINE=InnoDB;
INSERT INTO tb_trans VALUES(9, 'Matt');
commit;
-- 테이블 스페이스 익스포트
mysql> FLUSH TABLES tb_trans FOR EXPORT;
-- 익스포트된 테이블 스페이스 파일 복사
$ cp /data/test/tb_trans.ibd /backup/
$ cp /data/test/tb_trans.cfg /backup/
-- 테이블 잠금 해제
mysql> UNLOCK TABLES tb_trans;
-- 테이블 스페이스 Import
mysql> ALTER TABLE tb_trans DISCARD TABLESPACE;
$ cp /backup/tb_trans.cfg /data/test/
$ cp /backup/tb_trans.ibd /data/test/
mysql> ALTER TABLE tb_trans IMPORT TABLESPACE;
- FLUSH TABLES tb_trans FOR EXPORT 명령을 실행하면 MySQL 서버는 tb_trans 테이블을 변경하지 못하도록 InnoDB 스토리지 엔진은 테이블 잠금을 걸고 tb_trans 테이블 스페이스를 다른 MySQL 서버에서 임포트할 수 있도록 \*.cfg 파일을 생성한다.
- FLUSH TABLES..FOR EXPORT가 실행되면 해당 테이블에 명시적인 잠금이 걸리게 되므로 다른 사용자는 그 테이블의 레코드를 읽을 수는 있지만 절대 변경할 수는 없다.
- ALTER TABLE..DISCARD TABLESPACE 를 이용하여 기존 테이블이 가지고 있던 테이블 스페이스를 삭제 한다.
- 테이블 스페이스를 익스포트해서 임포트할 때 각각의 테이블의 이름은 달라도 되지만 반드시 동일한 테이블 구조와 스토리지 엔진인 경우에만 가능하다.
6.3.1.8 독립된 언두 스페이스
- MySQL 5.5 버전까지의 InnoDB에서 언두 영역은 시스템 테이블 스페이스의 일부 영역을 사용하고 있었다.
- MySQL 5.6 버전의 InnoDB에서는 언두 영역을 시스템 테이블 스페이스가 아닌 별도의 공간에 저장할 수 있도록 3개 시스템 설정 변수가 도입 되었다.
- innodb_undo_directory : InnoDB의 언두 로그가 저장되는 언두 영역이 저장될 디렉토리를 설정한다. innodb_undo_directorydml의 Default값은 "." 인데, 이는 MySQL 5.5에서와 같이 언두 영역이 시스템 테이블 스페이스를 사용하는 것을 의미한다.
- innodb_undo_tablespaces : 언두 영역도 테이블과 마찬가지로 파티션 하듯이 여러개의 테이블 스페이스로 분리해서 생성할 수 있다. 최대 126개까지 생성할 수 있고, innodb_undo_tablespaces = 6으로 설정되었다면 innodb_undo_directory 설정 값에 지정된 언두 디렉토리에 "undo" 라는 이름으로 시작하는 팡ㄹ이 6개가 생성되는 것이다. 만약 언두 영역 사용에 대해 경합이 심하다면 이 값을 증가시켜서 언두 세그먼트에 대한 뮤텍스 경합을 줄일 수 있다.
- innodb_undo_logs : 언두 세그먼트의 개수를 지정하는 값. InnoDB에서는 최대 1023개의 쓰기 트랜잭션이 하나의 언두 세그먼트를 공유하면서 사용할 수 있다. 이 값은 최대 128까지 설정 가능하다. innodb_undo_logs=20 으로 설정한다면 최대 20460(1023 * 20)개의 쓰기 트랜잭션이 실행될 수 있다는 것이다. 한번 증가된 언두 세그먼트의 개수는 데이터베이스를 새로 생성하지 않는 이상 줄일 수 없기 때문에 처음에는 작은 값부터 시작해서 언두 세그먼트에 대한 경합이 심한 경우 증가시켜 주는 것이 좋다.
6.3.1.9 읽기 전용 트랜잭션(Read-Only transaction) 최적화
- MySQL 5.5 버전까지의 InnoDB 스토리지 엔진에서는 모든 쿼리에 대해서 트랜잭션이 자동으로 시작되고 종료되는 형태로 처리 되었다.
- 트랜잭션이 보장되기 위해서는 내부적으로 트랜잭션 ID를 발급하고 트랜잭션 유지에 대한 메모리 구조체들을 매번 할당했어야 했다.
- MySQL 5.6 버전의 InnoDB에서는 다음 두 가지 경우에 대해 읽기 전용 트랜잭션으로 처리할 수 있도록 개선되었다.
- "START TRANSACTION READ ONLY"로 시작된 트랜잭션
- AutoCommit이 활성화된 상태에서 SELECT 쿼리만 실행된 트랜잭션(SELECT..FOR UPDATE 제외)
6.3.1.10 버퍼 풀 덤프 & 로드
- MySQL 5.5 버전에서는 MySQL 서버가 재시작되면 InnoDB에서 버퍼 풀의 모든 내용이 비어 있는 상태로 시작 되었다.
- MariaDB에서는 5.5버전부터 버퍼풀의 데이터를 덤프하고 로딩하는 기능이 제공되었다.
6.3.1.10.1 MariDB 5.5의 버퍼 풀 덤프 & 로딩
- MariaDB 5.5버전에서는 innodb_auto_lru_dump 시스템 변수를 사용해서 MariaDB 서버가 종료될 때 XtraDB의 버퍼 풀 내용을 모두 파일로 덤프해 두고, 다시 MariDB 서버가 시작될 때 파일로 기록된 버퍼 풀 정보를 다시 XtraDB 버퍼 풀로 읽어 들이는 작업을 자동으로 수행하도록 할 수 있다.
- innodb_auto_lru_dump 시스템 변수의 값이 0이 아닌 값이 설정되면 버퍼 풀의 덤프와 로딩이 자동으로 수행되었다.
MariaDB> SELECT * FROM information_schema.XTRADB_ADMIN_COMMAND /*\!XTRA_LRU_DUMP*/;
MariaDB> SELECT * FROM information_schema.XTRADB_ADMIN_COMMAND /*\!XTRA_LRU_RESTORE*/;
- XtraDB는 버퍼 풀의 데이터 페이지 목록(LRU 리스트)를 MariaDB 서버의 데이터 디렉토리에 ib_lru_dump라는 이름의 파일로 기록한다.
- XtraDB 버퍼 풀을 다시 XtraDB의 버퍼 풀로 로드한다.
- XtraDB 버퍼 풀을 덤프하라는 명령이 실행되면 XtraDB 스토리지 엔진은 버퍼 풀의 캐싱된 모든 페이지에 대해서 space_id와 page_no 값만을 모아서 space_id와 page_no순서대로 정렬해서 ib_lru_dump 파일로 기록한다.
- 나중에 디스크에서 해당 테이블의 데이터 페이지를 읽을 때 Sequential I/O로 한번에 많은 데이터를 읽어서 빠르게 로딩하기 위해서 정렬을 하여 저장한다.
- space_id는 테이블 스페이스를 식별하는 값이며 page_no는 하나의 테이블 스페이스에서 특정 페이지(블록)을 식별하는 값이다.
- innodb_blocking_buffer_pool_restore = ON으로 설정되면 버퍼 풀 로딩 중에는 사용자 쿼리를 실행할 수 없게 된다. Default는 "OFF"이고, 이는 사용자 쿼리가 Blocking 되지 않는다.
6.3.1.10.2 MySQL 5.6의 버퍼 풀 덤프 & 로딩
- innodb_buffer_pool_dump_now : "ON"으로 설정하면 즉시 InnoDB 버퍼 풀의 내용을 덤프한다. 버퍼 풀의 덤프가 완료되면 이 변수 값은 다시 자동으로 OFF로 재설정된다.
- innodb_buffer_pool_load_now : "ON"으로 변경하면 innodb_buffer_pool_filename 시스템 설정 변수에 지정된 파일을 읽어서 데이터와 인덱스 페이지들을 InnoDB 버퍼 풀로 적재한다. 버퍼 풀의 적재가 완료되면 OFF로 재설정 된다.
- innodb_buffer_pool_dump_at_shutdown : "ON"으로 설정되면 MySQL 서버가 셧다운 될 때 InnoDB 버퍼풀의 내용을 파일로 덤프한다.
- innodb_buffer_pool_dump_load_at_startup : "ON"으로 설정되어 있으면 MySQL 서버가 시작될 때 innodb_buffer_pool_filename 시스템 설정 변수에 지정된 파일을 읽어서 데이터와 인덱스 페이지들을 InnoDB 버퍼 풀로 적재한다.
6.3.1.11 리두 로그 사이즈
- InnoDB 서버 크래시에 대한 데이터 안전을 보장하면서 성능을 향상시키기 위해 커밋된 트랜잭션 내용을 먼저 로그 파일로 기록하고 실제 데이터 파일의 변경은 나중에 모아서 배치형태로 처리한다.
- 로그를 리두 로그라고도 하며 WAL(Write Ahead Log) 로그라고도 하는데, InnoDB의 로그는 여러 개의 파일이 하나의 논리적 저장소처럼 순환되면서 사용된다.
- innodb_log_file_size : 각 로그 파일의 사이즈를 설정한다. 이미 사용되고 있는 리두 로그 파일의 사이즈를 변경하기 위해서는 Shutdown 후에만 가능하다.
- innodb_log_files_in_group : 로그 파일의 개수를 몇 개로 생성할지를 결정하는 변수. InnoDB 스토리지 엔진이 최종적으로 사용 가능한로그 영역은 innodb_log_file_size * innodb_log_files_in_group 만큼이 되는 것이다.
- innodb_log_group_home_dir : InnoDB 리두 로그를 생성할 디렉토리를 설정하는 변수이며, 명시하지 않으면 MysQL 서버의 데이터 디렉토리에 생성한다.
- MySQL 5.5의 InnoDB는 로그 파일의 최대 사이즈를 4GB 까지만 사용할 수 있었다. InnoDB 로그의 공간이 클수록 InnoDB 버퍼 풀에는 많은 더티 페이지들이상주할 수 있게 되고, 그 결과 InnoDB 버퍼 풀의 더티 페이지가 조금 더 배치 형태로 디스크로 플러시 될 수 있게 된다.
- MySQL 5.6의 InnoDB 부터는 innodb_log_file_size * innodb_log_files_in_group의 조합을 512GB 까지 설정할 수 있다.
6.3.1.12 리두 로그 크기 변경
MariaDB 5.5나 MySQL 5.5에서 리두 로그 파일 크기를 변경하는 과정
- MariaDB 서버에 로그인 후 "SET GLOBAL innodb_fast_shutdown=0" 실행 (클린 셧다운을 할 수 있도록 변경)
- MariaDB 서버 종료
- MariaDB 서버의 에러 로그 파일을 열어서 정상적으로 셧다운 되었는지 확인
- 기존의 리두 로그 파일을 별도 디렉토리로 백업
- MariaDB 서버의 설정 파일을 변경
- MariaDB 서버 시작
- 에러 로그와 리두 로그 디렉토리에서 사이즈 변경됐는지 확인
- 혹시 셧다운 직전의 데이터 존재 여부 확인
- 백업해 두었던 리두 로그 파일 삭제
MariaDB 10.0과 MySQL 5.6에서 리두 로그 파일 크기 변경하는 과정
- MariaDB 서버의 설정 파일 변경
- MariaDB 서버 재시작
- 에러 로그 파일과 리두 로그 디렉토리의 파일 사이즈 확인
6.3.1.13 데드락 이력
- MySQL 5.5 버전의 InnoDB에서는 데드락이 발생해도 데드락 내용은 "SHOW ENGINE INNODB STATUS" 명령 결과의 DEADLOCK 섹션에서만 확인 가능
- 데드락이 여러번 발생하면 이전 이력은 모두 삭제되고, 가장 마지막에 발생한 데드락 내용만 조회 가능
- MySQL 5.6의 InnoDB에서는 innodb_print_all_deadlocks = ON으로 설정하면 에러 로그 파일에 기록 할지 말지 선택한다.
6.3.2 더티 페이지 플러시
- InnoDB에서는 사용자의 쿼리를 처리한 결과 메모리 공간에 있는 버퍼 풀의 데이터는 변경되었지만, 아직 디스크로 기록되지 않은 페이지를 더티 페이지라고 하고, 이런 더티 페이지를 디스크로 기록하는 것을 플러시라고 표현한다.
- InnoDB의 더티 페이지 플러시는 크게 플러시 리스트 플러시와 LRU 플러시 두 종류로 나누어 볼 수 있다.
- LRU_list : 버퍼 풀에서 자주 사용되지 않는 페이지들의 목록을 관리
- Flush_list : 변경된 페이지들의 목록을 시간 순서대로 관리
6.3.2.1 Flush_list Flush
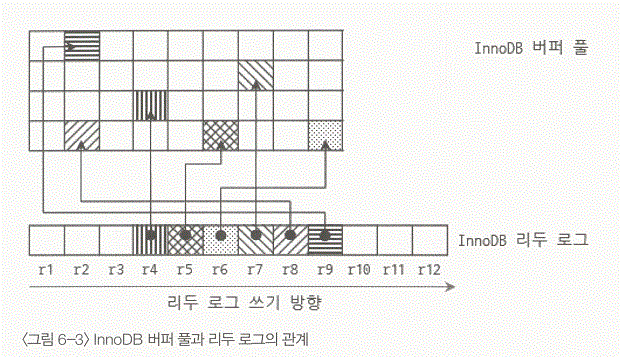
- InnoDB의 리두로그는 여러개의 파일로 구성되지만 InnoDB 스토리지 엔진은 내부적으로 이 파일들을 모두 모아서 하나의 연속된 공간으로 인식한다.
- 위의 그림에서 로그는 r1 슬롯에서 r2 슬롯으로 순서대로 사용된다고 가정하다.
- r4 슬롯부터 r99 슬롯까지 사용되고 있으며, 각각의 리두 로그 슬롯은 InnoDB 버퍼 풀에서 각 페이지와 화살표(리두 로그 슬롯에 의해서 변경된 InnoDB 버퍼 풀의 더티 페이지)로 연결되어 있다.
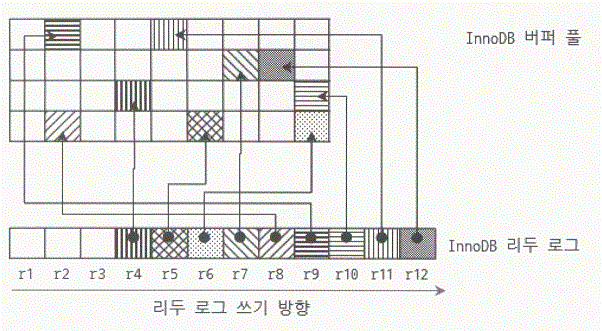
- 리두 로그 슬롯이 3개 더 사용
- 3개의 UPDATE 문장이 더 실행되어 리두 로그 r10 슬롯부터 r12 까지 사용된 상태의 InnoDB 버퍼 풀과 리두 로그 상태이다.
- r4번 슬롯이 지금 InnoDB 스토리지 엔진에서 가장 오래된 리두 로그 슬롯이며 r12는 가장 최근에 발생한 변경 내역을 저장하고 있는 슬롯이다.
- InnoDB 스토리지 엔진은 오래된 리두 로그 슬롯을 적절한 시점에 비워주어야 한다.
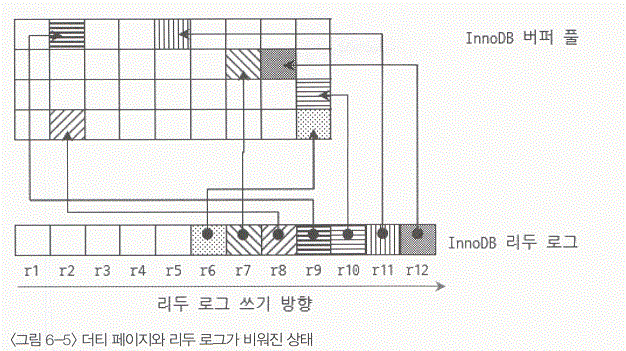
- r4번 슬롯과 r5 슬롯이 비워진 상태를 표현 했다.
- 이때 r4번과 r5번 슬롯과 관계를 가지고 있던 InnoDB 버퍼 풀의 더티 페이지가 없어졌다.
- RDBMS의 리두 로그 작동방식 특성상 리두 로그와 더티 페이지 중에서 항상 리두 로그가 먼저 디스크로 플러시되어야 한다.
- 그리고 InnoDB 버퍼 풀에서 더티 페이지가 디스크로 완전히 플러시되어야만 그 더티 페이지와 연관을 가지고 있던 리두 로그 슬롯이 재사용될 수 있다.
- 이때 버퍼 풀에서 더티 페이지들을 빠르게 찾도록 하기 위해서 더티 페이지들의 변경 시간 순서대로 목록을 관리하는 이를 Flush_List라고 한다.
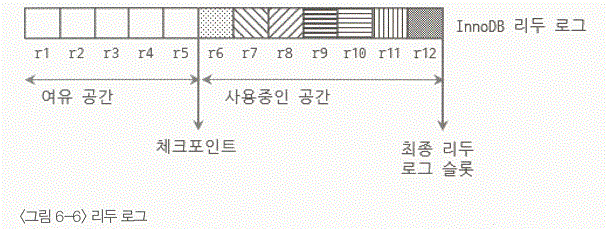
- 현재 상태에서 리두 로그의 여유 공간과 사용공간을 구분 했다.
- 사용 중인 공간 중에서 가장 오래된 리두 로그 슬롯은 가장 최근의 체크포인트가 발생한 지점이다.
- "(가장 최근의) 체크 포인트" 지점과 "최종 리두 로그 슬롯"까지의 길이를 InnoDB 에서는 체크포인트 에이지(Checkpoint age)라고 한다.
- 리두로그는 최대한 여유 공간을 많이 확보해야 하며, InnoDb 버퍼 풀의 더티 페이지는 오랜 시간 동안 유지되면 될수록 효율적이다.
- 가장 좋은 방법은 리두 로그의 여유 공간을 적절히 유지하면서 버퍼 풀의 더티 페이지를 최대한 유지하는 것이다.
6.3.2.2 LRU 리스트 플러시
- InnoDB 버퍼 풀이 모두 인덱스나 데이터 페이지로 채워져 있을때, InnoDB 버퍼 풀에 빈 공간이 남아 있지 않다.
- 이 상태에서 쿼리가 요청이 되면, 버퍼 풀에 공간이 없으므로 버퍼 풀에 적재된 몇 개의 페이지를 버퍼 풀에서 제거하고 빈 공간을 만들어야 한다.
- LRU_list는 최근에 가장 사용되지 않은 페이지들의 목록을 의미.

- LRU_list는 MRU영역과 LRU 영역으로 사용된다. innodb_old_blocks_pct 값을 이용하여 기준점의 값을 변경할 수 있다.
- InnoDB 스토리지 엔진은 LRU_list를 참조해서 가장 사용되지 않은 LRU 리스트의 끝에 있는 페이지 몇 개를 버퍼 풀에서 제거한다.
- 만약 제거해야할 페이지 3개중 2개가 더티 페이지라면, 먼저 디스크에 Fluiish 하고 제거해야 한다.
- InnoDB의 리두로그와 전혀 부관하게 버퍼 풀에 새로운 페이지를 읽어 드링기 위해서 Disk로 Flush할 경우 이를 LRU_flush 라고 한다.
6.3.2.3 InnoDB와 XtraDB의 더티 플러시
- XtraDB의 더티 페이지 플러시의 기본 작동 방식은 InnoDB와 같다.
- InnoDB와 XtraDB에서는 마지막 체크포인트가 발생한 시점의 리두 로그 위치(LSN, Log Sequence Number)에서부터 마지막 리두 로그 슬롯의 위치까지의 길이를 체크포인트 에이지(Checkpoint Age)라고 한다.
- InnoDB와 XtraDB 모두 리두 로그의 전체 공간 크기와 체크 포인트 에이지의 길이를 이용해서 플러시를 실행해야 할 더티 페이지의 개수를 결정한다.
- 체크 포인트 에이지가 얼마나 되는지에 따라서 XtraDB나 InnoDB의 쿼리가 일부만 블로킹되거나 전부 블로킹 될 수도 있다.
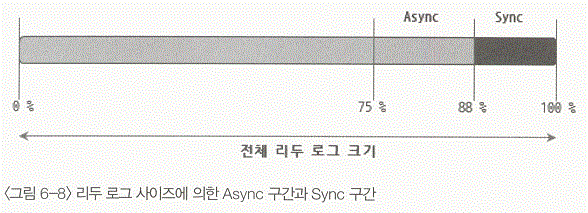
- 전체 리두 로그를 0~75% 구간과 75% ~ 88% 구간, 88%~100% 구간으로 구분해서 표시. 75%, 88%라는 수치는 InnoDB나 XtraDB의 소스코드상에 고정적으로 정의된 상수값으로 MySQL 소스코드를 변경해서 다시 컴파일 하지 않는 이상 변경 불가능하다.
- 75, 88%구간을 "Async"라고 하고 88%~100%까지의 구간을 "Sync" 구간이라고 한다.
- 리두로그 크기가 1000MB인데 현재 체크포인트 에이지(현재 사용 중이어서 재사용 될 수 없는 리두 로그 구간)가 800MB(75%~88%까지의 구간) 정도라면 이때부터는 InnoDB와 XtraDB가 Async 모드 방식으로 동작 된다. 체크포인트 에이지가 900MB 정도로 오르면 이를 Sync 모드라고 부른다.
- 평상시 모드 : 리두 로그의 여유 공간이 충분히 남아 있으므로 정해진 알고리즘 대로 적절히 더티 페이지를 디스크로 플러시 한다. 체크포인트 에이지가 75% 이하인 상태에서는 MySQL 서버로 유입되는 쿼리는 아무런 제한없이 실행된다.
- Async 모드 : 리두 로그의 여유 공간이 긴급하지는 않지만 부족 상황으로 접어들고 있음을 나타내며, 이 상태에서 유입되는 쿼리는 블로킹 된다. 리두 로그의 여ㅠ 공간을 확보하기 위해 클라이언트로부터 유입된 쿼리를 막고 버퍼 풀의 더티 페이지를 디스크로 플러시한다. 이미 실행되고 있던 쿼리들은 블로킹 되지 않고 실행된다.
- Sync 모드 : 리두 로그의 여유 공간이 매우 부족한 상태이며, 클라이언트로부터 유입되는 쿼리뿐만 아니라 이미 시작된 쿼리들까지 모두 블로킹을 시키고 버퍼 풀의 더티 페이지를 매우 공격적으로 디스크로 플러시한다.
- InnoDB나 XtraDB가 Async나 Sync 모드로 접어들게 되면, 그때부터는 버퍼 풀의 더티 페이지를 최대한 빨리 디스크로 플러시해서 리두 로그를 재사용 할 수 있도록 만들어야 한다.
6.3.2.4 MySQL 5.5 InnoDB의 더티 플러시
- MySQL 5.5 부터 경험 기반의 Adaptive Flushing 기능이 추가 되었다.
- 쓰기가 발생하는 만큼 적절하게 백그라운드 스레드가 더티 페이지를 디스크로 플러시 하도록 설계 되었다.
- Adaptive Flush는 Flush_list Flush의 쓰기에만 적용된다.
- InnoDB는 리두 로그가 꽉 채워진 상태에서 더티 페이지를 플러시하게 되면 짧지 않은 시간 동안 모든 사용자 쿼리들이 리두 로그가 재사용될 수 있도록 연관 더티 페이지가 모두 플러시될 때까지 기다려야 한다. 이런 장시간 대기를 막기 위해서 InnoDB는 유입되는 DML ㅓ쿼리의 량에 맞게 적절하게 더티페이지를 디스크로 플러시해주고 그 만큼 리두 로그가 다시 재사용될 수 있도록 여유 공간을 확보해야 한다.
- 만약 InnoDB 스토리지 엔진이 유입되는 DML 쿼리의 양이나 리두 로그의 증가 속도보다 더티 페이지를 느리게 디스크로 플러시 하면 사용자의 쿼리가 블로킹 될 것이다.
- 리두 로그의 증가 속도보다 빠르게 더티 페이지를 디스크로 플러시한다면 버퍼풀의 효율이 떨어지제 되면서 때로는 과도한 디스크 I/O를 유바할 수도 있다.
플러시해야 할 더티 페이지 수 =
((버퍼 풀의 전체 더티 페이지 수) * (리두 로그 증가 사이즈) / (전체 리두 로그 사이즈)) - (LRU_flush 페이지수)
1초에 플러시 해야할 더티 페이지수 =
(( 버퍼 풀의 전체 더티 페이지 수) * (초당 리두 로그 증가 사이즈) / (전체 리두 로그 사이즈)) - ( 초당 플러시된 LRU_flush 페이지 수)
- InnoDB의 체크포인트 에이지가 낮아서 Async나 Sync 모드가 아닌 평상시 모드라면 위의 공식대로 적절히 더티 페이지를 디스크로 플러시 한다.
- 유입되는 DML 쿼리의 양보다 리두 로그가 누적되는 속도가 더 빠른 경우에는 결국 체크포인트 에이지가 높아져서 InnoDB가 Asyn모드나 Sync 모드로 빠질 수도 있다.
- MySQL 5.5 버전에는 Adaptive Flush가 서비스의 트래픽을 적절히 소화하지 못할 경우를 대비 해서 튜닝 할 수 있는 변수를 제공
- innodb_io_capacity : 플러시해야 할 더티 페이지의 수를 계산하는 공식으로 계산한 결과가 만약 이 변수에 설정된 값보다 크면 innodb_io_capacity 설정 값만큼의 더티 페이지만 플러시하게 된다. 즉 한번에 플러시할 수 있는 최대 더티 페이지의 개수를 설정하는 변수
**innodb_max_dirty_pages_pct : InnoDB 버퍼 풀에서 더티 페이지가 어느 정도 비율까지 유지될 수 있는지를 설정하는 값. Default는 75로 75%까지 더티 페이지로 채워질 수 있다는 것을 의미.
- innodb_io_capacity 시스템변수에는 장착된 하드 디스크의 IOPS(Input output Operation Per Second) 를 설정해 주면 된다.
- MySQL 5.5 버전의 InnoDB에서는 버퍼 풀의 더티 페이지 비율이 높아지면 innodb_io_capacity를 적절히 높은 값으로 설정해서 더티 페이지의 비율을 낮출 수 있다.
- InnoDb 내부적으로는 LRU 플러시와 리두 로그 쓰기 횟수까지 합쳐서 innodb_io_capacity를 계산하기 때문에 리두 로그가 동기화 모드로 작동하는 MySQL 서버에서는 실제 디스크의 IOPS보다 훨씬 높은 값을 설정해야 할 때도 있다.
6.3.2.5 MariaDB 5.5 XtraDB의 더티 플러시
6.3.2.5.1 innodb_adaptive_flushing_method
- XtraDB에서는 innodb_adaptive_flushing_method 시스템 설정을 이용해서 어떤 Adaptive Flush 알고리즘을 사용할 지 선택 할 수 있게 됐다.
- native : XtraDb 스토리지 엔진을 사용한다 하더라도 더티 페이지 플러시 알고리즘은 MySQL 5.5의 InnoDB와 동일한 알고리즘의 Adaptive Flush를 사용하도록 설정.
- estimate : 체크포인트 에이지가 innodb_checkpoint_age_target시스템 변수에 설정된 값읜 1/4미만인 경우에는 10초당 innodb_io_capacity에 설정된 수만큼의 더티 페이지를 플러시한다. 그러다가 체크포인트 에이지가 innodb_checkpoint_age_target의 1/4 지점을 넘어서면 매초 단위로 리두 로그의 증가 비율에 맞춰서 더티 페이지를 디스크로 플러시 한다. 체크포인트 에이지가 1/4 지점을 넘어선 경우에는 10초 단위로 innodb_io_capacity에 설정된 만큼의 더티 페이지 플러시도 계속 실행된다.
- keep_average : Adaptive Flush가 keep_average 알고리즘으로 설정되면 0.1초 단위로 더티 페이지 플러시 작업이 수행 된다. keep_average 알고리즘에서도 리두 로그의 증가 비율에 맞춰서 적절히 더티 페이지를 디스크로 플러시한다. 0.1초 단위로 리두 로그 증가량이 알고리즘으로 반영되기 때문에 유입되는 DML의 변화를 빠르게 반영해서 더티 페이지가 디스크로 플러시된다고 볼 수 있다.
6.3.2.5.1 innodb_flush_neighbot_pages
- InnoDB에서는 플러시해야할 더티 페이지 주위의 더티 페이지를 모아서 같이 한번에 플러시를 하도록 섥ㅖ 되어 있다.
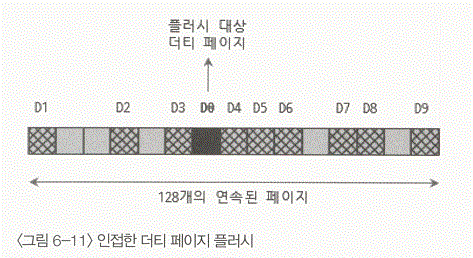
- area : innodb_flush_neighbot_pages 시스템 설정이 area로 설정되면 MySQL 5.5의 더티 페이지 플러시와 동일하게 동작한다. 이 모드에서는 플러시하고자 하는 더티 페이지를 기준으로 이웃한 페이지들 128개 중에서 더티 상태인 페이지를 모두 모아서 같이 플러시 한다. "DO"를 플러시할 때에는 양 영ㅍ의 128개 페이지 중에서 더티 상태인 D1~D9 페이지까지 같이 플러시 한다.
- count : innodb_flush_neighbot_pages 시스템 설정이 count로 설정되면 플러시하려는 더티 페이지와 인접한 더티 페이지들(인접한 페이지들이 모두 더티 상태인 것들까지만)만 같이 모아서 더티 페이지를 프럴시한다. 그림에서 "D0"를 기준으로 D3과 D4 그리고 D5와 D6 번 페이지만 플러시 하는 것이다.
- none : innodb_flush_neighbot_pages 시스템 설정이 none인 경우에는 이웃한 더티 페이지들을 전혀 고려하지 않고 대상 더티 페이지만 플러시한다.area나 count 플러시 모드는 모두 랜덤 I/O 성능이 취약한 HDD를 위한 배치 형태의 더티 플러시이다. none 으로 설정되면 플러시 대상이 "D0"페이지만 플러시 하게 된다.
6.3.2.5.3 innodb_flush_method
- innodb_flush_method 설정을 이용하여 데이터 파일의 읽고 쓰기를 어떤 방식으로 수행할지 결정할 수 있다.
- fdatasync : 이전 버전과의 호환성을 위해서 유지되는 방법. 실제로는 설정 불가. 데이터 파일의 쓰기를 fdatasync() 시스템 콜로 동기화 하는 목적으로 만들어 졌으나 지금은 MySQL 내부적으로 fsync()를 호출하도록 구현.
- O_DSYNC : InnoDB 스토리지 엔진이 데이터 파일에 쓰기 위해서 데이터 파일을 오픈할 때 "O_DSYNC" 옵션을 이용해서 파일을 열고, 데이터 쓰기 후 동기화를 수행할 때는 fsync() 시스템 콜을 호출하는 방식이다. O_DSYNC에서는 로그 파일은O_SYNC 옵션으로 열지만 플러시는 수행하지 않는다.
- O_DIRECT : InnoDB 스토리지 엔진이 데이터 파일에 쓰기 위해서 데이터 파일을 오픈할 때 "O_DIRECT" 옵션을 이용해서 파일을 열고, 데이터 쓰기 후 동기화를 수행할 때는 fsync() 시스템 콜을 호출하는 방식
- ALL_O_DIRECT : MariaDB 5.5의 XtraDB에 추가된 플러시 방법
- O_DIRECT_NO_FSYNC : MySQL 5.6 부터 도입된 플러시 방법. O_DIRECT 파일 입출력 모드는 쓰기를 실행하면 내부적으로 fsync()가 호출되는 것과 같은 효과를 낸다. 이런 이중 작업을 피하기 위해 서 설정.
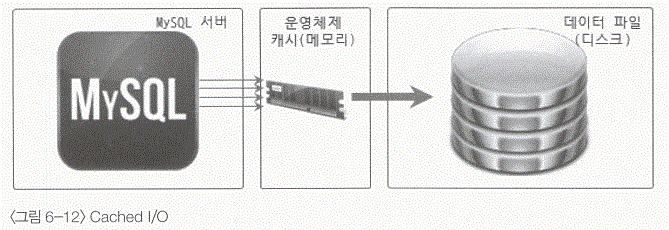
- 기본적으로 리눅스의 모든 디스크 읽고 쓰기는 Cached I/O를 기반으작동하고, 캐시 기반의 I/O 모드에서 디스크의 데이터를 읽고 쓰기는 다음과 같이 작동한다.
- 디스크로부터 데이터 읽기 : 캐시 기반의 I/O 응용 프로그램에서 디스크의 데이터를 읽을 때 먼저 리눅스의 운영체제 캐시를 찾아 보고 원하는 디스크 블록의 데이터가 이미 캐시되어 있는지를 확인한다. 찾는 블록이 있다면 캐시의 데이터를 바로 보여주고, 찾는 블록의 데이터가 없다면 실제 디스크로부터 데이터를 가져와서 운영체제 캐시에 먼저 복사하고 으용 프로그램을 반환한다.
- 디스크에 데이터 쓰기 : 으용 프로그램에서 운영체제로 파일의 데이터를 쓰기 요청을 하면, 리눅스는 요청을 받아서 바로 운영체제의 캐시에만 복사하고 리턴한다. 그리고 리눅스는 나중에 적절한 시점이 되면 응용 프로그램의 쓰기 요청들을 모아서 한번에 디스크로 기록한다.
6.3.2.5.4 XtraDB 스토리지 엔진의 개선된 결과
- INSERT 쿼리가 많은 경우 MySQL 5.5 InnoDB에서는 증가하는 리두 로그 대비 더티 페이지가 적절히 플러시되지 못해서 주기적으로 InnoDB 스토리지 엔진이 ASYNC 모드에서 처리되는 것을 발견할 수 있다.
6.3.2.6 MySQL 5.6 InnoDB의 더티 플러시
- MySQL 5.5의 InnoDB에서는 더티 페이지 플러시가 마스터 스레드 에서 수행
- Mysql 5.6 부터는 더티 페이지 플러시만 전담하는 페이지 클리너(page Cleaner) 스레드가 도입 되었다.
- 아래 두가 기준으로 더티 페이지 플러시를 실행한다.
- 액세스 패턴(Access Pattern) : 버퍼 풀에 빈 공간이 없을 때에는 최근에 자주 사용되지 않은 페이지가 LRU_List 플러시에 의해서 디스크로 플러시된다. 플러시해야 할 더티 페이지의 순서는 LRU_list에 관리된다.
- 에지이 : 더티 페이지들이 변경된 시간 순서대로 관리되는 리스트가 있는데, 이를 Flush_list라고 한다. Flush_list의 페이지는 몇가지 경험 기반의 알고리즘을 이용해서 플러시된다.
6.3.2.6.1 액세스 패턴
- 사용자가 쿼리를 요청하면 InnoDB 스토리지 엔진은 그 쿼리를 처리하기 위해서 디스크의 데이터 페이지를 읽어야 할 때도 있다. 이때, 버퍼 풀의 Free_List에서 여유 페이지가 없다면 LRU_list의 제일 마지막 페이지를 디스크로 플러시하게 된다.
- 문제는 배치 형식으로 많은 페이지들을 프럴시해 버린다.
- Free_List 페이지가 없을 때 실행되는 쿼리는 많은 시간이 소요될 수도 있다.
- MySQL 5.6 InnoDB에서는 LRU_list 플러시를 위해서 innodb_lru_scan_depth라는 변수에서 버퍼 풀 인스턴스 단위로 설정하는데, 페이지 클리너 스레드가플러시할 더티 페이지를 찾기 위해서 LRU_list에서 얼마나 많은 페이지를 스캔할지를 결정한다.
- LRU 플러시는 1초에 한번씩 백그라운드로 실행되는데, 평균적으로 i/o여유가 있는MySQL 에서는 innodb_lru_scan_depth를 조금 높게 설정하고, 쓰기가 많은 버퍼 풀이 큰 MySQL 서버에서는 이 값을 줄이는 것이 좋다.
6.3.2.6.2 체크포인트 에이지
- Flush_list에 남아 있을 수 있는 페이지의 전체 양은 InnoDB의 전체 리두 로그 사이즈의 합에 의해서 결정된다.
- InnoDB의 리두 로그 파일에 적당한 크기의 여유 공간으 마련해 두기 위해서 Flush_list의 더티 페이지를 계속적으로플러시 해야 한다.
- Flush_list의 더티 페이지를 너무 공격적으로 많이 플러시를 하면 버퍼 풀의 효율이 떨어지고, 너무 천천히 플러시 하면 InnoDB 리두 로그의 여유 공간 확보가 어려워 진다.
- MySQL 5.6의 InnoDB에서는 디스크로 플러시해야 할 페이지의 수를 현재 체크포인트 에이지를 기반으로 다음의 공식으로 결정하게 된다.
플러시해야 할 더티 페이지의 수 = ((innodb_io_capacity_max / innodb_io_capacity) * (lsn_age_factor * sqrt(lsn_age_factor))) / 7.5;
6.3.2.7 MariaDB 10.0의 XtraDB
플러시해야 할 더티 페이지의 수 = (((srv_max_io_capacity/srv_io_capacity) * (lsn_age_factor * lsn_age_factor * sqrt(lsn_age_factor))) / 700.5))
6.3.3 버퍼 풀 성능 개선
6.3.3.1 NUMA
- AMD의 Opteron과 인텔의 네할렘(Nehalme) 프로세스부터는 NUMA(Non Uniform Memory Access) 아키텍처가 적용되었다. 기존에는 UMA 아키텍처를 이용했다.
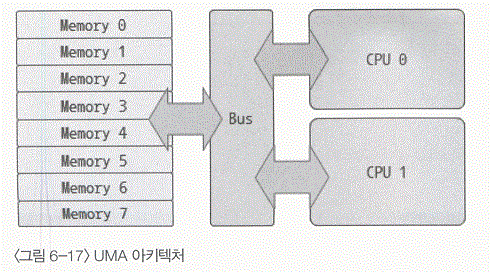
- UMA 아키텍처에서는 CPU 0번과 CPU 1번이 모두 시스템 버스(Bus)와 연결되어 있으며, 메모리는 통합되어 있고 그 메모리에 접근하기 윙해서는 반드시 시스템 버스를 통해야만 했다.
- 이런 아키텍처에서는 CPU가 메모리에 접근하는 경로가 길고 시간이 많이 걸리는 단점이 있었다.
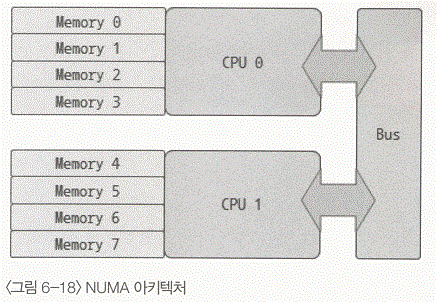
- 메모리가 CPU와 바로 연결되어 있다.
- 응용 프로그램이 CPU 번에서 기동되면 0~3번까지의 뱅크에 꽃힌 메모리를 사용한다. 그럼으로써 CPU와 메모리간의 접근이 아주 빠르게 처리되는 것이다.
- NUMA 아키텍처의 장점은 MySQL 서버와 같은 RDBMS에는 적합하지 않은 구조이다. MySQL 서버의 InnoDB 스토리지 엔진은 초기에 하나의 스레드에서 아주 대용량의 메모리를 버퍼 풀로 할당하고, 쿼리를 처리할 때에는 특정 메모리 영역만 읽어도 되는 경우가 거의 없었다.
- 실제 RDBMS에서 NUMA 아키텍처가 제대로 적용되려면 운영체제의 스케줄러가 쿼리가 접근하고자 하는 데이터와 각 메모리 뱅크가 가진 데이터를 인식하고 있어야 하는데, 거의 불가능이다.
- MySQL 서버에서 NUMA 아키텍처가 발생시키는 고치거리는 스왑이다. CPU가 2개인 시스템에서 NUMA 아키텍처의 각 CPU는 사용할 수 있는 메모리가 각각 반으로 줄어들게 되는데, 만약 한쪽이 90% 이상의 메모리를 사용해 버린 경우라면 다른 한쪽 CPU가 사용할 수 있는 메모리가 50%가 비어 있는 상태라 하더라도 스왑을 발생시키는 문제점이 있다.
- 리눅스에서 기동되는 MySQL 서버는 기본적으로 NUMA를 비활성하거나 numactl 유틸리티를 이용해서 메모리가 라운드 로빈방식으로 돌아 가면서 할당되도록 해주고 있다.
6.3.3.2 버퍼 풀 메모리 초기 할당
- 리눅스에서는 InnoDB 버퍼 풀을 40GB 로 설정하고 MySQL 서버를 시작해도 InnoDB 스토리지 엔진이 처음부터 40GB 메모리를 점유하는 것이 아니라 단순히 40GB 를 사용할 것이라고 리눅스에게 예약만 해두게 된다.
- 이렇게 예약된 메모리는 실제 응용 프로그램에서 접근할 때에만 리눅스가 응용 프로그램쪽으로 할당해주는 방식이다.
- XtraDB에서는 innodb_buffer_pool_populate 시스템 변수를 ON으로 설정하면 MySQL 서버가 기동되면서 XtraDB가 버퍼 풀을 할당받을 때 설정된 40GB의 메모리를 모두 할당 받는다. 전체 적인 메모리 사용량을 고정하는 것이다.
6.3.3.3 InnoDB 잠금 세분화
- MySQL 5.5 버전의 InnoDB에서는 별도의 뮤텍스를 만들기가 어려운 코드 블록에서는 거의 모두 kernel_mutext가 사용되어, 불필요하게 대기하게 되는 경우가 많았다.
- MySQL 5.6 InnoDB에서는 XtraDB와 비슷하게 kernel_mutex를 좀 더 세분화 해서 경합을 줄일 수 있도록 개선되었다.
6.3.3.4 I/O 기반의 워크로드 성능 향상
- 디스크의 데이터 파일의 크기가 InnoDB 버퍼 풀보다 훨씬 커서 디스크 읽기가 매우 빈번하게 발생하는 MySQL 서버에서는 다음과 같은 현상이 자주 발생한다.
- 페이지 클리너 스레드(Page Cleaner Thread)에서 프리 페이지를 준비하는 것보다 버퍼 풀의 Free_list의 프리 페이지가 매우 더 빠르게 소진되는 경우
- 버퍼 풀의 Free_list가 모두 소진되어서 쿼리나 다른 백그라운드 스레드가 계속 대기하는 상태가 발생
- Free_list의 동기화를 위한 뮤텍스 대기가 증가
- 페이지 클리너 스레드와 사용자 스레드에서 프리 페이지를 준비해도 버퍼 풀의 Free_list에 넣기 위해서 뮤텍스 대기를 해야하기 때문에 페이지 클리너 스레드의 성능이 떨어지게 됨.
- XtraDB에서는 위와 같은 악순환을 막기 위해서 프리 페이지(Free Page)를 생성하는 페이지 클리너 스레드는 즉시 프리 페이지 리스트의 뮤텍스를 획득할 수 있도록 우선순위를 부여 했다.
6.3.3.5 Adaptive Hash Partition
- InnoDB 스토리지 엔진에서는 프라이머리 키나 인덱스에 대한 룩업이 빈번히 발생하는 경우, 해당 인덱스의 일부 값들에 대해서 내부적으로 자동으로 해시 인덱스를 생성해서 검색이 빠르게 수행될 수 있도록 최적화 한다.
- 이때 자동 생성되는 인덱스를 Adaptive Hash Index라고 한다.
- MySQL 5.6의 InnoDB Adaptive Hash Index는 코어가 많이 장착된 시스템에서 읽기와 쓰기를 섞어서 사용하는 쿼리들이 많이 실행될 때 동시성 문제가 발생할 수 있다.
- XtraDB는 innodb_adaptive_hash_index_partition에 설정된 값만큼 인덱스를 생성하고, InnoDB 테이블의 각 인덱스 아이디를 기준으로 사용될 Adaptive Hash Index를 결정하게 된다.
- 테이블 하나에 인덱스가 하나만 있는 MySQL 서버에서는 Adaptive Hash Partition이 크게 도움되지 않을 수 있다.
6.3.4 원자 단위의 쓰기(FusionIO SSD를 위한 Atomic Write)
- InnoDB 스토리지 엔진의 리두 로그는 리두 로그 공간의 낭비를 막기 위해 페이지의 변경된 내용만 기록한다.
- 더티 페이지를 디스크 파일로 플러시할 때 일부만 기록되는 문제가 발생하면 그 페이지의 내용은 복구할 수 없을 수도 있다.
- 이렇게 페이지가 일부만 기록되는 현상은 Partial-page 또는 Torn-page라고 하는데, 이런 현상은 하드웨어의 오작동이나 시스템의 비정상 종료 등으로 발생할 수 있다.
- innoDB 스토리지 엔진에서는 이런 문제점을 막기 위해서 Double-wirte 기법을 이용한다.
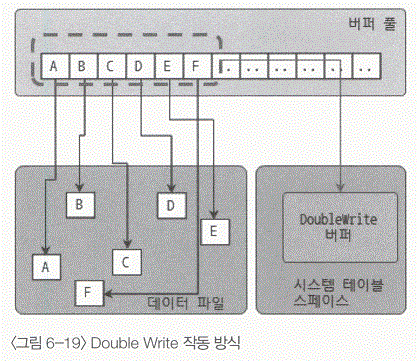
- 위의 그림 처럼 "A"~"F" 까지의 더티 페이지를 디스크로 플러시 할 경우, 실제 데이터 파일에 변경 내용을 기록하기 전에 A~F까지의 더티 페이지를 우선 묶어서 한번의 디스크 쓰기로 시스템 테이블 스페이스의 DoubleWrite 버퍼에 기록한다.
- 그리고 InnoDB 스토리지 엔진은 각 더티 페이지를 파일의 적당한 위치에 하나씩 랜덤으로 쓰기를 실행하게 된다.
- Double Write 버퍼의 내용은 데이터 파일의 쓰기가 중간에 실패할 때에만 원래의 목적으로 사용된다.
- 서버가 비정상 종료 되면, InnoDB 스토리지 엔진은 재식작 될 때 항상 DoubleWrite 버퍼의 내용과 데이터 파일의 페이지들을 모두 비교해서 다른 내용을 담고 있는 페이지가 있으면 DoubleWrite 버퍼의 내용을 데이터 파일의 페이지로 복사한다.
- SSD와 같이 랜덤 IO나 순차 IO의 비용이 비슷한 경우는 2개의 더티 페이지를 플러시 하는 것이 상당히 부담 스럽다.
- 이럴 경우 Fusion IO와 같은 고성능의 SSD는 디스크 쓰기를 원자 단위로 처리할 수 있게 해주는 기능을 지원한다.
- 원자 단위라 함은 innoDB 스토리지 엔진이 16kb를 디스크로 쓰기를 실행했을 때 Fusion IO 드라이브를 16KB가 100% 완전하게 기록되거나 아니면 하나도 디스크에 기록되지 않는 형태로 트랜잭션을 보장하는 것이다.
6.3.5 확장된 InnoDB 엔진 상태 출력
- MySQL 서버의 "SHOW ENGINE INNODB STATUS" 가 가독성이 떨어지는 단점이 있음
- XtraDB에서는 "SHOW ENGIEN INNODB STATUS"의 결과 값이 어떻게 보여질지 제어 가능
- innodb_show_verbose_locks : 잠김 레코드의 정보를 출력할지 여부 결정.
- innodb_show_locks_held : InnoDB의 각 트랜잭션 단위로 잠금의 개수를 출력할지 여부를 결정
6.3.6 XtraDB 리두 로그 아카이빙
- XtraDB에서느 오래된 리두 로그가 새로운 리두 로그에 의해서 덮어 씌이기 전에 오래된 로그를 복사하도록 기능이 추가 되었음.