press x to close
티베로 오픈 시점(2016년 9월 19일(월))에서 약 1개월 이후 시점인 2016년 10월 24 일(월) 하루 동안 운영된 결과를 TPR을 통해 확인해보고자 한다(소속 회사는 매일 유사한 업무가 수행되므로 하루 동안의 데이터베이스 사용 패턴이 매일 유사하게 나타날 것이다).
앞의 개요에서 언급한 것과 같이 소속 회사 프로젝트는 내부적인 엔진 분석 보다는 리플레이를 통한 SQL의 성능을 목표 지점까지 분석/개선하며 진 행하고 오픈하였는데 그 결과 과연 데이터베이스 내부 엔진도 자원을 효율적으로 사용하며 문제없이 수행되고 있는지 살펴보는 것이 본 장의 목적이다.
note : TPR은 성능 지연이 발생했던 시점과 정상적인 업무가 가능했던 시점을 비교하여 차이나는 항 목을 기준으로 성능 지연의 원인을 찾아가는 데 주로 활용된다(장애 분석 시 주로 사용). 따라 서 대다수의 항목들은 해당 수치만 보고 정상/비정상 여부를 판단할 수 없으므로 본 장에서는 일반적으로 정상일 때의 수치가 다소 분명한(비교가 불필요한) 항목들에 대해서만 살펴보고자 한다(원활한 분석을 위해 일부 항목은 Maxgauge 성능 분석 툴에서 제공하는 수치로 대체하거 나 함께 표기한다).
note : TPR에서 사용하는 모든 용어/항목을 데이터베이스 관리자가 이해하기는 현실적으로 불가능할 것이라고 생각한다. 따라서 티베로 제조사에서 주기적으로 사용 회사들의 TPR을 과거 시점과 비교하며 상세 분석을 하고 제조사/사용자 기준의 개선 사항을 도출하여 각자의 필요한 역할 을 수행할 수 있도록 안내하는 서비스가 존재하면 많은 도움이 될 것이라 판단된다(현재는 이 런 서비스가 존재하지는 않으며 장애 분석 시에만 사용된다).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | DB Name : xxxxxxxTAC : YESInstance Cnt : 2Release : 6 r128409Patches applied : FS04_98340l ...HOST CPUs : xxInterval condition : 4376 ~ 4419 (snapshot ids) (#=24 reported)Report Snapshot Range : 2016-10-24 08:18:58 ~ 2016-10-24 20:18:58Report Instance Cnt : 1 (from Instance NO. '0') <--TAC 0번 nodeElapsed Time : 720.00 (mins)DB Time : 869.43 (mins)Avg. Session # : 1,040.63DB Name : xxxxxxxTAC : YESInstance Cnt : 2Release : 6 r128409Patches applied : FS04_98340l ...HOST CPUs : xxInterval condition : 4396 ~ 4439 (snapshot ids) (#=24 reported)Report Snapshot Range : 2016-10-24 08:19:41 ~ 2016-10-24 20:19:41Report Instance Cnt : 1 (from Instance NO. '1') <--TAC 1번 nodeElapsed Time : 720.00 (mins)DB Time : 413.07 (mins)Avg. Session # : 964.04 |
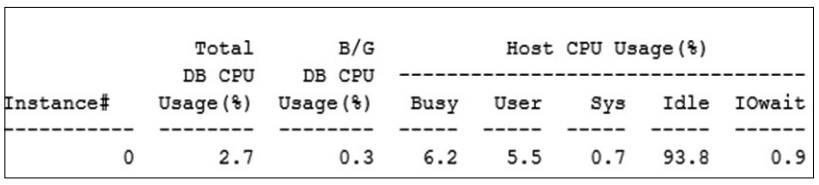
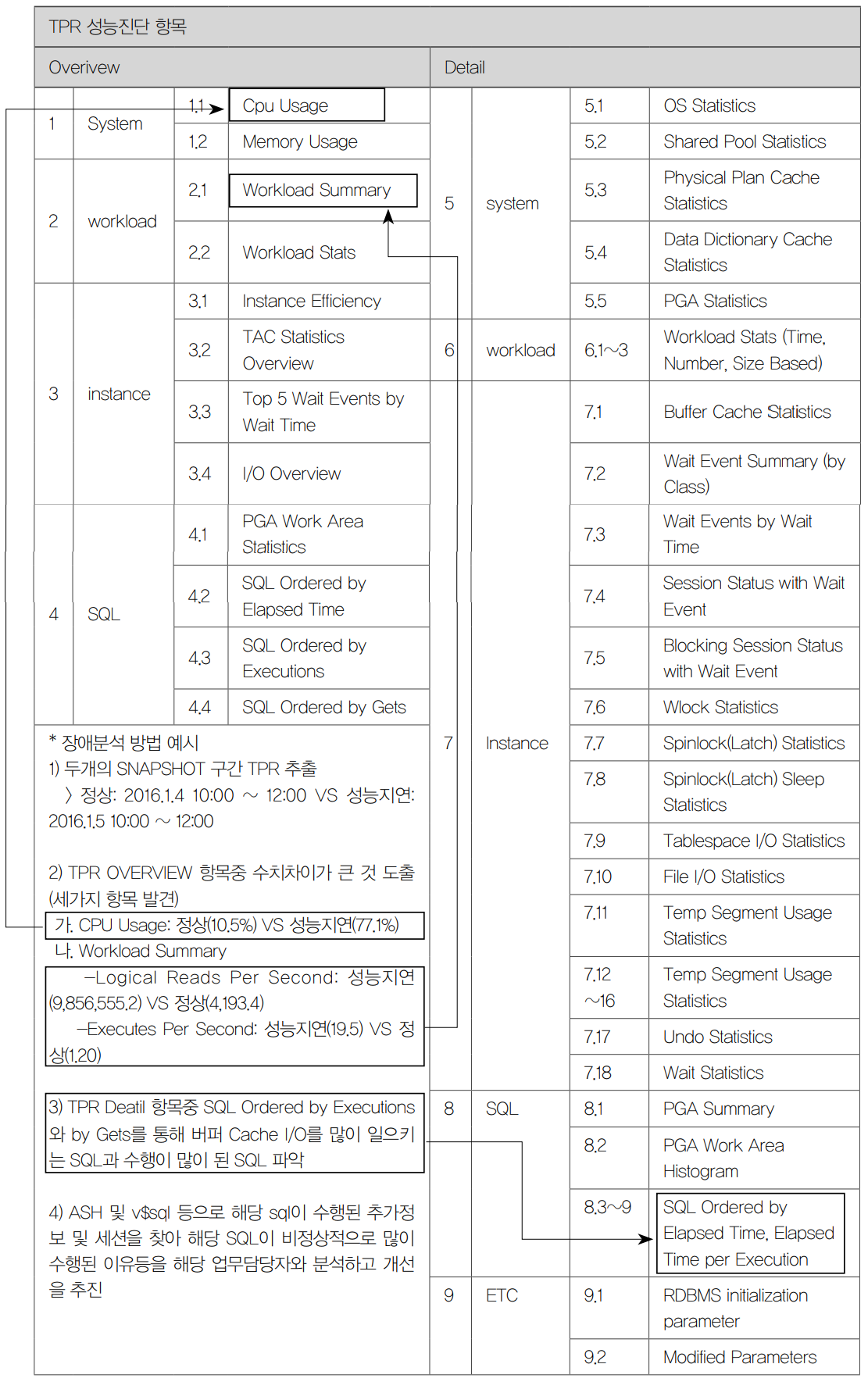
항목의 수치는 제조사별 추출 기준에 따라 다소 상이하나 TPR, Maxgauge 모두 OS CPU 자원을 과다하게 사용하지 않고 안정적으로 운영되었음이 확인된다.
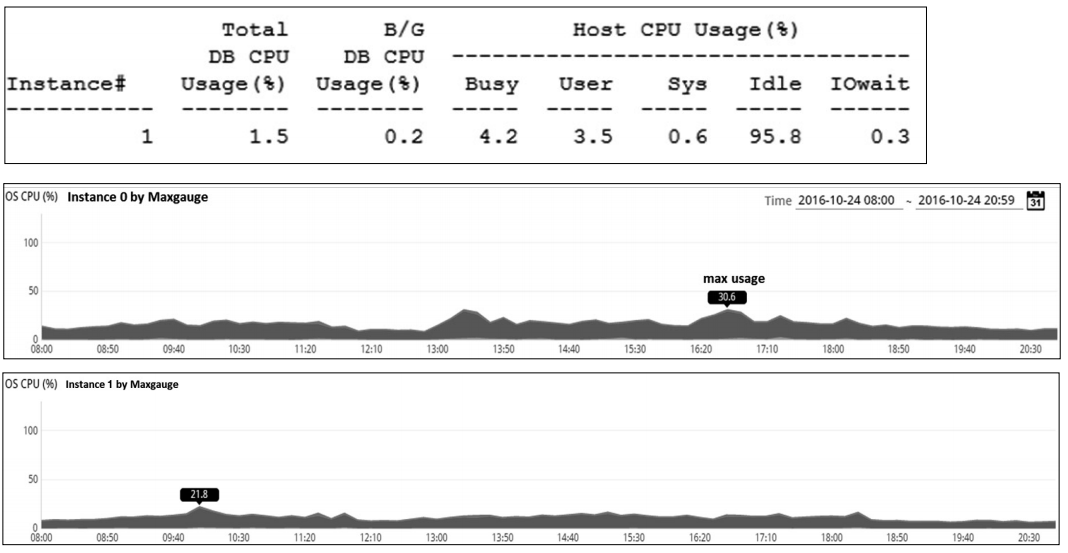
> Tibero가 사용 가능한 물리적인 메모리는 62G로 확인되며 이중 52G를 티베로 에 할당(MEMORY_TARGET=52G)하고 나머지 10G는 3rd Party Tool(모니터 링, 백업 솔루션) 등을 위해 남겨두었다.
따라서 전체 52G중 24G가 Total SHM Size(Share Memory 영역주1), TOTAL_SHM_SIZE=24G)에 할당되었고, 나머지 28G(MEMORY_TARGET-TOTAL_SHM_SIZE, 52G-24G)가 각 SQL Session 에서 사용하는 영역에 할당되었음을 확인할 수 있다.
| 주1 | 티베로의 메모리는 크게 모든 Working Thread가 공유할 수 있는(혹은 공유 해야 하는) 정보를 담고 있는 Shared Memory 영역과, 각 Working Thread에 각각 할당되어 공유하지 않고 해당 Thread 내에서만 사용하는 Sql Execution Work Area로 구분할 수 있다.
Total SHM Size(24G)는 다시 Buffer Cache(10G)가 속한 Fixed Memory와 DD cache, PP cache 등이 속한 Shared Pool(14G)로 나누어 지는데 현재 평균 Shared Pool의 사용량은 약 9G(Avg.Shared Pool Size)로 확인이 되므로 약 5G(14G - 9G)의 여유가 있음을 확인할 수 있다.
티베로의 메모리 관련 매뉴얼에서는 일반적인 온라인 업무 환경(OLTP, Online Transaction Processing)의 Shared Memory 영역(24G)과 SQL Execution 영역 (28G)을 8:2 비율로 할당할 것을 권고하고 있으나 소속 회사는 비교적 메모리가 충분하였으므로 일단 Shared Memory에 필요한 용량을 부여(기존 사용하던 외산 DBMS의 사용량 등을 참고하여)한 뒤 나머지를 모두 SQL Execution 영역에 부여 하여 갑작스런 세션 폭증 혹은 성능저하에 따른 해당 영역의 과도한 사용 등에 대 비하였다.
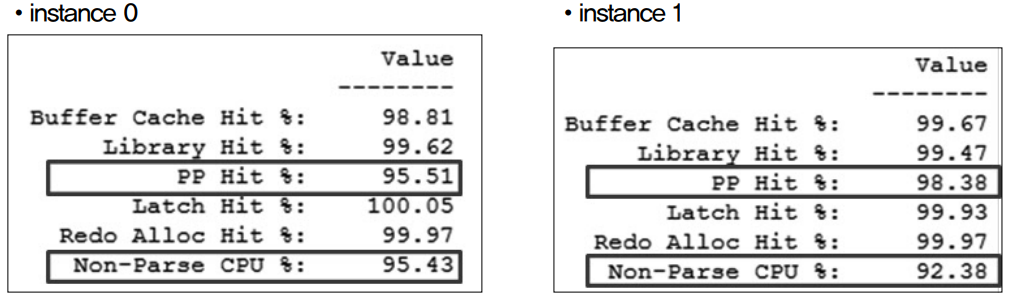
Hit율은 100%에 가까울수록 이상적인 효율을 나타내는데(예를 들어, Buffer Cache Hit율주2)은 필요한 블록을 디스크가 아닌 메모리 블록(Buffer Cache)에서 찾은 비율을 나타내는데, 이는 자주 사용되는 데이터 블록을 메모리에 적재해둠으 로써 고비용의 I/O를 최소화하여 데이터베이스 전체 성능 향상을 구현하는 핵심적 인 동작이다) 소속 회사는 PP Hit %, Non-Parse CPU %를 제외하고는 98% 이상 의 양호한 효율을 나타내는 것을 확인할 수 있다.
한편 PP(Physical Plan) Hit %과 Non-Parse CPU %는 모두 SQL의 파싱부하와 관련된 항목인데 바인드 변수를 적 극적으로 사용하지 않아 SQL이 동일함에도 불구하고 옵티마이저가 소프트파싱하 지 못하고 하드파싱하는 동작이 많음을 의미한다.
따라서 소속 회사는 ‘4.2장 비효 율 SQL 형태 - 6) 과도한 하드 파싱(HARD PARSING)’과 같은 비효율 SQL을 찾 아 바인드 변수를 사용하는 방향으로 어플리케이션을 개선할 필요가 있음이 확인 되었다.
| 주2 | 아래 Maxgauge의 Logical reads량과 Physical read량을 통해서도 대부분의 블록 I/O가 메모리를 통해 이루어 지고 있음을 확인할 수 있다.

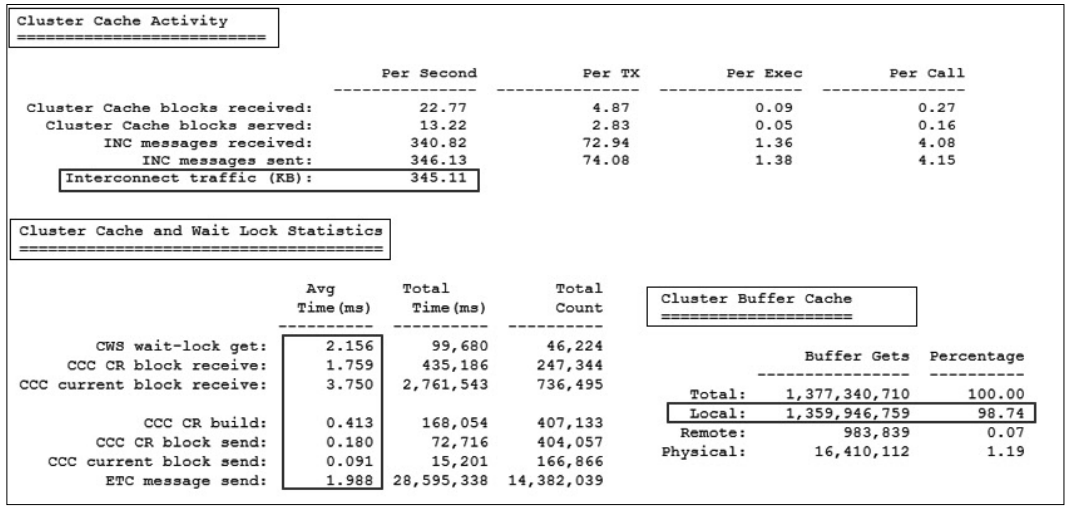
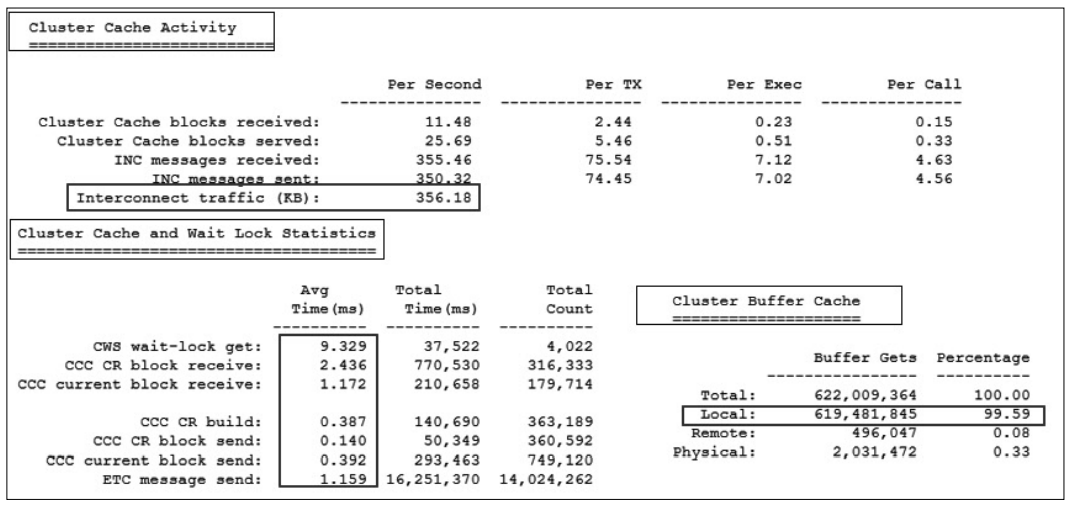
티베로 TAC는 ‘Tibero Active Cluster’의 약자로써 확장성과 고가용성을 목적으로 여러 대의 노드가 하나의 공유 캐시(Shared Cache)를 사용하는 것처럼 동작하며 운영 중에 한 노드가 멈추더라도 동작 중인 다른 노드들이 서비스를 지속할 수 있 게 구현된 티베로의 핵심 기능이다.
소속 회사는 두개의 노드로 TAC를 구성하였으 며 각 노드가 지나치게 블록을 주고받는 것을 방지하기 위해 어플리케이션별로 할 당된 고유의 노드로 접속(해당 노드가 다운되었을 때만 다른 노드로 접속)하도록 설정, 공통 영역의 오브젝트들에 한해서만 노드 간 블록 이동이 발생하도록 의도하 였다.
이제 위와 같은 소속 회사의 의도대로 티베로 TAC가 원활히 동작하고 있는 지 참고 5-9의 각 항목별 의미를 참고해서 살펴보자.
먼저 Cluster Buffer Cache 항목에서 대부분의 블록I/O가 상대방의 노드(Remote) 가 아닌 자신의 노드(Local, 98.74%, 99.59%)에서 발생하였음이 확인되므로 위 소속 회사의 의도를 만족하며 TAC가 동작 중임을 확인할 수 있다.
또한 Cluster Cache and Wait Lock Statistics 항목에서 instance 1번의 CWS wait-lock get 항목을 제외하면 모두 권장 사항보다 훨씬 양호한 수치가 추출되었음이 확인되므 로 Cluster Cache Activity에서 보여주고 있는 노드 간의 주고받은 블록들(초당 345k, 356k)이 엔진단에서 효율적으로 처리되고 있음을 확인할 수 있다.
| TAC Activity - Cluster Cache Activity | |
|---|---|
| Cluster Cache blocks received | 다른 노드의 글로벌 Cache에서 블록을 수집한 횟수(노드 간 주고받는 블록 의 수가 많은 경우 수치가 높다) |
| Cluster Cache blocks served | 다른 인스턴스로 블록을 전송한 횟수 |
| INC messages received | 블록 전송 이외에 블록에 대한 글로벌 lock 요청 및 응답 메시지, Cluster Wlock Service(CWS) 요청 및 응답 메시지, 노드 간 각종 동기화 메시지(예 : TSN 동기화), IIC(Inter instance call, 노드 간 일반 메시지 전송) 및 글로벌 VIEW 메시지를 수신/전송한 횟수이다. |
| INC messages sent | |
| Interconnect traffic (KB) | 노드 간 주고받은 데이터의 총량 |
| TAC Activity - Cluster Buffer Cache Summary | |
| Buffer Gets | 버퍼 Cache에 블록 요청 횟수 |
| Total | 전체 버퍼 Cache I/O 횟수 및 비율 (Local Buffer Gets + Remote Buffer Gets + Physical Read) |
| Local | 전체 버퍼 Cache I/O 중 Local 버퍼 Cache에서 블록을 가져온 횟수 및 비율 |
| Remote | 전체 버퍼 Cache I/O 중 Remote 버퍼 Cache에서 블록을 가져온 횟수 및 비율 |
| Physical | 전체 버퍼 Cache I/O 중 디스크에서 블록을 가져온 횟수 및 비율 |
| TAC Activity- Cluster Cache and Wait Lock Statistics | |
| CWS wait-lock get | Wait lock을 얻어오는 평균 시간과 전체 시간, 횟수/이 수치에 영항을 줄 수 있는 부분은 interconnect 성능과 wait lock contention이다(3ms 이하 권장). |
| CCC CR block receive | Consistent Read를 위한 블록을 요청하고 전송받을 때까지의 시간 및 횟 수/ 주로 Select 부하가 많은 경우 이 수치가 높아진다(3ms 이하 권장). |
| CCC current block receive | Current Block을 요청하고 전송받을 때까지의 시간 및 횟수(5ms 이하 권장) |
| CCC CR build | 다른 노드의 요청에 의해 consistent read block을 생성하는 시간 및 횟수 (3ms 이하 권장) |
| CCC CR block send | 다른 인스턴스로 CR 블록을 전송할 때 걸린 시간 및 전체 시간, 횟수(3ms 이하 권장) |
| CCC current block send | 다른 인스턴스로 Current 블록을 전송할 때 걸린 시간 및 전체 시간, 횟수 (5ms 이하 권장) |
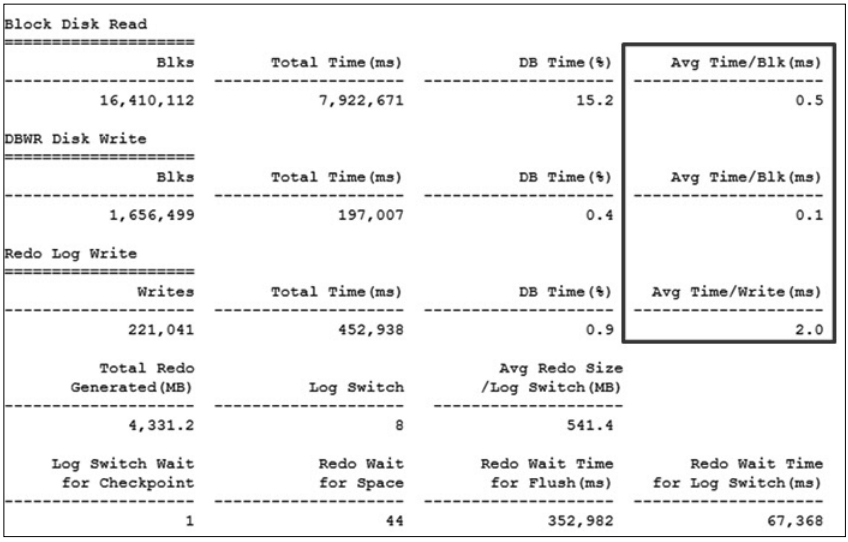
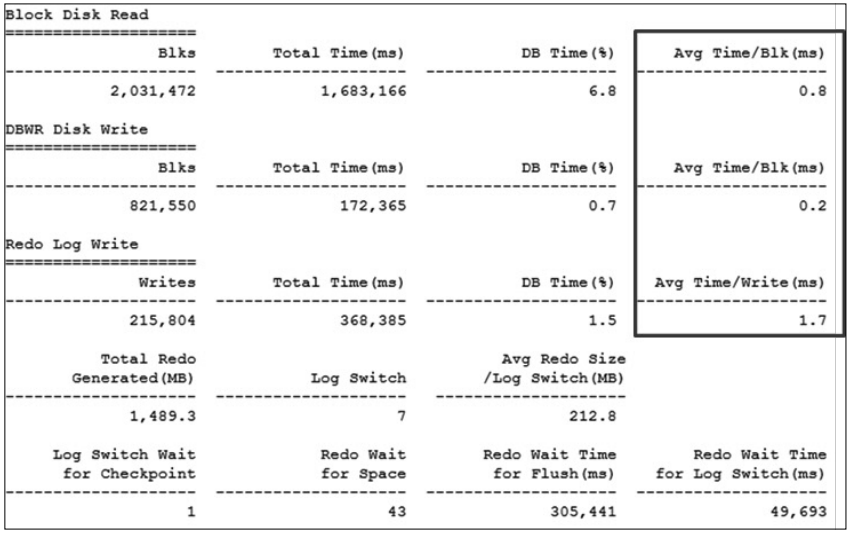
물리적인 디스크 I/O가 발생하는 대표적인 세 가지 항목(Block Disk Read, DBWR Disk Write, Redo Log Write)에 대해 각 단위 항목(블록, 쓰기)에 대한 평균 소요 시간이 최소 0.5ms에서 최대 2.0ms으로써 티베로에서 판단하는 평균 기준인 5ms 에 비해 매우 우수함을 확인할 수 있다


티베로와 같은 데이터베이스는 다수의 프로세스(스레드, 세션)가 공유된 여러 가지 자원을 동시에 사용하는 경우가 빈번하므로 선행 프로세스가 처리를 다 마칠 때까 지 기다려야 하는 상황이 발생할 수 있는데 이 경우 본인의 차례가 될 때까지 해당 프로세스는 수면(SLEEP, OS에 자원을 반납) 상태에 빠지게 된다.
이때 해당 프로 세스가 왜 수면 상태에 빠지는지 사용자에게 힌트를 주는 것이 대기 이벤트(WAIT EVENT)인데 소속 회사의 경우 양쪽 노드에서 spinlock total wait 이벤트가 가장 높게 나온 것을 확인할 수 있다.
본 이벤트 관련 티베로 연구소에 상세 분석을 의뢰한 결과 해당 이벤트는 spinlock 중 SPIN_BITQ에 의한 것으로 TAC에서 자원을 재활용하는 과정에서 요청이 몰 려 발생할 수 있는데, TPR 보고서 내 자원 할당 관련 또 다른 이벤트 확인 시(Total Times to allocate new CCC RSB) 문제가 없는 것으로 보아 서비스에는 영향이 없 는 것으로 판단하였다.
연구소는 스핀락의 Sleep Time이 다소 크게 설정되어 부하 에 비해 과도하게 Sleep하는 현상으로 최종 분석하였으며 다음과 같이 파라미터 값 을 변경하는 것을 권고하였다(이외의 항목은 큰 문제가 없는 것을 확인할 수 있다).
| 변경 전(기본값) | 변경 후 |
|---|---|
| _SPIN_USE_WAITER_LIST=N | SPIN_USE_WAITER_LIST=N |
| _SPIN_COUNT_MAX = 100 | SPIN_COUNT_MAX=3200 |
| _SPIN_SLEEP_TIME = 32000 | _SPIN_SLEEP_TIME=2000 |
- 강좌 URL : http://www.gurubee.net/lecture/4145
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.