press x to close
SQL을 작성하다 보면 참고 4-18과 같이 N개의 ROWS로 표현된 문자열을 특정 컬 럼을 기준으로 1개의 ROWS로 연결하는 형태를 자주 사용하게 되는데 이때 티베 로가 공식 지원하는 함수는 AGGR_CONCAT이다.
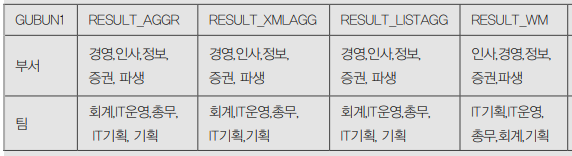
그러나 참고 4-19와 같이 외산 DBMS에서 널리 사용되었던 WM_CONCAT, XMLAGG, LISTAGG 또한 큰 제약 없이 동일하게 사용은 가능한데, 이때 만약 연결해야 하는 문자열이 굉장히 많은 원본 데이터를 위와 같은 비공식 함수를 사용하면 성능의 저하가 두드러지게 나타 날 수 있으므로 주의해야 한다(그렇다고 기존에 사용했던 것을 모두 변경해야 한다 는 의미는 아니다).
소속 회사의 경우 XMLAGG를 사용하여 무거운 문자열을 연결 한 SQL이 메인 화면에 사용되어 반복 호출되며 성능저하가 발생한 경우가 존재하여 해당 SQL만 티베로가 공식 지원하는 AGGR_CONCAT으로 수정 처리하여 문제 를 해결하였다(참고 4-20, 4-21).
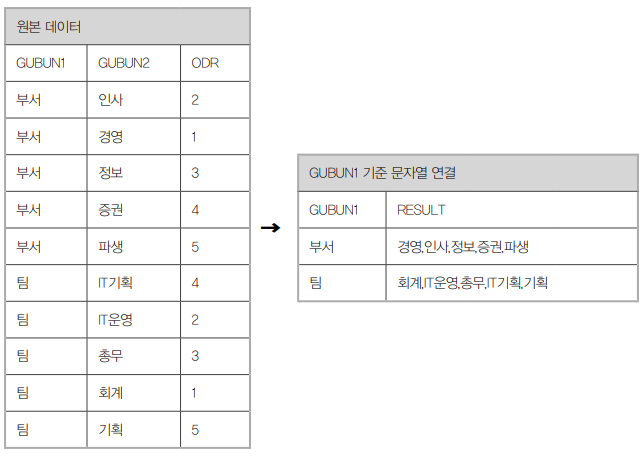
1 2 3 4 5 6 7 8 9 10 11 12 13 | SELECT GUBUN1, AGGR_CONCAT(GUBUN2,','ORDER BY ODR) RESULTFROM (SELECT '부서' GUBUN1, '인사' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT '부서' GUBUN1, '경영' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT '부서' GUBUN1, '정보' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT '부서' GUBUN1, '증권' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT '부서' GUBUN1, '파생' GUBUN2, '5' ODR FROM DUAL UNION ALLSELECT '팀' GUBUN1, 'IT기획' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT '팀' GUBUN1, 'IT운영' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT '팀' GUBUN1, '총무' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT '팀' GUBUN1, '회계' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT '팀' GUBUN1, '기획' GUBUN2, '5' ODR FROM DUAL) group by GUBUN1; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | SELECT GUBUN1 , AGGR_CONCAT(GUBUN2,','ORDER BY ODR) RESULT_AGGR , SUBSTR(XMLAGG(XMLELEMENT(x, ',', GUBUN2) ORDER BY ODR).EXTRACT('//text()'), 2) RESULT_XMLAGG , LISTAGG(GUBUN2, ',') WITHIN GROUP(ORDER BY ODR) RESULT_LISTAGG , WM_CONCAT(GUBUN2) RESULT_WM FROM (SELECT'부서' GUBUN1,'인사' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'경영' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'정보' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'증권' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'파생' GUBUN2, '5' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1,'IT기획' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1,'IT운영' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '총무' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '회계' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '기획' GUBUN2, '5' ODR FROM DUAL) group by GUBUN1; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | --만약 WM_CONCAT에 정렬을 보장하고 싶다면 다음과 같이 사용이 가능하다.SELECT GUBUN1,MAX(RESULT_WM)RESULT_WMFROM(SELECT GUBUN1, WM_CONCAT(GUBUN2) OVER (PARTITION BY GUBUN1 ORDER BY ODR)RESULT_WM FROM (SELECT'부서' GUBUN1,'인사' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'경영' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'정보' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'증권' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT'부서' GUBUN1,'파생' GUBUN2, '5' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1,'IT기획' GUBUN2, '4' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1,'IT운영' GUBUN2, '2' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '총무' GUBUN2, '3' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '회계' GUBUN2, '1' ODR FROM DUAL UNION ALLSELECT'팀' GUBUN1, '기획' GUBUN2, '5' ODR FROM DUAL))GROUP BY GUBUN1; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | --AGGR_CONCAT 사용 시 OVERALL TOTAL stage count cpu elapsed current query disk rows------------------------------------------------- parse 3 0.00 0.00 0 0 0 0 exec 0 0.00 0.00 0 0 0 0 fetch 6 0.01 0.03 0 535 0 4------------------------------------------------- sum 12 0.01 0.03 0 535 0 4 --XMLAGG 사용 시 OVERALL TOTAL stage count cpu elapsed current query disk rows------------------------------------------------- parse 2 0.00 0.00 0 0 0 0 exec 2 0.00 0.00 0 0 0 0 fetch 6 0.43 13.52 0 535 0 4------------------------------------------------- sum 10 0.43 13.52 0 535 0 4 >> query(block read) 항목은 동일하지만 성능에 큰 차이가 있음을 확인할 수 있다. |
| 구성 요소 | 설명 |
|---|---|
| set_quantifier | 질의 결과에 중복된 로우의 허용, 비허용 여부를 지정한다. DISTINCT,UNIQUE,ALL을 지정
할 수 있다. – DISTINCT, UNIQUE : 중복된 로우를 제거한다. – ALL : 모든 로우를 선택한다(기본값). |
| expr | 문자열이나 문자열로 변환될 수 있는 임의의 연산식이다 |
| separator | expr과 접합될 구분자를 나타내는 문자 리터럴이다. |
| order_by_clause | 접합할 문자열을 어떻게 정렬할지를 명시한다. |
- 강좌 URL : http://www.gurubee.net/lecture/4135
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.