press x to close
본 단계는 전환 프로젝트의 마지막 단계로써 오픈을 위해 필요한 최종 준비를 수행하는 단계이다.
2단계 비호환 SQL 분석 및 개선을 통해 가장 만족스러운 티베로의 패치 버전을 결정하는 순간 본 단계가 시작되며, 시작 이후 추가적인 패치는 꼭 필요한 사항이 아니면 최대한 자제해야 한다.
특히 성능 패치의 경우 부작용이 발생할 가능성이 크므로 2단계에서 최대한 성능을 검증하고 이후에 발생하는 것들에 대해선 SQL을 수정하여 어플리케이션에 반영하는 것이 현명하다.
따라서 3단계 시작 전에 최대한 성능을 개선하고 검증된 분석 데이터를 근거로 신중하게 최종 패치버전을 결정해야 한다(최종 패치 버전을 선택하는 것이 프로젝트 전 과정에서 가장어려운 결정이었다).
신중하게 패치가 결정이 되었다면 어떤 것들을 오픈을 위해준비해야 했는지 살펴보자.
리플레이를 통해 어플리케이션에서 수행하는 SQL들을 충분히 검증하였으므로 업무 담당자의 수동 테스트는 필요 없다고 느껴질 수 있겠지만 다음과 같은 리플레이 한계점들로 인하여 오픈준비 단계를 통해 약 1개월간 진행하였다
한계점 1) 리플레이의 수집 시간을 아무리 늘린다고 하더라도 모든 SQL들을 수집할 수는 없다(자주 사용되지 않는 쿼리, 월/분기/연 1~2회 수행되는 업무의 SQL들은 리플레이 수집에 누락될 수밖에 없다). 따라서 이러한 업무들은 담당자가 수동 테스트를 통해 가장 중요한 일부분만이라도 검증해야 한다.
한계점 2) 리플레이는 트랜잭션을 정확히 재현하지 않으므로 문법적(SQL Fail)으로, 성능적(부하검증)으로 문제가 있는 비호환 SQL을 파악하기 위한 용도로만 그 목적을 한정하였다. 따라서 개별 SQL들의 호환성이 검증되었더라도 어플리케이션 비즈니스 상 매우 복잡한 트랜잭션으로 해당 SQL들이 설계되어 있다면 반드시 수동 테스트를 거쳐 해당 비지니스가 의도한 대로 동작하는지 검증해야 한다
한계점 3) 리플레이는 ‘정렬(Sorting)’문제와 같이 SQL의 성능/문법은 이상이 없으나 출력 형태가 외산 DBMS와 상이한 경우를 파악할 수 없다. 참고로 소속 회사는 order by 절을 명시하지 않은 쿼리가 외산 DBMS에서는 우연히 의도한 바와 같이 정렬이 되었는데 티베로에서는 그렇지 못한 쿼리를 몇몇 발견하여 order by 절, 계층형의 경우 order by sibling 절(참고 3-1)을 명시해주는 것으로 조치를 하였다(메뉴,게시판 목록 조회와 같이 정렬이 주는 영향이 상당히 큰 화면은 반드시 수동 테스트를 하고 문제없음을 검증해야 한다).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 | 1) 테스트 테이블 구성CREATE TABLE TBWORKER( TBWORKER_ID NUMBER, WORKER_NAME VARCHAR2(100), BOSS_ID NUMBER );INSERT INTO TBWORKER VALUES ( 1, 'HONG', NULL );INSERT INTO TBWORKER VALUES ( 2, 'WOO', 1 );INSERT INTO TBWORKER VALUES ( 3, 'KIM', 1 );INSERT INTO TBWORKER VALUES ( 4, 'PARK', 3 );INSERT INTO TBWORKER VALUES ( 5, 'BYUN', 2 );INSERT INTO TBWORKER VALUES ( 6, 'LEE', 3 );INSERT INTO TBWORKER VALUES ( 7, 'KU', 3 );INSERT INTO TBWORKER VALUES ( 8, 'CHOI', 2 );INSERT INTO TBWORKER VALUES ( 9, 'KIL', 2 );INSERT INTO TBWORKER VALUES ( 10,'CHO', 2 );COMMIT; 2) 정렬을 지정하지 않은 경우 동일 LEVEL간 정렬이 보장되지 않아 외산 DBMS와 다르게 표기될 수 있다.SELECT LEVEL, LPAD ('->', (LEVEL - 1) * 3) || WORKER_NAME COL FROM TBWORKER START WITH BOSS_ID IS NULLCONNECT BY BOSS_ID = PRIOR TBWORKER_ID; LEVEL COL------ ---------- 1 HONG 2 ->KIM 3 ->KU <--KU, LEE, PARK는 우연히 정렬이 됨 3 ->LEE 3 ->PARK 2 ->WOO 3 ->CHO <--CHO, KIL, CHOI, BYUN은 정렬이 되지 않음 3 ->KIL 3 ->CHOI 3 ->BYUN 3) ORDER SIBLINGS BY를 통해 정렬을 명확히 지정할 경우는 동일 레벨 간 정렬이 보장되므로 외산 DBMS와 결과가 동일함SELECT LEVEL, LPAD ('->', (LEVEL - 1) * 3) || WORKER_NAME COL FROM TBWORKER START WITH BOSS_ID IS NULLCONNECT BY BOSS_ID = PRIOR TBWORKER_ID ORDER SIBLINGS BY WORKER_NAME; LEVEL COL------- ---------- 1 HONG 2 ->KIM 3 ->KU 3 ->LEE 3 ->PARK 2 ->WOO 3 ->BYUN 3 ->CHO 3 ->CHOI 3 ->KIL 4) 참고로 계층형 쿼리에 ORDER BY 절을 사용하면 계층 간의 정렬이 무시되고 ORDER BY 절에 명시된 컬럼을 기준으로 정렬됨SELECT LEVEL, LPAD ('->', (LEVEL - 1) * 3) || WORKER_NAME COL FROM TBWORKER START WITH BOSS_ID IS NULLCONNECT BY BOSS_ID = PRIOR TBWORKER_ID ORDER BY WORKER_NAME; LEVEL COL---------- ---------- 3 ->BYUN 3 ->CHO 3 ->CHOI 1 HONG 3 ->KIL 2 ->KIM 3 ->KU 3 ->LEE 3 ->PARK 2 ->WOO |
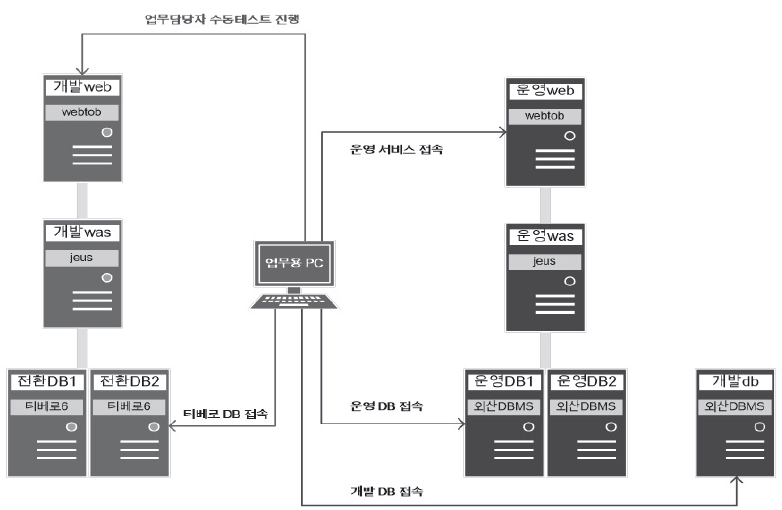
참고1) 오픈 준비 단계에서는 최종 패치가 확정되었으므로 더 이상 리플레이 수행이 불가하다. 따라서 리플레이 관련 서버 및 설정을 제거하였다.
참고2) 업무 담당자 수동 테스트 진행을 위해 기존 외산 DBMS 개발 서버와 연동하던 개발 웹/와스서버를 티베로 운영서버와 연동하여 환경을 제공하였다. 본 환경을 구성하는 순간 SQL/데이터 변경이 필요한 개발은 모두 불가능하므로 업무 담당자들 과 협의하여 오픈 전 1개월 시점에 본 환경을 구성하고 업무 담당자 테스트를 시작하였다.
2단계 ‘리플레이를 통한 비호환 SQL 분석 및 개선’의 이상적인 목표는 현재 사용 중인 모든 SQL들이 잘 동작하는 티베로 패치 버전을 확정하는 것이다. 그러나 동일 제조사의 DBMS 버전을 업그레이드할 때도 엔진 내부의 동작 방식 변경 및 추가/삭제되는 기능 등으로 인해 SQL 수정이 필요한 경우가 많다는 점을 고려할 때 제조사를 변경하는 티베로 전환 프로젝트 2단계의 현실적인 목표는 전환 추진 회사들이 대응 가능한 수준으로 SQL 수정을 최소화 하는 것주5) 이라고 할 수 있다.
따라서 패치가 확정되어 오픈 준비 단계를 시작하면 업무 담당자 테스트와 동시에 수정 대상 SQL을 선정주6)하여 최적화(튜닝)하는 작업을 수행해야 한다. 이때 외산 DBMS에서도 유사하거나 향상된 성능을 발휘할 수 있는 방향으로 SQL을 수정한다면 각 SQL 수정시점에 운영 반영이 가능하므로 오픈 이후 수정된 SQL을 한 번에 반영하는 것에 따른 어플리케이션 안정성 위험을 상당히 줄일 수 있다.
| 주5 | 소속 회사의 경우 티베로에 재현된 약 300만 회의 SQL 수행 중 0.3%가 수행되지 않고 실패(Fail) 처리되었으며 17.7%가 기준 시간(0.2초) 이상 소요(Elapsed Time)되는 것으로 최초 분석되었는데, 3개월간의 2단계 수행과정에서 약 10회의 패치를 적용하며 2개의 패턴을 제외하고는 실패(Fail)하는 SQL이 없도록 개선되었고 기준시간 이상 소요되는 SQL 수행율도 17.7%에서 5.4%로 감소되었다. 일정에 조금 더 여유가 있었다면 실패도 전혀없고 성능도 더욱 향상된 패치가 제작될 수 있도록 티베로 연구소와 함께 노력할 수 있었겠지만 2개의 실패 패턴과 5.4%의 수치는 소속 회사가 SQL 수정으로 조치하기에 감내할 만한 수준으로 판단되어 해당 시점에 패치를확정하였다. 이 외의 상세한 분석결과는 3.4장 티베로 재현결과 분석을 통해 확인할 수 있다
| 주6 | 수정 대상 SQL은 아래의 세 가지 기준으로 136개를 선정하였다. 해당 기준에 따른 SQL을 선정하여 최적화 한다면 SQL의 실패율은 0%가 될 것이고 성능 또한 소속 회사가 정의한 목표 수치(기준시간(0.2초) 이상 소요되는SQL의 비율을 외산 DBMS와 유사한 수준(2.3%)으로 개선)만큼 개선될 수 있을 것이라고 판단했다. 티베로 오픈 이후 3개월이 지난 현재 시점까지 성능 이슈가 적어도 리플레이를 통해 수행했던 쿼리들에는 전혀 발생하지 않은 점이 당시 판단이 틀리지 않은 것을 증명하고 있으나 전환을 진행하는 회사의 업무적 특성과 리플레이 분석결과를 고려하여 알맞게 변경하며 적용해야 할 것으로 생각된다.
1. 2가지의 실패 패턴을 사용하고 있는 모든 SQL
2. 외산 DBMS에서 수행될 때의 소요 시간 대비 10초 이상 성능저하가 발생한 SQL
3. 기준 시간(0.2초) 이상 소요된 SQL의 수행 횟수가 외산 DBMS와 비교할 때 200회 이상 차이나는 SQL
(수백 수천 회 반복 수행되는 SQL은 작은 성능의 차이로도 시스템에 큰 영향을 줄 수 있으므로)
기준 시간(0.2초) 이상 소요된 SQL의 수행횟수가 외산 DBMS와 비교할 때 200회 이상 차이나는 SQL
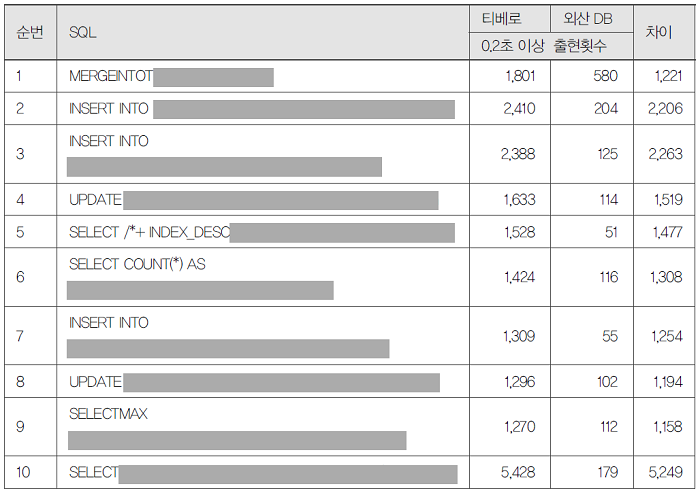
외산 DBMS에서 수행될 때의 소요 시간 대비 10초 이상 성능저하가 발생한 SQL

- 강좌 URL : http://www.gurubee.net/lecture/4121
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.