press x to close
 |
Note
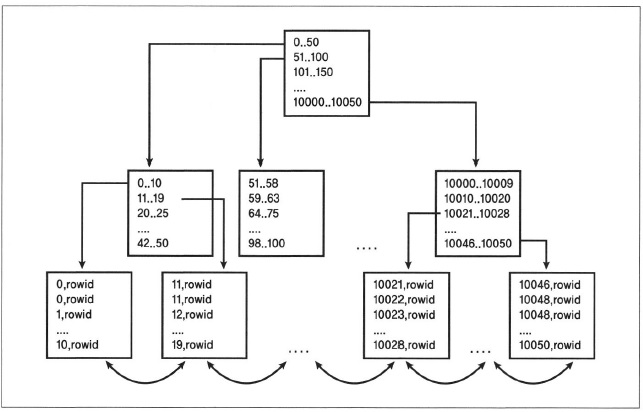
블록 레벨 최적화와 데이터 압축을 한 경우는 실제 데이터 블록 구조가 그림 11-1과는 다르게 생성된다.
where x between 20 and 30
Note
select index_name , blevel , num_rows
from user_indexes
where table_name = 'BIG_DATA'
INDEX_NAME BLEVEL NUM_ROWS
------------------------------ ---------- ----------
BIG_DATA_IDX 2 1000000
select x from big_data where x = 42;
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| BIG_DATA_IDX | 1 | 13 | 2 (0)| 00:00:01 |
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
532 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select x from big_data where x = 12345;
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
1 physical reads
0 redo size
534 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select x from big_data where x = 1234567;
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
5 physical reads
0 redo size
342 bytes sent via SQL*Net to client
508 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
Note
B*Tree는 큰 테이블과 작은 테이블에서 모두 잘 동작하며 태이블의 크기가 커짐 에도 성능 저하가 거의 없는 범용목적의 인덱스기법 이다.
Note
DBMS_STATS는 객체의 통계정보를 수집하는 데 사용되어야 하며, ANALYZE 영렁어는 인덱스 구조를 확인하거나 체인이 발생한 로우의 리스트를 확인하는 데 사용된다.
다음으로 인덱스 키를 압축하여 재생성해보기
create table t
as select * from all_objects
where rownum <= 50000;
create index t_idx on t(owner , object_type , object_name);
analyze index t_idx validate structure ;
create table idx_stats
as
select 'noncompressed' what , a.*
from index_stats a;
create table idx_stats
as
select 'noncompressed' what , a.*
from index_stats a;
drop index t_idx;
create index t_idx on
t(owner,object_type,object_name)
compress &1;
analyze index t_idx validate structure;
select 'compress &1' , height , lf_blks , br_blks , btree_space , opt_cmpr_count , opt_cmpr_pctsave from index_stats a;
--select what , height , lf_blks , br_blks , btree_space , opt_cmpr_count , opt_cmpr_pctsave
--from idx_stats;
WHAT HEIGHT LF_BLKS BR_BLKS BTREE_SPACE OPT_CMPR_COUNT OPT_CMPR_PCTSAVE
------------- ---------- ---------- ---------- ----------- -------------- ----------------
noncompressed 3 362 3 2920096 2 28
compress 1 3 324 3 2614800 2 19
compress 2 3 259 3 2095060 2 0
compress 3 3 404 3 3254480 2 35
drop table t ;
create table t tablespace assm
as
select 0 id, a.\*
from all_objects a
where 1=0;
alter table t
add constraint t_pk
primary key(id)
using index ( create index t_pk on t (id) reverse tablespace assm);
create sequence s cache 1000;
create or replace procedure do_sql
as
begin
for x in ( select rownum r, all_objects.* from all_objects )
loop
insert into t (ID
,OWNER
,OBJECT_NAME
,SUBOBJECT_NAME
,OBJECT_ID
,DATA_OBJECT_ID
,OBJECT_TYPE
,CREATED
,LAST_DDL_TIME
,TIMESTAMP
,STATUS
,TEMPORARY
,GENERATED
,SECONDARY
,NAMESPACE
,EDITION_NAME)
values
( s.nextval
,x.OWNER
,x.OBJECT_NAME
,x.SUBOBJECT_NAME
,x.OBJECT_ID
,x.DATA_OBJECT_ID
,x.OBJECT_TYPE
,x.CREATED
,x.LAST_DDL_TIME
,x.TIMESTAMP
,x.STATUS
,x.TEMPORARY
,x.GENERATED
,x.SECONDARY
,x.NAMESPACE
,x.EDITION_NAME
);
if ( mod(x.r , 100) = 0 )
then
commit;
end if;
end loop;
commit;
end ;
/
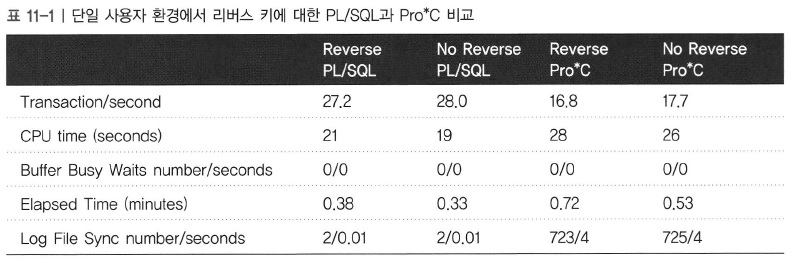 |
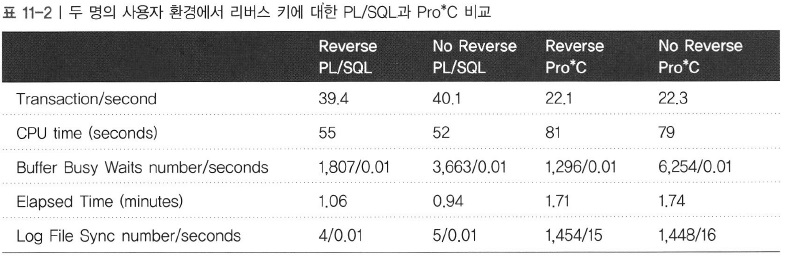 |
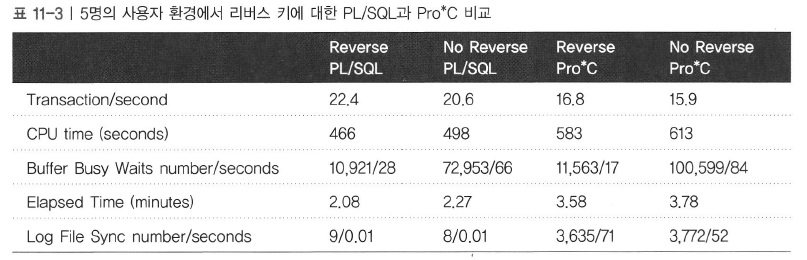 |
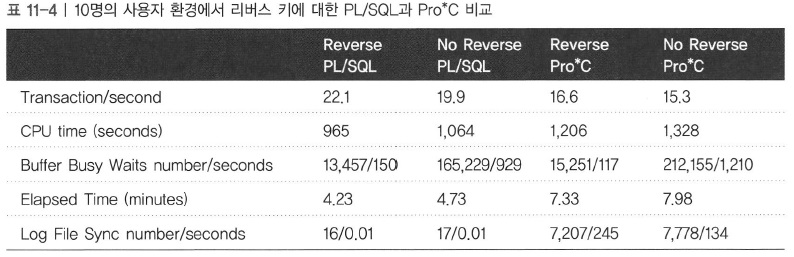 |
-- 인덱스 역순으로 읽은예 - SORT 작업이 없음
drop table t ;
create table t
as
select *
from all_objects;
create index t_idx on t( owner ,object_type , object_name);
begin
dbms_stats.gather_table_stats
( user, 'T' , method_opt=> 'for all indexed columns' );
end;
select owner , object_type
from t
where owner between 'T' and 'Z'
and object_type is not null
order by owner DESC, object_type DESC;
Plan hash value: 2685572958
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 357 | 5712 | 5 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN DESCENDING| T_IDX | 357 | 5712 | 5 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OWNER">='T' AND "OWNER"<='Z')
filter("OBJECT_TYPE" IS NOT NULL)
-- 인덱스 복합 수행 - SORT 작업이 생김
select owner , object_type
from t
where owner between 'T' and 'Z'
and object_type is not null
order by owner DESC, object_type ASC;
Plan hash value: 2813023843
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 357 | 5712 | 6 (17)| 00:00:01 |
| 1 | SORT ORDER BY | | 357 | 5712 | 6 (17)| 00:00:01 |
|* 2 | INDEX RANGE SCAN| T_IDX | 357 | 5712 | 5 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER">='T' AND "OWNER"<='Z')
filter("OBJECT_TYPE" IS NOT NULL)
--owner 인덱스 내림차순 , object_type 오름차순 수행 - SORT 작업이 없음
drop index t_idx;
create index t_idx on
t(owner desc , object_type asc) ;
select owner , object_type
from t
where owner between 'T' and 'Z'
and object_type is not null
order by owner DESC, object_type ASC;
Plan hash value: 2946670127
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 357 | 5712 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| T_IDX | 357 | 5712 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access(SYS_OP_DESCEND("OWNER")>=HEXTORAW('A5FF') AND
SYS_OP_DESCEND("OWNER")<=HEXTORAW('ABFF') )
filter(SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))>='T' AND
SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))<='Z' AND "OBJECT_TYPE" IS NOT
NULL)
select owner, status
from t
where owner = USER;
Plan hash value: 470836197
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3709 | 48217 | 23 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 3709 | 48217 | 23 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 247 | | 15 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(SYS_OP_DESCEND("OWNER")=SYS_OP_DESCEND(USER@!))
filter(SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))=USER@!)
select count(*)
from t
where owner = USER;
Plan hash value: 293504097
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 15 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 6 | | |
|* 2 | INDEX RANGE SCAN| T_IDX | 3709 | 22254 | 15 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(SYS_OP_DESCEND("OWNER")=SYS_OP_DESCEND(USER@!))
filter(SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))=USER@!)
select * from T where primary_key between :x and :y
drop table colocated ;
create table colocated ( x int, y varchar2(80) );
begin
for i in 1 .. 100000
loop
insert into colocated(x ,y)
values (i, rpad(dbms_random.random,75,'*' ));
end loop;
end;
alter table colocated
add constraint colocated_Pk
primary key(x);
begin
dbms_stats.gather_table_stats( user, 'COLOCATED' ) ;
end;
create table disorganized
as
select x,y
from colocated
order by y;
alter table disorganized
add constraint disorganized_Pk
primary key (x);
begin
dbms_stats.gather_table_stats( user, 'disorganized' ) ;
end;
select *
from
colocated where x between 20000 and 40000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.00 0.00 0 0 0 0
Execute 5 0.00 0.00 0 0 0 0
Fetch 55 0.04 0.03 0 465 0 25250
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 65 0.04 0.03 0 465 0 25250
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 84
Rows Row Source Operation
------- ---------------------------------------------------
5050 TABLE ACCESS BY INDEX ROWID COLOCATED (cr=93 pr=0 pw=0 time=2524 us cost=283 size=1620162 card=20002)
5050 INDEX RANGE SCAN COLOCATED_PK (cr=22 pr=0 pw=0 time=757 us cost=43 size=0 card=20002)(object id 74640)
********************************************************************************
select /*+ index( disorganized disorganized_pk ) */* from disorganized
where x between 20000 and 40000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.00 0.00 0 0 0 0
Execute 5 0.00 0.00 0 0 0 0
Fetch 55 0.06 0.05 0 25355 0 25250
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 65 0.06 0.06 0 25355 0 25250
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 84
Rows Row Source Operation
------- ---------------------------------------------------
5050 TABLE ACCESS BY INDEX ROWID DISORGANIZED (cr=5071 pr=0 pw=0 time=8078 us cost=20041 size=1620162 card=20002)
5050 INDEX RANGE SCAN DISORGANIZED_PK (cr=22 pr=0 pw=0 time=631 us cost=43 size=0 card=20002)(object id 74642)
 |
select
a.index_name,
b.num_rows,
b.blocks,
a.clustering_factor
from user_indexes a, user_tables b
where index_name in ( 'COLOCATED_PK', 'DISORGANIZED_PK')
and a.table_name = b.table_name
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ---------- -----------------
COLOCATED_PK 100000 1252 1190
DISORGANIZED_PK 100000 1219 99921
- 강좌 URL : http://www.gurubee.net/lecture/4043
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.