비용기반의 오라클 원리 (2009년)
정렬과 머지조인
- 보통 오라클에서 order by절, group by절, distinct 연산자, connect by 쿼리, b-tree to bitmap conversions 오퍼레이션, 분석함수, 집합연사, 인덱스 생성 등 많은 경우 정렬처리를 필요로한다.
- 정렬 처리는 아주 일반적인 오퍼레이션이면서 실제 메커니즘과 자원요구량이 잘 알려지지 않았다.
정렬처리 모드(work_area_execution)
- 정렬처리도 해시 조인과 같이 효율성 기준으로 optimal. onepass, multipass과 같이 3가지로 구분한다
- optimal정렬은 순전히 메모리에서만 수행된다. 정렬을 시작할때 데이터 읽기를 진행하면서 점차적으로 메모리가 할당되며, 정렬시작 시 sort_area_size로 설정된 크기(또는 pga_aggregate_target의 5%)만큼의 메모리가 할당되는 것은 아니다
- onepass정렬은 읽은 데이터가 너무 커서 메모리에 더 이상 수용할 수 없을때 나타난다.
- 데이터를 읽어 들이면서 정렬을 수행하다가 가용메모리가 차게 되면 정렬된 데이터집합을 디스크로 덤프하게되는데 이러한 과정은 모든 입력 데이터를 처리할 때까지 반복된다.
- 위 과정이 끝나면 몇 개의 정렬된 run(집합)이 남게 되고 이것을 단일 데이터 집합으로 머지한다.
- 정렬된 모든 run을 전부 읽어 들일 정도로 메모리가 충분히 크다면, 이것이 onepass정렬이 된다.
- multipass정렬은 onepass정렬과 시작은 같다.
- 디스크에 남아 있는 모든 run이 메모리에 한 번에 들어가지 못하고 머지된 결과를 다시 디스크에 쓰는 작업을 정렬이 완료될때까지 반복하는 과정이 추가된다.
- 결국 데이터의 정렬을 위해 여러 번 디스크에 쓰고 읽기가 반복될 수 있다.
- 이때 정렬된 데이터를 반복해서 읽어야하는 횟수를 merge passes횟수라고 하다. (10032트레이스의 max intermediate merge width으로 확인 할 수 있다.)
정렬테스트
테스트에서 보여지는 문제점들..
- 정렬 중에 디스크로 덤프되는 데이터 포맷을 보면 쓰여지는 전체 양이 생각 보다는 훨씬 더 크다.
- 본 사례를 보면 디스크로 덤프된 량이 몇 블록인데(몇 mb)인데 실제 정렬된 순수 데이터 부분은 몇 mb크기에 불과하다
- SORT_AREA_SIZE는 1MB일때 OPTIMAL정렬이 되지 않을 경우 정렬데이터가 1MB까지 도달하고난 후 디스크에 쓰여질거라고 예상했지만 그렇지 않은 이유가 있다.
- 정렬데이터에 순수데이터 뿐아니라 일정한 포멧데이터도 포함된다.
- 또한 메모리 구조에 의한 부가적인 공간도 포함된다.
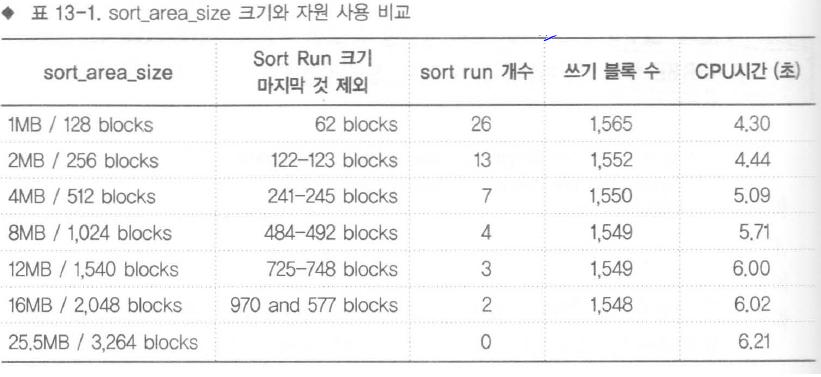
- SORT_AREA_SIZE의 크기를 변경하였을때 CPU시간이 크게 나오는 이유
- 일반적으로 sort가 메모리에서만 실행되면 최적이다라고 생각하고 적절한 sort_area를 지정하여 메모리안에서만 정렬하기를 원한다.
- 그러나 표에서는 예상과는 다르게 sort_area를 키워도 수행속도등 개선사항이 보이지 않느다.
 |
- 필자의 가설 : 오라클 정렬메커니즘의 의한 결과라는 유추
- 일종의 이진삽입트리에 기초로 한다( 이진 트리는 하위노드가 2두개인 트리구조이다)
- 인덱스의 B-Tree에서도 트리가 성장할때 많은 비용이 들어가는데 이진트리인 경우 특성상 DEPTH가 깊으므로 더 많은 상위 노드과 거기에 딸려 있는 노드들이 영향을 받을 것이다
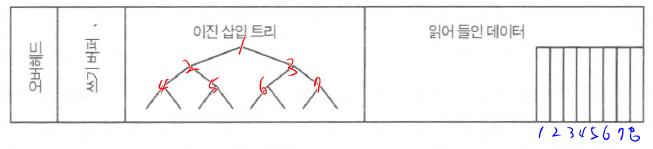 |
수행된 총비교횟수에 차이가 나지 않는다.
- 메모리 상의 이진트리가 길어지면 탐색시간이 증가한다는 것을 실험적으로 알 수 있다.
- 병목이 i/o가 아닌 메모리정렬에 의한 것이라면 in-memory보다는 onepass정렬로 유도할 수 있도록 memory를 설정하여 대량정렬 시 성능향상을 유도할 수 있다고 한다.
- 어째튼 sort_area는 multi-pass정렬이 되지 않을 정도 그리고 가능한 작게 설정한다.
정렬에 영향을 미치는 파라미터
sort_area_retained_size의 영향(10.2 default 0)
- sort_area_retained_size를 0이 아닌 다른 값을 설정하게 되면 오라클은 클라이언트로 결과를 반환하기 전에 모든 데이터를 디스크로 덤프하도록 한다.
- 정렬데이터를 처리할때 처음은 UGA에서 시작한다. 할당된 메모리가 sort_area_retained_size를 넘어가면 그 다음 할당은PGA에서 이루어 진다. 비록 정렬이 메모리안에서 이루어진다고 해도UGA와 PGA가 분할되어 있다면 전체 정렬데이터 집합을 디스크로 덤프해야 한다.
pga_aggregate_target
- workarea_policy = auto로 설정하면 정렬, 해시조인, 인덱스생성, 비트맵인덱스 처리등과 같은 대량의 메모리요구를 하는 프로세스에서 사용해야 하는 메모리 전체한도의 적정선을 의미한다.
- 병렬처리가 아닌 정렬처리의 경우 pga_aggregate_target의 5%까지 메모리를 할당 받을 수 있으며, 병렬처리일 경우 salve 프로세스가 사용하는 작업영역의 메모리 합계가 pga_aggregate_target의 30%를 넘을 수 없다.
- 병렬처리시의 메모리사용량을 변경할 수 있는 hidden파라미터
- _smm_px_max_size : 병렬처리 시 메모리한도를 설정
- _smm_max_size : 직렬처리 시 최대 메모리한도를 설정(디폴트 pga_aggregate_target의 5%)
- -smm_min_size : 직렬처리 시 최소 메모리한도를 설정(디폴트 pga_aggregate_target의 0.1%)
- _smm_auto_min_io_size, _smm_auto_max_io_size : sort run 머지 시 보다 큰 i/o크기를 사용하면 더 커진 메모리 할당의 이점을 누릴 수 있다.
- 여튼 workarea_policy = auto이며 pga_aggregate_target 디폴트 200MB를 사용한 경우 샘플코드를 수행하면서 최적의 메모리를 사용한다.
정렬 비용
- 4가지 설정 시 정렬비용 비교
- 가설이 너무 많아 pass, 단 cpu costing 방식일때 MBRC값에 따라 비용이 변경될 수 있음
머지조인
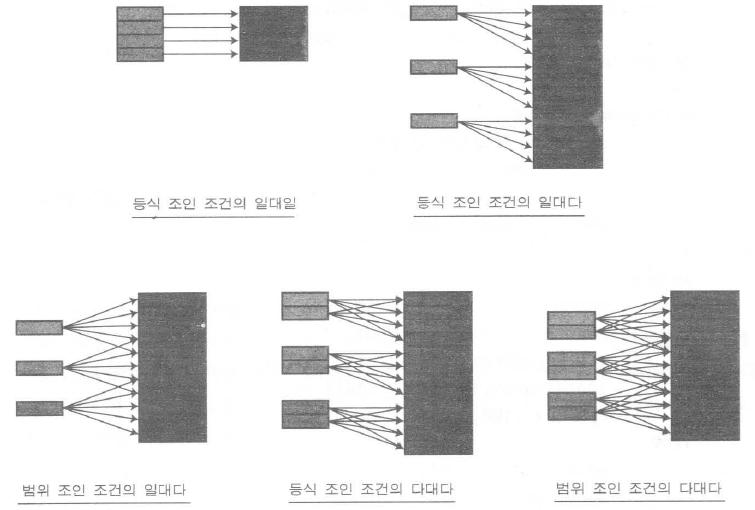
- 머지조인을 보통 sort merge join이라고 하는 것은 조인의 양쪽 대상 집합 모두가 조인 컬럼 순으로 정렬되어야 하기 때문이다.
- 해시 조인 처럼 조인을 두개의 독립된 쿼리로 분해하고 결과집합을 다시 결합하는 것이다.
- 그러나 해시 조인과는 달리 두 번째 쿼리 부분을 시작하기 전에 첫 번째 쿼리부분을 끝내야할 필요는 없다.(정렬을 한다는 것은 두 집합이 각각 실행완료된것을 의미하지 않을까?)
동작순서
- 액세스와 필터 조건절을 사용하여 첫 번째 데이터 집합을 획득하고 그것을 조인 컬럼 순으로 정렬한다.
- 액세스와 필터 조건절을 사용하여 두 번째 데이터 집합을 획득하고 그것을 조인 컬럼 순으로 정렬한다.
- 첫 번째 데이터 집합의 각 로우에 대해 두 번째 데이터 집합에서 시작점을 찾고 조인에 실패하는 로우를 만날 때까지 스캔한다.(각각 집합이 정렬되어 있으므로 중단지점을 알 수 있다.)
sort merge에 대해 알고 있던 내용과 다른 점
- 적절한 인덱스가 있으면 두 번째 집합을 획득하기 전에 전체를 처리하지 않아도된다.
- 머지조인은 첫번째 집합을 정렬할 필요가 없다.
- 정렬준비가 완료된 후에라야 조인을 시작할 수 있으므로 원초적으로 부분범위처리를 할 수 없어 항상 전체범위처리를 한다
- 동시적으로 처리된다. 조인 대상 집합은 각자가 상대 집합의 처리결과와 상관없이 자신이 보유한 처리조건만 가지고 액세스하여 정렬해 둔다. 양쪽 집합이 모두 준비가 완료되어야만 머지를 시작할 수 있으므로 순차적인 처리가 불가능하다
- http://wiki.gurubee.net/pages/viewpage.action?pageId=1966755
 |
alter session set hash_join_enabled = false;
create table t1 as
with generator as (
select --+ materialize
rownum id
from all_objects
where rownum <= 3000
)
select rownum id,
rownum n1,
trunc((rownum - 1)/2) n2,
lpad(rownum,10,'0') small_vc,
rpad('x',100,'x') padding
from generator v1,
generator v2
where rownum <= 10000;
alter table t1 add constraint t1_pk primary key(id);
select count(distinct t1_vc || t2_vc)
from (select /*+ no_merge ordered use_merge(t2) */
t1.small_vc t1_vc
t2.small_vc t2_vc
from t1,
t2,
where
t1.n1 <= 1000 and t2.id = t1.id -- 1번
t1.n1 <= 1000 and t2.n2 = t1.id -- 2번
t1.n1 <= 1000 and t2.id between t1.id -1 and t1.id +1 -- 3번
t1.n1 <= 1000 and t2.n2 = t1.id -- 4번
t1.n1 <= 1000 and t2.id = t1.id -- 5번
);
집계
- 집계query 수행 시 기본적인 실행계획
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 1 | 26 | 3 (34)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 1 | 26 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------
- 각 문장에 따른 변화는 id =1번의 오퍼레이션이 조금씩 바뀌지만 골격은 바뀌지 않는다.
- 단 10g부터는 Hash Group by(Hash unique)오퍼레이션이 있는 데 대부분의 경우 sort group by보다 빠르게 수행된나 기존 정렬의 효과는 없다.
select col1, col2 from t1 order by col1, col2;
| 1 | SORT ORDER BY | | 1 | 26 | 3 (34)| 00:00:01 |
select distinct col1, col2 from t1;
| 1 | HASH UNIQUE | | 1 | 26 | 3 (34)| 00:00:01 | <- 책은 Sort (unique)
select col1, col2, count(*) from t1 group by col1, col2;
| 1 | SORT GROUP BY | | 1 | 26 | 3 (34)| 00:00:01 |
select col1, col2, count(*) from t1 group by col1, col2 order by col1, col2;
| 1 | SORT GROUP BY | | 1 | 26 | 3 (34)| 00:00:01 |
select max(col1), max(col2) from t1;
| 1 | SORT AGGREGATE | | 1 | 26 | | |
인덱스
- 단일 테이블을 읽어 인덱스를 만드는 경우 데이터 정렬이 전체 일량의 대부분을 차지한다. (특정 컬럼을 기준으로 정렬을 해야하기 때문)
- B-tree 인덱스를 만들기 위한 필요 메모리 양을 계산하고자 하면 추가적인 컬럼 (Rowid)르 고려해야 한다.
- rowid의 크기
- 힙테이블 : 6 byte
- 클러스터 인덱스 : 8 byte
- 파티션 테이블의 global인덱스 : 10 byte
- 파티션 테이블의 local 인덱스 : 6 byte
집합연산자
- Union(합집합) : 양측 집합 중 어느 쪽에든 존재하는 로우
- Intersect(교집합) : 양측 집합 모두에 존재하는 로우
- Minus(차집합) : 첫 번째 집합 중 두 번째 집합에 없는 로우
- 기술적으로 볼때 집합 연산자는 중복을 허용하지 않으므로 중복을 허용하는 Union all 집합 연산자가 아니다.
alter session set "_optimizer_cost_model"=io
drop table t1 purge;
create table t1 as
select rownum id, ao.*
from all_objects ao
where rownum <= 2500;
drop table t2 purge;
create table t2 as
select rownum id, ao.*
from all_objects ao
where rownum <= 2000;
- 각각 집합에 대한 유일성을 강제한 후 집합연산을 하는 경우의 쿼리
select distinct owner, object_type from t1
intersect
select distinct owner, object_type from t2;
- 집합연산자는 unique한 결과를 반환한다는 점을 반영한 쿼리
select owner, object_type from t1
intersect
select owner, object_type from t2;
- 불필요한 오퍼레이션에 의해 부가적인 정렬연산을 일으킬 것이라 생각했지만 옵티마이져는 두사례를 동일한 일량으로 처리하는것을 볼 수 있다.
- cpu 모델은 비용이 같도록 계산되나 i/o 모델은 비용으로 다른 비용 가질 수 있다는데...
--위 쿼리
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 2000 | 123K| 45
| 1 | INTERSECTION | | | |
| 2 | SORT UNIQUE | | 2500 | 70000 | 24
| 3 | TABLE ACCESS FULL| T1 | 2500 | 70000 | 5
| 4 | SORT UNIQUE | | 2000 | 56000 | 21
| 5 | TABLE ACCESS FULL| T2 | 2000 | 56000 | 4
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2000 | 123K| 20 (50)| 00:00:01 |
| 1 | INTERSECTION | | | | | |
| 2 | SORT UNIQUE | | 2500 | 70000 | 11 (10)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T1 | 2500 | 70000 | 10 (0)| 00:00:01 |
| 4 | SORT UNIQUE | | 2000 | 56000 | 9 (12)| 00:00:01 |
| 5 | TABLE ACCESS FULL| T2 | 2000 | 56000 | 8 (0)| 00:00:01 |
----------------------------------------------------------------------------
--아래 쿼리
------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2000 | 123K| 45 |
| 1 | INTERSECTION | | | | |
| 2 | SORT UNIQUE | | 2500 | 70000 | 24 |
| 3 | TABLE ACCESS FULL| T1 | 2500 | 70000 | 5 |
| 4 | SORT UNIQUE | | 2000 | 56000 | 21 |
| 5 | TABLE ACCESS FULL| T2 | 2000 | 56000 | 4 |
------------------------------------------------------------
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2000 | 123K| 20 (50)| 00:00:01 |
| 1 | INTERSECTION | | | | | |
| 2 | SORT UNIQUE | | 2500 | 70000 | 11 (10)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T1 | 2500 | 70000 | 10 (0)| 00:00:01 |
| 4 | SORT UNIQUE | | 2000 | 56000 | 9 (12)| 00:00:01 |
| 5 | TABLE ACCESS FULL| T2 | 2000 | 56000 | 8 (0)| 00:00:01 |
----------------------------------------------------------------------------
alter session set "_optimizer_cost_model"=cpu;
alter session set statistics_level = all;
alter session set optimizer_features_enable = '9.2.0';
explain plan for
create table t_intersect as
select distinct *
from ( select owner, object_type from t1
intersect
select owner, object_type from t2
);
select * from table(dbms_xplan.display());
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | CREATE TABLE STATEMENT | |
| 1 | LOAD AS SELECT | T_INTERSECT |
| 2 | SORT UNIQUE | |
| 3 | VIEW | |
| 4 | INTERSECTION | |
| 5 | SORT UNIQUE | |
| 6 | TABLE ACCESS FULL| T1 |
| 7 | SORT UNIQUE | |
| 8 | TABLE ACCESS FULL| T2 |
----------------------------------------------
alter session set optimizer_features_enable = '10.2.0.1';
explain plan for
create table t_intersect as
select distinct *
from ( select owner, object_type from t1
intersect
select owner, object_type from t2
);
select * from table(dbms_xplan.display());
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | CREATE TABLE STATEMENT | | 2000 | 56000 | 30 (10)| 00:00:01 |
| 1 | LOAD AS SELECT | T_INTERSECT | | | | |
| 2 | HASH UNIQUE | | 2000 | 56000 | 27 (12)| 00:00:01 |
| 3 | VIEW | | 2000 | 56000 | 26 (8)| 00:00:01 |
| 4 | INTERSECTION | | | | | |
| 5 | SORT UNIQUE | | 2500 | 70000 | 11 (10)| 00:00:01 |
| 6 | TABLE ACCESS FULL| T1 | 2500 | 70000 | 10 (0)| 00:00:01 |
| 7 | SORT UNIQUE | | 2000 | 56000 | 9 (12)| 00:00:01 |
| 8 | TABLE ACCESS FULL| T2 | 2000 | 56000 | 8 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
- 9i와 10g에서 같은 쿼리를 실행하였을 때 9i에서 불필요한 오퍼레이션을 보여주지 않았지만 10g에서는 불필요한 연산에 대한 부분이 나온다.
- 그러나 9i실행계획이 잘못된 것이며 실제 10032트레이로 확인 하면 9i도 10g와 같은 중간연산을 하는 것을 확인할 수 있다.(위 테스트에서는 적용되지 않음)
마지막 당부
- 런타임 시에 엔진이 수행하는 것이 옵티마이저가 비용계산 시에 생각한 그대로일 필요는 없다는 것이다.
10032 항목
- max intermediate merge width multi-pass 정렬을 해야할 때, 오라클이 한 번에 읽고 머지할 수 있는 sort run의 수
- number of merges 스트림머지를 한 수
- Inital runs 오라클이 추산한 디스크로 덤프하게 될 sort runs의 개수(Block to sort * 블록크기 / area size)로 계산된다.\
- Number of direct sync 직접읽기대기회수
- Number of direct writes 직접쓰기대기회수 (오류로 정확하지 않은것 같다.)
10053 항목
- sort_with = max intermediate merge width
- Merge passes 전체 데이터 집합이 디스크로 쓰여졌다가 다시 읽혀지는 횟수이다.
- inital runs가 Sort width보다 적으면 한번의 pass로 머지됨을 의미한다.
- Area size 데이터처리목적으로 사용된 메모리양(pga_aggregate_target에 기초한 최소할당양)
- Max Area size 해당 세션에서 받을 수 있는 최대 할당양
- Degree 병렬처리외 직렬처리 시 각각의 정렬비용계산내역을 별도의 섹션으로 보여준다.
- Rows 테이블의 계산된(필터링된) 카디널리티이다.
- Area_size를 늘이지 않고도 Row갯수를 떨어뜨릴 수 있기 때문에 병렬처리를 이용하면 정렬비용을 손쉽게 낮출 수 있다.
- Block to sort 정렬될 데이터양으로 "로우크기*로우개수/블록크기"로 산출된다.
- Row size 옵티마이져가 추산한 정렬 데이터의 평균 row길이이다.
- Total IO sort cost '아마도' cost per pass와 pass회수가 결합된 값이다.
- Total CPU sort cost 비용중 CPU에 해당하는 부분으로서 CPU오퍼레이션 수 단위이고, 트레이스파일을 보면 나중에 상응하는 비교적 작은 I/O비용으로 전환한다.
- Total Temp space used 정렬 오퍼레이션이 요구하는 임시 영역의 이론적인 크기
"코어 오라클 데이터베이스 스터디모임" 에서 2009년에 "비용기반의 오라클 원리
" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3986
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.