press x to close
select t1.cola,
t2.colb
from table_1 t1,table_2 t2
where t1.colx = {value}
and t2.id1 = t1.id1
;
-- 위의 Query를 For문으로 작성하면 다음과 같다.
for r1 in (select rows from table_1 where colx = {value}) loop
for r2 in (select rows from table_2 that match current row from table_1) loop
output values from current row of table_1 and current row of table_2
end loop
end loop
Execution Plan (9.2.0.6 autotrace - unique access on inner table (traditional))
-------------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=324 Card=320 Bytes=11840)
1 0 NESTED LOOPS (Cost=324 Card=320 Bytes=11840)
2 1 TABLE ACCESS (FULL) OF 'DRIVER' (Cost=3 Card=320 Bytes=2560)
3 1 TABLE ACCESS (BY INDEX ROWID) OF 'TARGET' (Cost=2 Card=1 Bytes=29)
4 3 INDEX (UNIQUE SCAN) OF 'T_PK' (UNIQUE) (Cost=1 Card=1)
Execution Plan (9.2.0.6 autotrace - range scan on inner table (new option))
---------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=322 Card=319 Bytes=11803)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TARGET' (Cost=2 Card=1 Bytes=29)
2 1 NESTED LOOPS (Cost=322 Card=319 Bytes=11803)
3 2 TABLE ACCESS (FULL) OF 'DRIVER' (Cost=3 Card=319 Bytes=2552)
4 2 INDEX (RANGE SCAN) OF 'T_PK' (UNIQUE) (Cost=1 Card=1)
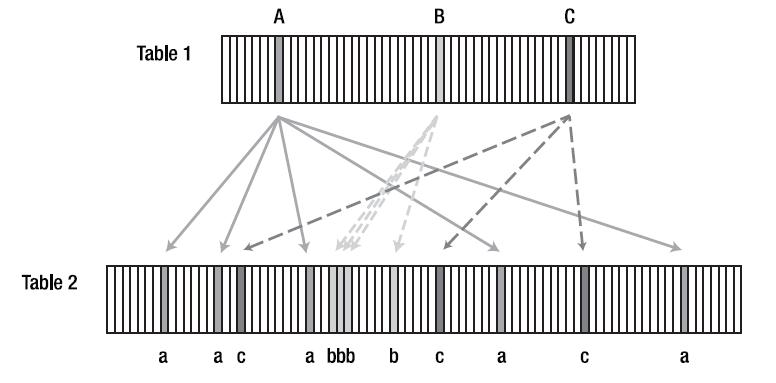 |
| 그림1. Nested Loop Join |
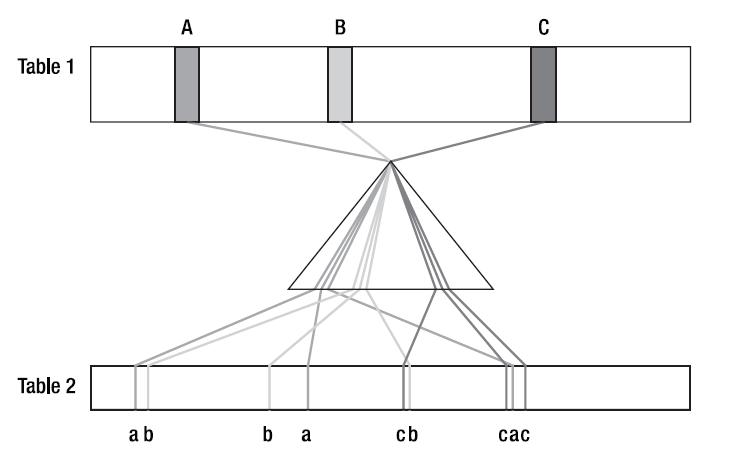 |
| 그림2. 인덱스를 경유한 Nested Loop 조인 |
- 강좌 URL : http://www.gurubee.net/lecture/3984
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.