비용기반의 오라클 원리 (2009년)
ch10. 조인 카디널리티
- 오라클은 FROM절에 얼마나 많은 테이블을 기술할 수 있느냐는 별개로 조인 시 한번에 두개 오브젝트만을 처리한다.
- 다섯개의 테이블을 조인하기 위해 옵티마이저는 어느 한 테이블을 시작으로 다른 한 테이블과 조인한다.
- 결과로서 만들어진 중간결과 집합을 다른 테이블과 조인하고, 다시 그 결과집합을 또 다른 테이블과 계속해서 조인하는 방식이다.
조인 카디널리티 기본
-- 조인 선택도를 구하는 공식
Sel = 1 / max[(NDV(t1.c1), NDV(t2.c2)] *
((card t1 - # t1.c1 NULLS) / card t1) *
((card t2 - # t2.c2 NULLS) / card t2)
조인 선택도 =
((num_rows(t1) - num_nulls(t1.c1)) / num_rows(t1)) *
((num_rows(t2) - num_nulls(t2.c2)) / num_rows(t2)) *
greater(num_distinct(t1.c1), num_distinct(t2.c2))
-> user_tables.num_rows
-> user_tab_col_statistics.num_nulls
-> user_tab_col_statistics.num_distinct
-- 조인 카디널리티(Cardinality)를 구하는 공식
Card(Pj) = card(t1) * card(t2) * sel(Pj)
조인 카디널리티 =
조인 선택도 *
필터된 카디널리티(t1) * 필터된 카디널리티(t2)
--> 필터된 카디널리티 : 조인조건외의 다른 조건들을 각 테이블에 적용한 것.
-- (조인 조건중 일부가 필터 조건처럼 작용할 수 도 있다)
create table t1 AS
SELECT trunc(dbms_random.value(0, 25 )) filter,
trunc(dbms_random.value(0, 30 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 50 )) filter,
trunc(dbms_random.value(0, 40 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.filter = 1
AND t2.join1 = t1.join1
AND t2.filter = 1 ;
- 생성된 데이터
- t1.filter 25 values
- t2.filter 50 values
- t1.join1 30 values
- t2.join1 40 values.
- 조인 카디널리티
Join Selectivity =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) = 1/40
Join Cardinality = 1/40 * (400 * 200) = 2000
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=2000 Bytes=68000)
1 0 HASH JOIN (Cost=57 Card=2000 Bytes=68000)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=200 Bytes=3400)
3 2 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=400 Bytes=6800)
- NULL 값을 포함할 때도 계산식이 잘 들어 맞는지 확인.
- t1 테이블은 20번째 로우마다 t2 테이블은 30번째 로우마다 조인컬럼이 NULL 값을 갖도록 데이터 갱신
update t1 set join1 = null
where mod(to_number(v1),20) = 0;
-- 500 rows updated
update t2 set join1 = null
where mod(to_number(v1),30) = 0;
-- 333 rows updated
- 조인 카디널리티
Join Selectivity =
(10,000 - 500) / 10,000) *
(10,000 - 333) / 10,000) /
greater(30, 40) = 0.022959125
Join Cardinality = 400 * 200 * 0.022959125 = 1,836.73
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1837 Bytes=62458)
1 0 HASH JOIN (Cost=57 Card=1837 Bytes=62458)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=200 Bytes=3400)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=400 Bytes=6800)
- 필터 컬럼의 일부 레코드도 NULL 값으로 치환
update t1 set filter = null
where mod(to_number(v1),50) = 0;
-- 200 rows updated
update t2 set filter = null
where mod(to_number(v1),100) = 0;
-- 100 rows updated
- 필터조건(filter = 1) 컬럼에 NULL 값이 존재하므로 테이블별로 필터된 카디널리티만 다시 계산.
Adjusted (computed) Cardinality = Base Selectivity * (num_rows - num_nulls)
. For table t1 we have 1/25 * (10,000 . 200) = 392.
. For table t2 we have 1/50 * (10,000 . 100) = 198.
- 조인 카디널리티
Join Cardinality = 392 * 198 * 0.022959125 = 1,781.995
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1782 Bytes=60588)
1 0 HASH JOIN (Cost=57 Card=1782 Bytes=60588)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=198 Bytes=3366)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=392 Bytes=6664)
- 조인 컬럼이 두 개 이상이라면 어떻게 계산해야 할까?
- 조인절에 범위 검색 조건(range scan)을 포함한다면 어떻게 해야 할까?
- 3개 이상의 테이블을 조인한다면 어떻게 해야 할까?
- 공식을 보면, 양쪽 조인 컬럼 값의 범위가 일부만 겹치는, 즉 일부 값들만 조인에 성공하는 경우에 대해서는 고려하고 있지 않은 것 같은데, 그 이유는 무엇일까?
- 히스토그램 정보가 있다면 조인 카디널리티 계산에 어떤 영향을 미칠까?
한 쪽에만 필터조건을 적용한 경우
create table t1 AS
SELECT trunc(dbms_random.value(0, 100 )) filter,
trunc(dbms_random.value(0, 30 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 1000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 100 )) filter,
trunc(dbms_random.value(0, 40 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 1000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 = t1.join1
-- and t1.filter = 1
AND t2.filter = 1 ;
- 테이블 t1의 조인컬럼에는 30개의 distinct 값을, t2의 조인컬럼에는 40개의 distinct 값을 갖는다.
Join Selectivity =
(1000 / 1000) * (1000 / 1000) / greater(30, 40) =
1/40 = 0.025
Join Cardinality =
Join Selectivity *
filtered cardinality(t1) * filtered cardinality(t2) =
0.025 * 10 * 1000 = 250
- autotrace 결과
Execution Plan (9.2.0.6 Filter on just T1)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=11 Card=250 Bytes=7750)
1 0 HASH JOIN (Cost=11 Card=250 Bytes=7750)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=5 Card=10 Bytes=170)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=5 Card=1000 Bytes=14000)
Execution Plan (9.2.0.6 Filter on just T2)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=11 Card=333 Bytes=10323)
1 0 HASH JOIN (Cost=11 Card=333 Bytes=10323)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=5 Card=10 Bytes=170)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=5 Card=1000 Bytes=14000)
- 필터 테이블을 바꾸었는데, 조인 후 결과집합의 카디널리티가 바뀌었다.
- 두 개의 num_distinct 중 더 큰쪽을 이용하는게 아니라 필터 조건이 없는 쪽 테이블의 num_distinct 값을 사용한다.
- (옵티마이저가 어느 테이블의 num_distinct값을 사용할지를 결정하는 데에 필터 조건이 영향을 미치는 일반적인 규칙에서 벗어나는 매우 특별한 케이스에 해당한다(필자생각))
- -> t2에만 필터조건을 사용할 때는 기본 공식에 따라 더 큰 num_distinct 값 40을 사용하지 않고 t1테이블의 num_distinct 값 30을 사용하게 된 것이다.
실환경에서의 조인 카디널리티
- 두 테이블 조인 시 둘 이상의 컬럼이 사용될 경우는 어떻게 될까?
- 단일 테이블에 대한 다중 조건절을 처리할 때 했던 방식과 같은 전략을 사용한다.
- 선택도 구하는 공식은 각 조건절마다 차례로 한 번씩 적용하고 그 값들을 곱하기만 하면 최종 조인 선택도가 구해진다.
create table t1 AS
SELECT trunc(dbms_random.value(0, 30 )) join1,
trunc(dbms_random.value(0, 50 )) join2,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 40 )) join1,
trunc(dbms_random.value(0, 40 )) join2,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 = t1.join1
AND t2.join2 = t1.join2 ;
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=50000 Bytes=1700000)
1 0 HASH JOIN (Cost=60 Card=50000 Bytes=1700000)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=170000)
- 조인선택도
Join Selectivity =
{join1 bit} *
{join2 bit} =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) * -- uses the t2 selectivity (1/40)
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(50, 40) = -- uses the t1 selectivity (1/50)
1/40 * 1/50 = 1/2000
- 10g autotrace 결과 (다른 결과 출력 - 역으로 조사)
Execution Plan (10.1.0.4 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=62500 Bytes=2125000)
1 0 HASH JOIN (Cost=60 Card=62500 Bytes=2125000)
2 1 TABLE ACCESS (FULL) OF 'T1' (TABLE) (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (TABLE) (Cost=28 Card=10000 Bytes=170000)
- 조인선택도
62,500 = 100,000,000 * join selectivity.
Join selectivity = 62,500 / 100,000,000 = 1/1,600
- 옵티마이저는 두 개의 선택도를 양쪽 테이블에서 하나씩 취한 게 아니라 두 테이블 중 어느 한 쪽을 선택하고 거기서 두개의 선택도를 취했다.
- 10053 트레이스
Table: T1 Multi-column join key card: 1500.000000 (30 * 50)
Table: T2 Multi-column join key card: 1600.000000 (40 * 40)
Using multi-column join key sanity check for table T2
Revised join selectivity: 6.2500e-004 = 5.0000e-004 * (1/1600) * (1/5.0000e-004)
Join Card: 62500.00 = outer (10000.00) * inner (10000.00) * sel (6.2500e-004)
- 간단히 두 테이블을 조인하는 경우에는 10g 에서 계산방식이 대체되어 항상 이런 sanity check가 일어난다(11장에서 설명)
- 양쪽 조인 컬럼 중 num_distinct가 큰 값을 선택하는 작업을 조인 조건절마다 차례로 수행.
- 각테이블 조인 컬럼들의 num_distinct 값을 조회해서 테이블별 선택도를 따로따로 구한 후에 그 중 작은 값을 사용.
- _optimizer_join_sel_sanity_check 파라미터로 이 행동을 제어할 것이다.
- 개별 테이블에 대한 다중컬럼 조인키 카디널리티가 그 테이블에 대한 1/num_rows 보다 작다면 계산된 값 대신 1/num_rows를 사용.
확장과 예외
범위조건에 의한 조인
- 옵티마이저가 범위(t2.join1>t1.join1)기반 조인문을 만났을때는 조인 조건절의 선택도로서 미리 정해 둔 고정된 상수를 이용.(5%)
- t2.join1 between t1.join1 - 1 and t1.join1 + 1 은 두개의 독립적이 조건절 "join1 >= :bind1 and join1 <= :bind2"로 처리하여 1/20과 1/20을 곱해서 1/400(0.025%)의 선택도를 계산한다.
- 조인절 t2.join1=t1.join1일 때의 결과 집합이 t2.join1 between t1.join1 - 1 and t1.join2 + 1 의 부분집합인데, 계산된 카디널리티를 보면 거꾸로 2전자가 2,000, 후자는 200이라는 점을 주목하라.
- 일관성에 문제가 있고, 범위기반 조인의 계산 전략에 진지하게 고민해 볼 필요가 있다.
부등호 조인
- t1.join1 != t2.join1의 선택도는 1에서 (t1.join1 = t2.join1의 선택도를 빼면 된다.
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 != t1.join1 -- (30 / 40 values for num_distinct)
AND t2.join2 != t1.join2 -- (50 / 40 values for num_distinct)
;
- 두 조인조건이 등호일 경우 1/40 * 1/50 공식을 사용하므로, 반대로 둘 다 부등호일 때는 39/40 * 49/50 공식을 사용하면 된다.
- 두 조인조건을 OR연산자로 했을경우에는 잘못된 카디널리티를 보여준다(버그)
- 이 경우 옵티마이저가 묵시적으로 concatenation 실행계획을 생성하도록 UNION ALL을 이용해 두 개의 조인문으로 분기해라.
조인하는 두 집합이 완전히 겹치지 않는 경우
- 두 집합이 서로 중복되는 비율이 낮아질수록 조인 카디널리티에 어떤변화가 발생하는지 살펴보자.
- join1 컬럼의 distinct 값은 양쪽 모두 100개,
- t1.join1이 갖는 값의 범위를 -100 ~ -1 부터 100 ~ 199 까지 계속 값의 범위를 변경
- t2.join1 컬럼의 값은 항상 0 ~ 99
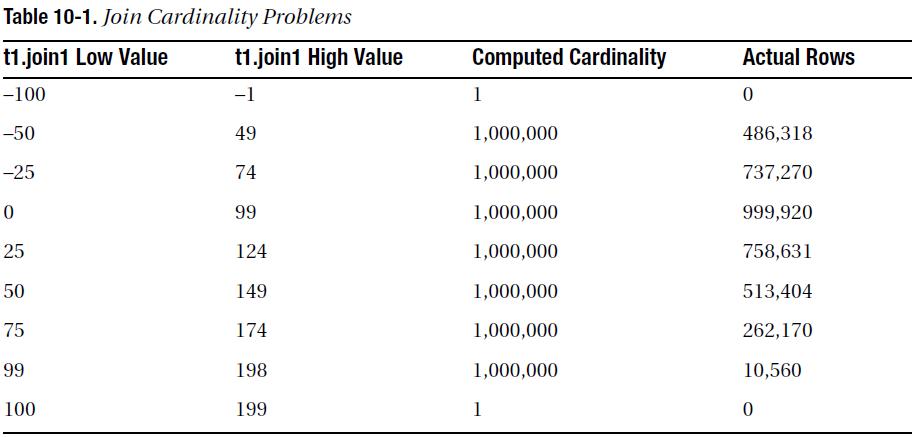
- 9i, 10g에서는 서로 일치하는 값이 전혀 없는 경우를 제외하면 양쪽 집합이 100% 조인한다는 가정하에 카디널리트를 계산.
- (8i에서는 두 집합간에 겹치는 데이터가 전혀 없는 경우에도 카디널리티를 1,000,000으로 계산)
히스토그램
- 조인 카디널리티 계산 시 조인조건에 포함된 두 컬럼들의 히스토그램 정보를 이용한다.(9i/10g 결과)
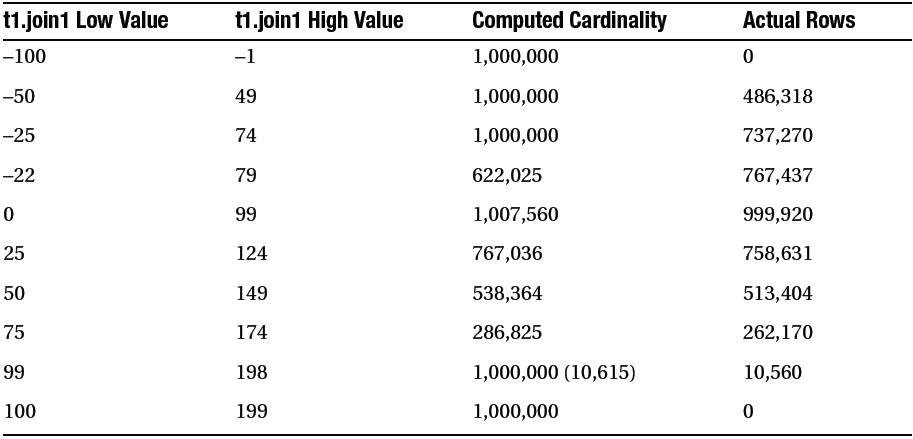
- 첫번째 버킷사이즈 85(height balanced), 두번째 254(frequency)로 히스토그램 생성.
- 첫번째는 중복된 집합에 대서 만큼은 완벽하지 않지만 어느 정도 정밀하고 합리적인 값으로 계산
- 두번째는 최저값을 100 또는 -100으로 바꾸었을때만 1,000,000으로 계산되고, 이외에는 실제 로우 개수와 거의 일치하는 값으로 계산.()의 값.
- 일반적으로 사용되는 히스토그램은 height balanced 형태이다.
- 첫번째에서 -22와 75 사이일때 실제 로우 수와 거의 가까운 값을 계산해 내고 있다.
- (이 구간에서 양쪽 테이블 중 하나의 히스토그램에 빈번한 값(popular value)이 있는것으로 나타났다)
- 아래 조건을 모두 만족할때 옵티마이저는 히스토그램을 활용하는 어떤 방법을 동원함으로서 더 나은 조인 실행계획을 만들어 내는 것 같다.
- 9i/10g 에서 수행
- 등호(=)로 조인되는 양쪽 컬럼 무두에 히스토그램을 생성.
- 적어도 둘 중 하나가 두수분포(frequency) 히스토그램이거나 빈번한 값(popluar value)이 있는것으로 나타난다.
- 8i에서는 히스토그램이 완전한 도수 분포 히스토그램이 아닌 경우에 다소 부정확한 결과가 나온다.
- 도수분포 히스토그램을 생성할 수 없을 때(빈번한 값(popular value)이 있을때) 그런 값들을 잘 표현하기 위한
적정한 버킷 개수를 몇 개로 선택할지가 고민거리다.(알아서 찾아내라???)
1. 적정한 버킷 개수 선택하기.
- 히스토그램 생성 시 요청할 수 있는 가장 큰 버킷 개수는 254.
- 컬럼에 대한 히스토그램이 유익할 것으로 판단되면 최적의 버킷 개수를 찾기 위한 추정치로서 처음부터 아예 가장 큰 값을 지정해도 좋다.
- 히스토그램의 정밀도를 높임으로써 얻을 수 있는 잠재적인 이익을 고려하면, 초과버킷(기본값은 75)에 의한 한?비용은 중요하지 않다.
2. 도수분포(FREQUENCY) 히스토그램과 DBMS_STATS
- dbms_stats 패키지를 통해 도수분포 히스토그램을 생성할 때 문제가 있다.
- 위의 예에서 100이상의 버킷 개수를 요청해도 높이균형 히스토그램이 생성된다. 134를 넘는 순간부터 도수분포 히스토그램이 생성된다.
이행적 폐쇄
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.join1 = 20 -- 30 distinct values
AND t2.join1 = t1.join1 -- 40 / 30 distinct values
AND t2.join2 = t1.join2 -- 40 / 50 distinct values
;
- t1.join1 = 20이 없을 경우
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=50000 Bytes=1700000)
1 0 HASH JOIN (Cost=60 Card=50000 Bytes=1700000)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=170000)
- 조건 추가했을경우
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1667 Bytes=56678)
1 0 HASH JOIN (Cost=57 Card=1667 Bytes=56678)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=250 Bytes=4250)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=333 Bytes=5661)
- dbms_xplan
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1667 | 56678 | 57 |
|* 1 | HASH JOIN | | 1667 | 56678 | 57 |
|* 2 | TABLE ACCESS FULL | T2 | 250 | 4250 | 28 |
|* 3 | TABLE ACCESS FULL | T1 | 333 | 5661 | 28 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
1 - access("T2"."JOIN2"="T1"."JOIN2")
2 - filter("T2"."JOIN1"=20)
3 - filter("T1"."JOIN1"=20)
Join Selectivity =
((num_rows(t1) - num_nulls(t1.c1)) / num_rows(t1)) *
((num_rows(t2) - num_nulls(t2.c2)) / num_rows(t2)) /
greater(num_distinct(t1.c1), num_distinct(t2.c2))
Join Cardinality =
join selectivity *
filtered cardinality(t1) * filtered cardinality(t2)
Join Selectivity =
((10000 - 0)/ 10000) *
((10000 - 0)/ 10000) /
greater(40, 50) = -- t1.join2, t2.join2 (num_distinct)
1/50
Join Cardinality =
(1 / 50) *
10000/30 * 10000/40 = -- t1.join1 has 30 values, t2.join1 has 40
333 * 250 / 50 =
1,666.66
- Predicate Information를 보면 이행적 폐쇄(transitive closure)의 매카니즘에 의해 두개의 필터조건과 단일 조인 컬럼을 갖는 형태로 바뀌었다.
- 9i, 10g의 결과가 같게 나타난다(이행성 폐쇄과정에서 두 개의 조인 조건중 하나가 제거되었기 때문에 10g에서 snity check가 일어나지 않는다.)
- 필요 이상의 조건정을 명시적으로 추가할 경우 어떤일이 일어날까?
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.join1 = 20 -- 30 distinct values
AND t2.join1 = t1.join1 -- 40 / 30 distinct values
AND t2.join2 = t1.join2 -- 40 / 50 distinct values
AND t2.join1 = 20 -- 40 distinct values
;
- dbms_xplan
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 42 | 1428 | 57 |
|* 1 | HASH JOIN | | 42 | 1428 | 57 |
|* 2 | TABLE ACCESS FULL | T2 | 250 | 4250 | 28 |
|* 3 | TABLE ACCESS FULL | T1 | 333 | 5661 | 28 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
1 - access("T2"."JOIN1"="T1"."JOIN1" AND "T2"."JOIN2"="T1"."JOIN2")
2 - filter("T2"."JOIN1"=20)
3 - filter("T1"."JOIN1"=20)
- 9i
Join Selectivity =
{join1 bit} *
{join2 bit} =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) *
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(50, 40) =
1/40 * 1/50 = 1/2000
Join Cardinality =
(1 / 2000) *
10000 / 30 * 10000 / 40 =
333 * 250 / 2000 =
41.625
- 10g
Join Cardinality =
(1 / 1600) *
10000 / 30 * 10000 / 40 =
333 * 250 / 2000 =
52.031
- t2.join1 = t1.join1 조건절이 다시 나타났다. t2.join1 = 20 조건절을 생성하려고 이행적 폐쇄를 사용할 필요가 없었다.
- 옵티마이저가 t2.join1의 선택도를 중복해서 두번 계산하는 셈이된다(조인 선택도를 위해 한번(1), 필터 카디널리티를 위해 한번(2))
- 10g에서는 다중컬럼 sanity check 효과 때문에 다르게 나타난다. 1/2,000 대신 더 작은 결과집합을 리턴하는 어느 한쪽 테이블로부터의 개별적인 선택도들을 가져온다(여기서는 t2 테이블로부터 1/40*1/40=1/1,600)
- 오래전부터 사람들은 옵티마이저와 관련된 버그들을 발견하고는 이를 이용해 단순 조건절을 반복 사용함으로써 옵티마이저가
다른 실행계획을 사용하도록 조정하곤 했다. - 8i/9i 에서 query_rewrite_enabled 파라미터를 TRUE로 설정하는 것은 이행적 폐쇄가 작동한느 방식에 영향을 미친다.
세 개 이상 테이블을 조인할 경우
- 세 번째 테이블과 조인 시 연결 컬럼이 첫 번째 또는 두 번째 테이블 중 어느 한 쪽으로부터 오는 것이 아니라 양쪽 모두에서 오는 경우.
SELECT t1.v1,
t2.v1,
t3.v1
FROM t1,
t2,
t3
WHERE t2.join1 = t1.join1 -- 36 / 40 distinct values
AND t2.join2 = t1.join2 -- 38 / 40 distinct values
--
AND t3.join2 = t2.join2 -- 37 / 38 distinct values
AND t3.join3 = t2.join3 -- 39 / 42 distinct values
--
AND t3.join4 = t1.join4 -- 41 / 40 distinct values
;
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=109 Card=9551 Bytes=573060)
1 0 HASH JOIN (Cost=109 Card=9551 Bytes=573060)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=28 Card=10000 Bytes=200000)
3 1 HASH JOIN (Cost=62 Card=62500 Bytes=2500000)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=29 Card=10000 Bytes=200000)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=200000)
조인 순서 t1 > t2 > t3
- t3을 메모리로 해싱
- t1을 메모리로 해싱
- t2를 읽기 시작하여 각 로우마다 매칭되는 데이터를 찾기 위해 t1 해시 테이블 탐색
- 첫 번째 탐색이 성공한다면 매칭 되는 데이터를 찾기 위해 t3 해시 테이블 탐색
- 첫 번째 조인은 t1 > t2 (t2 > t1이 맞지 않나??), 두 번째 조인은 (t1 > t2) > t3
Join Selectivity =
{join1 bit} *
{join2 bit} =
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater (36 , 40) *
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater (38 , 40) =
1/1600
Join Cardinality =
1 / 1600 *
10000 * 10000 =
62,500
- 62,500개의 로우를 갖는 중간집합을 생성.
Join Selectivity =
{join2 bit} *
{join3 bit} *
{join4 bit} =
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 37, 38) * -- greater( 37, 40)으로 대체해야 하지 않을까?
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 39, 42) *
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 41, 40) =
1/65,436
Join Cardinality =
1 / 65436 *
62500 * 10000 =
9,551 (as required)
- 조인 선택도를 계산하기 위해 join2와 join3의 컬럼이 속한 테이블의 SQL 조인문에 기술된 테이블 별칭을 보고 알 수 있다.
- 무의식적으로(또는 고의로) 조인 조건절을 다르게 기술했을 때 계산된 카디널리티가 어떻게 바뀔까?
t2.join1 = t1.join1
and t2.join2 = t1.join2
--
and t3.join3 = t2.join3
--
and t3.join2 = t1.join2 -- was t3.join2 = t2.join2
and t3.join4 = t1.join4
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=109 Card=9074 Bytes=544440)
1 0 HASH JOIN (Cost=109 Card=9074 Bytes=544440)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=28 Card=10000 Bytes=200000)
3 1 HASH JOIN (Cost=62 Card=62500 Bytes=2500000)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=29 Card=10000 Bytes=200000)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=200000)
이행성 폐쇄는 열결고리 컬럼 중 어느 하나에 상수조건을 추가적으로 가지고 있을 때에만 일어난다.
- 계산된 카디널리티가 9,074로 떨어졌다.
- 공식은 분명히 greater( 37, 38)에서 greater( 37, 40)으로 바뀌었다.
- 이것은 틀림없이 옵티마이저의 결함이다.
- (첫 번째는 중간집합시 t1테이블 선택도 사용, t3 조인시 t2 테이블의 선택도 사용, 두 번째는 중간집합시 t1테이블 선택도 사용, t3 조인시 t1 테이블의 선택도 사용)
- 복잡한 조인에서도 항상 컬럼의 선택도를 정확하고 일관성 있게 처리 해야 한다.
- 10g에서 실행할 때 고려해야 할 중요한 요소가 있다.(sanity check)
- 첫 번째는 같은 방식으로 9,551로 계산(join4 컬럼을 위해 t3 선택도 사용)
- 두 번째는 9,301로 바뀐다(join2를 위해 t1 선택도 사용, join4 컬럼에 대해서도 t1 선택도 사용)
- 더 나쁜 케이스는 't3.join2 = t2.join2', 't3.join2 = t1.join2'를 모두 사용할 경우 두 조건 모두를 사용하여 최종 카디널리티를 계산한다.(239로 떨어진다)
- 이런 이유 때문에 다중테이블 조인문을 작성할 때는 세심한 주의가 필요하다.
조인 컬럼에 NULL값을 갖는 경우
- 두 테이블만을 다룰 때는 대개 문제가 되지 않지만, 오라클 버전이 8i에서 9i로 올라가면서 조인 선택도 계산시 NULL을 다루는 전략이 바뀌었다.
- (존인 컬럼에 포함된 NULL값의 개수가 테이블 로우 수의 5%를 초과할 때만 새로운 계산식이 사용)
create table t1 AS
SELECT mod(rownum-1, 15) n1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 150 ;
UPDATE t1
SET n1 = null
WHERE n1 = 0;
- 100개의 로우를 가진 t1 테이블 정의.
- n1 컬럼은 1 ~ 9까지 9개의 값과 NULL 값을 가지도록 가공.(num_rows=100, num_distinct=9, num_nulls=10)
- t2, t3는 각각 1~11, 1~14까지의 값을 갖도록 정의
- 세 테이블 모두 n1 컬럼이 어떤 값이든 각각 열 개의 로우를 가진다.
- 각 테이블마다 n1에는 NULL값을 가진 레코드도 열 개씩 들어 있으므로 5% 제한을 넘는다.
SELECT /*+ ordered */
t1.v1,
t2.v1,
t3.v1
FROM t1,
t2,
t3
WHERE t2.n1 = t1.n1
AND t3.n1 = t2.n1 ;
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=9000 Bytes=378000)
1 0 HASH JOIN (Cost=8 Card=9000 Bytes=378000)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=2 Card=140 Bytes=1960)
3 1 HASH JOIN (Cost=5 Card=900 Bytes=25200)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=2 Card=90 Bytes=1260)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=2 Card=110 Bytes=1540)
Execution Plan (8.1.7.4 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=5 Card=8250 Bytes=346500)
1 0 HASH JOIN (Cost=5 Card=8250 Bytes=346500)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=1 Card=150 Bytes=2100)
3 1 HASH JOIN (Cost=3 Card=900 Bytes=25200)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=1 Card=100 Bytes=1400)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=1 Card=120 Bytes=1680)
- 라인 4, 5의 각 테이블 스켄을 위한 다른 카디널리티로 계산 했는데 두 버전 모두 라인 3에서 같은 카디널리티(900) 값을 보여준다.
- 로우수 계산 (9i가 정확)
- t1의 n1 컬럼에는 9개의 다른값, 총 90개의 로우(NULL 제외)
- t2에 매칭되는 로우가 10개씩, 조인결과 900로우
- t3에 매칭되는 로우가 10개씩, 조인결과 총 9,000로우
- 9i에서 dbms_xplan을 이용하면 필터 조건절에 다음을 확인할 수 있다
t1.n1 is not null
t2.n1 is not null
t3.n1 is not null
- t1.n1 = t1.n2 조건으로 조인한 결과집합에는 이들 컬럼에 NULL값을 가진 레코드가 존재할 수 없다.
- 8i
T1 to T2: the tables with 100 and 120 rows respectively:
Join Selectivity =
(100 - 10) / 100) *
(120 - 10) / 120) /
greater(9, 11) = 0.075
Join Cardinality =
0.075 * 100 * 120 = 900
Intermediate to T3: the table with 150 rows:
Join Selectivity =
(120 - 10) / 120) * -- the CBO uses the t2 figures at one end
(150 - 10) / 150) / -- of the join, and the t3 at the other.
greater(11, 14) =
0.0611111
Join Cardinality =
0.061111 * 900 * 150 =
8,250
- 9i
T1 to T2: the tables with 100 and 120 rows respectively:
Join Selectivity =
1 / greater(9, 11) =
0.09090909
Join Cardinality =
0.09090909 * 90 * 110 =
900
Intermediate to T3: the table with 150 rows:
Join Selectivity =
1 / greater(11, 14) =
0.0714285
Join Cardinality =
0.0714285 * 900 * 140 =
9,000 (as required)
- 9i에서는 'is not null' 조건에 의한 필터링 효과를 조인 카디널리티를 구하는 단계에서 반영하고 있다.
- 즉, 조인 선택도 공식에는 NULL효과를 반영하지 않고 조인 카디널리티를 구하는 단계에서만 각 테이블의 필터된 카디널리티를 인자로 사용.
- 8i에서 9i로 업그레이드하면 NULL 허용 컬럼들을 이용해 여러 테이블을 조인하는 쿼리들의 카디널리티가 더 높게 계산되기 때문에 갑자기 실행계획이 바뀔 수 있다(계산된 카디널리티가 앞 단계에서 증가하기 때문에 NL -> 해쉬 나 머지로)
"코어 오라클 데이터베이스 스터디모임" 에서 2009년에 "비용기반의 오라클 원리
" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3983
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.