비용기반의 오라클 원리 (2009년)
5. 클러스터링 팩터
- 클러스터링 팩터(Clustering Factor)는 B-Tree 인덱스를 사용한 Range Scan 비용 계산식의 중요한 요소이며, 비용계산 결과에 오차를 일으키는 가장 큰 원인이 될 수 있다고 경고했다.
- 클러스터링 팩터는 데이터가 테이블 전체에 무작위로 분산된 정도를 나타내는 하나의 숫자이다.
- 테이블 내 데이터의 흩어짐(Scatter)을 표현할 수 있는 숫자를 만든 발상은 매우 훌륭하다.
- DBA가 성능을 개선하거나 경합을 줄이고자 채택한 합리적인 전략 대부분이 오히려 옵티마이져가
- 당연히 사용해야 할 인덱스를 무시하게 하는 부작용을 일으키는데, 이 장은 이런 내용을 다루고 있다.
- 앞으로의 모든 설명은 전통적인 힙 구조(Heap-Organized) 테이블에 초점을 맞출 것이며, 예제에 사용된 문제의 인덱스는 대체로 시간기반(time-based) 또는 순서기반(Sequence-based) 컬럼을 가진다.
5.1. 기준 예제
SQL> create table t1 ( date_ord date constraint t1_dto_nn not null,
seq_ord number(6) constraint t1_sqo_nn not null ,
small_vc varchar2(10)) pctfree 90 pctused 10
/
Table created.
SQL> create sequence t1_seq ;
Sequence created.
SQL> create or replace procedure t1_load(i_tag varchar2) as
m_date date ;
begin
for i in 0..25 loop
m_date := trunc(sysdate) + i ;
for j in 1..200 loop
insert into t1 values ( m_date, t1_seq.nextval, i_tag||j) ;
commit ;
dbms_lock.sleep(0.01);
end loop;
end loop;
end ;
/
Procedure created.
-- 다중 세션에서 동시에 Insert 수행
SQL> execute t1_LOAD('a');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('b');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('c');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('d');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('e');
PL/SQL procedure successfully completed.
SQL> create index t1_i1 on t1 ( date_ord, seq_ord ) ;
Index created.
SQL> begin
dbms_stats.gather_table_stats ( user ,'t1', cascade => true, estimate_percent=>null, -
method_opt => 'for all columns size 1');
end ;
/
PL/SQL procedure successfully completed.
SQL> select blocks , num_rows from user_tables where table_name ='T1';
BLOCKS NUM_ROWS
---------- ----------
754 26000
SQL> select index_name, blevel, leaf_blocks, clustering_factor from user_indexes
2 where table_name ='T1';
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ----------- -----------------
T1_I1 1 87 1342
- PCTFREE 90 을 부여하여 적은 Row 수로 다수의 Block 을 차지 하도록 Table 생성,
- Insert 주체를 파악하기 위한 "small_vc", 다섯 세션에서 동시에 Insert 작업 수행 후,
- Rows, Block, Clustering Factor 파악 하기
- 이 사례에서 클러스터링 팩터가 테이블 블록 개수와 비슷한 반면 테이블 로우 수보다 훨씬 적다는 사실에 주목하라.
SQL>
alter session set "_optimizer_cost_model"=io ;
Session altered.
SQL> alter session set "_optimizer_skip_scan_enabled"=false;
Session altered.
SQL> set autotrace traceonly explain
SQL> select count(small_vc) from t1 where date_ord = trunc(sysdate)+7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 57 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 1000 | 13000 | 57 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 1000 | | 5 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
SQL> set autotrace off
- 특정 날짜의 모든 데이터를 요청 하는 쿼리를 수행 - 인덱스 사용
- 비용 계산은 아래와 같다.
비용 계산
Cost =
Blevel +
Ceil(effective index selectivity*leaf_blocks) +
Ceil(effective table selectivity*clustering_factor)
Cost =
1\+
Ceil(0.03846*86) +
Ceil(0.03846*1,008)
= 1 + 4 + 39 = 44
5.2. 테이블 경합 줄이기(다중 FREELIST) - 테이블
SQL>
select /*+ full(t1) */ rowid, date_ord, seq_ord, small_vc from t1
where rownum <= 10 ;
ROWID DATE_ORD SEQ_ORD SMALL_VC
------------------ --------------- ---------- ----------
AAANFyAABAAAO/SAAA 18-JUN-09 5201 a1
AAANFyAABAAAO/SAAB 18-JUN-09 5202 a2
AAANFyAABAAAO/SAAC 18-JUN-09 5203 a3
AAANFyAABAAAO/SAAD 18-JUN-09 5204 a4
AAANFyAABAAAO/SAAE 18-JUN-09 5205 a5
AAANFyAABAAAO/SAAF 18-JUN-09 5206 a6
AAANFyAABAAAO/SAAG 18-JUN-09 5207 a7
AAANFyAABAAAO/SAAH 18-JUN-09 5208 a8
AAANFyAABAAAO/SAAI 18-JUN-09 5209 a9
AAANFyAABAAAO/SAAJ 18-JUN-09 5210 a10
10 rows selected.
확장 rowid 는 다음과 같이 구성되어 있다.
- Object_ID 처음 6개 문자 (AAANFy)
- 상대 File_ID 다음 3개 문자 (AAB)
- 파일 내 블록 번호 다음 6개 문자 (AAAO/S)
- 블록 내 로우 위치 다음 3개 문자 (AAJ)
여기서는 모든 로우가 같은 블록(AAANFy)에 존재한다.
- 테스트 실행 시, 로우를 삽입하는 프로세스를 식별하고자 small_vc 컬럼에 꼬리표를 달아 놓았다.
- 다섯 개 모든 프로세스가 동시에 같은 블록을 사용하느라 분주했을 것이다.
- 아주 바쁜 시스템(특히, 동시성이 높은 시스템)에서, 모든 데이터가 하나의 블록에 집중적으로
- 입력되는 경우 해당 블록에서 다수의 buffer busy waits 가 나타날 수 있다.
- 이 문제를 어떻게 해결할 수 있을까 ?
- 테이블을 생성할 때 다중 FREELIST를 가지도록 하면 된다.
Storage ( freelists 5 )
- 이 절을 사용하면, 오라클은 테이블의 세그먼트 헤더 블록에 매달린 다섯 개의 FREE 블록 연결 리스트를 관리한다.
- 프로세스가 로우를 삽입할 때, FREE 블록을 찾으려면 어떤 리스트를 방문해야 할지 프로세스 ID를 사용하여 결정한다.
- 이것은 ( 약간의 운에 따라서 ) 다섯 개의 동시 프로세스가 서로 전혀 충돌하지 않을 수 있다는 뜻이다.
- 다섯 개 프로세스는 로우 삽입 시 완전히 다른 다섯 개 테이블 블록을 사용할 수 있다.
FREELIST 관리"
- 기본적으로, 테이블은 오직 한 개의 세그먼트 FREELIST 를 갖도록 정의한다.
- 오라클은 고수위선(HWM, High Water Mark)을 다섯 블록씩 밀어 올리고 FREELIST 가 비워질 때마다 이 블록들을 FREELIST 에 추가한다.
- 일반적으로, 전형적인 힙구조 테이블의 로우 생성 시 FREELISTS의 최상위(top) 블록만 사용된다. 다중 FREELIST 을 지정하면, 오라클은 (사용자가 지정한 개수보다) 세그먼트 FREELIST를 하나 더 할당하며 첫 번째 것을 마스터 FREELIST로 사용한다.
- 이 마스터 FREELIST 는 나머지 다른 FREELIST를 제어하고 이들이 같은 길이(대략 0 에서 5블록 사이)를 유지하도록 하는 중심점이다. 과거에는 테이블 생성 시에만 FREELIST 파라미터를 설정할 수 있었지만,
- 8i(아마도 8.1.6) 시점부터 간단한 alter 명령어를 통해 FREELIST 값을 변경할 수 있으며 이후에 공간을 할당할 때부터 적용된다.
FREELIST 를 5로 설정하고, 앞의 테스트 반복 수행
- 클러스터링 팩터가 1,000 정도(테이블 블록 개수와 비슷)에서 26,000(테이블 로우 개수와 일치)으로 증가했다.
- 따라서 옵티마이저는 이 인덱스가 끔찍하다고 생각하여 하루치를 조회하는 쿼리에서조차 인덱스 사용을 거부했다.
- 그러나 안타까운 것은 하루에 입력된 데이터는 FREELIST 가 1일 때와 마찬가지로 여전히 30에서 35개 테이블 블록에 존재하며, 단지 로우의 순서만 변경되었을 뿐이다.
- 이 문제는 오라클이 클러스터링 팩터 계산 시 최근 이력을 유지하지 않고, 단순히 현재 블록이 이전 블록과 같은지 여부만 확인하기 때문이다.
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 24136
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 74 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 74 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
5.3. LEAF 블록 경합 줄이기(reverse key 인덱스) - 인덱스
- Reverse key 인덱스로 순서기반 인덱스의 끝부분에서 발생하는 경합(특히 RAC 시스템에서)을 줄이기 위한 매커니즘 이다.
- Reverse key 인덱스는 인덱스 구조에 결과 값을 삽입하기 전에 인덱스 구성 컬럼 각각의 바이트 순서를 뒤집는다. 이를 통해 연속된 값이 무작위로 흩어진 인덱스 엔트리가 된다.
SQL>
select dump(date_ord,16) date_dump, dump(seq_ord,16) seq_dump
from t1
where date_ord = to_date('18-jun-2009') and seq_ord = 39 ;
DATE_DUMP SEQ_DUMP
---------------------------------- -------------------------------
Typ=12 Len=7: 78,6d,6,12,1,1,1 Typ=2 Len=2: c1,28
1 row selected.
그러나 이 값을 뒤집으면
SQL> select dump(reverse(date_ord),16) date_dump, dump(reverse(seq_ord), 16) seq_dump from t1
2 where date_ord = to_date('18-jun-2009') and seq_ord = 39 ;
DATE_DUMP SEQ_DUMP
---------------------------------------- ----------------------------------------
Typ=12 Len=7: 1,1,1,12,6,6d,78 Typ=2 Len=2: 28,c1
1 row selected.
Normal Index
SQL> create index t1_i1 on t1(date_ord, seq_ord);
Index created.
SQL> begin
2 dbms_stats.gather_table_stats(
3 user,
4 't1',
5 cascade => true,
6 estimate_percent => null,
7 method_opt => 'for all columns size 1'
8 );
9 end;
10 /
PL/SQL procedure successfully completed.
SQL> select blocks, num_rows from user_tables
where table_name = 'T1';
BLOCKS NUM_ROWS
---------- ----------
744 26000
1 row selected.
SQL> select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1' ;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 801
1 row selected.
SQL> set autotrace traceonly explain
SQL> select count(small_vc)
from t1
where date_ord = trunc(sysdate) + 7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 36 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 1000 | 13000 | 36 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 1000 | | 5 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DATE_ORD"=TRUNC(SYSDATE@!)+7)
SQL> set autotrace off
- 인덱스 사용
Reverse Index
SQL> alter index t1_i1 rebuild reverse;
Index altered.
SQL> begin
2 dbms_stats.gather_table_stats(
3 user,
4 't1',
5 cascade => true,
6 estimate_percent => null,
7 method_opt => 'for all columns size 1'
8 );
9 end;
10 /
PL/SQL procedure successfully completed.
SQL> select blocks, num_rows
from user_tables
where table_name = 'T1';
BLOCKS NUM_ROWS
---------- ----------
744 26000
1 row selected.
SQL> select index_name, blevel, leaf_blocks, clustering_factor
From user_indexes
Where table_name = 'T1' ;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 25979
1 row selected.
SQL> set autotrace traceonly explain
SQL> select count(small_vc) from t1
where date_ord = trunc(sysdate) + 7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 166 (2)| 00:00:02 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 166 (2)| 00:00:02 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
SQL> set autotrace off
CLUSTERING_FACTOR 값이 높아졌으며, Index 를 사용하지 않았음
- 인덱스를 뒤집는 목적은 테이블 엔트리가 연속된 값으로 들어올 때 인덱스 엔트리를 흩뿌리기(Scatter) 위함이지만, 이는 인접한 인덱스 엔트리에서 가리키는 테이블 엔티리가 여기 저기 흩어지는 결과를 가져온다.
- 다시 말하면, 클러스터링 팩터가 극도로 증가한다.
- 이번 테스트에서 클러스터링 팩터가 로우 개수와 비슷하므로, 사용자가 원하는 로우가 작은 테이블 블록 집합(Cluster)에 모여 있음에도 실행 계획이 Index Range Scan 에서 Table Scan 으로 변경되었다.
- 클러스터링 팩터를 계산하는 매커니즘은 reverse key 인덱스이 영향을 모르기 때문에, 사용자의 데이터 분포는 변하지 않았지만 오라클은 크게 변했다고 생각한다.
- 특정 인덱스에 대한 i/o 집중을 피하기 위해서 Reverse Index 를 사용하게 되면 결과적으로, Table Block 은 그대로고, Index Block 이 흩뿌려져서, Clustering Factor 가 증가하되고, Full Table Scan 을 선호 하게 된다.
Reverse Key 인덱스와 Range Scan
- Reverse Key 인덱스가 Range Scan 을 사용하지 못하는 경우는 Reverse Key 인덱스가, 단일 컬럼 유니크 인덱스의 경우에만 해당 된다.
5.4. 테이블 경합 줄이기(ASSM)
- 인덱스의 효율성을 크게 떨어뜨리는 또 다른 신기능이 있는데, 이 기능 또한 데이터를 흩뿌림으로써 경합을 줄인다.
- 다시 말하지만, 하나의 성능 문제를 해결하려는 어떤 시도는 또 다른 성능 문제를 일으킬 수 있다.
SQL> create tablespace test_8k_assm
blocksize 8k
datafile '/u02v/dbatest/DBATEST/test_8k_assm.dbf'
size 50m extent management local
uniform size 1m segment space management auto
- 오라클은, 특히 RAC 환경에서, 로우 생성 시 테이블 블록에 대한 경합 문제를 회피하고자 이 새로운 segment space management 전략을 선보였다. ASSM 에는 두 가지 주요 특징이 있다.
- 첫 번째는 구조적인 특징이다. ASSM 테이블스페이스 내 각 세그먼트는 각 익스텐트 시작 부분의 몇 개 블록 (대개 익스텐트의 64개 블록 당 한두 개)을 사용하여 해당 익스텐트 내 나머지 다른 블록에 대한 맵을 관리 한다.
- 이를 통해 각 블록에 여유 공간이 얼마나 남아 있는지 대충(정확히 말하면 1/4 블록 단위로) 짐작할 수 있다.
- 두 번째 특징은 실행 시점에 나타난다. 프로세스가 로우를 삽입할 때, 프로세스 ID 에 의해 결정된 공간 맵 블록을 선택한 후 공간 맵으로 부터 데이터 블록(또 다시 프로세스 ID에 의해 결정된)을 선택한다.
- ASSM의 순(NET) 효과는 DBA의 개입 없이 프로세스 간 경합을 최소화 하도록 동시 수행되는 프로세스가 데이터 삽입 시 서로 다른 블록을 선택하는 것이다.
BLOCKS NUM_ROWS
---------- ----------
754 26000
1 row selected.
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 23044
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 74 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 74 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
- ASSM Tablespace 에 Table 생성 시, CLUSTERING_FACTOR 가 높아지며, Table Access 를 선호하게 된다.
- 데이터 생성 코드, 데이터 정의 또는 최종 사용자의 행동에 아무런 변화가 없어도, 기본구조 레벨에서의 독특한 오라클 기능만으로 실행 계획이 인덱스를 통한 엑세스 경로에서 테이블 스캔으로 변경될 수 있다.
- 이 특별한 테스트를 통해서 얻은 또 다른 정보는 ASSM 사용 시 로우 생성의 무작위성과 경합이다.
SQL> select ct,count(*)
from
(
select block, count(*) ct
from
(
select
distinct dbms_rowid.rowid_block_number(rowid) block,
substr(small_vc, 1,1)
from t1
)
group by block
)
group by ct
;
CT COUNT(*)
---------- ----------
5 11
1 461
3 62
2 188
4 5
5 rows selected.
표 5-1 ASSM 과 FREELIS 에서 충돌 횟수
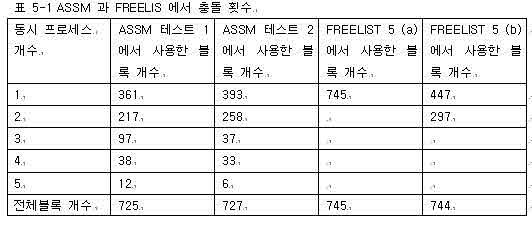
- FREELIST 를 완벽하게 설정하면 동시 로우 생성 시 테이블 블록 경합을 절대적으로 줄일 수 있지만 항상 그런 것은 아니다.
- 반면 ASSM 에 의한 무작위 정도(Degree of randomness) 로는 경합을 완벽하게 회피하기 어렵지만, 시간이 지남에 따라(프로세스가 증가함에 따라) 경합 발생량이 감소하면서 넓게 퍼질 것이다.
5.5. RAC 에서 경합 줄이기(FREELIST GROUPS)
- 동시 로우 생성이 매우 빈번한, 특히 (과거의) OPS와 (현재의) RAC 환경에서 테이블에 대한 경합을 줄이기 위한 또 다른 옵션은 다중 FREELIST GROUP 을 사용하여 테이블을 생성하는 것이다.
- RAC 환경에서, 다중 FREELIST 를 지정하여 테이블 블록에 대한 경합을 제거하더라도 인스턴스 간에 전송되는 세그먼트 헤더 블록은 과열한다. 테이블 정의사항의 일부로 다중 FREELIST GROUP 을 지정할 수 있다.
STORAGE ( FREELIST GROUPS 5 )
- 이렇게 하면(NON-ASSM 테이블스페이스에서), 세그먼트 헤더 블록 뒤의 세그먼트 시작점에서 FREELIST GROUP 당 한 개의 블록을 얻는다.
- 각 블록(그룹)은 인스턴스 ID 와 연관되어 있으며, 각 블록(그룹)은 독립적인 FREELIST 세트를 관리 한다.
- 따라서, 세그먼트 헤더에 해한 경합이 제거 된다.
- RAC 시스템에서 다중 FREELIST GROUP 을 사용하여 테이블 블록에 대한 경합을 자동으로 완화시키는 몇 가지 시나리오가 있다.
첫째, 시퀸스(sequence)의 캐시 사이즈를 충분히 크게 설정한다.
- 예를 들면, Create sequence big_seq cache 10000 ;
- 각 인스턴스가 자신만의 '캐시(Cache)' ( 실제로는 low/high 또는 current/target 의 두 개 숫자만) 관리 하기 때문에, 한 인스턴스가 생성한 값은 다른 인스턴스가 생성한 값과 크게 다를 수 있다.
- 값의 차이가 크면 서로 떨어진 두 개의 리프 블록에 각각의 값을 저장할 것이다. ( Instance 간의 Ordering 이 되지 않는다. Order Option Or Nocache Option 활용 )
둘째, 테이블의 FREELIST 를 1로 설정하여 각 인스턴스에서 캐싱하는 인덱스 블록이 FRESLIST 절에서 설명했던 flip-flop 효과의 영향을 받지 않도록 한다.
- ( 각 프로세스가 서로 다른 블록을 번갈아 액세스한다는 것의 의미한다. )
- 그러나 여기에는 주의해야 할 커다란 부작용이 있다.
- 각 인스턴스가 자기의 개별적인 인덱스 구역을 효율적으로 채우기 때문에, 현재 가장 높은 값을 가진 부분을 제외한 리프 블록 분할 시 50/50 분할(다시 채워질 가능성이 없는)이 모든 인스턴스에서 일어날 수 있다.
- 다시 말하면, RAC 시스템에서 테이블에 대한 경합, 순서기반 컬럼 인덱스에 대한 경합, 이러한 인덱스의 클러스터링 팩터에 대한 손상을 피할 수 있지만, 반대급부로 인덱스 사이즈
- ( 특히 리프 블록 개수)가 단일 인스턴스 데이터베이스의 것보다 두 배 가까이 커질 수 있다.
5.6. 인덱스 컬럼 순서
- 범위기반 조건 뒤에 나오는 컬럼에 어떤 조건을 사용해도 유효 인덱스 선택도(effective index selectivity) 계산 시 무시(유효 테이블 선택도(effective table selectivity)에는 사용되지만)되면 이 때문에 오라클이 해당 인덱스의 비용을 터무니없이 높게 처리한다.
- 이런 문제 때문에, 범위기반 조건에 자주 사용되는 컬럼을 인덱스 뒤쪽에 위치시키는 재구성 작업을 제안하기도 한다.
create table t1
pctfree 90
pctused 10
as
select
trunc((rownum-1)/ 100) clustered,
mod(rownum - 1, 100) scattered,
lpad(rownum,10) small_vc
from
all_objects
where
rownum <= 10000
;
Create index t1_i1_good on t1 ( clustered, scattered ) ;
Create index t1_i2_bad on t1 (scattered, clustered ) ;
BLOCKS NUM_ROWS
---------- ----------
278 10000
select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1'
;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I2_BAD 1 24 10000
T1_I1_GOOD 1 24 278
2 rows selected.
set autotrace traceonly explain
select
/*+ index(t1 t1_i1_good) */
count(small_vc)
from
t1
where
scattered = 50
and clustered between 1 and 5
;
Execution Plan
----------------------------------------------------------
Plan hash value: 1877155477
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 4 |
| 1 | SORT AGGREGATE | | 1 | 16 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 96 | 4 |
|* 3 | INDEX RANGE SCAN | T1_I1_GOOD | 6 | | 3 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("CLUSTERED">=1 AND "SCATTERED"=50 AND "CLUSTERED"<=5)
filter("SCATTERED"=50)
Note
-----
- cpu costing is off (consider enabling it)
- 이 쿼리를 가장 효율적으로 수행하기 위한 요건을 완벽하게 만족하는 것으로 보이는 인덱스 ( 첫 번째 scattered 컬럼에 equel 조건을 사용하고 두 번째 clustered 컬럼에 범위기반 조건을 사용한)가 있는데도, 옵티마이저는 엉뚱한 인덱스(선두 컬럼에 범위기반 조건을 사용한) 를 선택 한다.
select
/*+ index(t1 t1_i2_bad) */
count(small_vc)
from
t1
where
scattered =50
and clustered between 1 and 5
;
Execution Plan
----------------------------------------------------------
Plan hash value: 2775871337
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 9 |
| 1 | SORT AGGREGATE | | 1 | 16 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 96 | 9 |
|* 3 | INDEX RANGE SCAN | T1_I2_BAD | 6 | | 2 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("SCATTERED"=50 AND "CLUSTERED">=1 AND "CLUSTERED"<=5)
Note
-----
set autotrace off
- 힌트를 추가하여 ( 사용자가 적절하다고 생각하는 ) 인덱스를 사용하도록 강요하면, 오라클이 이 인덱스를 사용하지만, 옵티마이저가 기본적으로 선택한 인덱스를 사용하는 경우보다 비용이 두 배 이상 커진다.
- 이 결과는 옵티아미저가 클러스터링 팩터를 고려하여 인덱스를 통한 인덱스 경로의 비용을 산출하는 과정에 큰 약점이 있음을 보여준다.
- 옵티마이저는 단순히 테이블 블록 방문 횟수만을 평가하기 때문에, 최근에 방문한 블록을 다시 방문함으로써 얻어지는 비용감소 효과를 계산식에 어떻게 반영해야 하는지 모른다.
5.7. 인덱스 컬럼 추가
- 컬럼 순서 변경만이 문제를 일으키는 것은 아니다.
- 기존 인덱스에 컬럼을 한 두 개 추가하는 것은 매우 일반적인(그리고 대체로 효과적인) 사례이다.
- 이 방법도 클러스터링 팩터에 극적인 차이를 만들 수 있으며, 따라서 인덱스 선호도에 큰 영향을 미친다.
- 기존 : movement_date
- 이후 : movement_date + product_id
create table t1
as
select
sysdate + trunc((rownum-1) / 500) movement_date,
trunc(dbms_random.value(1,60.999)) product_id,
trunc(dbms_random.value(1,10.000)) qty,
lpad(rownum,10) small_vc,
rpad('x',100) padding
from
all_objects
where
rownum <= 10000
;
create index t1_i1 on t1(movement_date);
begin
dbms_stats.gather_table_stats(
user,
't1',
cascade => true,
estimate_percent => null,
method_opt => 'for all columns size 1'
);
end;
/
Select blocks, num_rows
From user_tables
Where table_name = 'T1';
select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1';
set autotrace traceonly explain
-- 인덱스 컬럼 추가를 권장하는 예제
select sum(qty)
from t1
where movement_date = trunc(sysdate) + 7
and product_id = 44
;
-- 인덱스 변경으로 불리해지는 예제
Select product_id, max(small_vc)
from t1
where movement_date = trunc(sysdate) + 7
group by product_id
;
set autotrace off
BLOCKS NUM_ROWS
---------- ----------
182 10000
1 row selected.
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 27 182
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 12 |
| 1 | SORT AGGREGATE | | 1 | 14 | |
|* 2 | TABLE ACCESS BY INDEX ROWID| T1 | 8 | 112 | 12 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 500 | | 2 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PRODUCT_ID"=44)
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
Execution Plan
----------------------------------------------------------
Plan hash value: 3571608589
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 1320 | 38 |
| 1 | HASH GROUP BY | | 60 | 1320 | 38 |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 500 | 11000 | 12 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 500 | | 2 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
drop index t1_i1;
create index t1_i1 on t1(movement_date, product_id);
begin
dbms_stats.gather_table_stats(
user,
't1',
cascade => true,
estimate_percent => null,
method_opt => 'for all columns size 1'
);
end;
/
Select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1' ;
set autotrace traceonly explain
select sum(qty)
from t1
where movement_date = trunc(sysdate) + 7
and product_id = 44;
select product_id, max(small_vc)
from t1
where movement_date = trunc(sysdate) + 7
group by product_id
;
set autotrace off
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 31 6645
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 7 |
| 1 | SORT AGGREGATE | | 1 | 14 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 8 | 112 | 7 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 8 | | 1 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7 AND "PRODUCT_ID"=44)
Note
-----
- cpu costing is off (consider enabling it)
Execution Plan
----------------------------------------------------------
Plan hash value: 2967276995
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 1320 | 45 |
| 1 | HASH GROUP BY | | 60 | 1320 | 45 |
|* 2 | TABLE ACCESS FULL| T1 | 500 | 11000 | 19 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
5.8. 통계정보 바로잡기
- 오라클이 산출한 클러스터링 팩터가 테이블 내 데이터가 실제로 모여있는 상태를 정확히 대변하지 못할 수 있음을 설명했다.
- 데이터와 오라클의 계산방식을 조금만 이애하면, 문제를 바로잡을 수 있다.
- DBMS_STATS 패키지를 통해서 가능하다. Get_xxx_stats 와 set_xxx_stats 등 중요한 두 가지 클래스의 프로시저를 포함하고 있다.
데이터 딕셔너리 조작하기
PL/SQL API 로 데이터 딕셔너리 조작하는 것과 Update Col$ 를 조작하는 것
- 전자는, 사용자가 시스템에 대해서 오라클에 무엇을 지시하고 있는지 이해 못하지도 모르지만, 적어도 데이터 딕셔너리를 일관된 (Self-Consistent) 상태로 유지할 것이다.
- 후자는 (a) 사용자가 한 번에 변경해야 할 것이 얼마나 많은지 모르며, (b) 딕셔너리 캐시(v$rowcache)로부터 마음대로 갱신되는 것처럼 보이므로, 변경 사항이 실제로 데이터 딕셔너리에 반영되는지 알수 없다.
- © 데이터베이스가 일관성 없는 상태가 되기 쉽다.
끝으로
Alter table x enable row movement ;
Alter table x shrink space compact ;
Alter table x shrink space ;
- 이 기능을 사용하기 전에, 이 명령은 테이블 끝부분에서 옮겨온 데이터를 가지고 시작 부분의 구멍을 메움으로써 공간을 재사용하도록 한다는 사실을 명심하라.
- 다시 말하면, 로우가 테이블 끝에서 다른 쪽으로 이동하기 때문에, 데이터 입력 시각에 의한 자연적인 클러스터링이 손상될 수 있다.
요약
- 클러스터링 팩터는 index range scan 비용 산정에 매우 중요하다.
- 그러나 몇 가지 오라클의 기능과 성능전략에 의해 부적절한 클러스터링 팩터가 만들어지기도 한다.
- 대부분의 경우, 일어날 만한 문제는 쉽게 예측할 수 있으며, 다른 방법을 사용하여 더 적절한 클러스터링 팩터를 만들어 낼 수 있다. 언제든지 dbms_stats 패키지를 사용하여 클러스터링 팩터를 바로 잡을 수 있다.
- 만약 다중 FREELISTS 또는 ASSM 사용에 의해 클러스터링 팩터가 과도하게 증가하며, 클러스터링 팩터를 만들어내는 오라클 내부 코드인 SYS_OP_COUNTCHG() 함수를 사용하여 더 현실적인 값을 얻을 수 있다.
"코어 오라클 데이터베이스 스터디모임" 에서 2009년에 "비용기반의 오라클 원리
" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3978
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.