Optimizing Oracle Optimizer (2011년)
1. CSSCAN 사용목적
- character set 변경시 발생할 수 있는 문제점을 미리 감지하고 보고서를 생성해주는 매우 유용한 유틸리티이다.
2. CSSCAN utility에서 적용되는 scan 범위
- CHAR, VARCHAR2, LONG, CLOB, NCHAR, NVARCHAR2, NCLOB 데이터를 모두 검사한다.
- 전체 데이터베이스, 사용자 또는 지정된 테이블에 대해 수행할 수 있다.
- 데이터베이스의 문자 데이터는 사용자 데이터와 데이터 딕셔너리 데이터로 나누어지는데 데이터 딕셔너리 데이터는 전체 데이터베이스 스캔에서만 검사된다.(데이터 딕셔너리 컬럼 길이는 모든 모드에서 검색 가능)
3. CSSCAN utility 실행시 검사 항목
- 문자가 코드를 변경하는지 여부
- 문자를 새로운 집합에 나타낼 수 있는지 여부
- 새 문자열 길이가 컬럼 정의를 초과하는지 여부
4. CSSCAN utility 사용 방법
- 10gR1 이상부터는 $ORACLE_HOME/bin/csscan이 존재하지만 9iR2 이하 버전은 별도 설치가 필요하다.
4.1 CSSCAN utility schema 생성
- sysdba 권한을 가지고 sqlplus 에 접속하여 csscan을 설치한다.
connect / as sysdba
SQL> @?/rdbms/admin/csminst.sql
- 위의 문장을 실행하지 않고 csscan을 사용하려고 하면 아래의 에러메세지가 나온다.
- CSS-00107: Character set migration utility schema not installed
4.2 CSSCAN 실행
- 아래와 같이 명령행 인터페이스를 사용하거나 혹은 대화식 프롬프트로 실행할 수 있다.
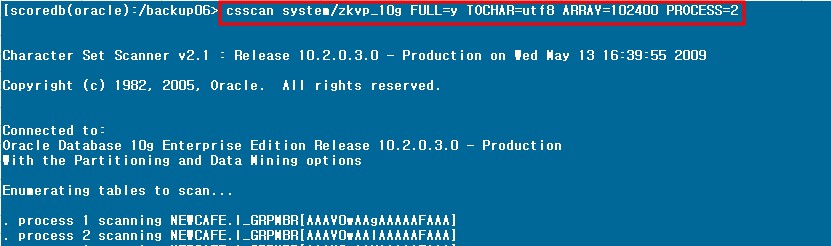
- csscan system/manager FULL=y TOCHAR=utf8 ARRAY=102400 PROCESS=5
4.3 CSSCAN 매개변수 설명
csscan help=y
- USERID: 표준 사용자 이름/암호[@alias]는 문자열을 데이터베이스에 연결한다. 사용자는 DBA 권한이 있어야 한다.
- FULL: Y인 경우 전체 데이터베이스를 스캔한다. FULL은 USER, TABLE과 함께 사용할 수 없다.
- USER: 스캔할 테이블의 소유자
- TABLE:(table1, table2, ...) 형식의 스캔할 테이블 이름
- TOCHAR: 대상 CHARACTER SET의 이름으로 이 문자 집합에 대해 CHAR, VARCHAR2, LONG, CLOB 데이터의 테스트 변환이 수행된다.
- PROCESS: 스캔시 사용할 프로세스의 수이다. 상당한 CPU를 사용하니 명령을 수행할 시스템의 CPU를 확인한 후 설정한다.
- ARRAY: fetch array 크기이다.
- LOG: 출력될 세파일의 이름 및 경로이다.
- TONCHAR: NCHAR, NVARCHAR, NCLOB 데이터의 대상 문자 집합이다.
- PARFILE: 모든 매개변수를 포함하는 매개변수 파일이다.
5. CSSCAN 실행 후의 결과물
- 세개의 텍스트 파일 보고서(기본 이름은 scan)가 생성된다.
5.1 scan.out
- scan 명령을 수행한 화면 로그 복사
5.2 scan.txt
- 요약 보고서
- 사용된 매개변수
- 테이블스페이스 크기
- 스캔된 데이터 양
- 문제 데이터가 있는 테이블과 컬럼
5.3 scan.err
- 오류 보고서
- 문제가 있는 행 목록
- 변환할 수 없는 문자
- 컬럼 길이 오버플로우
6. CHARACTER SET 변환
- 문자 집합 스캐너 출력 결과를 확인한 후에 수행한다.
- 출력 결과에서 변환할 수 없는 문자가 있는 경우에는 character set의 변환이 불가하다.(superset 관계가 아닌 character set으로의 변환의 경우)
- 컬럼 길이 오버플로우 발생시나 변환할 수 없는 문자가 없는 경우 아래의 방법을 사용한다.
6.1 EXPORT/IMPORT
- 데이터베이스 character set 을 변환할 때 권장되는 방법이다.
- 오래 걸리는 것이 단점이지만 인덱스 재구축, 삭제된 공간 압축등의 장점이 특징이다.
- 컬럼 길이 오버플로우가 발생했을 경우 임포트 전에 미리 긴 컬럼이 필요한 테이블을 생성한다.
- 데이터베이스를 export한다.
- 새 character set을 가지는 데이터베이스를 생성한다.
- 긴 컬럼 길이가 필요한 테이블을 생성한다.
- 데이터를 import 한다. (이전 단계에서 생성한 테이블로 import 하는 경우 IGNORE=YES 옵션을 준다.)
6.2 ALTER DATBASE [NATIONAL] CHARACTER SET
- csscan 수행 결과 문자 코드가 변경된 문자가 없을 경우 가장 빠른 변환 방법이다
- 이전에 입력된 데이터의 character set 이 적용되도록 선언을 변경하는데 사용된다.
- 9i까지만 사용이 가능하며 10g부터는 지원하지 않는다.(CSALTER 사용)
6.3 EXPORT/IMPORT + ALTER DATABASE CHARACTER SET
- 변환이 필요한 데이터양이 적을 때 사용한다.
- 변환이 필요한 데이터를 포함하는 테이블을 export 한다.
- export한 테이블을 truncate 한다.
- ALTER DATABASE ... CHARACTER SET ... 명령을 수행한다.
- 테이블 데이터를 다시 import 한다.
6.4 CSALTER(10g 이상)
- 10g부터 ALTER DATBASE CHARACTER SET 명령을 대신해서 사용된다.
- 데이터베이스를 restricted mode로 오픈한다.(이 명령 수행시 다른 세션이 접속해 있으면 실패한다.)
- SYS 유저로 접속해서 $ORACLE_HOME/rdbms/admin/csalter.plb를 수행한다.
- 데이터베이스가restricted 모드가 아닐 때
Checking data validility...
Sorry only one session is allowed to run this script
- 문자 변환에 문제가 있을 때
Checking data validility...
Unrecognized convertible date found in scanner result
7. 실제 사용사례(scoredb \-> dbset04)
테스트 환경
- scoredb 서버의 dbset04 마이그레이션을 목적으로 변환시 문제가 없는 지 확인
- character set: KO16KSC5601 => AL32UTF8 (superset 관계가 아님)
- data size: 93G(문자 데이터만은 아님)
csscan 수행
- 약 2시간 소요
- PROCESS를 2로 수행했을 때 CPU 평균 60% 정도 사용(CPU 사양: Intel® Xeon™ CPU 3.06GHz * 2 (CORE:2))
 |
 |
csscan 출력 결과(일부만 발췌합니다.)
1) SCAN.TXT
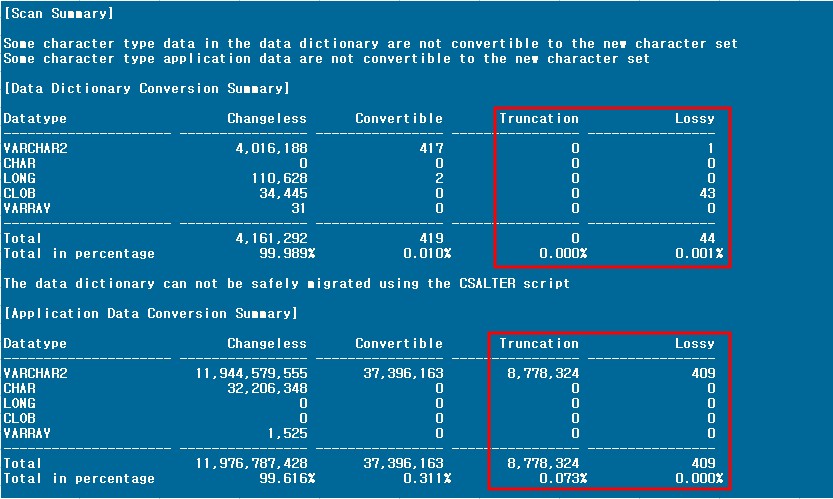 |
- data dictionary data와 user data 모두에서 truncation, lossy가 발생한 것을 확인할 수 있다. 정확한 발생 원인은 scan.err 에서 확인한다.
2) SCAN.ERR
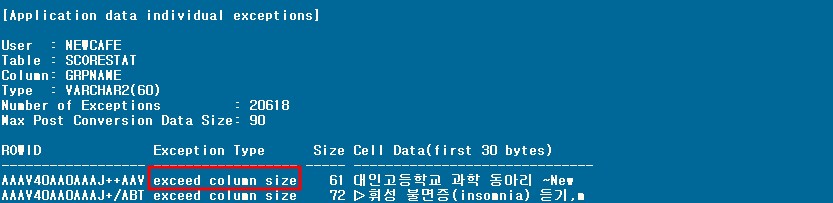 |
- exceed column size: KO16KSC5601 => AL32UTF8로 character set이 변환되면서 한글데이터의 경우 사이즈가 증가하여 발생한 에러이다. 컬럼 사이즈를 일정하게 증가하여 해결하였다.
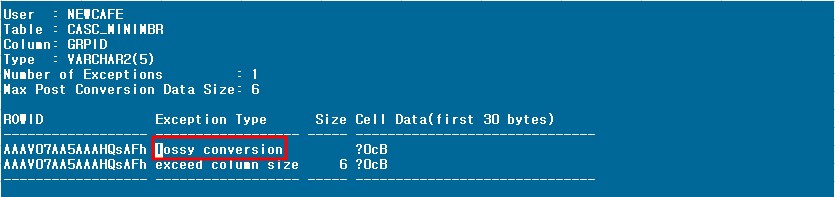 |
- lossy conversion: character set 변환시 데이터가 정상적인 변환이 되지 못해 깨지면서 발생하는 손실이다. 이런 Exception Type이 발생하는 경우 해당 데이터를 삭제하거나 포기하지 않는 이상 character set의 변환은 불가하다.
결론
- 위의 예에서는 csscan을 사용한 character set 변경시 발생할 수 있는 문제점을 진단한 결과 exceed column size, lossy conversion 두경우에 해당하는 문제점이 보고되었다.
- 그 중 exceed column size는 컬럼사이즈를 변경하면서 간단히 해결될 수 있는 문제이지만 lossy conversion의 경우 해결 방법이 없다.
- 해당하는 테이블과 컬럼을 살펴보아 필요없는 데이터라고 판단되면 이 점을 감안할 수 있겠지만 그렇지 않을 경우 chracter set의 변환이 불가하다.
- scan.txt에서 보이듯 총 453건의 lossy 데이터가 발견되었고(영어, 한글 모두 해당된다.) 이에 따라 KO16KSC5601 => AL32UTF8로의 character set 변환은 적합하지 않다.
"데이터베이스 스터디모임" 에서 2009년에 "OPTIMIZING ORACLE OPTIMIZER
" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3954
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.